
O evaluare crowdsourcing a rezultatelor căutării în cluster
Publicat: 2019-07-10Tocmai a fost acordat un brevet Google care se concentrează pe clasificarea aplicațiilor software folosind clustering și o abordare de evaluare crowdsourcing pentru a alege cele mai bune rezultate de căutare în cluster. Evaluarea crowdsourcing ar fi furnizată de surse precum Mechanical Turk.
Pe lângă faptul că este utilizată pentru aplicații software, această abordare este destinată să se aplice și pentru:
- Produse vândute pe piață
- Documente disponibile printr-o rețea
- Cântece într-un magazin de muzică online
- Imagini într-o galerie
- etc.
Problema cu gruparea rezultatelor căutării
Motivul pentru care ar fi utilizate rezultatele căutării grupate ar fi pentru a adresa interogări care pot returna un număr mare de articole receptive. Ni se spune că clusteringul automatizat, unul care este generat de algoritm, nu produce întotdeauna clustere de înaltă calitate. Ca răspuns, evaluarea manuală și rafinarea rezultatelor grupării de către experți poate crește calitatea rezultatelor căutării, dar poate fi, de asemenea, lentă și nu se poate scala la un număr mare de interogări. Aceasta este problema pe care intenționează să o abordeze acest brevet.
Rezultatele căutării grupate ca soluție
Procesul din spatele acestui brevet implică crearea unui sistem îmbunătățit pentru evaluarea crowdsourcing și rafinarea rezultatelor de căutare grupate într-un mod scalabil.
Începe cu sistemul care generează seturi de clustere pentru o interogare cu utilizarea unei varietăți de algoritmi de grupare.

Aceste seturi grupate ar fi apoi prezentate unui set de lucrători de crowdsourcing, în ordine aleatorie.
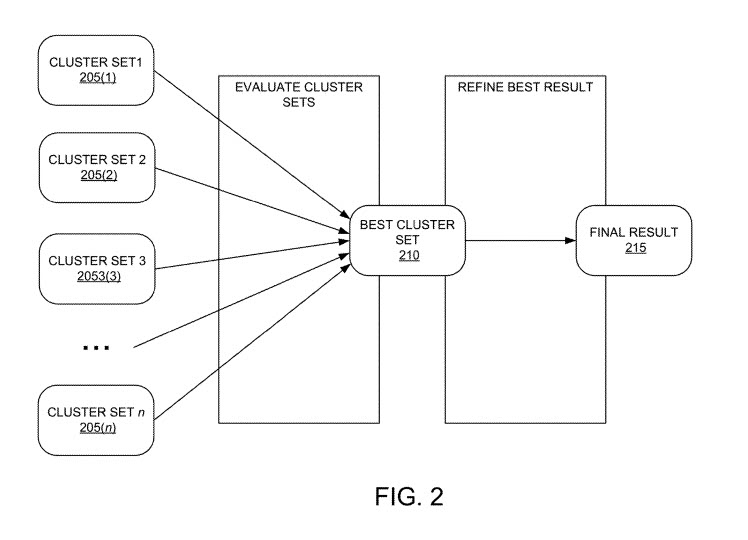
Lucrătorii ar interacționa cu o interfață cu utilizatorul care prezintă lucrătorilor seturile grupate de rezultate, pentru a primi evaluări de la acești lucrători pentru fiecare set de cluster, independent de celelalte seturi. Fiecare evaluare se concentrează pe calitatea fiecărui cluster, mai degrabă decât pe compararea clusterelor între ele.
Se generează un scor pentru fiecare grup pe baza evaluării pentru acel client, inclusiv:
- Evaluări oferite
- Timpul petrecut pentru furnizarea evaluărilor
- Informații suplimentare accesate
- etc.
Scorul poate fi utilizat pentru a determina, pe baza scorului din mai multe răspunsuri ale lucrătorilor, care algoritm de grupare a produs cel mai bun set de clustere pentru interogare.
Aceștia nu sunt evaluatorii care evaluează rezultatele căutării folosind Regulile Google pentru evaluarea calității. Nu i-am văzut niciodată pe acești evaluatori umani printr-o sarcină precum evaluarea grupurilor de rezultate ale căutării.
Rafinarea grupării rezultatelor căutării
Pe lângă evaluarea grupurilor de rezultate ale căutării, brevetul ne spune, de asemenea, că acești lucrători crowdsourcing ar putea sugera modificări și perfecționări ale clusterului care a fost determinat a fi cel mai bun. În timpul evaluării crowdsourced, lucrătorii pot sugera modificări în funcție de o serie de sarcini de rafinare.
Sarcinile de rafinare pot include:
- Fuzionarea a două grupuri care sunt prea asemănătoare
- Ștergerea unui cluster care nu pare să se potrivească cu celelalte
- Ștergerea unei entități/subiect dintr-un cluster
- Ștergerea unui anumit element de căutare dintr-un cluster
- Mutarea unei entități sau a unui element de căutare dintr-un cluster în altul
Ni se mai spune că:
Dacă rafinarea sugerată îndeplinește un prag de acord pentru sarcini, sistemul poate efectua automat rafinarea prin modificarea definiției clusterului și/sau poate raporta rafinamentul unui expert.
Testarea setului de clustere
Fiecare dintre seturile de clustere poate reprezenta un algoritm de clustering diferit. Un set este trimis la întâmplare lucrătorilor participanți, iar aceștia evaluează acel cluster. Aceste evaluări sunt combinate pentru a genera scoruri pentru acele grupuri.
Metoda include, de asemenea, stocarea unei definiții de set de cluster pentru setul de cluster cu cel mai mare scor al setului de cluster, definiția setului de cluster este asociată cu interogarea și utilizarea, după primirea unei cereri pentru interogare, definiția setului de cluster pentru a iniția afișarea elementelor de căutare răspund la interogare.

Avantajele acestei abordări de grupare a rezultatelor căutării
Aceste implementări pot fi utilizate pentru a realiza unul sau mai multe dintre următoarele avantaje.
- Sistemul oferă o modalitate de a determina ce algoritm de grupare produce cele mai bune rezultate de interogare grupate pentru interogări individuale. Acest lucru oferă o experiență mai bună pentru utilizatorii care vizualizează rezultatele
- Evaluarea și evaluarea sunt scalabile (de exemplu, pot gestiona sute sau mii de interogări) deoarece se bazează pe sarcini crowdsource și nu pe experți
- Sistemul maximizează calitatea prin ponderarea în jos a evaluărilor de la lucrătorii de la crowdsourcing care nu petrec suficient timp sarcinii și/sau care nu au suficientă experiență (de exemplu, familiaritatea cu interogarea și elementele de căutare)
- Sistemul maximizează, de asemenea, calitatea prin prezentarea aleatorie a diferitelor seturi de clustere diferiților lucrători pentru a evita părtinirea lucrătorului de a petrece mai mult timp pe primul set prezentat.
- Cerând lucrătorului să evalueze fiecare cluster înainte de a evalua setul general de cluster, sistemul încurajează evaluarea fiecărui cluster.
- Sistemul oferă un număr maxim de elemente de căutare importante sau de înaltă calitate pentru fiecare cluster, pentru a ajuta lucrătorul crowdsource să evalueze redundanța dintre clustere dintr-un set de clustere.
- Sistemul facilitează consensul asupra perfecționării setului de clustere, cum ar fi îmbinarea a două clustere în setul de clustere, ștergerea unui cluster din setul de clustere sau ștergerea anumitor subiecte sau elemente de căutare dintr-un cluster și poate face automat modificări în definiția setului de clustere. când un număr minim de muncitori recomandă aceeași rafinare
Brevetul de grupare a rezultatelor căutării poate fi găsit la:
Evaluarea crowdsourced și rafinarea clusterelor de căutare
Inventatori: Jilin Chen, Amy Xian Zhang; Sagar Jain, Lichan Hong și Ed Huai-Hsin Chi
Cesionar: GOOGLE LLC
Brevet SUA: 10.331.681
Acordat: 25 iunie 2019
Depus: 11 aprilie 2016Abstract
Implementările oferă un sistem îmbunătățit pentru prezentarea rezultatelor căutării pe baza asocierilor de entități ale elementelor de căutare. Un exemplu de metodă include, pentru fiecare dintr-o multitudine de lucrători crowdsource, iniţierea afişării unui prim set de cluster selectat aleatoriu dintr-o multitudine de seturi de cluster către lucrătorul crowdsource. Fiecare set de cluster reprezintă un algoritm de grupare diferit aplicat unui set de elemente de căutare care răspund la o interogare. Metoda include, de asemenea, primirea de evaluări de cluster pentru primul set de cluster de la lucrătorul crowdsource și calcularea unui scor de set de cluster pentru primul set de cluster pe baza evaluărilor cluster. Acest lucru se repetă pentru seturile de cluster rămase din multitudinea de seturi de clustere. Metoda include, de asemenea, stocarea unei definiții de set de cluster pentru un set de cluster cu cel mai mare punctaj, asocierea definiției setului de cluster cu interogarea și utilizarea definiției pentru a afișa elementele de căutare care răspund la interogare.
Crowdsourcing Evaluare TakeAways
Am găsit acest brevet interesant din cauza utilizării de evaluatori umani care nu au clasat rezultatele căutării, ci au evaluat și rafinat cele mai bune grupuri de rezultate de căutare. Clusterele se bazează pe diferiți algoritmi de clustering, iar brevetul nu ne spune prea multe despre cum ar putea funcționa acești algoritmi de clustering. Locul în care este posibil să fi văzut gruparea în rezultatele căutării la Google a fost Știri Google, unde articolele de știri sunt grupate în funcție de subiecte și zone geografice, iar cele mai reprezentative rezultate sunt de obicei cele mai înalte clasate în fiecare dintre aceste grupuri.
În loc de experți în materie de evaluare a clusterelor, se utilizează o abordare de evaluare crowdsourcing. Probabil că economisește timp, iar evaluatorii pot evalua și rafina o mulțime de grupuri de rezultate ale căutării. Acest lucru mă face să mă întreb cum ar putea paginile web să iasă în evidență ca fiind reprezentative pentru clustere.
DETALIAT [Acasă]