
データ サイエンティスト向けの最高の Python ライブラリ
公開: 2022-08-12この記事では、データ サイエンティストと機械学習チームに最適な Python ライブラリのいくつかについて言及し、説明します。
Python は、主に提供するライブラリのために、これら 2 つの分野でよく使用される理想的な言語です。
これは、データ サイエンティストや機械学習の専門家がデータの処理や探索に使用するデータ操作操作の中でも特に、データ入出力 I/O やデータ分析などの Python ライブラリのアプリケーションによるものです。
Python ライブラリ、それらは何ですか?
Python ライブラリは、クラスやメソッドなどのコンパイル済みコードを含む組み込みモジュールの広範なコレクションであり、開発者がコードを最初から実装する必要がなくなります。
データ サイエンスと機械学習における Python の重要性
Python には、機械学習とデータ サイエンスの専門家が使用するのに最適なライブラリがあります。
その構文は簡単なので、複雑な機械学習アルゴリズムを効率的に実装できます。 さらに、シンプルな構文は学習曲線を短縮し、理解を容易にします。

Python は、迅速なプロトタイプ開発とアプリケーションのスムーズなテストもサポートします。
Python の大規模なコミュニティは、データ サイエンティストが必要なときにクエリの解決策をすぐに探すのに便利です。
Python ライブラリはどれくらい便利ですか?
Python ライブラリは、機械学習とデータ サイエンスのアプリケーションとモデルの作成に役立ちます。
これらのライブラリは、開発者がコードを再利用できるようにするのに大いに役立ちます。 したがって、車輪を再発明する以外に、プログラム内の特定の機能を実装する関連ライブラリをインポートできます。
機械学習とデータ サイエンスで使用される Python ライブラリ
データ サイエンスの専門家は、データ サイエンスの愛好家が熟知している必要のあるさまざまな Python ライブラリを推奨しています。 アプリケーションでの関連性に応じて、機械学習とデータ サイエンスの専門家は、モデルのデプロイ、データのマイニングとスクレイピング、データ処理、およびデータの視覚化のために、ライブラリに分類されたさまざまな Python ライブラリを適用します。
この記事では、データ サイエンスと機械学習で一般的に使用される Python ライブラリをいくつか紹介します。
それらを見てみましょう。
ナンピー
Numerical Python Code とも呼ばれる Numpy Python ライブラリは、十分に最適化された C コードで構築されています。 データ サイエンティストは、その深遠な数学的計算と科学的計算のためにそれを好みます。
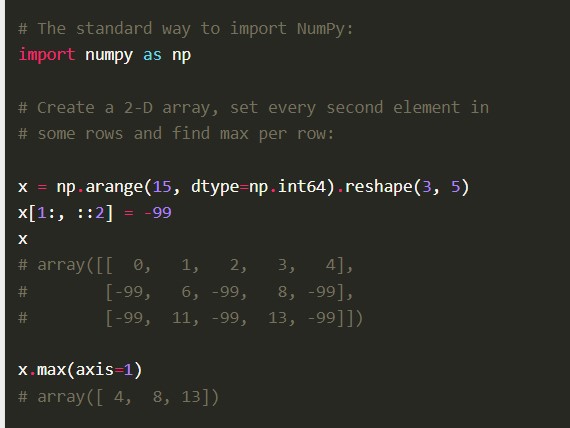
特徴
- Numpy には、経験のあるプログラマーにとって簡単な高レベルの構文があります。
- ライブラリを構成する C コードが最適化されているため、ライブラリのパフォーマンスは比較的高くなります。
- フーリエ変換機能、線形代数、乱数ジェネレーターなどの数値計算ツールがあります。
- これはオープンソースであるため、他の開発者による多数の貢献が可能です。
Numpy には、数学演算のベクトル化、インデックス付け、配列と行列の実装における重要な概念など、その他の包括的な機能が付属しています。
パンダ
Pandas は、機械学習で有名なライブラリであり、大規模なデータセットを簡単かつ効果的に分析するための高レベルのデータ構造と多数のツールを提供します。 非常に少ないコマンドで、このライブラリは複雑な操作をデータに変換できます。
単一および多次元のテーブルに挿入する前に、データのグループ化、インデックス作成、取得、分割、再構築、およびフィルター セットを実行できる多数の組み込みメソッド。 このライブラリを構成します。
Pandas ライブラリの主な機能
- Pandas を使用すると、テーブルへのデータのラベル付けが簡単になり、データの整列とインデックス付けが自動的に行われます。
- JSON や CSV などのデータ形式をすばやく読み込んで保存できます。
優れたデータ分析機能と高い柔軟性により、非常に効率的です。
Matplotlib
Matplotlib 2D グラフィカル Python ライブラリは、多数のソースからのデータを簡単に処理できます。 それが作成するビジュアライゼーションは、ユーザーがズームインできる静的でアニメーション化された対話型であるため、ビジュアライゼーションとチャートの作成が効率的になります。 また、レイアウトとビジュアル スタイルのカスタマイズも可能です。
そのドキュメントはオープン ソースであり、実装に必要なツールの豊富なコレクションを提供します。
Matplotlib はヘルパー クラスをインポートして年、月、日、週を実装し、時系列データを効率的に操作できるようにします。
scikit 学習
複雑なデータを扱うのに役立つライブラリを検討している場合、Scikit-learn は理想的なライブラリです。 機械学習の専門家は、Scikit-learn を広く使用しています。 このライブラリは、NumPy、SciPy、matplotlib などの他のライブラリに関連付けられています。 本番アプリケーションに使用できる教師あり学習アルゴリズムと教師なし学習アルゴリズムの両方を提供します。
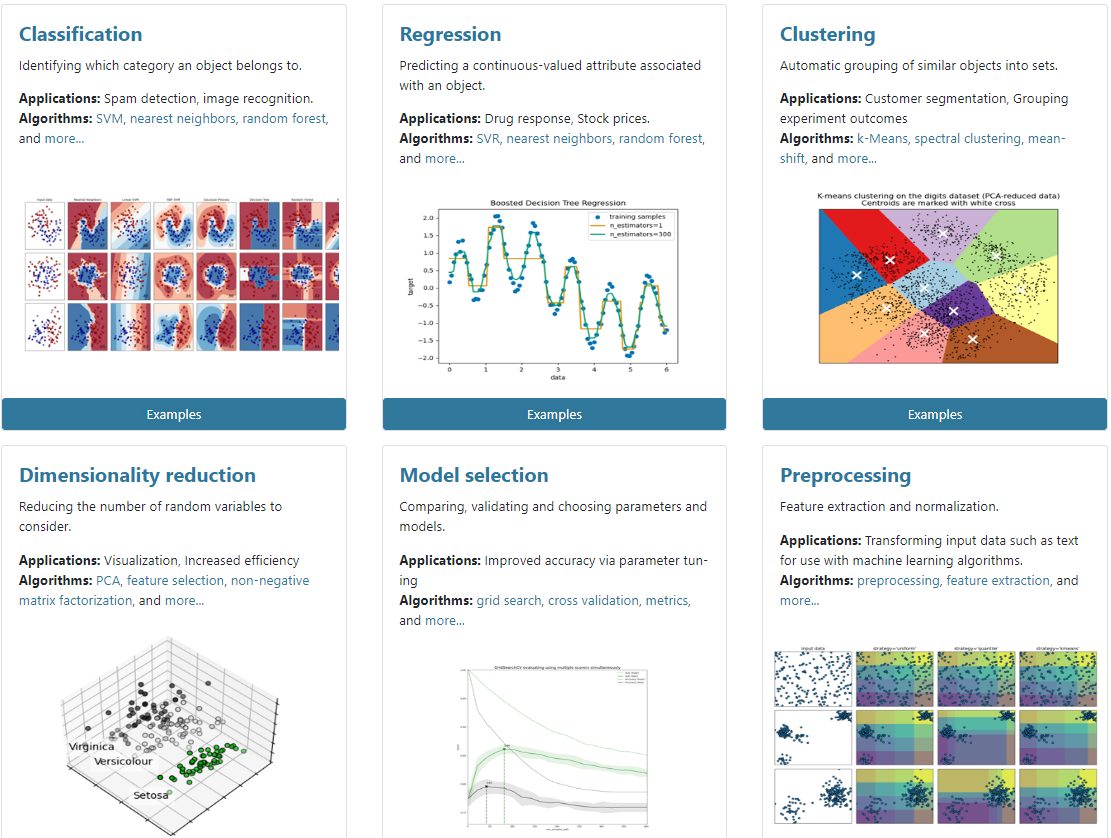
Scikit-learn Python ライブラリの機能
- たとえば、画像認識などのアプリケーションで SVM やランダム フォレストなどのアルゴリズムを使用して、オブジェクト カテゴリを識別します。
- オブジェクトが回帰と呼ばれるタスクに関連付ける連続値属性の予測。
- 特徴抽出。
- 次元削減は、考慮される確率変数の数を削減する場所です。
- 類似オブジェクトのセットへのクラスタリング。
scikit-learn ライブラリは、テキストおよび画像データ セットからの特徴抽出に効率的です。 さらに、目に見えないデータに対する教師ありモデルの精度を確認することもできます。 その多数の利用可能なアルゴリズムにより、データ マイニングやその他の機械学習タスクが可能になります。
SciPy
SciPy (Scientific Python Code) は、広く適用可能な数学関数とアルゴリズムに適用されるモジュールを提供する機械学習ライブラリです。 そのアルゴリズムは、代数方程式、補間、最適化、統計、および統合を解きます。
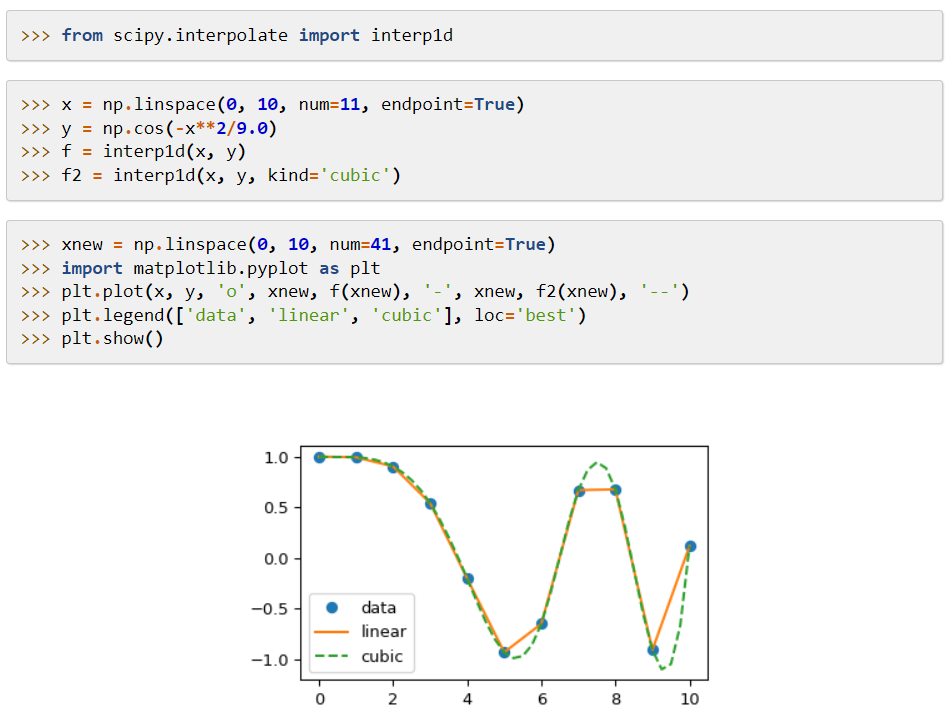
その主な機能は、NumPy への拡張であり、数学関数を解決するツールを追加し、スパース行列のようなデータ構造を提供します。
SciPy は、高レベルのコマンドとクラスを使用して、データを操作および視覚化します。 そのデータ処理とプロトタイプ システムにより、さらに効果的なツールになります。
さらに、SciPy の高レベルの構文により、あらゆる経験レベルのプログラマーが簡単に使用できます。
SciPy の唯一の欠点は、数値オブジェクトとアルゴリズムのみに重点を置いていることです。 したがって、プロット機能を提供することはできません。

PyTorch
この多様な機械学習ライブラリは、GPU アクセラレーションを使用してテンソル計算を効率的に実装し、動的計算グラフと自動勾配計算を作成します。 C で開発されたオープンソースの機械学習ライブラリである Torch ライブラリは、PyTorch ライブラリを構築します。
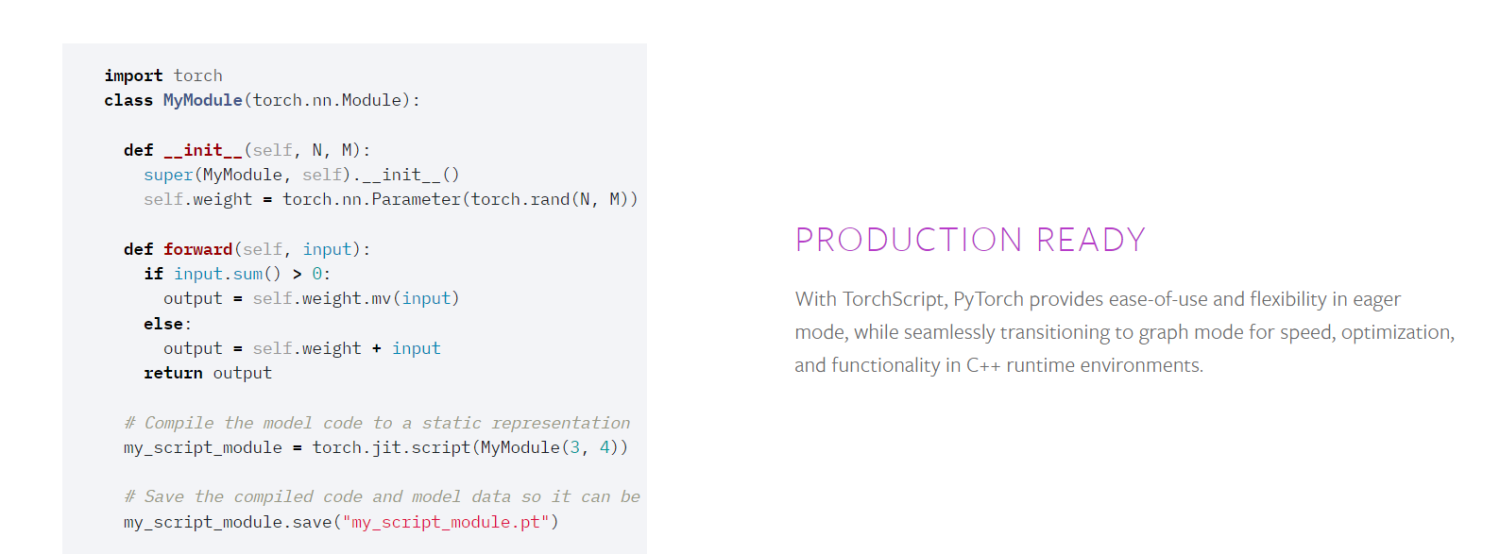
主な機能は次のとおりです。
- 主要なクラウド プラットフォームでの優れたサポートにより、摩擦のない開発とスムーズなスケーリングが提供されます。
- ツールとライブラリの堅牢なエコシステムは、コンピューター ビジョンの開発や、自然言語処理 (NLP) などの他の分野をサポートします。
- TorchServe を使用して本番環境へのパスを高速化しながら、Torch スクリプトを使用して熱心なモードとグラフ モードの間のスムーズな移行を提供します。
- Torch 分散型バックエンドにより、研究と生産における分散トレーニングとパフォーマンスの最適化が可能になります。
NLP アプリケーションの開発に PyTorch を使用できます。
ケラス
Keras は、ディープ ニューラル ネットワークの実験に使用されるオープンソースの機械学習 Python ライブラリです。

モデルのコンパイルやグラフの視覚化などのタスクをサポートするユーティリティを提供することで有名です。 バックエンドには Tensorflow を適用しています。 または、バックエンドで Theano または CNTK などのニューラル ネットワークを使用することもできます。 このバックエンド インフラストラクチャは、操作の実装に使用される計算グラフの作成に役立ちます。
ライブラリの主な機能
- 中央処理装置とグラフィック処理装置の両方で効率的に実行できます。
- Keras は Python ベースであるため、デバッグが容易です。
- Keras はモジュール式であるため、表現力と適応性に優れています。
- モジュールを JavaScript に直接エクスポートしてブラウザーで実行することにより、Keras をどこにでもデプロイできます。
Keras のアプリケーションには、画像やテキスト データの操作を容易にする他のツールの中でも特に、レイヤーや目標などのニューラル ネットワークのビルディング ブロックが含まれます。
シーボーン
Seaborn は、統計データの視覚化におけるもう 1 つの貴重なツールです。
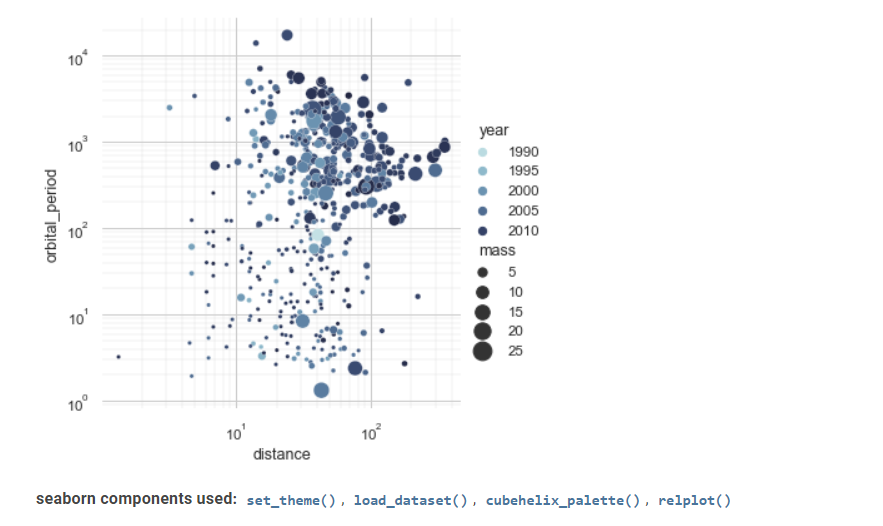
その高度なインターフェースは、魅力的で有益な統計グラフィック描画を実装できます。
あらすじ
Plotly は、Plotly JS ライブラリ上に構築された 3D Web ベースの視覚化ツールです。 折れ線グラフ、散布図、ボックス型のスパークラインなど、さまざまな種類のグラフを幅広くサポートしています。
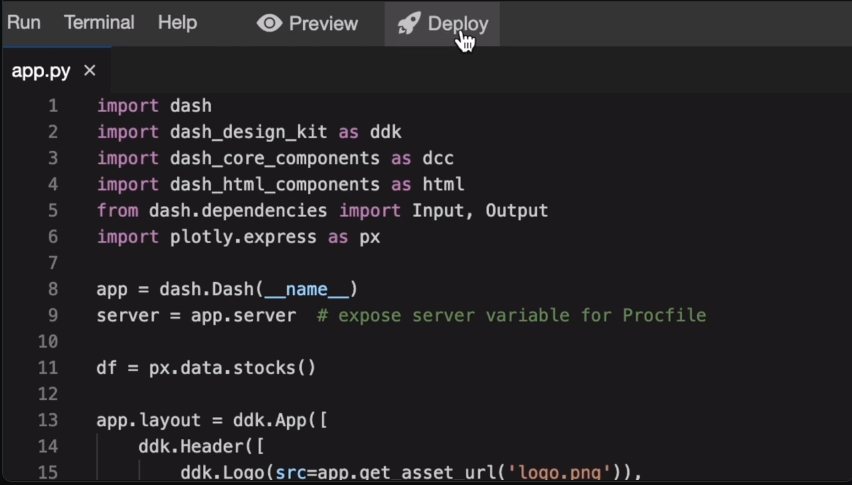
そのアプリケーションには、Jupyter ノートブックでの Web ベースのデータ視覚化の作成が含まれます。
Plotly はホバー ツールでグラフの外れ値や異常を指摘できるため、視覚化に適しています。 好みに合わせてグラフをカスタマイズすることもできます。
Plotly の欠点として、ドキュメントが古くなっています。 したがって、これをガイドとして使用することは、ユーザーにとって難しい場合があります。 さらに、ユーザーが習得する必要のある多数のツールがあります。 それらすべてを追跡するのは難しいかもしれません。
Plotly Python ライブラリの機能
- それが利用する3Dチャートは、相互作用の複数のポイントを可能にします.
- 単純化された構文があります。
- ポイントを共有しながら、コードのプライバシーを維持できます。
シンプルITK
SimpleITK は、Insight Toolkit (ITK) へのインターフェイスを提供する画像解析ライブラリです。 C++ に基づいており、オープンソースです。
SimpleITK ライブラリの特長
- その画像ファイル I/O は、JPG、PNG、DICOM などの最大 20 の画像ファイル形式をサポートし、変換できます。
- Otsu、レベル セット、流域など、多数の画像セグメンテーション ワークフロー フィルターを提供します。
- 画像をピクセルの配列ではなく、空間オブジェクトとして解釈します。
その簡素化されたインターフェイスは、R、C#、C++、Java、Python などのさまざまなプログラミング言語で利用できます。
統計モデル
Statsmodel は、統計モデルを推定し、統計テストを実装し、クラスと関数を使用して統計データを調査します。
モデルの指定には、R スタイルの数式、NumPy 配列、および Pandas データ フレームを使用します。
スクレイピー
このオープンソース パッケージは、Web サイトからデータを取得 (スクレイピング) およびクロールするための推奨ツールです。 これは非同期であるため、比較的高速です。 Scrapy には、効率的なアーキテクチャと機能があります。
反対に、そのインストールはオペレーティング システムによって異なります。 また、JSで構築されたWebサイトでは使用できません。 また、Python 2.7 以降のバージョンでのみ動作します。
データ サイエンスの専門家は、データ マイニングと自動テストにそれを適用します。
特徴
- フィードを JSON、CSV、XML でエクスポートし、複数のバックエンドに保存できます。
- HTML/XML ソースからデータを収集および抽出する機能が組み込まれています。
- 明確に定義された API を使用して Scrapy を拡張できます。
まくら
Pillow は、画像を操作および処理する Python イメージング ライブラリです。
Python インタープリターの画像処理機能を追加し、さまざまなファイル形式をサポートし、優れた内部表現を提供します。
基本的なファイル形式で保存されたデータは、Pillow のおかげで簡単にアクセスできます。
まとめ
以上が、データ サイエンティストと機械学習の専門家向けの最高の Python ライブラリのいくつかの探索をまとめたものです。
この記事が示すように、Python には、より便利な機械学習とデータ サイエンスのパッケージがあります。 Python には、他の領域に適用できる他のライブラリがあります。
いくつかの最高のデータ サイエンス ノートブックについて知りたいと思うかもしれません。
ハッピーラーニング!