
Eine Crowdsourcing-Auswertung von geclusterten Suchergebnissen
Veröffentlicht: 2019-07-10Ein Google-Patent, das sich auf das Ranking von Softwareanwendungen mithilfe von Clustering und einem Crowdsourcing-Bewertungsansatz konzentriert, um die am besten geclusterten Suchergebnisse auszuwählen, wurde gerade erteilt. Die Crowdsourcing-Bewertung würde von Quellen wie Mechanical Turk geliefert.
Dieser Ansatz soll nicht nur für Softwareanwendungen verwendet werden, sondern auch für:
- Produkte, die auf einem Marktplatz verkauft werden
- Über ein Netzwerk verfügbare Dokumente
- Lieder in einem Online-Musikladen
- Bilder in einer Galerie
- Etc.
Das Problem beim Clustering von Suchergebnissen
Der Grund, warum geclusterte Suchergebnisse verwendet werden, besteht darin, Anfragen zu bearbeiten, die möglicherweise eine große Anzahl von responsiven Elementen zurückgeben. Uns wird gesagt, dass automatisiertes Clustering, das durch Algorithmen generiert wird, nicht immer qualitativ hochwertige Cluster erzeugt. Als Reaktion darauf kann die manuelle Auswertung und Verfeinerung der Clustering-Ergebnisse durch Experten die Qualität der Suchergebnisse erhöhen, aber auch langsam sein und nicht auf eine große Anzahl von Abfragen skalieren. Das ist das Problem, das dieses Patent ansprechen soll.
Geclusterte Suchergebnisse als Lösung
Der Prozess hinter diesem Patent beinhaltet die Schaffung eines verbesserten Systems für die Crowdsourcing-Bewertung und die skalierbare Verfeinerung geclusterter Suchergebnisse.
Es beginnt damit, dass das System unter Verwendung einer Vielzahl von Clustering-Algorithmen Cluster-Sätze für eine Abfrage generiert.

Diese geclusterten Sets würden dann in zufälliger Reihenfolge einem Set von Crowdsourcing-Mitarbeitern präsentiert.
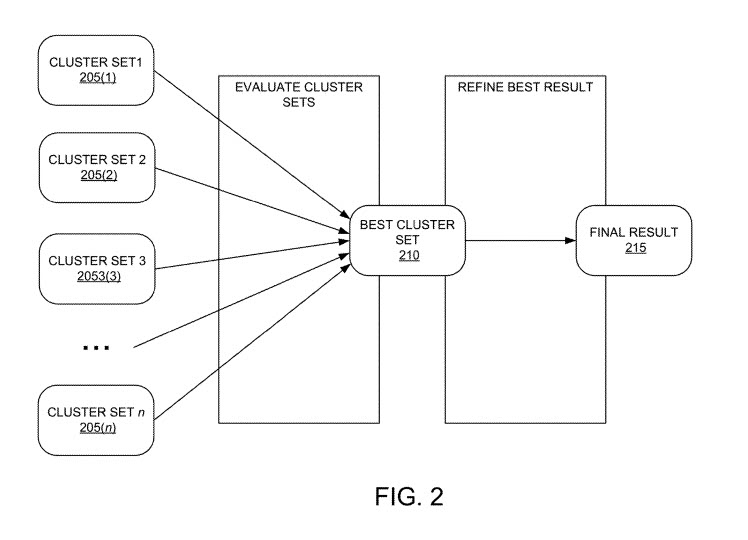
Die Arbeiter würden mit einer Benutzerschnittstelle interagieren, die den Arbeitern die geclusterten Ergebnissätze präsentiert, um Bewertungen von diesen Arbeitern für jeden Clustersatz unabhängig von den anderen Sätzen zu erhalten. Jede Bewertung konzentriert sich auf die Qualität jedes Clusters, anstatt die Cluster miteinander zu vergleichen.
Für jeden Cluster wird basierend auf der Bewertung für diesen Kunden eine Punktzahl generiert, einschließlich:
- Bewertungen abgegeben
- Der Zeitaufwand für die Bereitstellung der Bewertungen
- Zusätzliche Informationen abgerufen
- Etc.
Die Bewertung kann verwendet werden, um basierend auf der Bewertung über mehrere Arbeiterantworten zu bestimmen, welcher Clustering-Algorithmus den besten Satz von Clustern für die Abfrage erzeugt hat.
Dies sind nicht die Bewerter, die Suchergebnisse anhand der Richtlinien für Qualitätsbewerter von Google bewerten. Ich habe diese menschlichen Bewerter noch nie bei einer Aufgabe wie der Bewertung von Suchergebnisseiten gesehen.
Verfeinerung des Clusterings von Suchergebnissen
Neben der Bewertung von Suchergebnisclustern sagt uns das Patent auch, dass diese Crowdsourcing-Mitarbeiter Änderungen und Verfeinerungen an dem als das beste Cluster ermittelten Cluster vorschlagen könnten. Während der Crowdsourcing-Bewertung können die Mitarbeiter Änderungen gemäß einer Reihe von Verfeinerungsaufgaben vorschlagen.
Verfeinerungsaufgaben können sein:
- Zusammenführen von zwei Clustern, die zu ähnlich sind
- Löschen eines Clusters, der nicht zu den anderen zu passen scheint
- Eine Entität/ein Thema aus einem Cluster löschen
- Löschen eines bestimmten Suchbegriffs aus einem Cluster
- Verschieben einer Entität oder eines Suchelements von einem Cluster in einen anderen Cluster
Uns wird auch gesagt:
Wenn die vorgeschlagene Verfeinerung einen Übereinstimmungsschwellenwert für die Aufgaben erfüllt, kann das System die Verfeinerung durch Ändern der Clusterdefinition automatisch vornehmen und/oder kann die Verfeinerung einem Experten melden.
Cluster-Set-Tests
Jeder der Clustersätze kann einen anderen Clustering-Algorithmus darstellen. Ein Set wird nach dem Zufallsprinzip an Crowdsourcing-Mitarbeiter gesendet, die diesen Cluster bewerten. Diese Bewertungen werden kombiniert, um Punktzahlen für diese Cluster zu generieren.
Das Verfahren umfasst auch das Speichern einer Cluster-Set-Definition für das Cluster-Set mit der höchsten Cluster-Set-Punktzahl, die Cluster-Set-Definition wird mit der Abfrage verknüpft und die Cluster-Set-Definition nach Erhalt einer Anfrage für die Abfrage verwendet, um die Anzeige von Suchelementen zu initiieren auf die Anfrage reagieren.

Vorteile dieses Clustering-Ansatzes für Suchergebnisse
Diese Implementierungen können verwendet werden, um einen oder mehrere der folgenden Vorteile zu realisieren.
- Das System bietet eine Möglichkeit zu bestimmen, welcher Clustering-Algorithmus die besten Cluster-Abfrageergebnisse für einzelne Abfragen erzeugt. Dies bietet eine bessere Benutzererfahrung für Benutzer, die die Ergebnisse anzeigen
- Die Auswertung und Bewertung sind skalierbar (können beispielsweise Hunderte oder Tausende von Abfragen verarbeiten), da sie auf Crowdsource-Aufgaben und nicht auf Experten angewiesen sind
- Das System maximiert die Qualität durch Heruntergewichten von Bewertungen von Crowdsourcing-Mitarbeitern, die nicht genügend Zeit für die Aufgabe aufwenden und/oder nicht über ausreichendes Fachwissen verfügen (z. B. Vertrautheit mit der Abfrage und den Suchbegriffen)
- Das System maximiert auch die Qualität, indem es die verschiedenen Cluster-Sets nach dem Zufallsprinzip verschiedenen Arbeitern präsentiert, um zu vermeiden, dass der Arbeiter voreingenommen wird, mehr Zeit mit dem ersten präsentierten Set zu verbringen
- Indem der Arbeiter aufgefordert wird, jeden Cluster zu bewerten, bevor er den gesamten Cluster-Satz bewertet, fördert das System die Bewertung jedes Clusters
- Das System bietet für jeden Cluster eine maximale Anzahl hochwertiger oder wichtiger Suchbegriffe, um den Crowdsource-Mitarbeiter bei der Bewertung der Redundanz zwischen Clustern in einem Cluster-Set zu unterstützen
- Das System ermöglicht einen Konsens über die Verfeinerung von Cluster-Sets, wie das Zusammenführen von zwei Clustern im Cluster-Set, das Löschen eines Clusters aus dem Cluster-Set oder das Löschen bestimmter Themen oder Suchbegriffe aus einem Cluster, und kann automatisch Änderungen an der Cluster-Set-Definition vornehmen wenn eine Mindestanzahl von Arbeitern die gleiche Verfeinerung empfiehlt
Das Suchergebnis-Clustering-Patent finden Sie unter:
Crowdsourcing-Auswertung und Verfeinerung von Suchclustern
Erfinder: Jilin Chen, Amy Xian Zhang; Sagar Jain, Lichan Hong und Ed Huai-Hsin Chi
Rechtsnachfolger: GOOGLE LLC
US-Patent: 10.331.681
Bewilligt: 25. Juni 2019
Gespeichert: 11. April 2016Abstrakt
Implementierungen stellen ein verbessertes System zum Präsentieren von Suchergebnissen basierend auf Entitätszuordnungen der Suchbegriffe bereit. Ein beispielhaftes Verfahren beinhaltet für jeden von mehreren Crowdsource-Workern das Initiieren der Anzeige eines ersten zufällig ausgewählten Clustersatzes aus mehreren Clustersätzen für den Crowdsource-Worker. Jeder Clustersatz stellt einen anderen Clustering-Algorithmus dar, der auf einen Satz von Suchelementen angewendet wird, die auf eine Abfrage reagieren. Das Verfahren umfasst auch das Empfangen von Clusterbewertungen für den ersten Clustersatz von dem Crowdsource-Worker und das Berechnen einer Clustersatzbewertung für den ersten Clustersatz basierend auf den Clusterbewertungen. Dies wird für die verbleibenden Clustersätze in den mehreren Clustersätzen wiederholt. Das Verfahren umfasst auch das Speichern einer Clustersatzdefinition für einen Clustersatz mit der höchsten Bewertung, das Assoziieren der Clustersatzdefinition mit der Abfrage und das Verwenden der Definition zum Anzeigen von Suchelementen als Reaktion auf die Abfrage.
TakeAways für die Crowdsourcing-Evaluierung
Ich fand dieses Patent aufgrund des Einsatzes menschlicher Bewerter interessant, die keine Suchergebnisse einordneten, sondern stattdessen die besten Cluster von Suchergebnissen bewerteten und verfeinerten. Die Cluster basieren auf verschiedenen Clustering-Algorithmen, und das Patent sagt uns nicht viel darüber, wie diese Clustering-Algorithmen funktionieren könnten. Der Ort, an dem Sie möglicherweise Clustering in den Suchergebnissen bei Google gesehen haben, war Google News, wo Nachrichtenartikel nach Themen und Geografie gruppiert sind und die repräsentativsten Ergebnisse in der Regel in jedem dieser Cluster am höchsten sind.
Anstelle von Fachexperten-Bewertungsclustern wird ein Crowdsourcing-Bewertungsansatz verwendet. Dies spart wahrscheinlich Zeit und die Bewerter können viele Cluster von Suchergebnissen bewerten und verfeinern. Ich frage mich, wie sich Webseiten als repräsentativ für Cluster herausstellen können.
DETAILLIERTE [Startseite]