
Qu'est-ce que la régression logistique ? Apprenez quand l'utiliser
Publié: 2021-07-29La vie est pleine de choix binaires difficiles.
Dois-je avoir cette part de pizza ou pas ? Dois-je porter un parapluie ou non?
Alors que certaines décisions peuvent être prises à juste titre en pesant le pour et le contre – par exemple, il vaut mieux ne pas manger une tranche de pizza car elle contient des calories supplémentaires – certaines décisions peuvent ne pas être aussi faciles.
Par exemple, vous ne pouvez jamais être sûr qu'il pleuvra ou non un jour précis. La décision de porter ou non un parapluie est donc difficile à prendre.
Pour faire le bon choix, il faut des capacités prédictives. Cette capacité est très lucrative et a de nombreuses applications dans le monde réel, en particulier dans les ordinateurs. Les ordinateurs aiment les décisions binaires. Après tout, ils parlent en code binaire.
Apprentissage automatique Les algorithmes, plus précisément l' algorithme de régression logistique , peuvent aider à prédire la probabilité d'événements en examinant des points de données historiques. Par exemple, il peut prédire si un individu gagnera les élections ou s'il pleuvra aujourd'hui.
Qu'est-ce que la régression logistique ?
La régression logistique est une méthode statistique utilisée pour prédire le résultat d'une variable dépendante sur la base d'observations précédentes. C'est un type d'analyse de régression et c'est un algorithme couramment utilisé pour résoudre les problèmes de classification binaire.
Si vous vous demandez ce qu'est l'analyse de régression , il s'agit d'un type de technique de modélisation prédictive utilisée pour trouver la relation entre une variable dépendante et une ou plusieurs variables indépendantes.
Un exemple de variables indépendantes est le temps passé à étudier et le temps passé sur Instagram. Dans ce cas, les notes seront la variable dépendante. En effet, à la fois le « temps passé à étudier » et le « temps passé sur Instagram » influenceraient les notes ; l'un positivement et l'autre négativement.
La régression logistique est un algorithme de classification qui prédit un résultat binaire basé sur une série de variables indépendantes. Dans l'exemple ci-dessus, cela signifierait prédire si vous réussirez ou échouerez une classe. Bien sûr, la régression logistique peut également être utilisée pour résoudre des problèmes de régression, mais elle est principalement utilisée pour des problèmes de classification.
Conseil : utilisez un logiciel d'apprentissage automatique pour automatiser les tâches monotones et prendre des décisions basées sur les données.
Un autre exemple serait de prédire si un étudiant sera accepté dans une université. Pour cela, plusieurs facteurs tels que le score SAT, la moyenne pondérée cumulative de l'élève et le nombre d'activités parascolaires seront pris en compte. À l'aide de données historiques sur les résultats précédents, l'algorithme de régression logistique classera les étudiants en catégories « accepter » ou « rejeter ».
La régression logistique est également appelée régression logistique binomiale ou régression logistique binaire. S'il existe plus de deux classes de la variable de réponse, on parle de régression logistique multinomiale . Sans surprise, la régression logistique a été empruntée aux statistiques et est l'un des algorithmes de classification binaire les plus courants en apprentissage automatique et en science des données.
Le saviez-vous? Une représentation de réseau de neurones artificiels (ANN) peut être considérée comme empilant un grand nombre de classificateurs de régression logistique.
La régression logistique fonctionne en mesurant la relation entre la variable dépendante (ce que nous voulons prédire) et une ou plusieurs variables indépendantes (les caractéristiques). Pour ce faire, il estime les probabilités à l'aide de sa fonction logistique sous-jacente.
Termes clés de la régression logistique
Comprendre la terminologie est crucial pour déchiffrer correctement les résultats de la régression logistique. Savoir ce que signifient des termes spécifiques vous aidera à apprendre rapidement si vous débutez dans les statistiques ou l'apprentissage automatique.
- Variable : Tout nombre, caractéristique ou quantité pouvant être mesuré ou compté. L'âge, la vitesse, le sexe et le revenu en sont des exemples.
- Coefficient : un nombre, généralement un nombre entier, multiplié par la variable qu'il accompagne. Par exemple, dans 12y, le nombre 12 est le coefficient.
- EXP : forme abrégée d'exponentielle.
- Valeurs aberrantes : points de données qui diffèrent considérablement des autres.
- Estimateur : algorithme ou formule qui génère des estimations de paramètres.
- Test du chi carré : également appelé test du chi carré, il s'agit d'une méthode de test d'hypothèse pour vérifier si les données sont conformes aux attentes.
- Erreur standard : L'écart type approximatif d'un échantillon de population statistique.
- Régularisation : une méthode utilisée pour réduire l'erreur et le surajustement en ajustant une fonction (de manière appropriée) sur l'ensemble de données d'apprentissage.
- Multicolinéarité : Occurrence d'intercorrélations entre deux ou plusieurs variables indépendantes.
- Qualité de l'ajustement : description de la qualité de l'ajustement d'un modèle statistique à un ensemble d'observations.
- Odds ratio : mesure de la force de l'association entre deux événements.
- Fonctions de log-vraisemblance : évaluent la qualité d'ajustement d'un modèle statistique.
- Test de Hosmer-Lemeshow : un test qui évalue si les taux d'événements observés correspondent aux taux d'événements attendus.
Qu'est-ce qu'une fonction logistique ?
La régression logistique tire son nom de la fonction utilisée en son cœur, la fonction logistique . Les statisticiens l'ont d'abord utilisé pour décrire les propriétés de la croissance démographique. La fonction sigmoïde et la fonction logit sont quelques variantes de la fonction logistique. La fonction logit est l'inverse de la fonction logistique standard.
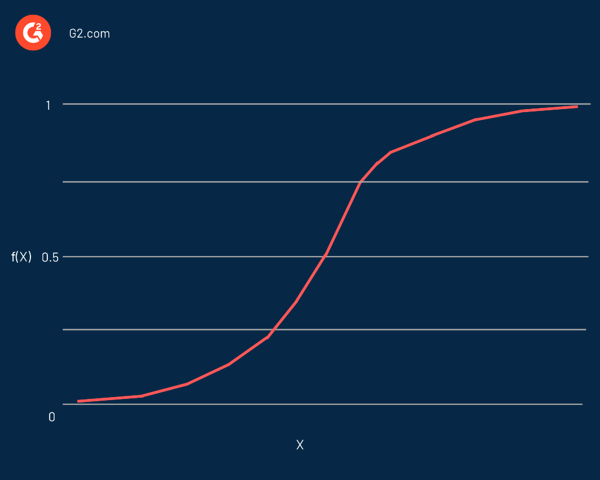
En effet, il s'agit d'une courbe en forme de S capable de prendre n'importe quel nombre réel et de le cartographier en une valeur comprise entre 0 et 1, mais jamais précisément à ces limites. Il est représenté par l'équation :
f(x) = L / 1 + e^-k(x - x0)
Dans cette équation :
- f(X) est la sortie de la fonction
- L est la valeur maximale de la courbe
- e est la base des logarithmes naturels
- k est la pente de la courbe
- x est le nombre réel
- x0 est les valeurs x du point médian sigmoïde
Si la valeur prédite est une valeur négative considérable, elle est considérée comme proche de zéro. En revanche, si la valeur prédite est une valeur positive significative, elle est considérée comme proche de un.
La régression logistique est représentée de la même manière que la régression linéaire est définie à l'aide de l'équation d'une ligne droite. Une différence notable par rapport à la régression linéaire est que la sortie sera une valeur binaire (0 ou 1) plutôt qu'une valeur numérique.
Voici un exemple d'équation de régression logistique :
y = e^(b0 + b1*x) / (1 + e^(b0 + b1*x))
Dans cette équation :
- y est la valeur prédite (ou la sortie)
- b0 est le biais (ou le terme d'interception)
- b1 est le coefficient de l'entrée
- x est la variable prédictive (ou l'entrée)
La variable dépendante suit généralement la Distribution de Bernoulli. Les valeurs des coefficients sont estimées à l'aide de l'estimation du maximum de vraisemblance (MLE) , de la descente de gradient et de la descente de gradient stochastique .
Comme avec d'autres algorithmes de classification comme le k-plus proches voisins, a matrice de confusion est utilisé pour évaluer la précision de l'algorithme de régression logistique.
Le saviez-vous? La régression logistique fait partie d'une famille plus large de modèles linéaires généralisés (GLM).
Tout comme pour évaluer les performances d'un classificateur, il est tout aussi important de savoir pourquoi le modèle a classé une observation d'une manière particulière. En d'autres termes, nous avons besoin que la décision du classifieur soit interprétable.
Bien que l'interprétabilité ne soit pas facile à définir, son intention première est que les humains sachent pourquoi un algorithme a pris une décision particulière. Dans le cas de la régression logistique, elle peut être combinée avec des tests statistiques comme le Essai Wald ou la test du rapport de vraisemblance pour l'interprétabilité.
Quand utiliser la régression logistique
La régression logistique est appliquée pour prédire la variable dépendante catégorielle. En d'autres termes, il est utilisé lorsque la prédiction est catégorique, par exemple, oui ou non, vrai ou faux, 0 ou 1. La probabilité prédite ou le résultat de la régression logistique peut être l'un ou l'autre, et il n'y a pas de terrain d'entente.
Dans le cas des variables prédictives, elles peuvent appartenir à l'une des catégories suivantes :
- Données continues : données mesurables à l'infini. Il peut prendre n'importe quelle valeur entre deux nombres. Des exemples sont le poids en livres ou la température en Fahrenheit.
- Données nominales discrètes : données qui correspondent à des catégories nommées. Un exemple rapide est la couleur des cheveux : blond, noir ou brun.
- Données discrètes et ordinales : données qui s'inscrivent dans une certaine forme d'ordre sur une échelle. Un exemple indique à quel point vous êtes satisfait d'un produit ou d'un service sur une échelle de un à cinq.
L'analyse de régression logistique est utile pour prédire la probabilité d'un événement. Il aide à déterminer les probabilités entre deux classes.

En un mot, en examinant les données historiques, la régression logistique peut prédire si :
- Un email est un spam
- Il va pleuvoir aujourd'hui
- Une tumeur est mortelle
- Un particulier achètera une voiture
- Une transaction en ligne est frauduleuse
- Un candidat gagnera une élection
- Un groupe d'utilisateurs achètera un produit
- Un titulaire de police d'assurance expirera avant l'expiration de la durée de la police
- Un destinataire d'e-mails promotionnels est un répondeur ou un non-répondant
Essentiellement, la régression logistique aide à résoudre les problèmes de probabilité et de classification . En d'autres termes, vous ne pouvez vous attendre qu'à des résultats de classification et de probabilité de la régression logistique.
Par exemple, il peut être utilisé pour déterminer la probabilité que quelque chose soit "vrai ou faux" et aussi pour décider entre deux résultats comme "oui ou non".
Un modèle de régression logistique peut également aider à classer les données pour les opérations d'extraction, de transformation et de chargement (ETL). La régression logistique ne doit pas être utilisée si le nombre d'observations est inférieur au nombre d'entités. Sinon, cela peut conduire à un surajustement.
Régression linéaire vs régression logistique
Alors que la régression logistique prédit la variable catégorielle pour une ou plusieurs variables indépendantes, régression linéaire prédit la variable continue. En d'autres termes, la régression logistique fournit une sortie constante, tandis que la régression linéaire offre une sortie continue.
Puisque le résultat est continu en régression linéaire, il existe une infinité de valeurs possibles pour le résultat. Mais pour la régression logistique, le nombre de valeurs de résultats possibles est limité.
Dans la régression linéaire, les variables dépendantes et indépendantes doivent être liées de manière linéaire. Dans le cas de la régression logistique, les variables indépendantes doivent être liées linéairement à la cotes du journal (log (p/(1-p)).
Conseil : La régression logistique peut être implémentée dans n'importe quel langage de programmation utilisé pour l'analyse de données, tel que R, Python, Java et MATLAB.
Alors que la régression linéaire est estimée à l'aide de la méthode des moindres carrés ordinaires, la régression logistique est estimée à l'aide de l'approche d'estimation du maximum de vraisemblance.
La régression logistique et linéaire sont apprentissage automatique supervisé algorithmes et les deux principaux types d'analyse de régression. Alors que la régression logistique est utilisée pour résoudre les problèmes de classification, la régression linéaire est principalement utilisée pour les problèmes de régression.
Pour reprendre l'exemple du temps passé à étudier, la régression linéaire et la régression logistique peuvent prédire différentes choses. La régression logistique peut aider à prédire si l'étudiant a réussi ou non un examen. En revanche, la régression linéaire peut prédire le score de l'élève.
Hypothèses de régression logistique
Lors de l'utilisation de la régression logistique, nous faisons quelques hypothèses. Les hypothèses font partie intégrante de l'utilisation correcte de la régression logistique pour faire des prédictions et résoudre des problèmes de classification.
Voici les principales hypothèses de la régression logistique :
- Il y a peu ou pas de multicolinéarité entre les variables indépendantes.
- Les variables indépendantes sont linéairement liées au log des cotes (log (p/(1-p)).
- La variable dépendante est dichotomique ou binaire ; il s'inscrit dans deux catégories distinctes. Cela s'applique uniquement à la régression logistique binaire, qui est discutée plus tard.
- Il n'y a pas de variables non significatives car elles pourraient conduire à des erreurs.
- Les tailles d'échantillon de données sont plus grandes , ce qui est intégral pour de meilleurs résultats.
- Il n'y a pas de valeurs aberrantes .
Types de régression logistique
La régression logistique peut être divisée en différents types en fonction du nombre de résultats ou de catégories de la variable dépendante.
Lorsque nous pensons à la régression logistique, nous pensons très probablement à la régression logistique binaire. Dans la plupart des parties de cet article, lorsque nous faisions référence à la régression logistique, nous faisions référence à la régression logistique binaire.
Voici les trois principaux types de régression logistique.
Régression logistique binaire
La régression logistique binaire est une méthode statistique utilisée pour prédire la relation entre une variable dépendante et une variable indépendante. Dans cette méthode, la variable dépendante est une variable binaire, c'est-à-dire qu'elle ne peut prendre que deux valeurs (oui ou non, vrai ou faux, succès ou échec, 0 ou 1).
Un exemple simple de régression logistique binaire consiste à déterminer si un e-mail est un spam ou non.
Régression logistique multinomiale
La régression logistique multinomiale est une extension de la régression logistique binaire. Il permet plus de deux catégories de résultat ou de variable dépendante.
C'est similaire à la régression logistique binaire mais peut avoir plus de deux résultats possibles. Cela signifie que la variable de résultat peut avoir au moins trois types non ordonnés possibles - des types n'ayant aucune signification quantitative. Par exemple, la variable dépendante peut représenter "Type A", "Type B" ou "Type C".
Semblable à la régression logistique binaire, la régression logistique multinomiale utilise également l'estimation du maximum de vraisemblance pour déterminer la probabilité.
Par exemple, la régression logistique multinomiale peut être utilisée pour étudier la relation entre l'éducation et les choix professionnels. Ici, les choix professionnels seront la variable dépendante qui se compose de catégories de différentes professions.
Régression logistique ordinale
La régression logistique ordinale , également appelée régression ordinale, est une autre extension de la régression logistique binaire. Il est utilisé pour prédire la variable dépendante avec trois types ordonnés possibles ou plus - types ayant une signification quantitative. Par exemple, la variable dépendante peut représenter « Fortement en désaccord », « En désaccord », « D'accord » ou « Fortement d'accord ».
Il peut être utilisé pour déterminer le rendement au travail (médiocre, moyen ou excellent) et la satisfaction au travail (insatisfait, satisfait ou très satisfait).
Avantages et inconvénients de la régression logistique
Bon nombre des avantages et des inconvénients du modèle de régression logistique s'appliquent au modèle de régression linéaire. L'un des avantages les plus importants du modèle de régression logistique est qu'il ne se contente pas de classer mais donne également des probabilités.
Voici quelques-uns des avantages de l'algorithme de régression logistique.
- Simple à comprendre, facile à mettre en œuvre et efficace à former
- Fonctionne bien lorsque l'ensemble de données est linéairement séparable
- Bonne précision pour les petits ensembles de données
- Ne fait aucune hypothèse sur la répartition des classes
- Il propose le sens d'association (positif ou négatif)
- Utile pour trouver des relations entre les fonctionnalités
- Fournit des probabilités bien calibrées
- Moins sujet au surajustement dans les ensembles de données de faible dimension
- Peut être étendu à la classification multi-classes
Cependant, la régression logistique présente de nombreux inconvénients. S'il existe une fonctionnalité qui séparerait parfaitement deux classes, le modèle ne peut plus être formé. C'est ce qu'on appelle la séparation complète .
Cela se produit principalement parce que le poids de cette fonctionnalité ne convergerait pas car le poids optimal serait infini. Cependant, dans la plupart des cas, une séparation complète peut être résolue en définissant une distribution de probabilité a priori des poids ou en introduisant une pénalisation des poids.
Voici quelques-uns des inconvénients de l'algorithme de régression logistique :
- Construit des limites linéaires
- Peut conduire à un surajustement si le nombre de caractéristiques est supérieur au nombre d'observations
- Les prédicteurs doivent avoir une multicolinéarité moyenne ou nulle
- Difficile d'obtenir des relations complexes. Les algorithmes comme les réseaux de neurones sont plus adaptés et puissants
- Peut être utilisé uniquement pour prédire des fonctions discrètes
- Impossible de résoudre des problèmes non linéaires
- Sensible aux valeurs aberrantes
Quand la vie vous offre des options, pensez à la régression logistique
Beaucoup pourraient dire que les humains ne vivent pas dans un monde binaire, contrairement aux ordinateurs. Bien sûr, si on vous donne une tranche de pizza et un hamburger, vous pouvez manger les deux sans avoir à en choisir un seul. Mais si vous y regardez de plus près, une décision binaire est gravée sur (littéralement) tout. Vous pouvez choisir de manger ou de ne pas manger une pizza ; il n'y a pas de juste milieu.
L'évaluation des performances d'un modèle prédictif peut être délicate si la quantité de données est limitée. Pour cela, vous pouvez utiliser une technique appelée validation croisée, qui consiste à partitionner les données disponibles en un ensemble d'apprentissage et un ensemble de test.