
تحديد حالات الحوار لنماذج اللغة المحدثة
نشرت: 2022-03-16الادعاءات الأولى لتحديد حالات الحوار لنماذج اللغة
من المحتمل أنك رأيت براءات اختراع حوار من إنسان إلى كمبيوتر من Google. لقد كتبت عن البعض في الماضي. فيما يلي نوعان يوفران الكثير من التفاصيل حول هذا الحوار:
- حوار من إنسان إلى كمبيوتر في Google
- المحتوى غير المرغوب فيه في حوار من إنسان إلى كمبيوتر
بالإضافة إلى النظر بعناية في براءات الاختراع التي تتضمن حوارًا بين الإنسان والحاسوب ، فإن الأمر يستحق قضاء بعض الوقت في معالجة اللغات الطبيعية ، والاتصالات بين البشر وأجهزة الكمبيوتر. لقد كتبت أيضًا عن عدد قليل من هؤلاء. وهنا اثنين منهم:
- مساعد Google ومعالجة اللغة الطبيعية القائمة على السياق
- ردود استعلام اللغة الطبيعية
تم تحديث براءة اختراع Google Determining Dialog States For Language Models مرتين الآن ، مع منح أحدث إصدار في وقت سابق من هذا الأسبوع. آخر مطالبة أولية أطول قليلاً ولديها بعض الكلمات الجديدة المضافة إليها.
من الناحية المثالية ، يجب أن تبدأ براءات الاختراع هذه بإلقاء نظرة عميقة على لغة المطالبات.
يبدأ الإصدار الثاني من تحديد حالات الحوار لنماذج اللغة ، والذي تم تقديمه بتاريخ 18 ، 2018 ، وتم منحه في 4 فبراير 2020 ، بالمطالبة التالية:
- ما ادعى هو:
- 1. طريقة يتم تنفيذها بالحاسوب وتشمل:
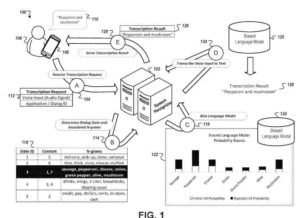
- تلقي ، بواسطة جهاز كمبيوتر ، بيانات صوتية لإدخال صوتي إلى جهاز الحوسبة ، حيث يتوافق الإدخال الصوتي مع مرحلة غير معروفة من حوار صوتي متعدد المراحل بين جهاز الحوسبة ومستخدم جهاز الحوسبة
- تحديد تنبؤ أولي لمرحلة غير معروفة من الحوار الصوتي متعدد المراحل
توفير بواسطة الجهاز الحاسوبي ونظام الحوار الصوتي ،- (ط) البيانات الصوتية للإدخال الصوتي لجهاز الحوسبة و
- (2) إشارة إلى التنبؤ الأولي للمرحلة غير المعروفة من الحوار الصوتي متعدد المراحل
- تلقي نسخة من الإدخال الصوتي ، عن طريق الجهاز الحاسوبي ومن نظام الحوار الصوتي ، حيث تم إنشاء النسخ من خلال معالجة البيانات الصوتية بنموذج متحيز وفقًا لمعايير تتوافق مع تنبؤ دقيق لمرحلة غير معروفة من الحوار الصوتي متعدد المراحل ، حيث يتم تكوين نظام الحوار الصوتي لتحديد التنبؤ الدقيق للمرحلة غير المعروفة من الحوار الصوتي متعدد المراحل بناءً على (1) التنبؤ الأولي للمرحلة غير المعروفة من الحوار الصوتي متعدد المراحل و
- (2) معلومات إضافية تصف سياق الإدخال الصوتي ، وحيث تكون المعلومات الإضافية التي تصف سياق الإدخال الصوتي مستقلة عن محتوى
- إدخال الصوت وتقديم نسخ الإدخال الصوتي بجهاز الحوسبة.
يبدأ الإصدار الأول من براءة الاختراع المستمرة هذه ، تحديد حالات الحوار لنماذج اللغة ، المقدمة في 16 مارس 2016 ، والمُنحت في 22 مايو 2018 ، بهذا الادعاء:
- ما ادعى هو:
- 1. طريقة يتم تنفيذها بالحاسوب وتشمل:
- تلقي ، في نظام الحوسبة ، بيانات صوتية تشير إلى الإدخال الصوتي الأول الذي تم توفيره لجهاز الكمبيوتر
- تحديد أن الإدخال الصوتي الأول هو جزء من حوار صوتي يتضمن مجموعة من حالات الحوار المحددة مسبقًا والمرتبة لتلقي سلسلة من المدخلات الصوتية المتعلقة بمهمة معينة ، حيث يتم تعيين كل حالة حوار إلى: (1) مجموعة من عرض البيانات التي تميز المحتوى المخصص للعرض عند استلام المدخلات الصوتية لحالة الحوار ، و
(2) مجموعة من n-grams - تلقي ، في نظام الحوسبة ، أولاً عرض البيانات التي تميز المحتوى الذي تم عرضه على شاشة جهاز الحوسبة عندما تم توفير الإدخال الصوتي الأول لجهاز الحوسبة ؛ التحديد ، بواسطة نظام الحوسبة ، حالة حوار معينة لمجموعة حالات الحوار المحددة مسبقًا التي تتوافق مع الإدخال الصوتي الأول ، بما في ذلك تحديد التطابق بين بيانات العرض الأولى ومجموعة بيانات العرض المقابلة التي تم تعيينها إلى معين حالة الحوار تحيز نموذج اللغة عن طريق ضبط درجات الاحتمال التي يشير إليها نموذج اللغة لـ n-grams في المجموعة المقابلة من n-grams التي تم تعيينها لحالة الحوار الخاصة ؛ ونسخ المدخلات الصوتية باستخدام نموذج اللغة المتحيزة.
تم تقديم المطالبة الأولى الأخيرة في الإصدار الأخير من براءة الاختراع هذه ، تحديد حالات الحوار لنماذج اللغة ، في 2 يناير 2020 ، وتم منحها في 1 مارس 2022. تخبرنا:
- ما ادعى هو:
- 1. طريقة يتم تنفيذها بالحاسوب وتشمل:
- الحصول على نسخ من المدخلات الصوتية من مجموعة تدريب من المدخلات الصوتية ، حيث يتم توجيه كل إدخال صوتي في مجموعة التدريب الخاصة بالمدخلات الصوتية إلى واحدة من عدة مراحل لنشاط صوتي متعدد المراحل
- الحصول على بيانات العرض المرتبطة بكل إدخال صوتي من مجموعة التدريب للمدخلات الصوتية التي تميز المحتوى المخصص للعرض عند استلام الإدخال الصوتي المرتبط ؛ إنشاء مجموعة متعددة من مجموعات النسخ ، حيث تتضمن كل مجموعة من النسخ مجموعة فرعية مختلفة من تدوينات المدخلات الصوتية من مجموعة التدريب للمدخلات الصوتية
- تعيين كل مجموعة من النسخ إلى حالة حوار مختلفة لنموذج حالة الحوار الذي يتضمن تعدد حالات الحوار ، حيث تتوافق كل حالة حوار لتعددية حالات الحوار: مع مرحلة مختلفة من النشاط الصوتي متعدد المراحل ؛ ويتم تعيينها إلى مجموعة معنية من بيانات العرض التي تميز المحتوى المخصص للعرض عند استلام المدخلات الصوتية من مجموعة التدريب للمدخلات الصوتية المرتبطة بمجموعة النسخ المخصصة لحالة الحوار ؛ لكل مجموعة من النسخ ، وتحديد مجموعة تمثيلية من n-grams للمجموعة ، وربط المجموعة التمثيلية من n-grams للمجموعة بحالة الحوار المقابلة لنموذج حالة الحوار الذي تم تعيين المجموعة إليه ، حيث مجموعة تمثيلية من n-grams تم تحديدها لمجموعة النسخ تشتمل على n-grams- تلبية لعدد الحد الأدنى من التكرارات في مجموعة النسخ المخصصة لحالة الحوار لنموذج حالة الحوار
- تلقي إدخال صوتي لاحق وعرض بيانات العرض الأول الذي يميز المحتوى الذي تم عرضه على الشاشة عند تلقي الإدخال الصوتي اللاحق ، والإدخال الصوتي اللاحق موجه نحو مرحلة معينة من النشاط الصوتي متعدد المراحل
تحديد تطابق بين بيانات العرض الأولى ومجموعة بيانات العرض ذات الصلة المعينة لحالة الحوار في نموذج حالة الحوار الذي يتوافق مع المرحلة المعينة من النشاط متعدد الأصوات - المعالجة ، باستخدام أداة التعرف على الكلام ، والإدخال الصوتي اللاحق ، وبيانات العرض الأولى ، بما في ذلك تحيز أداة التعرف على الكلام باستخدام مجموعة تمثيلية من n-grams المرتبطة بحالة الحوار في نموذج حالة الحوار الذي يتوافق مع مرحلة معينة من نشاط متعدد الأصوات
\
مقارنة ادعاءات دول الحوار الحاسمة لنماذج اللغة
هذه بعض الاختلافات التي أراها مع الإصدارات المختلفة لبراءة الاختراع:

1. تخبرنا جميع الإصدارات الثلاثة أنها تدور حول "مدخلات صوتية" ، والتي تعمل كجزء من مجموعة التدريب.
لذلك على عكس براءات الاختراع السابقة حول حالات الحوار بين البشر وأجهزة الكمبيوتر ، والتي ركزت على محتوى الحوار ، فإن براءة الاختراع هذه تنظر في المقام الأول إلى اللغة اللفظية والمدخلات الصوتية الفعلية.
2. يصف الإصداران الثاني والثالث من براءة الاختراع تقسيم نصوص المدخلات الصوتية إلى نغمات ، والتي يمكن أن تساعد في حساب الإحصائيات حول تكرارات المدخلات الصوتية المستخدمة.
3. يشير ادعاء الإصدارين الأحدث والثالث من حالات حوار تحديد براءات الاختراع للنماذج اللغوية إلى استخدام أداة التعرف على السرعة.
- ما ادعى هو:
- 1. طريقة يتم تنفيذها بواسطة الكمبيوتر ، وتشمل: تلقي ، في نظام حوسبي ، بيانات صوتية تشير إلى أول إدخال صوتي تم توفيره لجهاز كمبيوتر ؛ تحديد أن الإدخال الصوتي الأول هو جزء من حوار صوتي يتضمن مجموعة من حالات الحوار المحددة مسبقًا والمرتبة لتلقي سلسلة من المدخلات الصوتية المتعلقة بمهمة معينة ، حيث يتم تعيين كل حالة حوار إلى:
- (1) مجموعة من بيانات العرض التي تميز المحتوى المخصص للعرض عند استلام المدخلات الصوتية لحالة الحوار ، و
- (2) مجموعة من n-grams ؛ تلقي ، في نظام الحوسبة ، أولاً عرض البيانات التي تميز المحتوى الذي تم عرضه على شاشة جهاز الحوسبة عندما تم توفير الإدخال الصوتي الأول لجهاز الحوسبة
- التحديد ، بواسطة نظام الحوسبة ، حالة حوار معينة لمجموعة حالات الحوار المحددة مسبقًا والتي تتوافق مع الإدخال الصوتي الأول ، بما في ذلك تحديد التطابق بين بيانات العرض الأولى ومجموعة بيانات العرض المقابلة التي تم تعيينها إلى المعين حالة الحوار
- تحيز نموذج اللغة عن طريق ضبط درجات الاحتمالية التي يشير إليها نموذج اللغة لـ n-grams في المجموعة المقابلة من n-grams التي تم تعيينها لحالة الحوار المعينة
- نسخ المدخلات الصوتية باستخدام نموذج اللغة المتحيزة.
تحديد حالات الحوار لنماذج اللغة
المخترعون: بيتار أليكسيتش ، بيدرو مورينو منجبار
الوكيل: Google LLC
براءات الاختراع الأمريكية: 11264.028
تم المنح: 1 مارس 2022
تاريخ التقديم: 2 يناير 2020
خلاصة
تم وصف الأنظمة والطرق والأجهزة والتقنيات الأخرى هنا لتحديد حالات الحوار التي تتوافق مع مدخلات الصوت ولتحيز نموذج اللغة بناءً على حالات الحوار المحددة. في بعض التطبيقات ، تتضمن الطريقة تلقي ، في نظام حوسبة ، بيانات صوتية تشير إلى إدخال صوتي وتحديد حالة حوار معينة ، من بين مجموعة من حالات الحوار ، والتي تتوافق مع الإدخال الصوتي. يمكن تحديد مجموعة من n-grams المرتبطة بحالة الحوار المعينة التي تتوافق مع إدخال الصوت. استجابةً لتحديد مجموعة n-grams المرتبطة بحالة الحوار المعينة التي تتوافق مع الإدخال الصوتي ، يمكن أن يكون نموذج اللغة متحيزًا عن طريق ضبط درجات الاحتمال التي يشير إليها نموذج اللغة لـ n-grams في مجموعة n- جرامات. يمكن نسخ الإدخال الصوتي باستخدام نموذج اللغة المعدل.
البحث في الأخبار مباشرة إلى بريدك الوارد
*مطلوب