
Jak Google może mapować zapytania graficzne
Opublikowany: 2020-01-14Mapowanie zapytań graficznych w Google
Wiele osób ma w sobie telefony z aparatami. Wygląda na to, że wyszukiwanie za pomocą zdjęć stałoby się bardziej popularne. Niedawny patent Google dotyczy wyszukiwania za pomocą obrazów, przyznany w listopadzie ubiegłego roku.
Zachowałem patent, aby o nim pisać, ponieważ pisałem o innych podejściach Google dotyczących wyszukiwania grafiki. Google stara się lepiej zrozumieć, jakie obrazy mogą zawierać.
Pisałem w zeszłym roku o dodawaniu przez Google kategorii semantycznych z ontologiami do wyników wyszukiwania grafiki. W tym poście etykiety wyszukiwania grafiki Google stają się bardziej semantyczne?
Wyobraź sobie moje zdziwienie, gdy szukałem [jaguar] i spodziewałem się, że w wynikach wyszukiwania kotów, takich jak Google, zobaczę jakieś obrazy w wynikach wyszukiwania uniwersalnego. Używali mieszanych wyników, które pokazywali, w celu uwzględnienia obrazów, wiadomości, lokalnych, filmów i wyników wyszukiwania w Internecie. Wyniki dla [jaguar] obejmowały koty i samochody, pokazujące nad nimi kategorie związane z wyszukiwaniem [jaguar] i ontologię związaną z tym wyszukiwaniem:
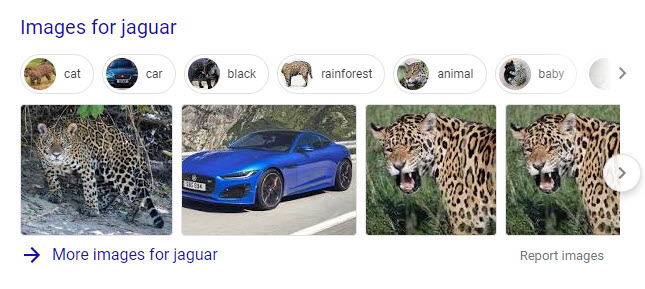
W ramach tego nowego patentu ktoś może wyszukiwać za pomocą obrazu – ze zdjęcia lub na swoim komputerze.
Firma Google wydała aplikację o wyszukiwaniu fotografii – Google Lens.
Google Lens rozpoznał, że ptak na tym zdjęciu, które zrobiłem w zeszłym tygodniu, to jastrząb:

Pozwoliło mi to wybrać obiekt na moim zdjęciu i spróbować go zidentyfikować.
Ten nowy patent nie wspomina o Google Lens. W przeszłości napisałem post na temat patentu dotyczącego Gogli Google i ulepszeń, które mogą wystąpić w tej aplikacji w nowych funkcjach wyszukiwania wizualnego zdjęć od Google. Gogle Google zostały zamknięte jako aplikacja. Na szczęście. wygląda na to, że Google Lens ma teraz wiele takich samych funkcji, w tym skupianie się na obiekcie zawartym na zdjęciu (tak jak w moim przykładzie z Hawkiem).
W odpowiedzi na zapytanie wyszukiwania obrazów, wyszukiwarka może dodać adnotacje do obrazu za pomocą etykiet obrazów (etykiety obrazów zapytań, które oznaczają elementy w obrazie zapytania).
Jeśli szukam za pomocą mojego obrazu, Google rozpoznaje moje zdjęcie (lub odczytuje nazwę pliku obrazu i stamtąd go pobiera.):

Google informuje nas, jak obraz może być oznaczony etykietą podczas wyszukiwania grafiki:
Etykiety obrazu zapytania oznaczają drobne cechy obrazu zapytania oraz, w niektórych przypadkach, szczegółowe cechy obrazu zapytania. W oparciu o etykiety obrazu zapytania, system identyfikuje jedną lub więcej jednostek powiązanych z etykietami obrazu zapytania, np. osoby, miejsca, sieci telewizyjne lub kluby sportowe, i identyfikuje jedno lub więcej zapytań wyszukiwania kandydatów przy użyciu zidentyfikowanej jednej lub więcej jednostek. System wykorzystuje zidentyfikowane encje i etykiety obrazów zapytań do zmiany punktacji zapytań kandydujących na te, które są istotne dla użytkownika, niezależnie od tego, czy obraz zapytania jest oznaczony etykietami o wysokim stopniu szczegółowości, czy nie. System zapewnia jedno lub więcej odpowiednich reprezentatywnych zapytań wyszukiwania dla danych wyjściowych.
(Dodano 1/16/2020 – Kolejny post dotyczący niedawnego patentu Google dotyczącego etykiet, które nakłada na obrazy, to Jak Google może dodawać adnotacje do obrazów, aby poprawić wyniki wyszukiwania
Patent mówi nam, jak można ucieleśnić „innowacyjne aspekty”, które obejmują działania:
- Otrzymywanie obrazu zapytania
- Otrzymanie jednego lub więcej podmiotów powiązanych z obrazem zapytania
- Identyfikowanie, dla podmiotów, jednego lub więcej zapytań wyszukiwania kandydatów wstępnie skojarzonych z podmiotami
- Generowanie odpowiedniego wyniku trafności dla każdego zapytania wyszukiwania kandydatów
- Wybieranie, jako reprezentatywnych zapytań do wyszukiwania obrazów zapytań, kandydatów do zapytań wyszukiwania opartych na odpowiednich wynikach trafności
- Podanie reprezentatywnego zapytania wyszukiwania w odpowiedzi na otrzymanie obrazu zapytania
Wyniki trafności dla jednostek w obrazach
Jak więc obliczane są te oceny trafności dla jednostek?
Opis patentu zawiera szczegółowe informacje na temat takiego wyniku:
Odpowiedni wynik trafności dla każdego zapytania wyszukiwania kandydatów obejmuje:
- Ustalenie, czy kontekst obrazu zapytania pasuje do kandydującego zapytania wyszukiwania
- Generowanie odpowiedniego wyniku trafności dla zapytania wyszukiwania kandydata
„Określenie, czy kontekst obrazu zapytania pasuje do zapytania wyszukiwania kandydata” oznacza, czy obraz ma miejsce powiązane z dopasowaniem zapytania wyszukiwania (robienie zdjęć budynków lub posągów w miejscach, z których są znane).
To określenie może również oznaczać otrzymanie zapytania w języku naturalnym i wygenerowanie odpowiedniego wyniku trafności dla każdego z zapytań wyszukiwania kandydatów na podstawie co najmniej otrzymanego zapytania w języku naturalnym.
Jak to się robi?
Dla każdego zapytania wyszukiwania kandydatów:
- Generowanie strony wyników wyszukiwania za pomocą zapytania wyszukiwania kandydata
- Analizowanie wygenerowanej strony wyników wyszukiwania w celu określenia miary wskazującej na to, jak interesująca i użyteczna jest strona wyników wyszukiwania
- Na podstawie określonej miary, generując odpowiedni wynik trafności dla zapytania wyszukiwania kandydata
W niektórych przypadkach generowanie odpowiedniego wyniku trafności dla każdego zapytania wyszukiwania kandydatów obejmuje:
- Określanie popularności zapytania wyszukiwania kandydata
- Na podstawie określonej popularności, generując odpowiedni wynik trafności dla zapytania wyszukiwania kandydata
Wyniki dotyczące etykiet zapytania graficznego
W niektórych innych przypadkach otrzymanie jednej lub więcej jednostek powiązanych z obrazem zapytania obejmuje:
- Uzyskiwanie co najmniej jednej etykiety obrazu zapytania
- Identyfikowanie, dla co najmniej jednej etykiety obrazu zapytania, co najmniej jednej jednostki, która jest wstępnie skojarzona z co najmniej jedną etykietą obrazu zapytania
Patent mówi nam o kilku różnych rodzajach etykiet graficznych:
Jedna lub więcej etykiet obrazu zapytania zawiera etykiety obrazu drobnoziarnistego lub mogą one zawierać etykiety obrazu gruboziarnistego.
Proces związany z patentem może również obejmować generowanie odpowiedniego wyniku etykiety dla każdej z etykiet obrazu zapytania.
W niektórych implementacjach odpowiedni wynik etykiety dla etykiety obrazu zapytania jest oparty przynajmniej na aktualności etykiety obrazu zapytania.
Odpowiedni wynik etykiety dla etykiety obrazu zapytania może być oparty przynajmniej na tym, jak dokładna jest etykieta.
Odpowiedni wynik etykiety dla etykiety obrazu zapytania może być również oparty co najmniej na wiarygodności backendu, z którego otrzymuje się etykietę obrazu zapytania, oraz skalibrowanym wyniku ufności backendu.
Wybór konkretnego zapytania kandydującego na podstawie co najmniej wyników zapytania kandydującego i ocen etykiet obejmuje:
- Określanie wyniku zagregowanego między każdym wynikiem etykiety a powiązanym wynikiem zapytania kandydującego
- Ranking ustalonych wyników zbiorczych
- Wybór konkretnego zapytania wyszukiwania kandydata, które odpowiada najwyżej ocenionej punktacji
Wybór konkretnego zapytania wyszukiwania kandydata może opierać się co najmniej na wynikach zapytania kandydata w wyniku procesu:
- Ranking wyników trafności zapytań wyszukiwania kandydatów
- Wybór konkretnego zapytania wyszukiwania kandydata, które odpowiada najwyżej ocenionej punktacji
Patent na mapowanie obrazów do zapytań wyszukiwania można znaleźć pod adresem:
Mapowanie obrazów do zapytań wyszukiwania
Wynalazcy: Matthew Sharifi, David Petrou i Abhanshu Sharma
Pełnomocnik: Google LLC
Patent USA: 10 489 410
Przyznano: 26 listopada 2019 r.
Złożony: 18 kwietnia 2016 r.
Abstrakcyjny
Metody, systemy i urządzenia do odbierania obrazu zapytania, odbierania jednej lub większej liczby jednostek, które są powiązane z obrazem zapytania, identyfikowania, dla jednej lub większej liczby jednostek, jednego lub większej liczby zapytań kandydujących, które są wstępnie powiązane z jednym lub więcej podmiotów, generując odpowiednią ocenę trafności dla każdego z zapytań kandydujących, wybierając jako reprezentatywne zapytanie wyszukiwania dla obrazu zapytania konkretne wyszukiwane hasło kandydujące w oparciu przynajmniej o wygenerowane odpowiednie wyniki trafności i dostarczając reprezentatywne zapytanie wyszukiwania dla danych wyjściowych w odpowiedzi na otrzymanie obrazu zapytania.
Ta specyfikacja opisuje system generowania zapytań wyszukiwania tekstowego przy użyciu zapytań opartych na obrazie (wyszukiwanie ze zdjęciem).
Ten system wyszukiwania łączy zestaw wyników rozpoznawania wizualnego dla otrzymanego zapytania opartego na obrazie z dziennikami zapytań wyszukiwania i znanymi atrybutami zapytania wyszukiwania, aby wygenerować odpowiednie zapytania wyszukiwania kandydatów w języku naturalnym dla wejściowego zapytania wyszukiwania opartego na obrazie.
Zapytania wyszukiwania kandydatów w języku naturalnym są nastawione na zapytania, które:
- Dopasuj intencje użytkownika
- Generuj interesujące lub trafne strony wyników wyszukiwania
- Lub są określone jako popularne zapytania
Połączone zapytania obrazowe z zapytaniami w języku naturalnym
W niektórych przypadkach system wyszukiwania może otrzymać zarówno zapytanie oparte na obrazie, jak i zapytanie w języku naturalnym (tekst, który mógł zostać wypowiedziany i uzyskany za pomocą technologii rozpoznawania mowy).
System wyszukiwania może łączyć zestaw wyników rozpoznawania wizualnego dla otrzymanego zapytania wyszukiwania opartego na obrazie z dziennikami zapytań wyszukiwania i znanymi atrybutami zapytania wyszukiwania w celu wygenerowania odpowiednich zapytań wyszukiwania kandydatów w języku naturalnym dla wejściowego zapytania wyszukiwania opartego na obrazie.
Zapytania kandydujące w języku naturalnym są nastawione na zapytania, które:
- Dopasuj intencje użytkownika
- Generuj interesujące lub trafne strony wyników wyszukiwania
- są określone jako popularne zapytania wyszukiwania
- Zawierają lub są powiązane z otrzymanym zapytaniem w języku naturalnym
Cechy obrazu gruboziarnistego i cechy obrazu drobnoziarnistego
Patent mówi nam, że może używać zarówno gruboziarnistych, jak i drobnoziarnistych funkcji obrazu do mapowania obrazu na określone zapytanie wyszukiwania. Jaka jest więc różnica między tymi dwoma?
Na przykład obraz zapytania może zawierać obraz książki na stole. W takim przypadku gruboziarnistą cechą obrazu zapytania może być książka, a drobnoziarnistą cechą może być tytuł lub gatunek książki. W przykładowym obrazie zapytania przedstawionym na FIG. 1, szczegółowe elementy obrazu zapytania mogą obejmować „miasto” lub „budynki”, a szczegółowe elementy mogą obejmować „Londyn” lub „Korniszon”.
Patent mówi nam, że może koncentrować się na obiektach lub cechach oznaczonych przez system rozpoznawania obrazów jako:
- Duży (zajmujący dużą powierzchnię obrazu)
- Mały (zajmujący niewielką ilość powierzchni obrazu)
- Centralny (wyśrodkowany w środku obrazu)
Obraz zapytania może zawierać obraz książki na stole.
Na tym zdjęciu dużą cechą obrazu może być tabela, a małą cechą obrazu może być książka.
Książka może być centralnym elementem obrazu.

Połączone zapytanie o obraz i zapytanie w języku naturalnym
W poszukiwaniu budynku Korniszon (patrz obraz nagłówka tego posta) ktoś może przesłać zdjęcie budynku i dołączyć zapytanie w języku naturalnym, takie jak:
- „Jakim stylem architektonicznym jest Korniszon?”
- „Jak wysoki jest Korniszon?”
- „Kto zajmuje Korniszona?”
- “Dojazd do Korniszona”
Wyniki wyszukiwania w odpowiedzi na wyszukiwanie grafiki
Przykładowa strona SERP może pokazywać linki i fragmenty wyników w różnych witrynach związanych z przeszukiwanym obrazem, a także panel wiedzy, który zawiera „ogólne informacje dotyczące podmiotu „Korniszon”, takie jak rozmiar, wiek i adres budynek."
Patent mówi nam również, że wyniki wyszukiwania mogą również:
- Pokaż więcej zapytań wyszukiwania kandydatów, które są wstępnie powiązane z co najmniej jednym podmiotem
- Wygeneruj odpowiednie wyniki dla każdego zapytania wyszukiwania kandydatów
- Wybierz reprezentatywne zapytanie wyszukiwania spośród zapytań wyszukiwania kandydatów na podstawie wygenerowanych wyników
Patent informuje nas również, że obraz lub film wideo można przesłać w ramach wyszukiwania za pomocą pisemnego zapytania w języku naturalnym, a nawet zapytania w języku naturalnym mówionym (a zarówno zapytania wideo, jak i wypowiedziane są objęte tym patentem).
Patent mówi nam o adnotatorze obrazu, który może dodawać etykiety obrazu zapytania (wyniki rozpoznawania wizualnego) do obrazu zapytania wprowadzonego przez użytkownika. Uważam to za interesujące, ponieważ Claire Carlile zwróciła mi wczoraj uwagę na fakt, że Google ponownie uruchomił swój program Image Labeler. Wcześniej była uruchamiana jako gra oparta na grze ESP autorstwa Luisa von Ahna, który wynalazł program Captcha, z którego korzystał również Google. Korzystanie z gry ma pomóc Google lepiej zrozumieć, które etykiety powinny mieć zastosowanie do obrazów, dzięki crowdsourcingowi ludzkich adnotacji do obrazów.
Patent mówi nam więcej o adnotacjach do obrazów, obejmujących proste etykiety obrazów zapytań i szczegółowe etykiety obrazów zapytań:
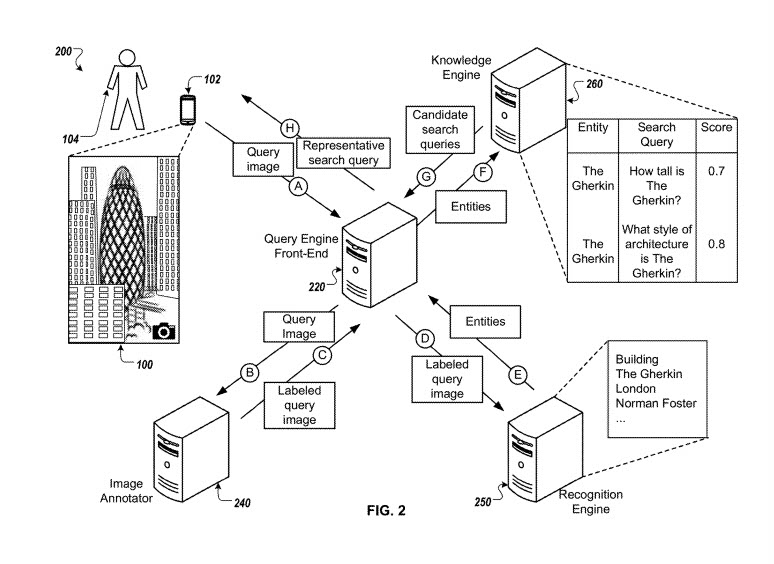
Podczas operacji (B), adnotator obrazu 0 może odbierać dane związane z obrazem zapytania wprowadzanym przez użytkownika i może identyfikować jedną lub więcej etykiet obrazu zapytania, np. wyniki rozpoznawania wizualnego, dla obrazu zapytania wprowadzanego przez użytkownika. Na przykład adnotator obrazu może zawierać lub komunikować się z jednym lub większą liczbą zapleczy, które są skonfigurowane do analizowania danego obrazu zapytania i identyfikowania jednej lub większej liczby etykiet obrazu zapytania. Adnotator obrazu może identyfikować drobnoziarniste etykiety obrazów zapytań (etykiety obrazów, które oznaczają określone punkty orientacyjne, okładki książek lub plakaty obecne na danym obrazie) i/lub gruboziarniste etykiety obrazów (etykiety obrazów, które oznaczają obiekty, takie jak tabeli, książki lub jeziora). Na przykład, na podstawie otrzymanych danych związanych ze zdjęciem wprowadzanym przez użytkownika 206, adnotator obrazu może zidentyfikować szczegółowe etykiety obrazu zapytania, takie jak „Korniszon” lub „Londyn” dla danych wprowadzanych przez użytkownika zdjęcie 206 i może identyfikować gruboziarniste etykiety obrazów zapytania, takie jak „Budynki” lub „miasto”. W niektórych implementacjach adnotator obrazu może zwracać etykiety obrazu zapytania oparte na wynikach rozpoznawania OCR lub tekstowego rozpoznawania wizualnego. Na przykład adnotator obrazu może identyfikować i przypisywać nazwę wydrukowaną na znaku drogowym zawartym w obrazie zapytania lub nazwę sklepu, która jest uwzględniona w obrazie, jako etykiety obrazu zapytania.
Zapytanie o budynek może wykorzystywać rozpoznawanie obrazów do identyfikacji budynków, takich jak:
- "Wieża Eiffla"
- „Imperium State Building”
- "Taj Mahal"
Można znaleźć drobnoziarnistą etykietę „Korniszon” dla obrazu nagłówka tego posta, a silnik rozpoznawania może identyfikować jednostki, takie jak „przybrany Norman”, (architekt) „Standard Life” (najemca) lub „City of London ” (lokalizacja) jako powiązany z obrazem zapytania wprowadzanym przez użytkownika na podstawie porównania etykiety zapytania „Korniszon” z terminami powiązanymi z zestawem znanych jednostek.
Znany zestaw jednostek może być dostępny dla silnika rozpoznawania przy użyciu bazy danych, która może je zidentyfikować.
W oparciu o identyfikowanie jednostek powiązanych z oznaczonym obrazem zapytania wprowadzanym przez użytkownika, silnik rozpoznawania może przesyłać dane, które identyfikują jednostki i wszelkie dodatkowe warunki kontekstu do silnika zapytań. Widzimy takie skojarzenia na etykietach obrazów, które pojawiają się w SERPach dla [korniszona], takie jak wzmianka o Normanie Fosterze i Searcys – restauracji w budynku:

Ten patent na obraz mapowania pokazuje nam, w jaki sposób jednostki na wykresie wiedzy mogą być mapowane razem, aby odzwierciedlić jednostki powiązane. Powiedziano nam o silniku wiedzy, który łączy te podmioty wykonując zapytanie graficzne:
Podczas operacji (F), front-end silnika zapytań może odbierać dane identyfikujące jedną lub więcej jednostek i może przesyłać dane identyfikujące jednostki do silnika wiedzy. Na przykład interfejs silnika zapytań może otrzymywać informacje identyfikujące jednostki „Korniszon”, „Norman Foster”, „Standard Life” i „City of London” i może przesyłać dane do silnika wiedzy, który identyfikuje „Korniszon”. ”, „Norman Foster”, „Standard Life” i „City of London”. W niektórych przypadkach front-end silnika zapytań może przesyłać dane identyfikujące jednostki do silnika wiedzy za pośrednictwem jednej lub większej liczby sieci lub za pośrednictwem jednego lub większej liczby innych połączeń przewodowych lub bezprzewodowych.
Mówi nam również, że zapytania wyszukiwania kandydatów (z odpowiedziami) mogą być mapowane do określonych podmiotów, ponownie używając Korniszona jako przykładu:
Silnik wiedzy może odbierać dane identyfikujące jednostki i może identyfikować jedno lub więcej zapytań wyszukiwania kandydatów, które są wstępnie powiązane z jedną lub większą liczbą jednostek. W niektórych implementacjach silnik wiedzy może identyfikować zapytania kandydujące związane ze zidentyfikowanymi jednostkami w oparciu o dostęp do bazy danych lub serwera, który utrzymuje zapytania wyszukiwania kandydatów związane z jednostkami, np. wstępnie obliczoną mapę zapytań. Na przykład silnik wiedzy może otrzymywać informacje identyfikujące podmiot „Korniszon”, a silnik wiedzy może uzyskać dostęp do bazy danych lub serwera w celu zidentyfikowania zapytań wyszukiwania kandydatów, które są powiązane z podmiotem „Korniszon”, na przykład „Jak wysoki jest Korniszon” lub „Jakim stylem architektonicznym jest Korniszon?” W niektórych implementacjach baza danych lub serwer, do którego uzyskuje dostęp silnik wiedzy, może być bazą danych lub serwerem powiązanym z silnikiem wiedzy, np. jako część silnika wiedzy, lub silnik wiedzy może uzyskać dostęp do bazy danych lub serwera, np. w jednej lub kilku sieciach. Baza danych lub serwer, który utrzymuje zapytania wyszukiwania kandydatów związane z jednostkami, np. wstępnie obliczona mapa zapytań, może zawierać zapytania wyszukiwania kandydatów w różnych językach. W takich przypadkach silnik wiedzy może być skonfigurowany do identyfikowania zapytań kandydujących, które są powiązane z daną jednostką w języku, który odpowiada językowi użytkownika, np. zgodnie ze wskazaniem urządzenia użytkownika lub zapytaniem w języku naturalnym dostarczonym z obrazem zapytania .
Google może sprawdzać zapytania, które są wstępnie powiązane z podmiotami, które mogą być powiązane z obrazami zapytań i dostarczać wyniki dla tych zapytań. Patent pokazuje przykład tego:
Interfejs silnika zapytań może otrzymywać dane, które zawierają lub identyfikują jedno lub więcej zapytań kandydujących i ich odpowiednie wyniki trafności z silnika wiedzy i może wybrać jedno lub więcej reprezentatywnych zapytań wyszukiwania z jednego lub więcej zapytań kandydujących na podstawie co najmniej na wynikach trafności (poprzez uszeregowanie jednego lub większej liczby zapytań kandydujących i wybranie kilku zapytań o najwyższym wyniku jako reprezentatywnych zapytań wyszukiwania). jest Korniszon? z oceną trafności 0,7 i „Jakim stylem architektury jest Korniszon?” z wynikiem trafności 0,8. Na podstawie wyników trafności interfejs silnika zapytań może wybrać kandydujące zapytanie wyszukiwania „Jakim stylem architektury jest Korniszon?” W niektórych implementacjach interfejs wyszukiwarki zapytań może wybrać jedno lub więcej reprezentatywnych zapytań wyszukiwania z jednego lub więcej zapytań kandydujących na podstawie wyników trafności i ocen etykiet otrzymanych z adnotatora obrazu (poprzez agregację ocen trafności i ocen etykiet przy użyciu funkcja rankingowa lub klasyfikator).
Powiązane lokalizacje i zapytania dotyczące obrazów
Kontekst obrazu zapytania może odgrywać rolę w określaniu, czy obraz zapytania ma powiązaną lokalizację, która odpowiada kandydującemu zapytaniu wyszukiwania.
Na przykład zdjęcie płaszcza może być rozumiane jako wykonane w centrum handlowym. System wyszukiwania może generować wyższe odpowiednie wyniki trafności dla zapytań dotyczących kandydatów, które są związane z zakupami lub wynikami komercyjnymi dla tego obrazu w oparciu o ten kontekst.
Uważa się, że inne zdjęcie płaszcza zostało zrobione w domu użytkownika. System wyszukiwania może generować wyższe odpowiednie wyniki trafności zapytań dotyczących kandydatów związanych z pogodą, takich jak „czy potrzebuję dzisiaj mojego płaszcza?”
Innym przykładem może być zrozumienie kontekstu jako lokalizacji odpowiadającej bieżącej lokalizacji urządzenia wyszukującego. Na przykład system wyszukiwania może określić, że obraz kwiatów został odebrany w określonym mieście lub okolicy. System wyszukiwania może generować wyższe odpowiednie wyniki trafności dla zapytań wyszukiwania kandydatów, które są związane z pobliskimi kwiaciarniami lub usługami ogrodniczymi.
Zapytania dotyczące obrazów, które otrzymały jedną skrzynkę i karty odpowiedzi internetowej
W przypadku niektórych wyników, gdy wynik trafności może zawierać miarę tego, jak interesująca i użyteczna może być strona wyników wyszukiwania, system wyszukiwania może generować wyższe odpowiednie wyniki trafności dla zapytań kandydujących, które generują strony wyników wyszukiwania z jednym polem lub kartami odpowiedzi internetowej niż zapytania kandydujące, które generują strony z wynikami wyszukiwania bez ramek i kart z odpowiedziami.
Zapytania dotyczące obrazów na wynos
Jak zapytania są mapowane na obrazy
Gdy zapytanie składa się wyłącznie z obrazu, Google może zidentyfikować zawartość obrazu oraz powiązane z nim etykiety. Może próbować zrozumieć, jakie inne jednostki mogą być również powiązane z tym, co znajduje się na obrazie, i sprawdzić, czy jakiekolwiek wstępnie skojarzone zapytania są powszechnie powiązane z tym, czym może być obraz lub z tymi powiązanymi jednostkami. Może również wykorzystywać wskazówki kontekstowe, takie jak lokalizacja, aby lepiej zrozumieć intencję zapytania graficznego.
Jeśli obraz zawiera zapytanie w języku naturalnym, wpisane lub wypowiedziane, może również uwzględnić te powiązane encje i wstępnie skojarzone zapytania, patrząc na dzienniki zapytań, a także kontekst z lokalizacji.
Dostęp do kategorii semantycznych w wyszukiwaniu grafiki może dostarczyć pewnych wskazówek, co Google może pokazać w wynikach wyszukiwania w odpowiedzi na zapytanie dotyczące grafiki.