
數據科學家的最佳 Python 庫
已發表: 2022-08-12本文為數據科學家和機器學習團隊提到並闡述了一些最好的 Python 庫。
Python 是一種理想的語言,主要用於它提供的庫,主要用於這兩個領域。
這是因為 Python 庫的應用程序,如數據輸入/輸出 I/O 和數據分析,以及數據科學家和機器學習專家用來處理和探索數據的其他數據操作操作。
Python 庫,它們是什麼?
Python 庫是包含預編譯代碼(包括類和方法)的大量內置模塊的集合,從而消除了開發人員從頭開始實現代碼的需要。
Python 在數據科學和機器學習中的重要性
Python 擁有供機器學習和數據科學專家使用的最佳庫。
它的語法很簡單,因此可以高效地實現複雜的機器學習算法。 此外,簡單的語法縮短了學習曲線,使理解更容易。

Python 還支持快速原型開發和應用程序的流暢測試。
Python 的大型社區非常方便數據科學家在需要時輕鬆地為他們的查詢尋求解決方案。
Python 庫有多大用處?
Python 庫有助於在機器學習和數據科學中創建應用程序和模型。
這些庫在幫助開發人員實現代碼可重用性方面大有幫助。 因此,除了重新發明輪子之外,您可以導入在您的程序中實現特定功能的相關庫。
機器學習和數據科學中使用的 Python 庫
數據科學專家推薦了數據科學愛好者必須熟悉的各種 Python 庫。 根據它們在應用程序中的相關性,機器學習和數據科學專家應用不同的 Python 庫,這些庫分為用於部署模型、挖掘和抓取數據、數據處理和數據可視化的庫。
本文確定了數據科學和機器學習中一些常用的 Python 庫。
現在讓我們看看它們。
麻木的
Numpy Python 庫,也是完整的數字 Python 代碼,是用經過優化的 C 代碼構建的。 數據科學家更喜歡它,因為它具有深刻的數學計算和科學計算能力。
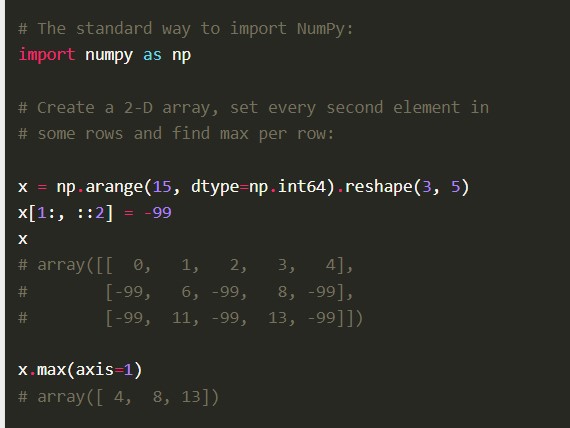
特徵
- Numpy 具有高級語法,使有經驗的程序員可以輕鬆使用。
- 該庫的性能相對較高,因為構成它的 C 代碼經過良好優化。
- 它具有數值計算工具,包括傅立葉變換功能、線性代數和隨機數生成器。
- 它是開源的,因此允許其他開發人員做出大量貢獻。
Numpy 還具有其他綜合功能,例如數學運算的矢量化、索引以及實現數組和矩陣的關鍵概念。
熊貓
Pandas 是機器學習領域的著名庫,它提供高級數據結構和眾多工具來輕鬆有效地分析海量數據集。 只需很少的命令,這個庫就可以用數據翻譯複雜的操作。
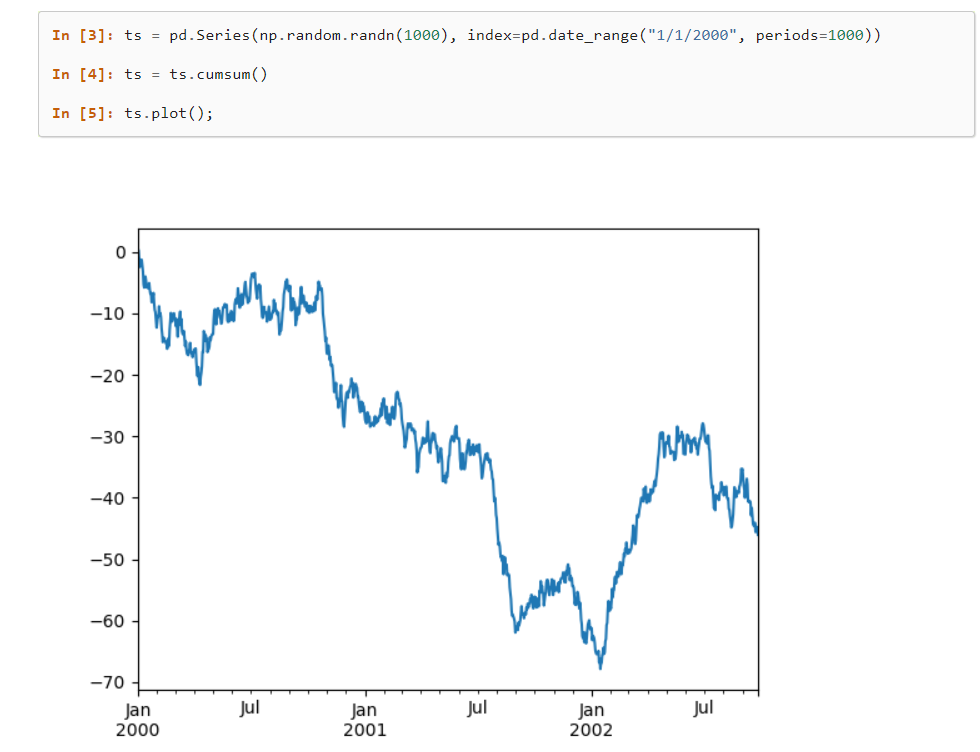
許多內置方法可以在將它們插入單維和多維表之前對數據進行分組、索引、檢索、拆分、重組和過濾集; 組成了這個庫。
Pandas 庫的主要功能
- Pandas 可以輕鬆地將數據標記到表格中,並自動對齊和索引數據。
- 它可以快速加載和保存 JSON 和 CSV 等數據格式。
它具有良好的數據分析功能和高度的靈活性,因此效率很高。
Matplotlib
Matplotlib 2D 圖形 Python 庫可以輕鬆處理來自眾多來源的數據。 它創建的可視化是靜態的、動畫的和交互式的,用戶可以放大它們,從而使其高效地進行可視化和創建圖表。 它還允許自定義佈局和視覺樣式。
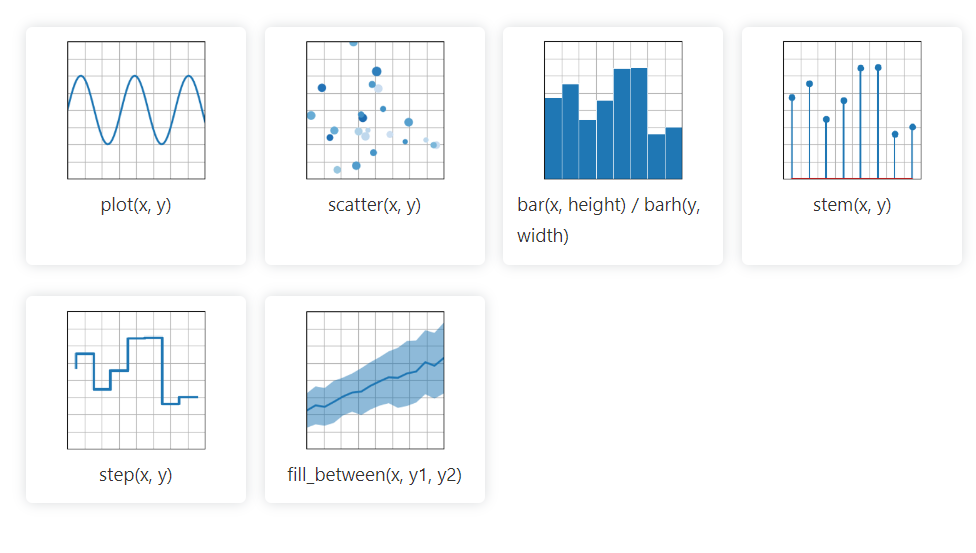
它的文檔是開源的,並提供了實施所需的大量工具。
Matplotlib 導入輔助類來實現年、月、日和周,從而可以高效地操作時間序列數據。
Scikit-學習
如果您正在考慮使用一個庫來幫助您處理複雜數據,那麼 Scikit-learn 應該是您理想的庫。 機器學習專家廣泛使用 Scikit-learn。 該庫與 NumPy、SciPy 和 matplotlib 等其他庫相關聯。 它提供了可用於生產應用的有監督和無監督學習算法。
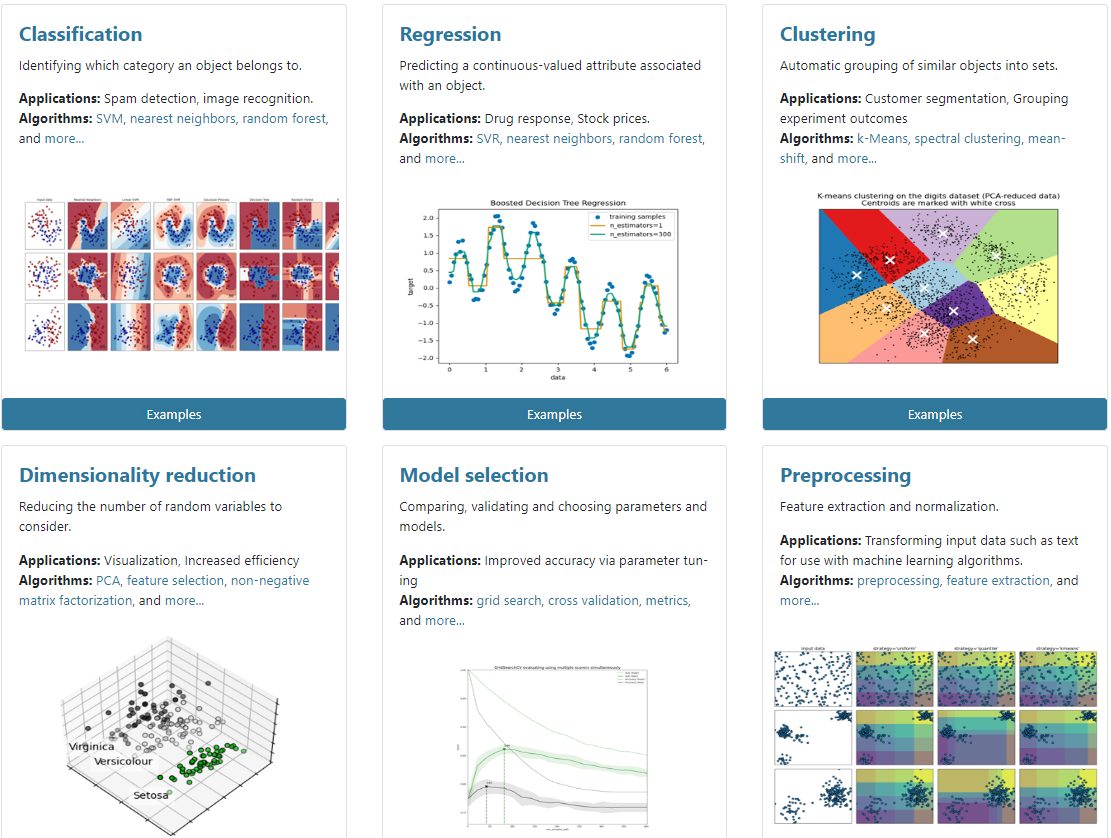
Scikit-learn Python 庫的特點
- 識別對像類別,例如,在圖像識別等應用程序中使用 SVM 和隨機森林等算法。
- 對象與稱為回歸的任務相關聯的連續值屬性的預測。
- 特徵提取。
- 降維是您減少考慮的隨機變量數量的地方。
- 將相似對象聚類成集合。
Scikit-learn 庫在從文本和圖像數據集中提取特徵方面非常有效。 此外,可以檢查未見數據的監督模型的準確性。 其眾多可用算法使數據挖掘和其他機器學習任務成為可能。
科學派
SciPy (Scientific Python Code) 是一個機器學習庫,提供適用於數學函數和算法的模塊,應用廣泛。 它的算法解決代數方程、插值、優化、統計和積分。
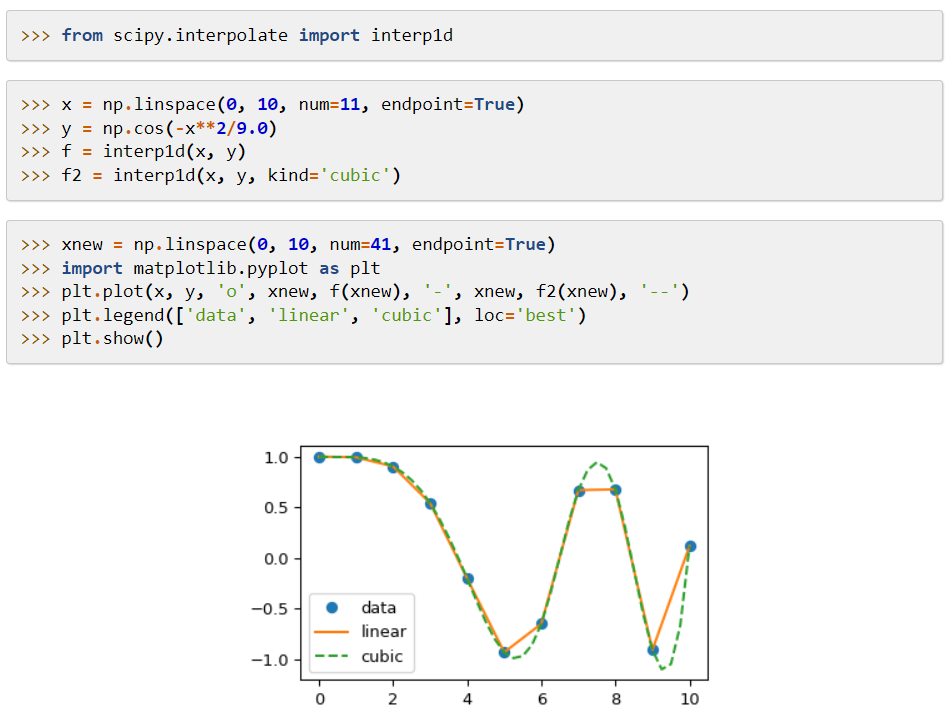
它的主要特點是它對 NumPy 的擴展,它增加了求解數學函數的工具,並提供了像稀疏矩陣這樣的數據結構。
SciPy 使用高級命令和類來操作和可視化數據。 它的數據處理和原型系統使其成為更有效的工具。
此外,SciPy 的高級語法使任何經驗水平的程序員都可以輕鬆使用。
SciPy 唯一的缺點是它只關注數字對象和算法。 因此無法提供任何繪圖功能。
PyTorch
這個多樣化的機器學習庫通過 GPU 加速有效地實現張量計算,創建動態計算圖和自動梯度計算。 Torch 庫是一個基於 C 開發的開源機器學習庫,它構建了 PyTorch 庫。

主要特點包括:
- 由於其對主要雲平台的良好支持,提供了無摩擦開發和平滑擴展。
- 強大的工具和庫生態系統支持計算機視覺開發和自然語言處理 (NLP) 等其他領域。
- 它使用 Torch 腳本在渴望模式和圖形模式之間提供平滑過渡,同時使用 TorchServe 加速其生產路徑。
- Torch 分佈式後端允許在研究和生產中進行分佈式訓練和性能優化。
您可以在開發 NLP 應用程序時使用 PyTorch。
喀拉斯
Keras 是一個開源機器學習 Python 庫,用於試驗深度神經網絡。

它以提供支持模型編譯和圖形可視化等任務的實用程序而聞名。 它將 Tensorflow 應用於其後端。 或者,您可以在後端使用 Theano 或 CNTK 等神經網絡。 這個後端基礎設施幫助它創建用於實現操作的計算圖。
圖書館的主要特點
- 它可以在中央處理器和圖形處理器上高效運行。
- 使用 Keras 進行調試更容易,因為它基於 Python。
- Keras 是模塊化的,因此使其具有表現力和適應性。
- 您可以在任何地方部署 Keras,方法是將其模塊直接導出到 JavaScript 以在瀏覽器上運行。
Keras 的應用包括神經網絡構建塊,如層和目標,以及其他有助於處理圖像和文本數據的工具。
海博恩
Seaborn 是統計數據可視化的另一個有價值的工具。
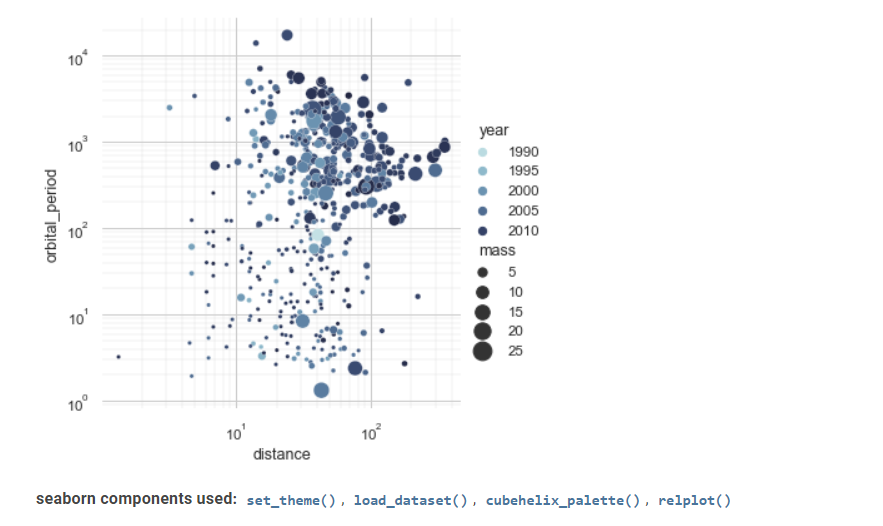
其先進的界面可以實現有吸引力和信息豐富的統計圖形繪圖。
情節
Plotly 是基於 Plotly JS 庫構建的基於 Web 的 3D 可視化工具。 它廣泛支持各種圖表類型,例如折線圖、散點圖和箱型迷你圖。
它的應用程序包括在 Jupyter 筆記本中創建基於 Web 的數據可視化。
Plotly 適合可視化,因為它可以使用懸停工具指出圖表中的異常值或異常。 您還可以自定義圖表以適合您的偏好。
Plotly 的缺點是它的文檔已經過時了。 因此,對於用戶而言,將其用作指南可能會很困難。 此外,它有許多用戶應該學習的工具。 跟踪所有這些可能具有挑戰性。
Plotly Python 庫的特點
- 它提供的 3D 圖表允許多點交互。
- 它有一個簡化的語法。
- 您可以在分享積分的同時維護代碼的隱私。
簡單ITK
SimpleITK 是一個圖像分析庫,為 Insight Toolkit (ITK) 提供接口。 它基於 C++ 並且是開源的。
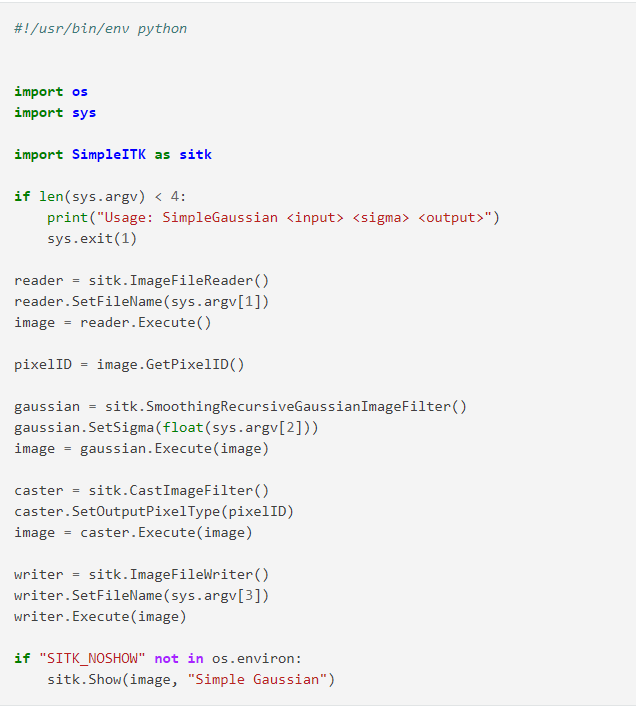
SimpleITK 庫的特點
- 其圖像文件 I/O 支持並可以轉換多達 20 種圖像文件格式,如 JPG、PNG 和 DICOM。
- 它提供了許多圖像分割工作流過濾器,包括 Otsu、水平集和分水嶺。
- 它將圖像解釋為空間對象而不是像素陣列。
其簡化的界面可用於各種編程語言,如 R、C#、C++、Java 和 Python。
統計模型
Statsmodel 估計統計模型,實施統計測試並使用類和函數探索統計數據。
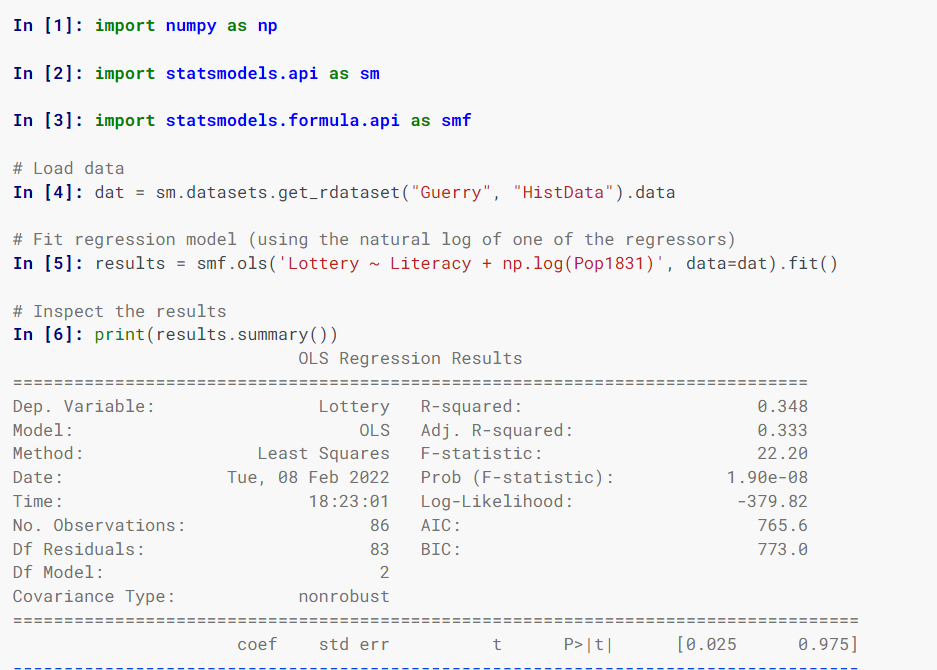
指定模型使用 R 風格的公式、NumPy 數組和 Pandas 數據框。
刮擦
這個開源包是從網站檢索(抓取)和抓取數據的首選工具。 它是異步的,因此相對較快。 Scrapy 具有使其高效的架構和功能。
另一方面,它的安裝因不同的操作系統而異。 此外,您不能在基於 JS 構建的網站上使用它。 此外,它只能與 Python 2.7 或更高版本一起使用。
數據科學專家將其應用於數據挖掘和自動化測試。
特徵
- 它可以以 JSON、CSV 和 XML 格式導出提要,並將它們存儲在多個後端。
- 它具有從 HTML/XML 源收集和提取數據的內置功能。
- 您可以使用定義明確的 API 來擴展 Scrapy。
枕頭
Pillow 是一個 Python 圖像處理庫,用於操作和處理圖像。
它增加了 Python 解釋器的圖像處理功能,支持各種文件格式,並提供了出色的內部表示。
借助 Pillow,可以輕鬆訪問以基本文件格式存儲的數據。
包起來
這總結了我們對數據科學家和機器學習專家的一些最佳 Python 庫的探索。
正如本文所示,Python 有更多有用的機器學習和數據科學包。 Python 有其他庫,您可以在其他領域應用。
您可能想了解一些最好的數據科學筆記本。
快樂學習!