
Import CSV do migracji Drupala 7 do 8 — kompletny przewodnik
Opublikowany: 2020-02-11Migracja Drupala 7 do 8 nie jest nudna, ponieważ istnieje tak wiele sposobów na przeprowadzenie migracji! W zależności od złożoności projektu możemy dobrać technikę, która najbardziej mu odpowiada. To, o czym będziemy rozmawiać na tym blogu, to migracja zawartości i konfiguracji z Drupala 7 do Drupala 8 przy użyciu metody importu CSV.

Drupal udostępnia różne moduły do importowania danych z różnych źródeł, takich jak JSON, XML i CSV. System API migracji rdzenia Drupal 8 oferuje cały zestaw interfejsów API, które zasadniczo mogą obsłużyć każdy rodzaj migracji z poprzedniej wersji Drupala do Drupala 8.
Niektóre prace przygotowawcze przed migracją Drupal 7 do 8
Aby przeprowadzić migrację z Drupala 7 do Drupala 8 za pomocą importu CSV, będziemy potrzebować tych modułów.
Moduły Drupala 7 -
Widoki Eksport danych : Ten moduł musi być zainstalowany na naszej stronie Drupal 7. Moduł eksportu danych widoków pomaga w eksporcie danych w formacie CSV.
Wyświetl pole hasła : Ten moduł pomaga w migracji haseł, które wysyłają hasła w formacie zaszyfrowanym.
Moduły Drupala 8 -
Migrate – Moduł Drupal 8 Migrate pomaga w wydobywaniu danych z różnych źródeł na Drupa 8.
Migrate Plus – Ten moduł Drupal 8 pomoże w manipulowaniu zaimportowanymi danymi źródłowymi
Migrate Drupal – Ten moduł oferuje wsparcie w migracji treści i konfiguracji do Drupala 8.
Migrate source CSV – ten moduł oferuje wtyczkę źródłową, która może migrować encje i zawartość do Drupal 8 z plików .csv.
Migrate Tools – ten moduł Drupal 8 pomaga, oferując narzędzia UI/polecenia Drush do zarządzania migracjami.
Moduł rozwoju konfiguracji – Ten moduł pomaga w imporcie plików konfiguracyjnych do Drupala 8.
Niech rozpocznie się migracja do Drupala 8!
Najpierw musimy stworzyć niestandardowy moduł dla naszej migracji do Drupala 8 . Nazwijmy ten moduł jako test_migrate . A wiemy, że po stworzeniu niestandardowego modułu musimy stworzyć plik info.yml .
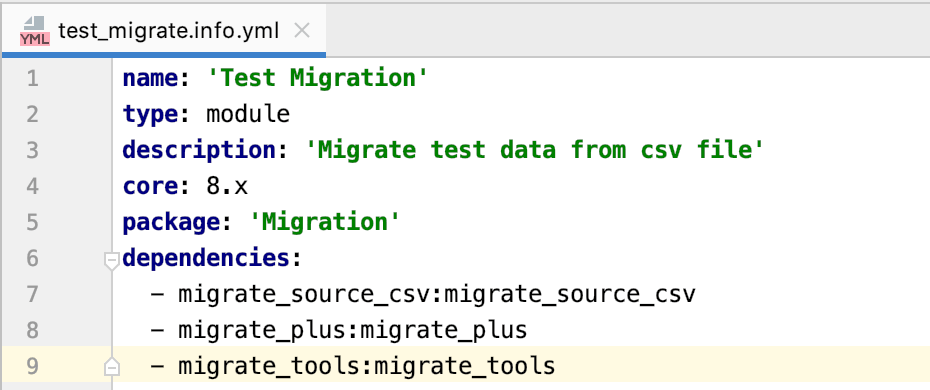
Powyższy zrzut ekranu pokazuje klucze wymagane do pliku info.yml .
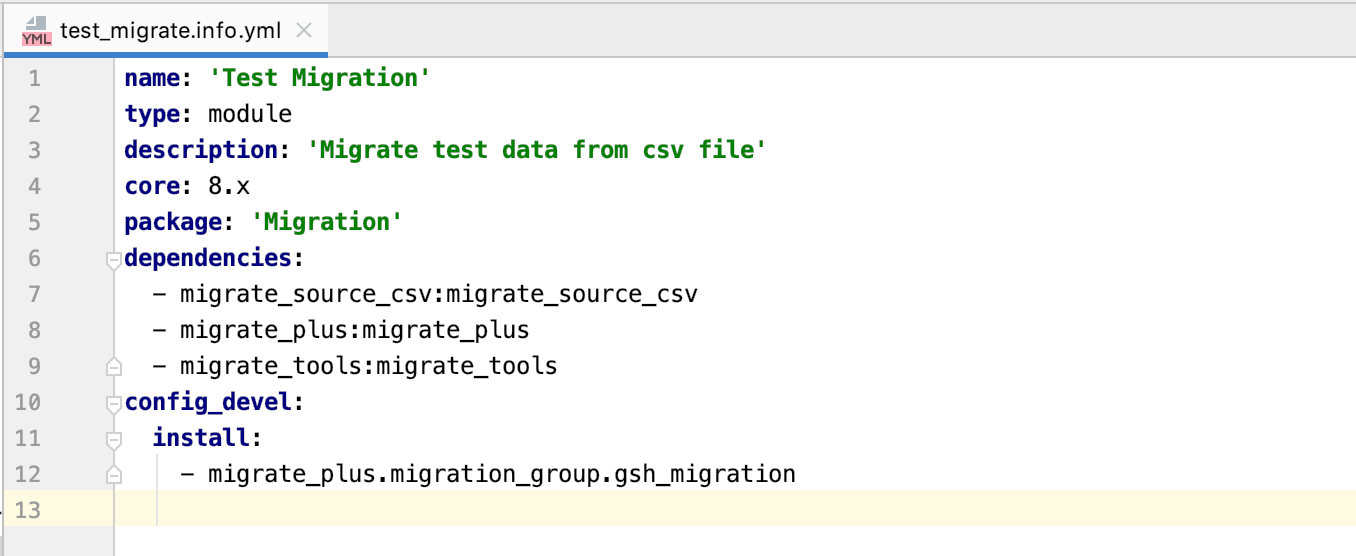
Po utworzeniu pliku info.yml musimy utworzyć grupę migracji do migracji. Tę grupę migracji należy utworzyć w ścieżce: test_migration > config > install . Nazwa grupy powinna brzmieć migrate_plus.migration_group.test_migration.yml .

Powyższy zrzut ekranu przedstawia strukturę folderów do utworzenia grupy migracji.
Wewnątrz pliku migrate_plus.migration_group.test_migration.yml musimy wpisać id, etykietę i opis grupy migracji, która jest pokazana na poniższym zrzucie ekranu.

Po utworzeniu grupy migracji musimy ją zainstalować w naszym pliku info.yml .
Teraz napiszemy skrypt migracji dla typów Użytkownicy, Termin taksonomii, Paragrafy, Treść. Pamiętaj, że migrujesz w tej samej kolejności, ponieważ między tymi podmiotami będzie połączenie. Na przykład treść będzie tworzona przez konkretnego użytkownika - więc najpierw musimy przeprowadzić migrację użytkowników, a po tej taksonomii typ treści.
Napiszmy teraz skrypt w pliku yaml do migracji użytkowników. Tak więc, aby napisać migrację użytkowników, potrzebujemy pliku yaml użytkownika o nazwie migrate_plus.migration.test_migration_users.yml a skrypt do migracji pokazano poniżej.
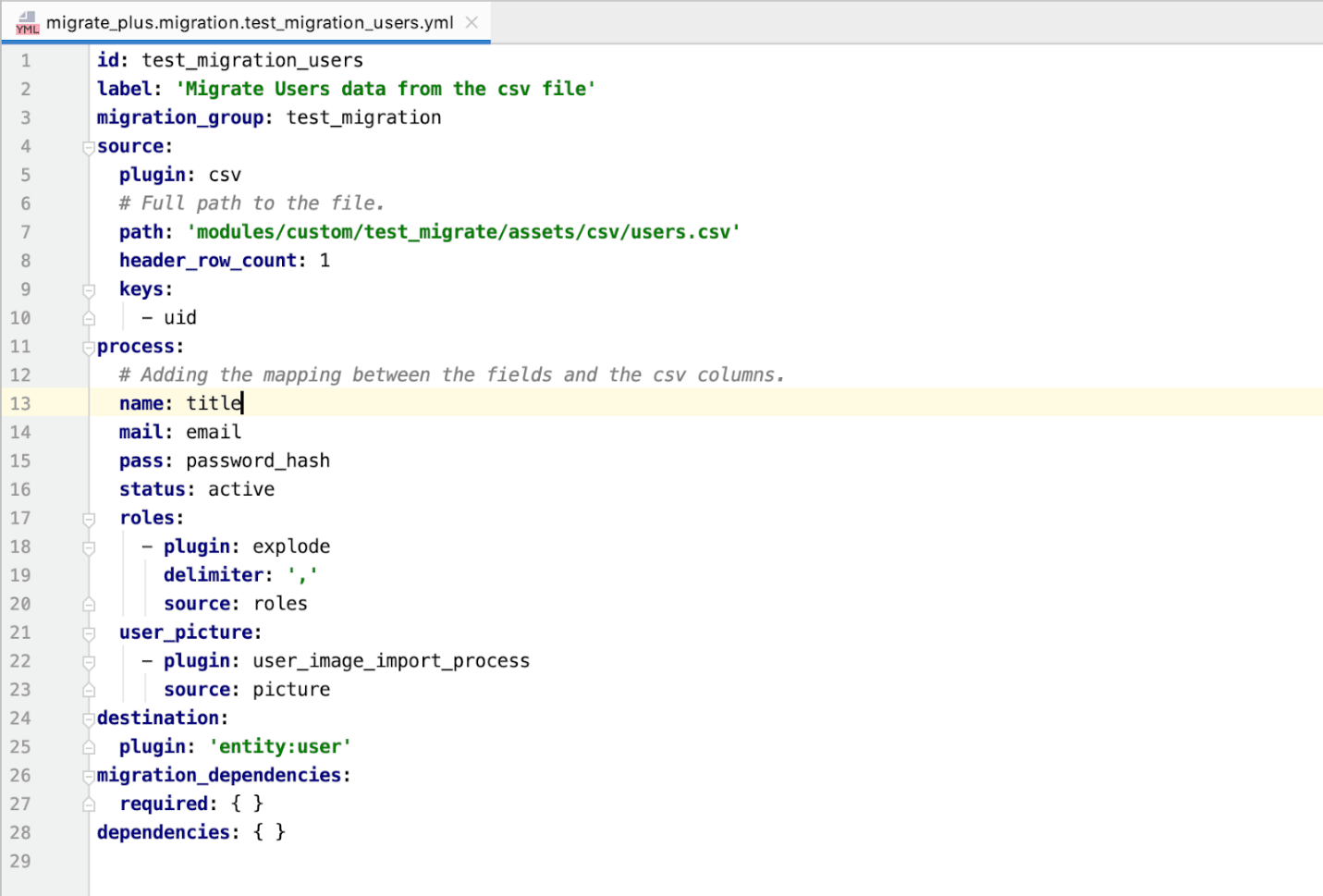
Są to klucze wymagane do migracji tutaj źródłowego pliku csv, który musimy przenieść. Pliki Csv należy umieścić w ścieżce asset > csv > user.csv . Users.csv jest również pokazany poniżej.


Ścieżka — wskazuje ścieżkę do pliku csv.
header_row_count - Daje liczbę wierszy, która jest nagłówkiem konkretnej kolumny.
Klucze - które powinny być unikalne dla każdego rzędu.
Proces - W tym mapowaniu plików csv do pól.
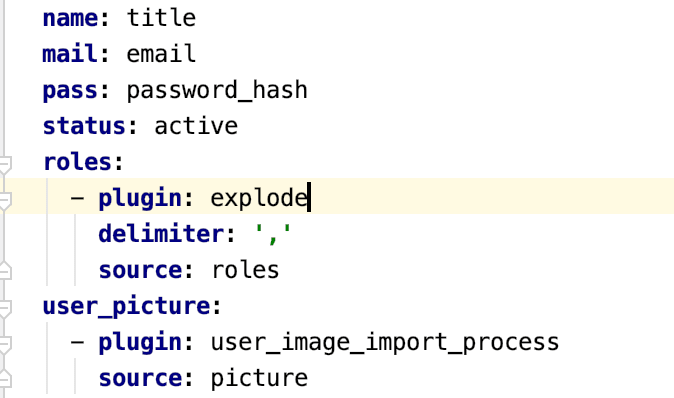
Powyższy obrazek pokazuje mapowanie między polami a csv. Tutaj nazwa jest nazwą komputera w polu nazwy użytkownika, a tytuł jest tytułem kolumny csv. Jeśli mamy wiele danych dla jednego pola, używamy ograniczników. Użytkownicy mogą mieć wiele ról, w takim przypadku piszemy tak, jak pokazano na powyższym obrazku.
Obrazy są migrowane przez napisanie niestandardowej wtyczki. Wtyczkę niestandardową można napisać w ścieżce src > plugin > migrate > process . Na powyższym obrazku widać, że proces user_image_import_process to niestandardowa wtyczka napisana do migracji obrazów użytkowników.

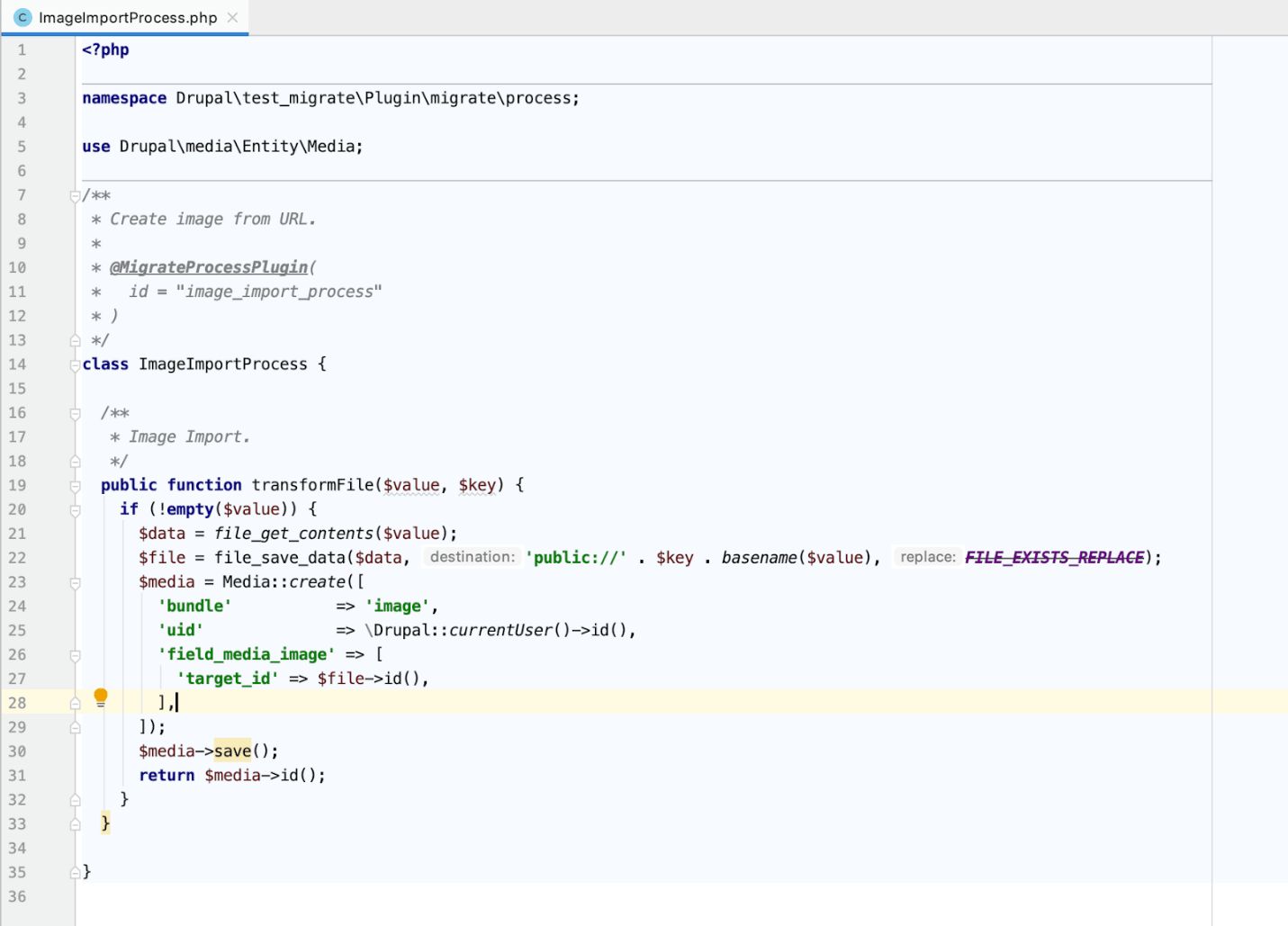
Wewnątrz UserImportProcess.php piszemy funkcję, która skopiuje obraz i zapisze go w miejscu docelowym. Skrypt jest pokazany na obrazku poniżej.

Aby określić, gdzie powinny być zapisywane obrazy, napiszemy jeszcze jedną funkcję ImageImportprocess . W tej funkcji wymienimy nazwę maszyny obrazu.
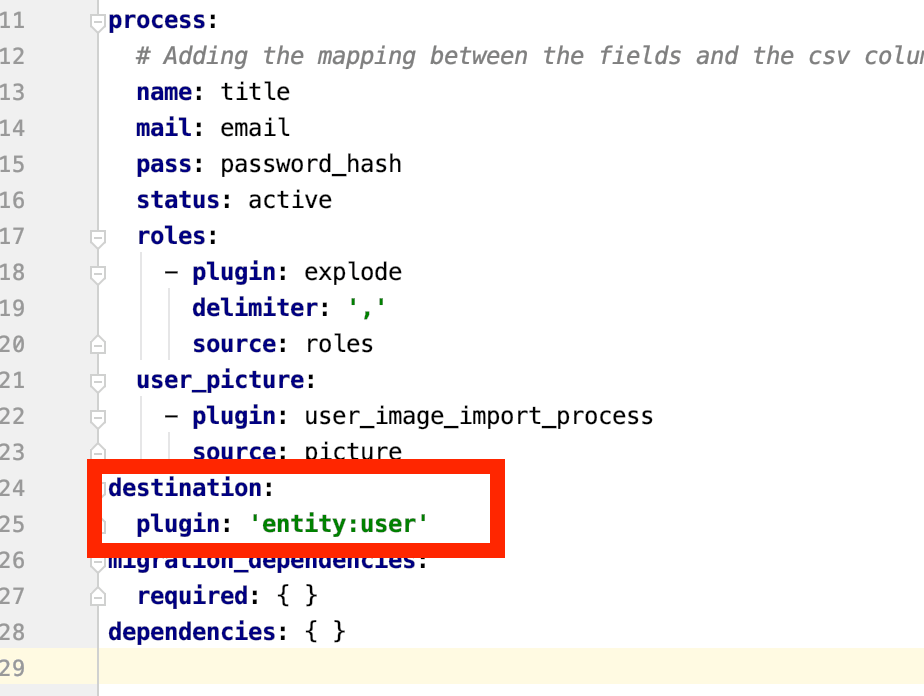
W pliku users info.yml znajduje się sekcja docelowa, która wskaże, gdzie mają być przechowywane migrowane dane i która jest encją. Jest to zaznaczone na poniższym obrazku.
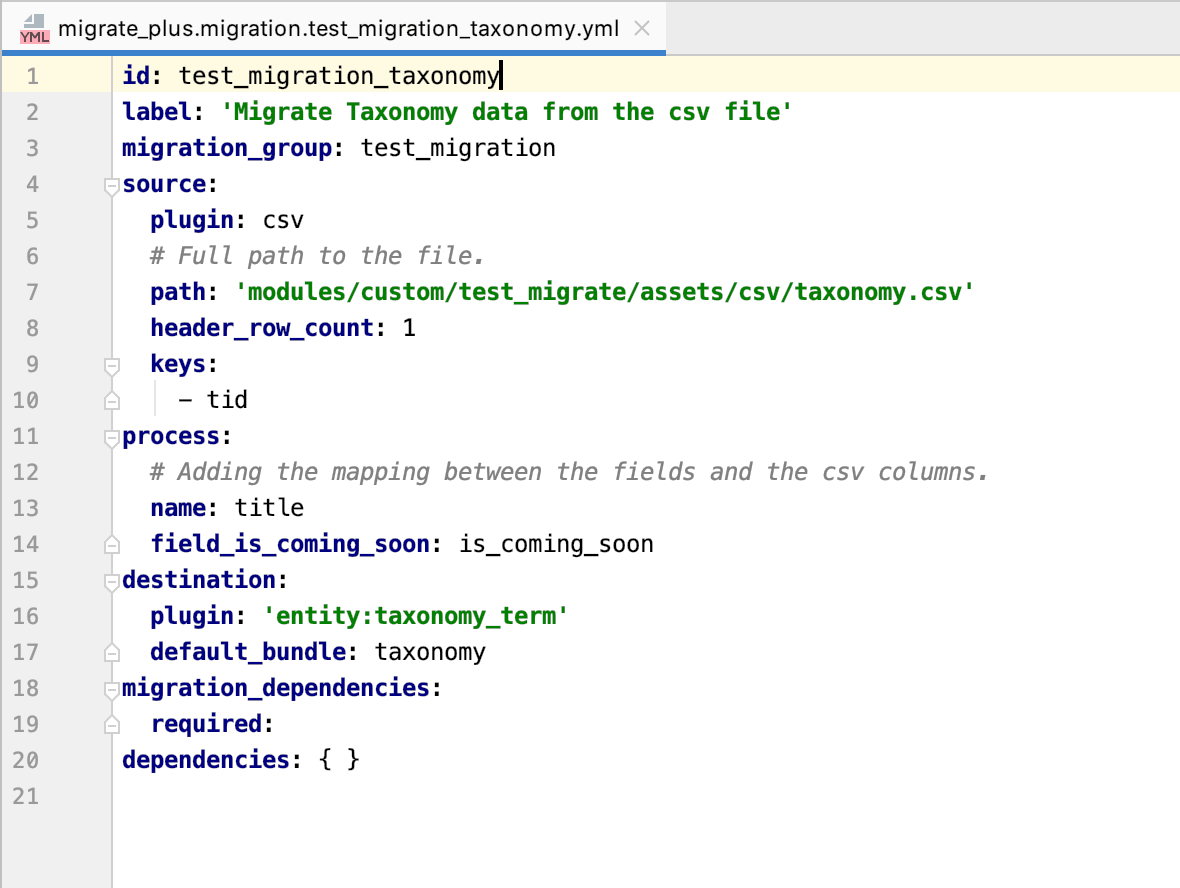
Po utworzeniu kodu dla użytkowników musimy napisać yaml dla terminów taksonomii. Zauważ, że jeśli masz tylko pole tytułu w swojej taksonomii, nie musisz pisać oddzielnego pliku yaml. Jeśli masz wiele pól w terminach taksonomii, musisz napisać osobny plik yaml. W terminologii taksonomicznej będziemy mieli tid jako kluczowy, ponieważ tid będzie unikalny dla każdego terminu.
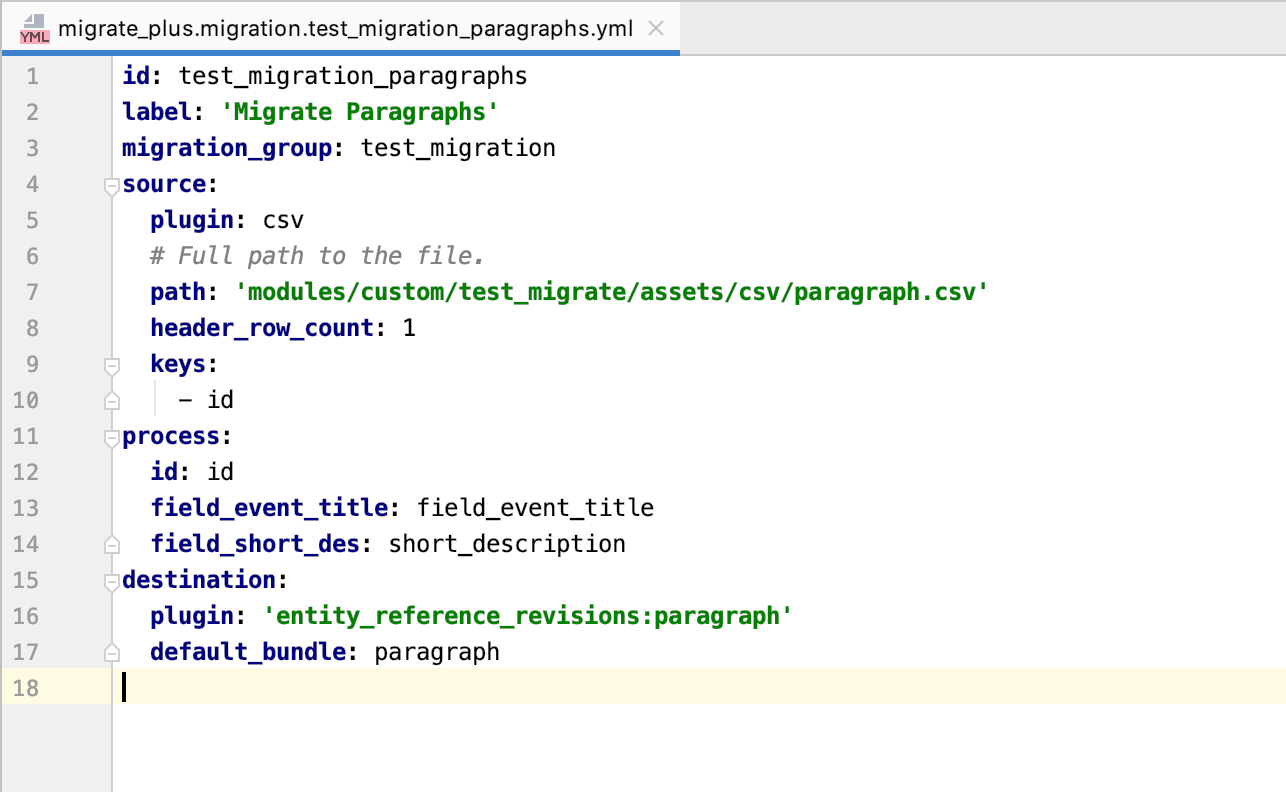
Następnie przeniesiemy akapity. W tym celu musimy stworzyć osobny plik yaml. Kod do migracji pokazano na poniższej ilustracji.
Na koniec przeprowadźmy migrację typu zawartości. Plik yaml dla typu zawartości jest pokazany w poniższym kodzie.
label : 'Przenieś dane typu treści z pliku csv'
Migration_group : test_migration
źródło : id : test_migration_content

wtyczka : csv
# Pełna ścieżka do pliku.
ścieżka : 'modules/custom/test_migrate/assets/csv/content.csv'
header_row_count : 1
klawisze :
- nid
proces :
# Dodanie mapowania między polami a kolumnami csv.
tytuł : tytuł
promować : promowana_na_stronę_główną
lepkie : lepkie
field_display_name : display_name
field_marketing_tagline : marketing_tagline
taksonomia_polowa :
wtyczka : entity_lookup
źródło : Taksonomia
entity_type : taksonomia_term
klucz_pakietu : vid
pakiet : taksonomia
klucz_wartości : nazwa
ciało/wartość : ciało
treść/format :
wtyczka : wartość_domyślna
default_value : "pełny_html"
field_paragraph :
- wtyczka : eksploduj
ogranicznik : "|"
źródło : fcid
- wtyczka : skip_on_empty
metoda : proces
- wtyczka : migration_lookup
migracja : test_migration_paragraphs
no_stub : prawda
- wtyczka : iterator
proces :
identyfikator_docelowy : '0'
target_revision_id : '1'
miejsce docelowe :
wtyczka : 'jednostka:węzeł'
default_bundle : zawartość
migracja_zależności :
wymagane :
- test_migration_paragraph
- test_migration_taksonomia
zależności : { }
Po zapisaniu wszystkich plików yaml migracja test_migrate.info.yml będzie zawierać poniższe instalacje.
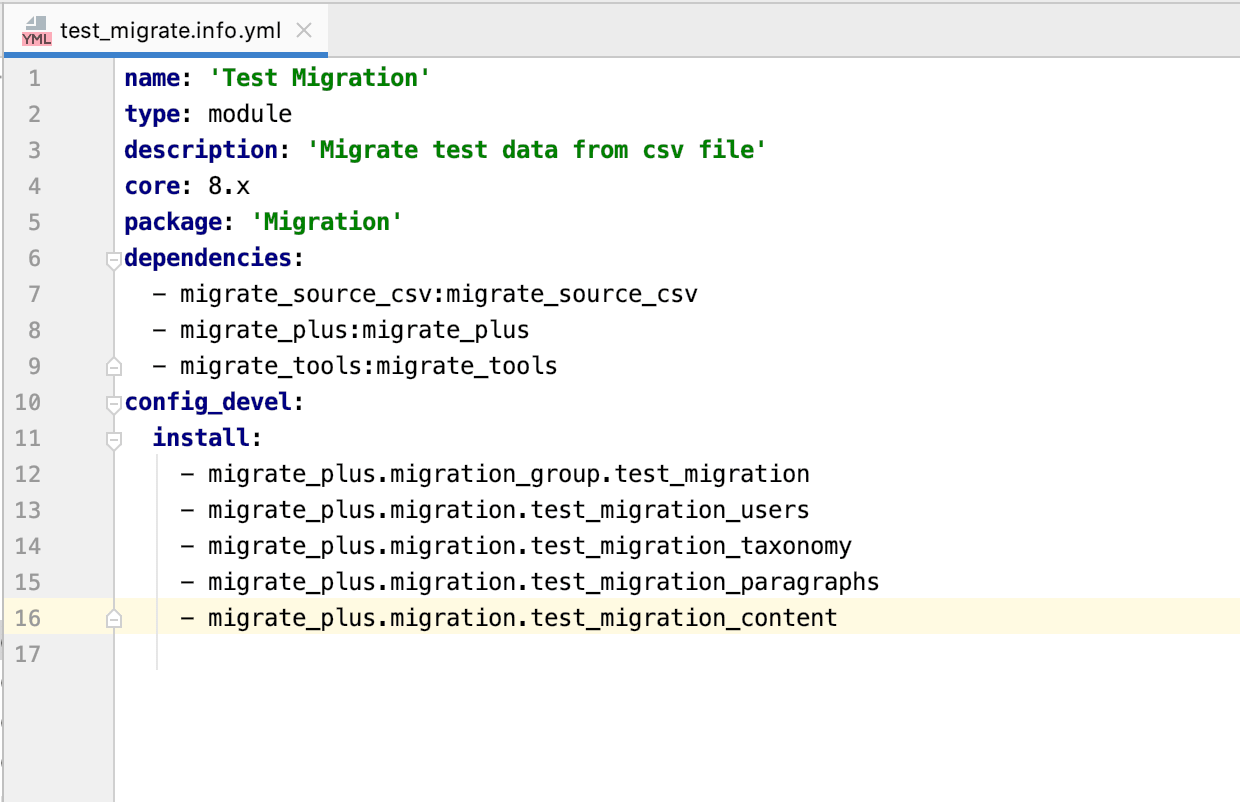
Po wykonaniu wszystkich tych kroków przejdź do swojej witryny i zainstaluj niestandardowy moduł.

Następnie przejdź do swojego projektu w terminalu i uruchom to polecenie „drush ms”, aby sprawdzić stan migracji, jak pokazano na poniższym obrazku.

Aby przeprowadzić migrację, użyj polecenia drush mim migration-id . Na powyższym obrazku widzimy identyfikator migracji.
Po zakończeniu, jeśli sprawdzisz stan migracji, zobaczysz liczbę przeniesionych elementów.
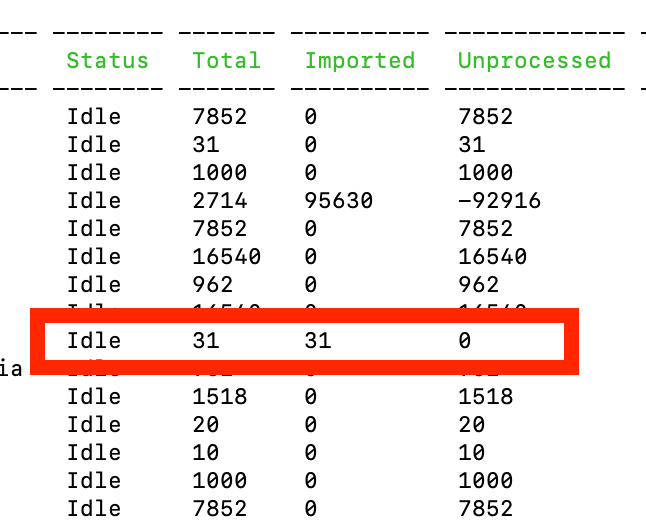
Teraz możesz zaobserwować, że cała zawartość jest migrowana. Jeśli wystąpi jakikolwiek błąd w migracji danych, proces zakończy się w tej konkretnej instancji. Sprawdź problem z tą zawartością, a następnie ponownie uruchom migrację.
Rzeczy do zapamiętania
Jeśli migracja zostanie przerwana pomiędzy procesem, status migracji będzie wyświetlany jako „importowanie”. Aby zmienić stan na bezczynny, musisz uruchomić polecenie drrush mrs migration-id . Następnie uruchom polecenie drush mim migration-id
Jeśli chcesz wycofać migrowaną zawartość, uruchom polecenie drush mr migration-id
Jeśli zmieniłeś coś w kodzie po rozpoczęciu procesu migracji, upewnij się, że uruchomiłeś polecenie drush cdi test_migration . To polecenie pomoże Ci odzwierciedlić zmiany podczas migracji. Po zakończeniu dokładnie sprawdź swoją witrynę, aby sprawdzić, czy cała zawartość została przeniesiona.