
パッセージインデックス:Googleの新しいランキングアルゴリズム
公開: 2022-05-09検索エンジンの巨人がランキング要素であるPassageIndexingを展開したため、Googleの検索エクスペリエンスは2021年から新しい展望に到達します。
新しいランキングテクノロジーは、2021年2月11日に正式に公開されました。公開の正式な確認は、GoogleSearchLiasonTwitterアカウントから行われました。
更新:英語での米国でのクエリについて、太平洋時間の昨日の午後にパッセージランキングが開始されました。 近い将来、英語でより多くの国に、そしてその後他の国や言語に来るでしょう。 これらのさらなる起動が発生したときに、このスレッドを更新します。
— Google SearchLiaison(@searchliaison)2021年2月11日
[adrotatebanner =” 3”]
パッセージインデックスアルゴリズムとは何ですか?
パッセージインデックスは、ユーザーの検索クエリに基づいて検索結果のページ内の個々のパッセージをランク付けできる、Googleのアルゴリズムで使用される新しいテクノロジーです。
Googleが2019年9月にBERTについて行った発表を覚えていますか? 彼らは、BERTが英語の検索クエリの10%に影響を与えると述べました。 信じられないかもしれませんが、実際には99%以上のクエリに影響を与えています。
パッセージインデックスは、Googleクローラーがコンテンツ内の特定のパッセージの関連性を理解し始めるのと同様に、検索結果ページに波及効果をもたらします。
Passage Indexingと呼ばれていますが、Googleの現在のインデックス作成プロセスで発生する大きな変更はありません。 ただし、新しいテクノロジーはランキングとより関係があります。
つまり、これが文字通り意味するのは、オフページSEOについて書かれた長い形式のコンテンツがあり、オフページSEO戦略のそれぞれについて個別のパッセージがある場合、Googleは検索クエリに一致するコンテンツの個々のセクションをランク付けするようになります。
Googleは創業以来、検索結果の関連性とコンテキストを改善する方向に進んでいます。 これで、コンテンツとリンクという2つの主要なランキング要素が、関連性を追加した場合にのみ価値があることがわかります。

Passage Indexに関するGoogleの公式発表によると、検索アルゴリズムは、ページ内のコンテンツの関連性を最も詳細なレベルで理解するようになります。
これは、検索クエリに関連する回答がページ内に深く埋め込まれている場合でも、Googleがその特定のパッセージを選択できることを意味します。 検索の巨人は、「あなたが探している干し草の山の針の情報」を見つけることができるようになったと言います。
Passage Indexは、世界中の検索クエリの7%に影響を与えます。 目の前にBERTの例があるので、その割合は1年以内に指数関数的なレベルに達するはずです。
パッセージインデックスは、表示されないランキングに焦点を当てています
PassageIndexingの概念を簡単に理解できるようにしましょう。
まず第一に、Passage Indexingは、Googleが結果を表示する場所に関するものではありません。 これは、Googleがページ内の個々のパッセージを理解できるようにする追加のランキング要素です。
パッセージランキングは表示ではありません。 スニペットがどういうわけか長くなることはありません。 それは、他のランキング要素に*追加*して、テキストのパッセージのコンテキストを理解することによって、ページが何であるかをよりよく理解することです。
— Danny Sullivan(@dannysullivan)2020年12月29日
つまり、これが意味するのは、PassageIndexingがBERTまたはLinkAnalysisアルゴリズムとまったく同じになるということです。 これは、他のランキング要素と連携して機能し、SERPの全体的なルックアンドフィールに大きな変更を加えることなく、ユーザーにより良い結果をもたらします。
パッセージインデックスについての混乱は、グーグルの終わりからの悪い例のために引き起こされました、そして、ダニーサリバンは彼のツイートの1つでこれを確認しました。
これは、通常のスニペットと注目のスニペットを比較するため、悪い例です。 パッセージランキングなしで、現在注目のスニペットになる通常のリストは、そのように見えます。
— Danny Sullivan(@dannysullivan)2020年12月29日
PassageIndexingAlgorithmがどのように機能するかを理解するための興味深い例を次に示します。
複数の章がある本としてランク付けするページを検討してください。 これまで、Googleはあなたがカバーしたメイントピックに基づいて本をランク付けしていました。
しかし、Passage Indexingを使用すると、Googleは書籍内の個々の章を理解します。 つまり、これが意味するのは、検索時に関連性の高いクエリが入力されると、個々のチャプター(ページのセクション)が結果に表示されるということです。
これは、ページをパッセージインデックスに適したものにするために、現時点では何もする必要がないことを意味します。これは、内部ランキングの変更に近いためです。
ただし、コンテンツを構造化すると、GoogleのPassageIndexingアルゴリズムがテキストの意味をよりよく理解しやすくなる場合があります。
したがって、複数の小見出しを含む長い形式のコンテンツを作成している場合で、これらの記事への有機的な牽引力が見られない場合は、PassageIndexingが役立ちます。
以前は、メイントピックが広範囲にわたる可能性があるため、詳細なコンテンツを含むページはランク付けできませんでした。
しかし、Passage Indexingを使用すると、このような長い形式のページを、コンテキストに関連する関連クエリにランク付けできるようになりました。
そのため、eコマースWebサイトを運営している場合、コンテンツは通常、要領を得ているため、製品ページはPassageIndexingのメリットを享受できない可能性があります。
パッセージインデックスアルゴリズムはどのように機能しますか?
パッセージインデックスは、クロールとインデックス作成のプロセスを変更しませんが、Googleがページ内のパッセージの意味を理解するのに役立ちます。
これは、Googleが個々のパッセージを個別にインデックス化しないことを意味します。 Googleは、クエリが入力されるたびに、関連性と意味に基づいて、結果に最も適切なパッセージを表示します。
ロングテールの質問ベースの検索クエリをグーグルですばやく検索すると、ウェブサイトのリストを含む結果が表示される場合があります。 しかし、あなたが望むのはあなたの質問に対する具体的な答えであり、Googleは以前は提供できませんでした。
ただし、Passage Indexingアルゴリズムを使用すると、Google検索でクエリに最も関連性の高い回答が取得されます。
興味深いことに、回答を提供するページには長い形式のコンテンツが含まれている可能性がありますが、Googleは、最もコンテキストに関連する回答を表示することで時間を節約します。
PassageIndexingに関するGoogleの公式の言葉は次のとおりです。
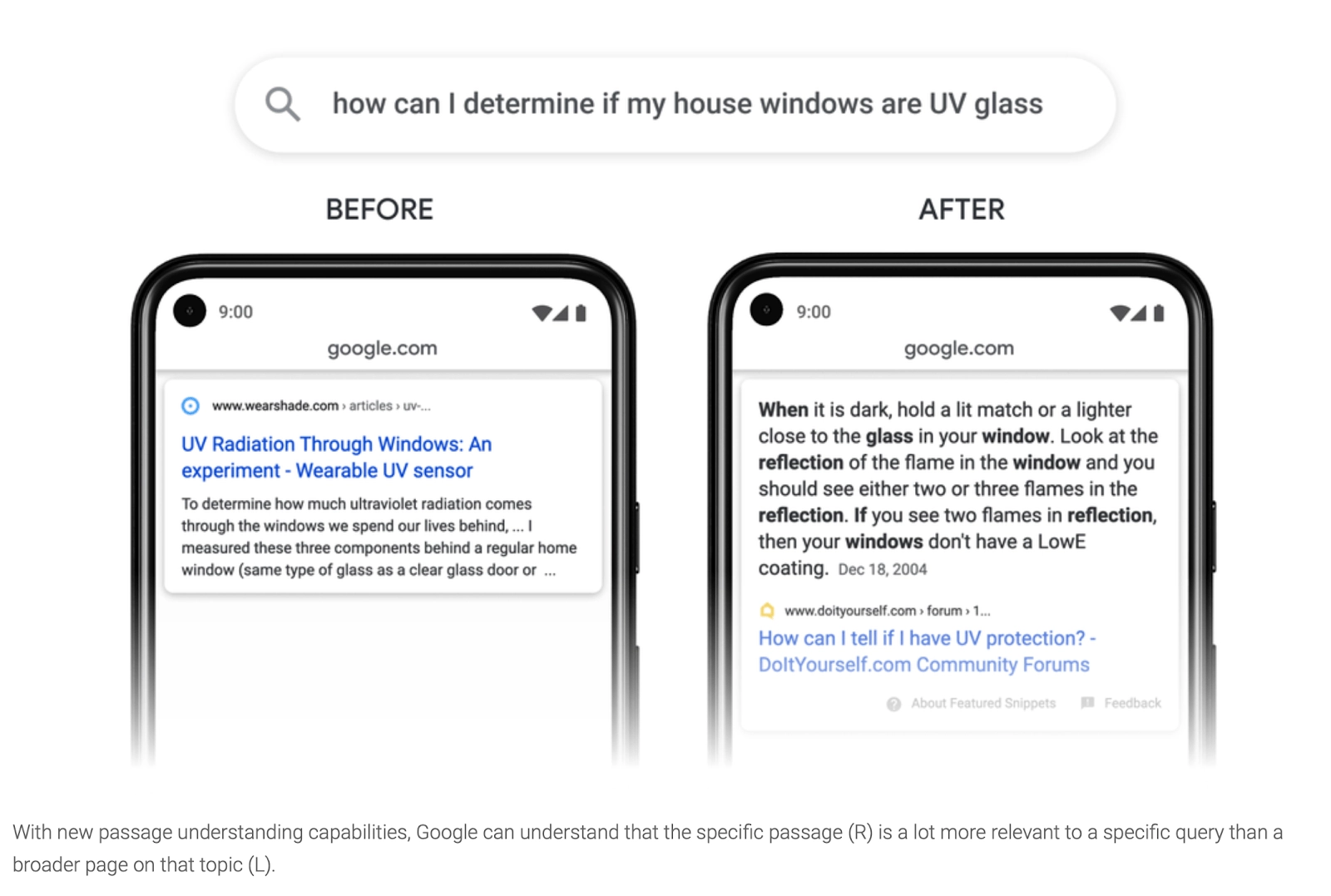
たとえば、「家の窓がUVガラスであるかどうかをどのように判断できますか」のようなかなりニッチなものを検索するとします。 これはかなりトリッキーなクエリであり、UVガラスと特別なフィルムがどのように必要かについて説明しているWebページがたくさんありますが、これは素人が行動を起こすのに本当に役立ちません。 私たちの新しいアルゴリズムは、質問に答えるDIYフォーラムのこの1つのパッセージにズームインできます。 どうやら、炎の反射を使用して、あまり役に立たないページ上の残りの投稿を伝えて無視することができます。

Googleはページの一部をインデックスに登録するだけですか?
Googleの関係者は、PassageIndexが通常のページインデックスに取って代わることはないことを確認しています。 これは、Googleのクローラーが引き続きページを完全にインデックスに登録することを意味しますが、これを行うと、コンテンツとコンテンツ内の各パッセージの意味を理解しようとします。
これは、Googleがページをインデックスに登録する方法の変化を示しているわけではありません。 それでも、既存のプロセスに別のレイヤーが追加され、もちろん、ページのランキングが変更されます。
SEOに関する限り、これは大きな問題です。これは、インデックスの変更ではなく、Passage Indexingアルゴリズムによって、ランキングと結果の表示方法にパラダイムシフトがもたらされるためです。
注目のスニペットとパッセージインデックスの違い
Googleによると、注目のスニペットの結果は、全体的なトピックの関連性があるページからのパッセージです。
ただし、Passage Indexingは、ページの全体的な関連性を考慮せず、検索クエリへのパッセージの関連性のみを考慮します。
GoogleのDannySullivanも、同じことわざについてツイートしました。「注目のスニペットは音声検索に使用されます。 それらは、パッセージとは異なるシステムを使用してすでに識別されています。」
注目のスニペットは音声検索に使用されます。 それらは、パッセージとは異なるシステムを使用してすでに識別されています。
— Danny Sullivan(@dannysullivan)2020年10月21日
GoogleはパッセージインデックスにSMITH言語処理を使用していますか?
BERTについては、検索と個々のページの両方で長いクエリを理解できると聞いています。 しかし今、グーグルはコードネームSMITHであるメガロドンを解き放ったようだ。
SMITHは、Siamese Multi-depth Transformer-based Hierarchical(SMITH)Encoderの略で、申請された新しい自然言語処理特許です。
この新しい言語処理モデルは、Googleアルゴリズムにページ内のパッセージを理解させることを目的としています。
これで、PassageIndexingが近い将来どのように機能するかについてのGoogleのロードマップがわかりました。
GoogleによるSMITHに関するドキュメント共有では、言語処理システムはニュース記事、関連記事、そして重要なことにドキュメントのクラスタリングを推奨するのに役立ちます。
ドキュメントクラスタリングに関する3番目のポイントは、パッセージインデックスに直接関連しているため、重要な側面です。
また、SMITHは長い形式のドキュメント照合システムであり、GoogleによるSearch Onの発表と、長い形式のコンテンツがPassageIndexingからどのように恩恵を受けるかについてのDannySullivanからのツイートを示しています。
これがどのように機能するかは、BERTとほぼ同じです。 BERTはマスクされた単語言語モデリングを使用しますが、SMITHは文のブロックをマスクすることでこれを強化します。
Googleによると、「長い形式のドキュメントマッチングに関するいくつかのベンチマークデータセットに関する実験結果は、提案されたSMITHモデルが、階層的注意、マルチ深度注意ベースの階層型リカレントニューラルネットワークなど、以前の最先端モデルよりも優れていることを示しています。とBERT。」
SMITHとBERTを比較すると、前者はより多くの単語を処理する機能を備えており、Googleによれば、これはドキュメントを照合する機能を向上させるのに役立ちます。
「BERTベースのベースラインと比較して、私たちのモデルは最大入力テキスト長を512から2048に増やすことができます」とGoogleの特許は述べています。 BERTの最大入力テキスト長は512ワードであることに注意する必要があります。
これがSMITHの実行方法です。
ステップ1:ドキュメントはいくつかの文のブロックに分割されます
ステップ2:言語処理トランスフォーマーは、各文ブロックのコンテキスト表現を学習します。
ステップ3: BERTの慣例に従うことにより、文ブロック全体がコンテキストで表されます。
ステップ4:一連の文ブロック表現が与えられると、ドキュメントレベルのトランスフォーマーは各文ブロックのコンテキスト表現と最終的なドキュメント表現を学習します。
憶測:コンテンツ最適化2.0に入っていますか?
Passage Indexingは、Googleが検索結果を表示する方法を変えるでしょう。そして、今後数日でSEOのためにやるべきことがたくさんあるようです。
Googleは、メタタイトルと見出しタグをコンテンツのコンテキストを理解するための重要なシグナルと見なしています。 しかし、それは彼らがパッセージインデックスを開始するまででした。
パッセージインデックスを使用すると、Googleはパッセージの意味を個別に理解することでページのインデックス作成を開始しました。 その結果、個々のパッセージが関連する検索クエリに対してランク付けできるようになりました。
さらに興味深いのは、ページで関連性の低いトピックについて説明している場合でも、ユーザーのクエリに対する回答がいずれかのパッセージ内に埋め込まれていると、そのページが検索に表示されることです。
Google社員とのパッセージインデックスに関するさまざまな議論を見ると、パッセージインデックスがより大きな影響を与えることは明らかです。
たとえば、後で述べたOfficeHourのディスカッション中にPassageIndexingの結果が注目のスニペット領域に表示される場合がありますが、時間の経過とともにPassageIndexingによって通常の検索結果が決まります。
ジョンは言った:
そのため、最初に注目のスニペットにこれらを表示し始める可能性があります。これは、その例を示したかどうかがわからないため、またはこれがこれを確認できる最も明確な方法である可能性があります。 そして、ある時点で、通常の検索結果にもそれらを表示し始めます。
これは、Googleがメタディスクリプションをかなり前から軽視しており、PassageIndexingがメタディスクリプションに表示される内容を今後制御する可能性が高いことを知っているため、大きな声明です。
これに加えて、私は個人的に、メタディスクリプションの文字数制限がパッセージ全体に対応するために増加するとは思いません。 代わりに、Googleが行う可能性があるのは、注目のスニペットの結果にすでに実装されているテキストへのスクロール機能をメタディスクリプションに拡張することです。
このようにして、ユーザーは自分の質問に答えるページ内の正確な箇所に移動できます。 ただし、広告収入に依存している場合、ユーザーがそうであるように、この機能は収入に大きな打撃を与えるでしょう。
これがすぐに実現するもう1つの理由は、Googleには、SERP機能を大規模に展開する前に、小規模でテストしてきた歴史があるためです。
注目のスニペットとテキストへのスクロール機能の代わりに表示されるパッセージのインデックス作成結果の現在の例は、分析の一部として宣伝して、ユーザーにとってどれほど有用かを理解することができます。
PassageIndexingが注目のスニペットに対してより良い回答をもたらすかどうかに関するGlennGabeの質問に対するジョンの答えは、PassageIndexingがGoogleにとってどれほど重要であるかということ自体の啓示です。
ジョンが答えたものは次のとおりです。
ですから、私の内部情報を使って、一歩下がってこれを推測します。 通常、これらの処理で発生するのは、特定の場所に展開し、少し実験して、これらを最適に実装する方法、最適に機能する方法を見つけ、それをもう少し広く展開する方法を見つけることです。
しかし、検索におけるこれらの新しい変更のすべてと同じようなものです。 通常、私たちはそれらを小規模で試し、その後少しずつ大きく展開します。
GoogleがPassageIndexingを注目のスニペット領域に制限するかどうかにかかわらず、ゼロクリッククエリの数が増える可能性があります。
これは、ユーザーがSERPでコンテキストに関連する最高の情報を取得しており、コンテンツをキュレートしたWebサイトにアクセスする必要がないために発生します。
したがって、Passage Indexingが公開されたら、受け取ったインプレッションとクリックを注意深く監視してください。 また、検索コンソールがパッセージインデックスの拡張機能を追加し、新しい機能から生成されたクリックを紹介する可能性が高くなります。
これが意味することは、SEOがキーワードに集中するのをやめ、トピックの関連性と決定性により多くの推進力を与えることができるということです。
ユーザーの懸念を理解し、コンテンツソリューションでそれらに対処することは、PassageIndexの展開後のWebサイトの成功に大きな役割を果たします。
私が言いたいのは、ある特定のトピックについて全体論的なアプローチをとる長い形式のコンテンツは、新しいパッセージインデックスアルゴリズムの恩恵を受けるチャンスがあるということです。
Googleの自然言語処理アルゴリズム– BERTのおかげで、各パッセージの意味と関連性を理解することは、検索エンジンの巨人にとってもはや面倒な作業ではありません。
グーグルが思いついたアルゴリズムと機能を見ると、それらがどのように機能するか、そして特定の検索クエリに対して可能な限り最高の結果をユーザーに提供するというグーグルの純粋な目標を達成するためにそれらがどのようにサポートするかを見ることができます。
[adrotatebanner =” 4”]