
Google verwendet Website-Repräsentationsvektoren zur Klassifizierung mit Fachwissen und Autorität
Veröffentlicht: 2020-02-21Hinzugefügt (2020-02-23) Fragen und Antworten: Ein paar Fragen zu diesem Patent für Website-Repräsentationsvektoren und einige Dinge dazu, die ich ansprechen wollte.
1. Das „Medic“-Update – das Barry Schwartz im August 2018 benannte, weil es medizinische Websites zu betreffen schien, betraf auch andere Arten von Websites. In dieser im August 2018 eingereichten Patentanmeldung wird darauf hingewiesen, dass sie eine Reihe von Branchen abdeckt, darunter zum Beispiel Websites für das Gesundheitswesen und künstliche Intelligenz. Es verwendet ein Beispiel dafür, dass Autoren von Gesundheitsseiten Ärzte als Experten, Medizinstudenten als Lehrlinge und Laien als Nicht-Experten sind. Aus diesem Grund habe ich einen Grafikdesigner von Go Fish Digital um das Impressum für diesen Beitrag gebeten, der jeweils eines davon zeigt. In diesem Patent sind verschiedene Branchen und unterschiedliche Fachkenntnisse enthalten. Ich habe mich für eine Illustration entschieden, die den „medizinischen“ Aspekt des Verfahrens des Patents widerspiegelt, weil ich der Meinung war, dass es eine genaue Wiedergabe dessen war, was das Patent abdeckt
2. Qualitätsbewertungen – Das Patent erklärt, wie es Websites weiter klassifizieren könnte, basierend darauf, ob sie Schwellenwerte basierend auf Qualitätsbewertungen erfüllen. Das Patent definiert einen „Qualitätsfaktor“ nicht speziell, aber Google hat mehrere Patente zu Qualitätswerten für Websites. Eine großartige Seite von Google darüber, was eine qualitativ hochwertige Website umfasst, ist ein Google-Blogpost von Amit Singhal: Weitere Anleitungen zum Erstellen hochwertiger Websites.
3. Rangfolge der Ergebnisse – Wie könnten Websites im Rahmen des Verfahrens aus diesem Patent eingestuft werden? Abfragen aus bestimmten Wissensdomänen (die bestimmte Themen abdecken) können Ergebnisse zurückgeben, bei denen klassifizierte Sites als aus derselben Wissensdomäne stammend verwendet werden. Beispielsweise wird eine medizinische Anfrage, wie etwa die Symptome einer Mononukleose aus einem medizinischen Wissensbereich, am besten von einer Site beantwortet, die als aus einem medizinischen Wissensbereich stammend klassifiziert ist. Das Patent sagt uns auch, dass ein Teil des Zwecks dieses Patents darin besteht, mögliche Ergebnisseiten basierend auf Klassifizierungen unter Einbeziehung von Industrie und Fachwissen zu begrenzen, die ausreichende Qualitätsschwellenwerte erfüllen. Ordnen Sie diese Seiten nach Relevanz- und Autoritätsbewertungen an:
0024] Die Suchergebnisse werden auf der Grundlage von Bewertungen in Bezug auf die durch die Suchergebnisse identifizierten Ressourcen eingestuft, z. . Entsprechend der Reihenfolge werden die Suchergebnisse nach diesen Scores geordnet und dem Benutzergerät entsprechend der Reihenfolge bereitgestellt.
Klassifizierung von Websites
Google teilt uns mit, dass sie Website-Repräsentationsvektoren verwenden können, um Websites basierend auf den auf diesen Websites gefundenen Funktionen zu klassifizieren.
In diesem Beitrag geht es um eine neue Google-Patentanmeldung, die im August 2018 eingereicht und letzte Woche bei der World Intellectual Property Organization (WIPO) veröffentlicht wurde.
Die Patentanmeldung verwendet neuronale Netze, um Muster und Funktionen hinter Websites zu verstehen und diese Websites zu klassifizieren.
Dieses Website-Klassifizierungssystem bezieht sich auf „eine zusammengesetzte Darstellung, z. B. einen Vektor, für eine Website-Klassifizierung innerhalb einer bestimmten Wissensdomäne“.
Diese Wissensdomänen können Themen wie Gesundheit, Finanzen und andere sein. Sites, die in bestimmten Wissensdomänen klassifiziert sind, können von Vorteil sein, wenn sie diese Klassifizierung verwenden, um Suchergebnisse zurückzugeben, wenn sie auf den Empfang einer Suchanfrage antworten.
Diese Website-Klassifizierungen können vielfältiger sein als die Darstellung von Kategorien von Websites innerhalb von Wissensdomänen. Das Patent unterteilt die Kategorien noch viel weiter:
Die Website-Klassifizierungen können beispielsweise die erste Kategorie von Websites umfassen, die von Experten im Wissensbereich erstellt wurden, z. B. Ärzte, die zweite Kategorie von Websites, die von Auszubildenden im Wissensbereich erstellt wurden, z. B. Medizinstudenten, und eine dritte Kategorie von Websites, die erstellt wurden von Laien im Wissensbereich.
Ich erinnere mich an Diskussionen in der SEO-Branche über die Google Quality Raters Guidelines und darin enthaltene Verweise auf EAT oder Expertise, Authority und Trustworthiness. Die Richtlinien weisen auf Gesundheitsseiten mit unterschiedlichen EAT-Stufen hin, ähnlich wie die Klassifikationen aus dieser neuen Google-Patentanmeldung über Website-Repräsentationsvektoren:
Expertise oder Akkreditierung. Schreiben oder produzieren Sie medizinische Ratschläge oder Informationen zu hohen EAT in einem professionellen Stil und sollten regelmäßig bearbeitet, überprüft und aktualisiert werden.
Die Richtlinien sagen uns, dass es Websites gibt, die von Leuten erstellt wurden, die nicht so viel Erfahrung mit Themen haben:
Es ist sogar möglich, alltägliches Fachwissen zu YMYL-Themen zu haben. Zum Beispiel gibt es Foren und Supportseiten für Menschen mit bestimmten Krankheiten. Der Austausch persönlicher Erfahrungen ist eine Form alltäglichen Fachwissens. Betrachten Sie dieses Beispiel.
Hier erzählen Forumsteilnehmer, wie lange ihre Lieben mit Leberkrebs gelebt haben. Dies ist ein Beispiel für das Teilen
persönliche Erfahrungen (in denen sie Experten sind), kein medizinischer Rat. Spezifische medizinische Informationen und Ratschläge (eher
als Beschreibungen von Lebenserfahrungen) sollten von Ärzten oder anderen Angehörigen der Gesundheitsberufe stammen.
Die Klassifikationen umfassen eine Expertenebene von Websites im Gesundheitsbereich, eine Lehrlingsebene von Websites und eine Laienebene von Websites.
Diese Klassifikationen stammen aus unterschiedlichen Erfahrungsstufen. Dieses Patent sagt uns, dass es auch Seiten basierend auf Autorität bewertet, sagt aber nichts über die Vertrauenswürdigkeit aus, also bewertet es Websites nicht vollständig basierend auf EAT. Dieser Prozess erfasst zwei Aspekte von EAT, sodass er einen Teil des Ziels der Quality Raters Guidelines erfüllen kann, indem er menschlichen Bewertern ermöglicht, über Websites zu verfügen, die ein gutes Ranking aufweisen und ein hohes Maß an Autorität und Expertise aufweisen.
Wenn dieser Prozess außerdem die Anzahl der Websites begrenzt, von denen Google Suchergebnisse basierend auf der Wissensdomäne zurückgeben muss, bedeutet dies, dass Google weniger Websites durchsucht, um Ergebnisse zurückzugeben, als der gesamte Index des Webs von Google. Schauen wir uns den Prozess hinter dieser Patentanmeldung etwas genauer an.
Es klassifiziert viele Websites in bestimmte Wissensdomänen und versucht, verschiedene Ebenen von Websites innerhalb dieser bestimmten Wissensdomänen zu finden:
- Empfangen von Darstellungen von Websites und Qualitätsbewertungen, die Qualitätsmaße von Websites im Vergleich zu anderen Websites darstellen
- Klassifizieren als erste Websites, wobei jede Site einen Qualitätsfaktor unter einem ersten Schwellenwert aufweist, wobei mindestens eine der Anzahl von Sites einen Qualitätsfaktor unter dem ersten Schwellenwert aufweist
- Klassifizieren als zweite Websites, wobei jede der Websites Qualitätsbewertungen über einem zweiten Schwellenwert aufweist, die über dem ersten Schwellenwert liegen, wobei mindestens eine der Anzahl von Websites einen Qualitätsfaktor über dem ersten Schwellenwert aufweist
- Generieren einer ersten zusammengesetzten Darstellung der als erste Websites klassifizierten Websites
- Generieren Sie eine zweite zusammengesetzte Darstellung der als zweite Websites klassifizierten Websites
- Erhalten Sie eine Darstellung einer anderen Website
- Bestimmen eines ersten Maßes der Differenz zwischen der ersten zusammengesetzten Darstellung und der Darstellung
- Bestimmen des zweiten Maßes der Differenz zwischen der zweiten zusammengesetzten Darstellung und der Darstellung
- Klassifizieren Sie basierend auf dem ersten Differenzmaß und dem zweiten Differenzmaß die andere Website als eine der ersten Websites, der zweiten Websites oder als dritte Websites, die weder als erste Websites noch als zweite Websites klassifiziert sind

Abfragen fordern Antworten von bestimmten Wissensdomänen an
Die Patentanmeldung teilt uns mit, dass ihr Prozess die Verwendung von Begriffen aus der Abfrage umfasst, um zu verstehen, dass die Abfrage reaktionsfähige Daten aus einem bestimmten Wissensbereich anfordert.
Es kann nach Antworten aus diesem bestimmten Wissensbereich suchen. Der Prozess umfasst:
- Generieren von vorverarbeiteten Antworten auf zukünftige Abfragen aus den maßgeblichen Datenquellen
- Empfangen, nach dem Generieren der vorverarbeiteten Antworten, einer Anfrage, die die bestimmte Wissensdomäne bestimmt oder zeigt
- Als Antwort auf die Anfrage mit einer der vorverarbeiteten Antworten antworten
Vorteile dieses Website-Repräsentationsvektoren-Ansatzes
Das Suchsystem kann Daten nur für Websites mit einer bestimmten Klassifizierung auswählen, durchsuchen oder beides, wodurch Computerressourcen reduziert werden, die zum Auffinden von Suchergebnissen erforderlich sind, z. B. indem keine Website unabhängig von der Klassifizierung ausgewählt oder durchsucht wird oder beides. Das kann:

- Reduzieren Sie den Speicherplatz, der zum Speichern von Daten für potenzielle Suchergebnisse erforderlich ist, z. B. benötigen Sie möglicherweise nur Datenspeicher für Websites mit der bestimmten Klassifizierung
- Reduzieren Sie viele vom Suchsystem analysierte Websites, z. B. durch Einschränken einer Suche auf Websites mit der bestimmten Klassifizierung
- Reduzieren Sie die Netzwerkbandbreite, die verwendet wird, um Suchergebnisse für ein anforderndes Gerät bereitzustellen
- Beheben Sie potenzielle Probleme mit früheren Systemen, wie z. B. höhere Nutzung von Bandbreite, Speicher, Prozessorzyklen, Leistung oder einer Kombination aus zwei oder mehr davon
- Verbessern Sie die von einem Suchsystem generierten Suchergebnisseiten, indem Sie nur Websites mit einer bestimmten Klassifizierung, z. B. einer qualitativen Klassifizierung, in die generierten Suchergebnisseiten identifizieren
- Verwenden Sie Merkmale, die Sie von bestehenden Websites gelernt haben, um zuvor nicht angezeigte Websites zu klassifizieren, ohne dass Benutzereingaben für die Klassifizierung erforderlich sind
- Erkennen Sie Websites, die eher auf Anfragen für eine Wissensdomäne reagieren, z
- Verwenden Sie eine zusammengesetzte Darstellung, die auf bestehenden Website-Klassifikationen basiert, was bedeutet, dass die von der Klassifizierung verwendeten Merkmale nicht durch vom Menschen erkennbare Merkmale eingeschränkt sind und jedes Merkmal sein können, das durch die Analyse der Website erlernt werden kann
Beachten Sie, dass es hilft, Sites zu identifizieren, die für verschiedene Wissensdomänen maßgebend sind.
Diese Website-Repräsentationsvektor-Patentanmeldung befindet sich unter:
Website-Repräsentationsvektor zum Generieren von Suchergebnissen und Klassifizieren der Website
Publikationsnummer: WO2020033805
Bewerber: GOOGLE LLC
Erfinder: Yevgen Tsykynovskyy
Veröffentlichungsnummer WO/2020/033805
Gespeichert: 10. August 2018
Erscheinungsdatum 13. Februar 2020
Abstrakt:
Verfahren, Systeme und Vorrichtungen, einschließlich Computerprogrammen, die auf Computerspeichermedien kodiert sind, verwenden Website-Darstellungen, um Suchergebnisse zu generieren, zu speichern oder beides. Eines der Verfahren umfasst das Empfangen von Daten, die jede Website in der ersten Vielzahl von Websites darstellen, die einer ersten Wissensdomäne einer Vielzahl von Wissensdomänen zugeordnet sind und eine erste Klassifikation aufweisen; Empfangen von Daten, die jede Website in der zweiten Vielzahl von Websites darstellen, die der ersten Wissensdomäne zugeordnet sind und eine zweite Klassifikation aufweisen; Erzeugen einer ersten zusammengesetzten Darstellung der ersten Vielzahl von Websites; Erzeugen einer zweiten zusammengesetzten Darstellung der zweiten Vielzahl von Websites; Empfangen einer Darstellung einer dritten Website; Bestimmen eines ersten Differenzmaßes zwischen der ersten zusammengesetzten Darstellung und der Darstellung; Bestimmen eines zweiten Differenzmaßes zwischen der zweiten zusammengesetzten Darstellung und der Darstellung; und basierend auf dem ersten Differenzmaß und dem zweiten Differenzmaß, Klassifizieren der dritten Website.
Daten aus dem Web-Klassifizierungssystem
Die Suchmaschine kann Daten aus diesem Klassifizierungssystem für Website-Repräsentationsvektoren verwenden, um Suchergebnisse zurückzugeben.
Dieses Klassifizierungssystem kann Darstellungen für jede der vielen Websites AN verwenden und die Darstellungen verwenden, um eine Klassifizierung für jede der vielen Websites AN zu bestimmen.
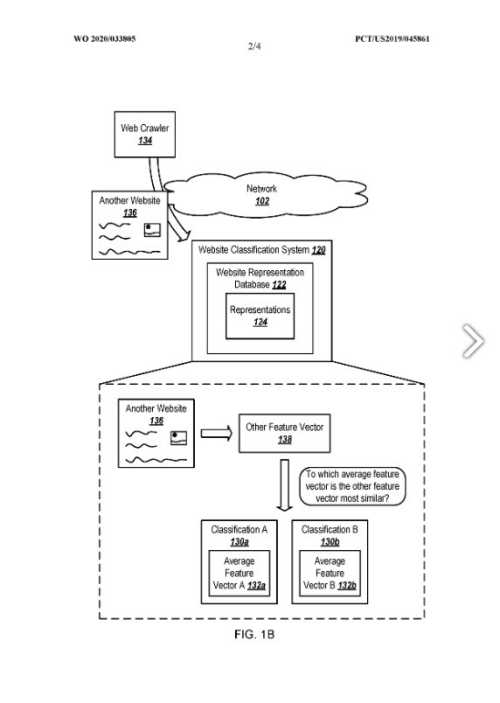
Die Suchmaschine entscheidet sich für eine Klassifizierung für eine Suchanfrage, um eine Kategorie von Websites mit derselben oder einer ähnlichen Klassifizierung auszuwählen.
Es kann Suchergebnisse aus dieser Kategorie von Websites zurückgeben.
Die Klassifizierungen von Sites hängen von den Funktionen ab, die die Sites enthalten.
Klassifizierung von Websites im Website-Repräsentationsvektoren-Patent
Dies war der Teil der Patentbeschreibung, den ich am meisten interessierte.
Es beginnt damit, dass wir uns sagen, dass das Klassifikationssystem für Repräsentationsvektoren dieser Website jede geeignete Methode zum Generieren von Klassifikationen verwenden könnte, was Google viel Flexibilität bietet.
Aber dann geht es ins Detail, indem es uns sagt, dass die Klassifizierung von Inhalten von Websites abhängt, um Darstellungen dieser Websites zu generieren.
Dieser Inhalt kann umfassen:
- Text von der Website
- Bilder auf der Website
- Andere Website-Inhalte, z. B. Links
- Oder eine Kombination aus zwei oder mehr davon
Das Patent enthält dann Details darüber, wie ein neuronales Netzwerk involviert ist:
Das Website-Klassifizierungssystem kann eine Zuordnung verwenden, die den Website-Inhalt für Website A auf einen Vektorraum abbildet, der eine Darstellung für Website A darstellt.
Zum Beispiel kann das Website-Klassifizierungssystem ein neuronales Netz verwenden, das die Abbildung darstellt, um einen Merkmalsvektor A zu erzeugen, der die Website A darstellt, wobei der Inhalt der Website A als Eingabe in das neuronale Netz verwendet wird.
Etiketten, die in Website-Repräsentationsvektoren verwendet werden
Die Klassifizierung von Websites erfordert möglicherweise die Verwendung von Labels. Die Etiketten:
- Kann alphanumerische, numerische oder alphabetische Zeichen, Symbole oder eine Kombination aus zwei oder mehr davon sein
- Kann einen Unternehmenstyp angeben, für den die entsprechende Website veröffentlicht wurde, z. B. ein gemeinnütziges oder ein gewinnorientiertes Unternehmen
- Meine Show eine auf der a-Site beschriebene Branche, z. B. über künstliche Intelligenz oder Bildung
- Kann eine Art von Person angeben, die eine Site erstellt hat, z. B. ein Arzt, ein Medizinstudent oder ein Laie
- Könnten auch Scores sein, die eine Website-Klassifizierung darstellen
Die Scores für Klassifikationen könnten verwendet werden:
- Um verschiedene Schwellenwerte zu erfüllen, um Kategorien zu erfüllen
- Kann spezifisch für einen bestimmten Wissensbereich sein
- So klassifizieren Sie eine Site, um mehr als eine Wissensdomäne abzudecken
- Um Websites auszuwählen, die auf viele Abfragen für bestimmte Wissensdomänen reagieren
- Mit Autorität der jeweiligen Website für die jeweilige Wissensdomäne
- Oder beides
Eingabedaten, die zum Klassifizieren von Websites verwendet werden, können Folgendes umfassen:
- Eine Position bestimmter Wörter zueinander, z. B. dass das Wort „künstlich“ im Allgemeinen in der Nähe oder neben dem Wort „Intelligenz“ steht.
- Bestimmte Sätze auf der Website
- Für jede der Klassifikationen AB ein Differenzmaß oder ein Ähnlichkeitsmaß, das eine Ähnlichkeit zwischen der jeweiligen Klassifikation und der anderen Website darstellt
- Die ähnlichste Klassifikation AB
- Die Klassifikation AB mit dem höchsten Ähnlichkeitsmaß bzw. mit dem kürzesten Abstand zwischen dem anderen Merkmalsvektor und dem jeweiligen mittleren Merkmalsvektor AB, um nur einige Beispiele zu nennen
- Ein Verhältnis zwischen zwei Ähnlichkeitsmaßen, um eine Klassifizierung für die andere Website auszuwählen
Dieses Patent für Website-Repräsentationsvektoren zeigt uns verschiedene andere Möglichkeiten, wie Daten während des Klassifizierungsprozesses durchlaufen können.
Qualitätsfaktoren, die eine Klassifizierung einer Site anzeigen, können ein Maß für Folgendes sein:
- Autorität
- Reaktionsfähigkeit für eine bestimmte Wissensdomäne
- Eine weitere Eigenschaft der Website
- Oder eine Kombination aus zwei oder mehr davon
Erkenntnisse aus dieser Website-Repräsentationsvektoren-Klassifizierungsmethode
Zuletzt aktualisiert am 23. Februar 2020