
Generative Adversarial Networks (GAN): はじめに
公開: 2022-08-16敵対的生成ネットワーク (GAN) は、古い写真の作成や音声の増強から、医療やその他の業界でのさまざまなアプリケーションの提供まで、多くのユースケースで多くの可能性を提供する最新のテクノロジの 1 つです。
この高度なテクノロジーは、製品やサービスの形成に役立ちます。 また、思い出を保存するために画質を向上させるためにも使用できます。
GAN は多くの人に恩恵をもたらしますが、気になる人もいます。
しかし、この技術は正確には何ですか?
この記事では、GAN とは何か、その仕組み、およびそのアプリケーションについて説明します。
それでは、さっそく飛び込みましょう!
敵対的生成ネットワークとは
Generative Adversarial Network (GAN) は、写真、ユニークな音楽、絵などのより正確な予測を生成するために競合する 2 つのニューラル ネットワークで構成される機械学習フレームワークです。
GANs は、2014 年にコンピューター科学者でエンジニアの Ian Goodfellow と彼の同僚によって設計されました。 それらは、トレーニング対象のデータと同様の新しいデータを生成できる独自のディープ ニューラル ネットワークです。 彼らは、一方のエージェントがゲームに負け、もう一方のエージェントが勝つという結果になるゼロサム ゲームで競います。
もともと、GAN は機械学習、主に教師なし学習の生成モデルとして提案されました。 しかし、GAN は完全教師あり学習、半教師あり学習、強化学習にも役立ちます。
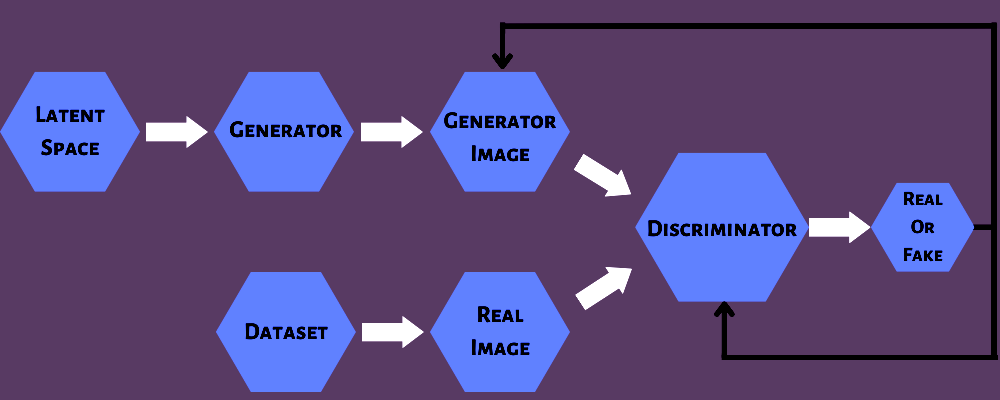
GAN で競合する 2 つのブロックは次のとおりです。
ジェネレーター:実際のデータに似た出力を人工的に生成する畳み込みニューラル ネットワークです。
弁別器:これは、人工的に作成された出力を識別することができるデコンボリューション ニューラル ネットワークです。
重要な概念
GAN の概念をよりよく理解するために、いくつかの重要な関連概念を簡単に理解しましょう。
機械学習 (ML)

機械学習は人工知能 (AI) の一部であり、データを活用してモデルを学習および構築し、タスクを実行したり、意思決定や予測を行ったりしながら、パフォーマンスと精度を向上させます。
ML アルゴリズムは、トレーニング データに基づいてモデルを作成し、継続的な学習によって改善します。 これらは、コンピューター ビジョン、自動意思決定、メール フィルタリング、医療、銀行業務、データ品質、サイバーセキュリティ、音声認識、レコメンデーション システムなど、複数の分野で使用されています。
判別モデル

深層学習と機械学習では、識別モデルは分類子として機能し、一連のレベルまたは 2 つのクラスを区別します。
たとえば、さまざまな果物や動物を区別します。
生成モデル
生成モデルでは、新しいリアルな画像を作成するためにランダム サンプルが考慮されます。 オブジェクトや生き物の実際の画像から学習して、現実的でありながら模倣された独自のアイデアを生成します。 これらのモデルには、次の 2 つのタイプがあります。
変分オートエンコーダー:別個のニューラル ネットワークであるエンコーダーとデコーダーを利用します。 これが機能するのは、特定の現実的な画像がエンコーダーを通過して、これらの画像を潜在空間のベクトルとして表現するためです。
次に、デコーダを使用してこれらの解釈を取得し、これらの画像の現実的なコピーを生成します。 最初は画質が悪いかもしれませんが、デコーダーが完全に機能するようになると改善され、エンコーダーは無視できます。
敵対的生成ネットワーク (GAN):上記で説明したように、GAN は提供されたデータ入力から新しい同様のデータを生成できるディープ ニューラル ネットワークです。 これは、以下で説明する機械学習の種類の 1 つである、教師なし機械学習に分類されます。
教師あり学習
教師ありトレーニングでは、適切にラベル付けされたデータを使用してマシンがトレーニングされます。 これは、一部のデータが既に正しい回答でタグ付けされていることを意味します。 ここでは、教師あり学習アルゴリズムがトレーニング データを分析し、このラベル付けされたデータから正確な結果を生成できるようにするために、マシンにいくつかのデータまたは例が与えられます。
教師なし学習
教師なし学習では、ラベル付けも分類もされていないデータを使用して機械をトレーニングします。 これにより、機械学習アルゴリズムがガイダンスなしでそのデータを処理できるようになります。 このタイプの学習では、マシンのタスクは、事前のデータ トレーニングなしで、パターン、類似点、および相違点に基づいて、並べ替えられていないデータを分類することです。
したがって、GAN は ML での教師なし学習の実行に関連付けられています。 入力データからパターンを自動的に発見して学習できる 2 つのモデルがあります。 これら 2 つのモデルは、ジェネレーターとディスクリミネーターです。
それらをもう少し理解しましょう。
GANのパーツ
「敵対的」という用語が GAN に含まれているのは、GAN には生成要素と分母の競合という 2 つの部分があるためです。 これは、データセット内のデータのバリエーションをキャプチャ、精査、複製するために行われます。 GAN のこれら 2 つの部分について理解を深めましょう。
発生器
ジェネレーターは、リアルに見える画像や音声などの偽のデータ ポイントを学習および生成できるニューラル ネットワークです。 これはトレーニングで使用され、継続的な学習によって改善されます。
ジェネレーターによって生成されたデータは、他の部分 (次に説明する分母) の負の例として使用されます。 ジェネレーターは、ランダムな固定長ベクトルを入力として受け取り、サンプル出力を生成します。 本物か偽物かを分類できるように、識別器の前に出力を提示することを目的としています。
ジェネレーターは、次のコンポーネントでトレーニングされます。
- ノイズの多い入力ベクトル
- ランダムな入力をデータ インスタンスに変換するジェネレータ ネットワーク
- 生成されたデータを分類する識別ネットワーク
- ディスクリミネーターをだますことができないため、ジェネレーターにペナルティを課すジェネレーターの損失
ジェネレーターは泥棒のように機能し、現実的なデータを複製して作成し、ディスクリミネーターをだまします。 実行されるいくつかのチェックをバイパスすることを目的としています。 初期段階ではひどく失敗する可能性がありますが、複数の現実的で高品質のデータを生成してテストを回避できるようになるまで、改善を続けます。 この能力が達成された後は、別個の弁別器を必要とせずにジェネレーターのみを利用できます。
識別器

弁別器は、偽物と本物の画像またはその他のデータ型を区別できるニューラル ネットワークでもあります。 発電機のように、トレーニング段階で重要な役割を果たします。
泥棒を捕まえるために警察のように振る舞います(ジェネレーターによる偽のデータ)。 これは、データ インスタンスの誤ったイメージと異常を検出することを目的としています。
前に説明したように、ジェネレーターは、弁別器を必要としない高品質の画像を生成するために自立するようになるポイントに到達するために学習し、改善を続けます。 ジェネレーターからの高品質データがディスクリミネーターを通過すると、本物の画像と偽の画像を区別できなくなります。 したがって、ジェネレーターだけを使用しても問題ありません。
GANはどのように機能しますか?
敵対的生成ネットワーク (GAN) では、次の 3 つのことが関係します。
- データの生成方法を説明する生成モデル。
- モデルがトレーニングされる敵対的な設定。
- トレーニング用の AI アルゴリズムとしてのディープ ニューラル ネットワーク。
GAN の 2 つのニューラル ネットワーク (ジェネレーターとディスクリミネーター) は、敵対的なゲームをプレイするために使用されます。 ジェネレーターは、音声ファイルや画像などの入力データを取得して同様のデータ インスタンスを生成し、ディスクリミネーターはそのデータ インスタンスの信頼性を検証します。 後者は、レビューしたデータ インスタンスが本物かどうかを判断します。
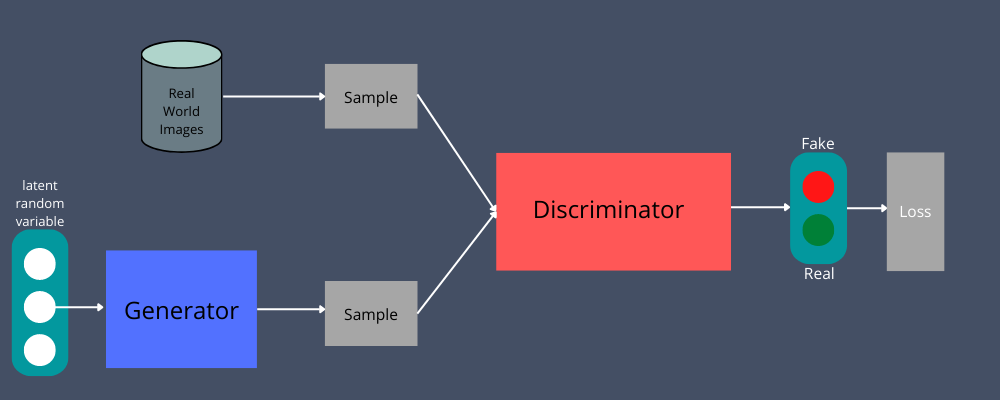
たとえば、特定の画像が本物か偽物かを検証したいとします。 手動で生成されたデータ入力を使用して、ジェネレーターにフィードできます。 出力として、複製された新しいイメージが作成されます。
そうしている間、ジェネレーターは、生成するすべての画像が偽物であるにもかかわらず、本物と見なされることを目指しています。 嘘をつき、捕まらないようにするために、まずまずの結果を作成したいと考えています。
次に、この出力は、実際のデータからの一連の画像とともに弁別器に送られ、これらの画像が本物かどうかを検出します。 どんなに真似しようとしても、ジェネレーターに悪影響を及ぼします。 弁別器は、事実のデータと偽のデータを区別するのに役立ちます。

ディスクリミネータは偽データと実データの両方を取得して、0 または 1 の確率を返します。ここで、1 は真正性を表し、0 は偽物を表します。
このプロセスには 2 つのフィードバック ループがあります。
- ジェネレーターは、フィードバック ループにディスクリミネーターを結合します。
- 弁別器は、一連の実画像を使用して別のフィードバック ループに参加します。
ジェネレーターとディスクリミネーターの両方がトレーニング中であるため、GAN トレーニングは機能します。 ジェネレーターは偽の入力を渡すことで継続的に学習しますが、ディスクリミネーターは検出を改善するために学習します。 ここでは、両方とも動的です。
ディスクリミネータは、供給された画像を分類できる畳み込みネットワークです。 これは、画像に偽物または本物のラベルを付ける二項分類器として機能します。
一方、ジェネレーターは、ランダムなデータ サンプルを取得して画像を生成する逆畳み込みネットワークのようなものです。 ただし、ディスクリミネーターは、最大プーリングなどのダウンサンプリング手法を使用してデータを検証します。
どちらのネットワークも、敵対的なゲームで反対の異なる損失関数または目的関数を最適化しようとします。 彼らの損失は、彼らがお互いにさらに強く押し合うことを可能にします。
GANの種類

敵対的生成ネットワークは、実装に基づいてさまざまなタイプがあります。 以下は、積極的に使用されている主な GAN タイプです。
- 条件付き GAN (CGAN):これは、実際のデータと偽のデータを区別するのに役立つ特定の条件付きパラメーターを含むディープ ラーニング手法です。 また、対応するデータを生成するために、ジェネレーター フェーズに "y" という追加のパラメーターも含まれます。 また、ラベルがこの入力に追加され、ディスクリミネーターに供給されて、データが本物か偽物かを検証できるようになります。
- バニラ GAN: ディスクリミネーターとジェネレーターがより単純な多層パーセプトロンである単純な GAN タイプです。 そのアルゴリズムは単純で、確率的勾配降下法を利用して数学方程式を最適化します。
- ディープ畳み込み GAN (DCGAN):人気があり、最も成功した GAN 実装と見なされています。 DCGAN は、多層パーセプトロンではなく、ConvNet で構成されています。 これらの ConvNet は、最大プーリングやレイヤーの完全接続などの手法を使用せずに適用されます。
- 超解像度 GAN (SRGAN):これは、敵対的ネットワークと共にディープ ニューラル ネットワークを使用して高品質の画像を生成するのに役立つ GAN 実装です。 SRGAN は、元の低解像度画像を効率的にアップスケーリングして詳細を強調し、エラーを最小限に抑えるのに特に役立ちます。
- Laplacian Pyramid GAN (LAPGAN):これは、8 スペース離れて配置された複数のバンドパス イメージを含む、可逆的で線形な表現であり、低周波の残基が含まれています。 LAPGAN は、いくつかのディスクリミネーターおよびジェネレーター ネットワークと、複数のラプラシアン ピラミッド レベルを利用します。
LAPGAN は最高の画質を提供するため、広く使用されています。 これらの画像は、最初に各ピラミッド レイヤーでダウンサンプリングされ、次にすべてのレイヤーでアップスケールされます。ここで、元のサイズになるまでアイデアにノイズが与えられます。
GANの応用
敵対的生成ネットワークは、次のようなさまざまな分野で使用されています。
化学

GAN は、高エネルギー ジェットの形成をモデル化し、物理実験を行うための正確かつ迅速な方法を提供できます。 これらのネットワークをトレーニングして、大量のリソースを消費する素粒子物理学のシミュレーションを実行する際のボトルネックを推定することもできます。
GAN は、シミュレーションを高速化し、シミュレーションの忠実度を向上させることができます。 さらに、GAN は重力レンズ効果をシミュレートし、天体画像を強調することで暗黒物質の研究に役立ちます。
ビデオゲーム

ビデオ ゲームの世界でも、GAN を活用して、古いビデオ ゲームで使用される低解像度の 2 次元データを拡大しています。 画像トレーニングを通じて、そのようなデータを 4k またはそれ以上の解像度に再作成するのに役立ちます。 次に、データまたは画像をダウンサンプリングして、ビデオ ゲームの実際の解像度に適合させることができます。
GAN モデルに適切なトレーニングを提供します。 色などの実際の画像の詳細を保持しながら、ネイティブ データと比較して印象的な品質のよりシャープで鮮明な 2D 画像を提供できます。
GAN を活用したビデオ ゲームには、バイオハザード リメイク、ファイナル ファンタジー VIII および IX などがあります。
アートとファッション
GAN を使用して、存在したことのない個人の画像の作成、インペイント写真、非現実的なファッション モデルの写真の作成など、アートを生成できます。 また、仮想影やスケッチを生成する図面でも使用されます。
広告

GAN を使用して広告を作成および作成すると、時間とリソースを節約できます。 上記のように、ジュエリーを販売したい場合は、GAN を使用して実際の人間のように見える架空のモデルを作成できます。
このようにして、モデルにあなたのジュエリーを着用させ、顧客に見せることができます. モデルを雇ってお金を払う必要がなくなります。 交通費、スタジオのレンタル、カメラマンやメイクアップ アーティストの手配などの余分な費用をなくすこともできます。
これは、成長中のビジネスで、モデルを雇ったり、広告撮影用のインフラストラクチャを用意したりする余裕がない場合に非常に役立ちます.
音声合成
GAN を使用して、一連のオーディオ クリップからオーディオ ファイルを作成できます。 これはジェネレーティブ オーディオとも呼ばれます。 これを、Amazon Alexa、Apple Siri、または音声の断片が適切に合成され、オンデマンドで生成されるその他の AI 音声と混同しないでください。
代わりに、ジェネレーティブ オーディオはニューラル ネットワークを使用して音源の統計的特性を調べます。 次に、特定のコンテキストでこれらのプロパティを直接再現します。 ここで、モデリングは、ミリ秒ごとに音声がどのように変化するかを表します。
転移学習

高度な転移学習研究では、GAN を利用して、深層強化学習などの最新の特徴空間を調整します。 このために、ソースの埋め込みと目的のタスクがディスクリミネーターに供給され、コンテキストが決定されます。 次に、結果がエンコーダを介して逆伝播されます。 このようにして、モデルは学習を続けます。
GAN のその他のアプリケーションには、次のようなものがあります。
- 緑内障画像の検出による完全または部分的な視力喪失の診断
- インダストリアル デザイン、インテリア デザイン、衣料品、靴、バッグなどを視覚化する
- 病気の人の法医学的な顔の特徴を再構築する
- 画像からアイテムの 3D モデルを作成する、3D ポイント クラウドとして新しいオブジェクトを作成する、ビデオでモーション パターンをモデル化する
- 年齢とともに変化する人の姿を見せる
- DNN 分類器の拡張などのデータ拡張
- マップ内の欠落しているフィーチャの修復、ストリート ビューの改善、マッピング スタイルの転送など
- 画像の生成、画像検索システムの置き換えなど
- GAN バリエーションを使用して非線形動的システムへの制御入力を生成する
- 気候変動が住宅に与える影響を分析する
- 声を入力として人の顔を作成する
- 癌、線維症、および炎症におけるいくつかのタンパク質標的のための新しい分子を作成します
- 通常の画像から GIF をアニメーション化する
GAN はさまざまな分野でさらに多くのアプリケーションがあり、その用途は拡大しています。 ただし、その誤用の例も複数あります。 GAN ベースの人間の画像は、偽のビデオや画像の作成など、悪意のあるユースケースに使用されてきました。
GAN は、ソーシャル メディア上で地球上に存在したことのないリアルな写真や人々のプロフィールを作成するためにも使用できます。 GNA の悪用に関するその他の懸念事項としては、注目の人物の同意を得ずにフェイク ポルノを作成したり、政治家候補の偽のビデオを配布したりすることなどが挙げられます。
GNA は多くの分野で恩恵をもたらす可能性がありますが、その誤用は悲惨な結果をもたらす可能性もあります。 したがって、その使用には適切なガイドラインを適用する必要があります。
結論
GAN は、現代技術の顕著な例の 1 つです。 データを生成し、視覚診断、画像合成、研究、データ拡張、芸術と科学などの機能を支援するためのユニークで優れた方法を提供します。
また、革新的なアプリケーションを構築するためのローコードおよびノーコードの機械学習プラットフォームにも興味があるかもしれません。