
適切なデータクレンジング戦略でより良い結果を得る [+5 ツール]
公開: 2022-12-01データ分析のために信頼できる一貫したデータを取得する方法を知りたいですか? これらのデータクレンジング戦略を今すぐ実装してください!
ビジネス上の意思決定は、データ分析の洞察に依存しています。 同様に、入力データセットから得られる洞察は、ソース データの品質に依存します。 低品質、不正確、ガベージ、および一貫性のないデータ ソースは、データ サイエンスおよびデータ分析業界にとって困難な課題です。
したがって、専門家は回避策を考え出しました。 この回避策はデータクレンジングです。 ビジネスを改善するのではなく、ビジネスに害を及ぼすデータ駆動型の意思決定を行う必要がなくなります。
成功しているデータ サイエンティストやアナリストが使用している、最適なデータ クレンジング戦略を学びましょう。 また、インスタント データ サイエンス プロジェクトにクリーンなデータを提供できるツールを調べます。
データクレンジングとは?

データ品質には 5 つの次元があります。 データ品質ポリシーに従って入力データのエラーを特定して修正することは、データ クレンジングと呼ばれます。
この 5 次元標準の品質パラメーターは次のとおりです。
#1。 完全
この品質管理パラメーターにより、データ サイエンス プロジェクトに必要なすべてのパラメーター、ヘッダー、行、列、テーブルなどが入力データに含まれるようになります。
#2。 正確さ
データが入力データの真の値に近いことを示すデータ品質インジケーター。 調査やデータ収集のためのスクラップのすべての統計基準に従うと、データは真の価値を発揮します。
#3。 有効
このパラメータ データ サイエンスは、設定したビジネス ルールにデータが準拠していることを示します。
#4。 均一
均一性は、データに含まれる内容が均一であるかどうかを確認します。 たとえば、米国のエネルギー消費量調査データには、すべての単位が帝国単位の測定システムとして含まれている必要があります。 同じ調査で特定のコンテンツにメートル法を使用すると、データは均一になりません。
#5。 一貫性
一貫性は、データ値がテーブル、データ モデル、およびデータセット間で一貫していることを保証します。 また、システム間でデータを移動する場合は、このパラメーターを注意深く監視する必要があります。
簡単に言うと、上記の品質管理プロセスを生のデータセットに適用し、データをクレンジングしてからビジネス インテリジェンス ツールに送ります。
データクレンジングの重要性
そのように、貧弱なインターネット帯域幅プランでデジタル ビジネスを実行することはできません。 データ品質が許容できない場合、優れた決定を下すことはできません。 不要なデータや誤ったデータを使用してビジネス上の意思決定を行おうとすると、収益の損失や投資収益率 (ROI) の低下が見られます。
データ品質の低さとその結果に関する Gartner のレポートによると、同シンクタンクは、企業が直面する平均損失額が 1,290 万ドルであることを発見しました。 これは、誤った、改ざんされた、不要なデータに基づいて意思決定を行うためのものです。
同じレポートは、米国全体で不適切なデータを使用すると、国が年間 3 兆ドルという驚異的な損失を被ることを示唆しています。
BI システムにガベージ データをフィードすると、最終的な洞察は確実にガベージになります。
したがって、金銭的損失を回避し、データ分析プロジェクトから効果的なビジネス上の意思決定を行うために、生データをクレンジングする必要があります。
データクレンジングの利点
#1。 金銭的損失を避ける
入力データをクレンジングすることで、コンプライアンス違反や顧客の喪失に対するペナルティとして生じる可能性のある金銭的損失から会社を救うことができます。
#2。 偉大な決断を下す

高品質で実用的なデータは、優れた洞察をもたらします。 このような洞察は、製品のマーケティング、販売、在庫管理、価格設定などに関する優れたビジネス上の決定を下すのに役立ちます。
#3。 競合他社より優位に立つ
競合他社よりも早くデータクレンジングを選択すると、業界で急速に発展するメリットを享受できます。
#4。 プロジェクトを効率化する
合理化されたデータ クレンジング プロセスにより、チーム メンバーの信頼度が向上します。 彼らはデータが信頼できるものであることを知っているので、データ分析により集中できます。
#5。 リソースを保存
データのクレンジングとトリミングにより、データベース全体のサイズが縮小されます。 したがって、ガベージ データを削除することで、データベースのストレージ スペースを空にします。
データをクレンジングするための戦略
視覚データの標準化
データセットには、テキスト、数字、記号など、さまざまな種類の文字が含まれます。すべてのテキストに統一されたテキスト大文字化形式を適用する必要があります。 シンボルが Unicode、ASCII などの正しいエンコーディングであることを確認してください。
たとえば、大文字の Bill は人の名前を意味します。 逆に、請求書または請求書は、取引の受領を意味します。 したがって、適切な大文字の書式設定は非常に重要です。
レプリケートされたデータの削除
重複データは BI システムを混乱させます。 その結果、パターンが歪んでしまいます。 したがって、入力データベースから重複するエントリを除外する必要があります。
重複は通常、人間によるデータ入力プロセスから発生します。 生データの入力プロセスを自動化できれば、データの複製を根本から根絶することができます。
不要な外れ値を修正
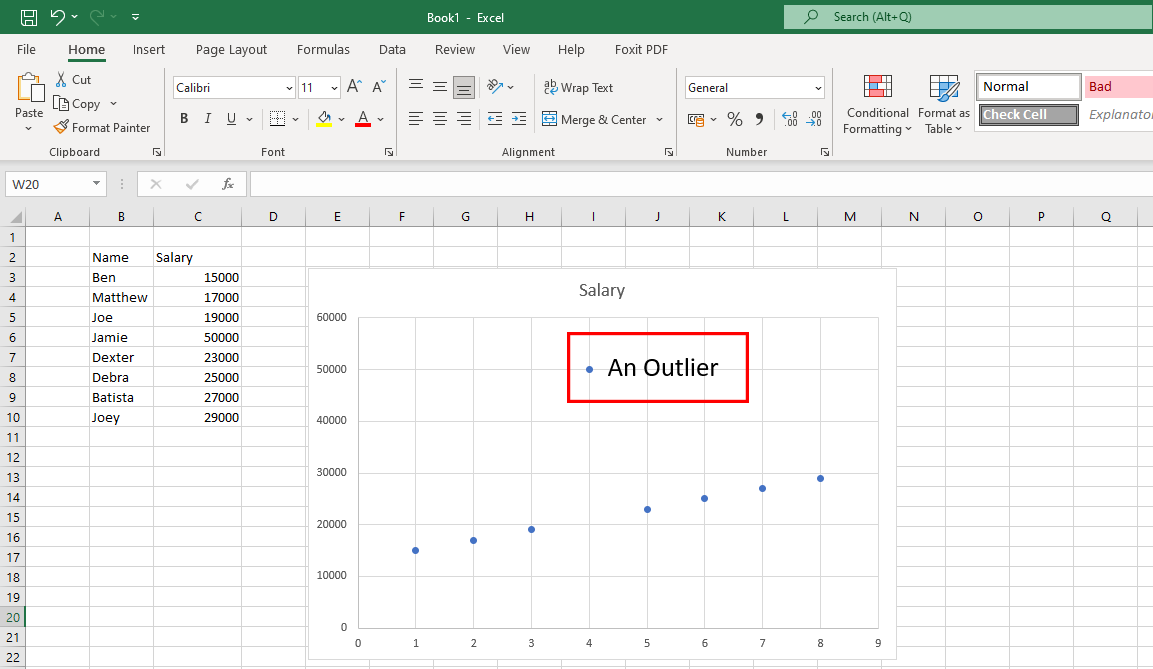
外れ値は、上のグラフに示されているように、データ パターン内に収まらない異常なデータ ポイントです。 データサイエンティストが調査の欠陥を発見するのに役立つため、本物の外れ値は問題ありません。 ただし、外れ値が人的エラーに起因する場合、それは問題です。
外れ値を探すには、データセットをチャートまたはグラフに配置する必要があります。 見つかった場合は、ソースを調査します。 ソースが人的エラーである場合は、外れ値データを削除します。
構造データに注目
主に、データセットのエラーを見つけて修正しています。
たとえば、データセットには USD の 1 つの列と他の通貨の多くの列が含まれています。 データが米国の視聴者向けである場合は、他の通貨を同等の USD に変換します。 次に、他のすべての通貨を USD に置き換えます。
データをスキャンする
データ ウェアハウスからダウンロードされた巨大なデータベースには、何千ものテーブルが含まれる場合があります。 データ サイエンス プロジェクトにすべてのテーブルが必要なわけではありません。
したがって、データベースを取得したら、必要なデータ テーブルを特定するスクリプトを作成する必要があります。 これがわかれば、無関係なテーブルを削除して、データセットのサイズを最小限に抑えることができます。
これにより、最終的にデータ パターンの検出が高速化されます。
クラウド上のデータをクレンジング
データベースでスキーマ オン ライト アプローチを使用している場合は、スキーマ オン リードに変換する必要があります。 これにより、クラウド ストレージで直接データ クレンジングを行い、フォーマット化され、整理され、すぐに分析できるデータを抽出できます。
外国語を翻訳する
世界中で調査を実施すると、生データに外国語が含まれることが予想されます。 外国語を含む行と列を英語またはその他の任意の言語に翻訳する必要があります。 この目的には、コンピューター支援翻訳 (CAT) ツールを使用できます。
ステップバイステップのデータクレンジング
#1。 重要なデータ フィールドの特定
データ ウェアハウスには、テラバイト単位のデータベースが含まれています。 各データベースには、数列から数千列のデータを含めることができます。 ここで、プロジェクトの目的を確認し、それに応じてそのようなデータベースからデータを抽出する必要があります。
プロジェクトで米国居住者の e コマース ショッピングの傾向を調査する場合、同じワークブックでオフラインの小売店のデータを収集しても何の役にも立ちません。
#2。 データの整理

データベースから重要なデータ フィールド、列ヘッダー、テーブルなどを見つけたら、それらを整理して照合します。

#3。 重複を一掃する
データ ウェアハウスから収集された生データには、常に重複するエントリが含まれます。 これらのレプリカを見つけて削除する必要があります。
#4。 空の値とスペースを削除する
一部の列ヘッダーとそれに対応するデータ フィールドには、値が含まれていない場合があります。 これらの列ヘッダー/フィールドを削除するか、空白の値を正しい英数字の値に置き換える必要があります。
#5。 ファインフォーマットを実行する
データセットには、不要なスペース、記号、文字などが含まれる場合があります。データセット全体のセル サイズとスパンが均一に見えるように、数式を使用してこれらをフォーマットする必要があります。
#6。 プロセスを標準化する
データ サイエンス チームのメンバーが従い、データ クレンジング プロセス中に職務を遂行できる SOP を作成する必要があります。 次のものが含まれている必要があります。
- 生データ収集の頻度
- 生データの保管と保守の監督者
- クレンジング頻度
- クリーンデータ保管および保守管理者
データクレンジングツール
データ サイエンス プロジェクトで役立つ一般的なデータ クレンジング ツールをいくつか紹介します。
ウィンピュア

データを正確かつ迅速にクリーニングおよびスクラブできるアプリケーションを探している場合、WinPure は信頼できるソリューションです。 この業界をリードするツールは、比類のない速度と精度を備えたエンタープライズ レベルのデータ クレンジング機能を提供します。
個人ユーザーや企業向けに設計されているため、どなたでも無理なくご利用いただけます。 このソフトウェアは、高度なデータ プロファイリング機能を使用して、データの種類、形式、整合性、および値を分析し、品質チェックを行います。 その強力でインテリジェントなデータ マッチング エンジンは、誤った一致を最小限に抑えて完全な一致を選択します。
上記の機能とは別に、WinPure は、すべてのデータ、グループ一致、および非一致の見事なビジュアルも提供します。
また、重複レコードを結合して、すべての現在の値を保持できるマスター レコードを生成するマージ ツールとしても機能します。 さらに、このツールを使用して、マスター レコードの選択ルールを定義し、すべてのレコードを即座に削除できます。
OpenRefine
OpenRefine は、乱雑なデータを Web サービスで使用できるクリーンな形式に変換するのに役立つ無料のオープンソース ツールです。 ファセットを使用して大規模なデータセットをクリーンアップし、フィルター処理されたデータセット ビューを操作します。
強力なヒューリスティックの助けを借りて、このツールは同様の値をマージしてすべての矛盾を取り除くことができます。 ユーザーがデータセットを外部データベースと照合できるように、調整サービスを提供します。 さらに、このツールを使用すると、必要に応じて古いデータセット バージョンに戻すことができます。
また、ユーザーは更新されたバージョンで操作履歴を再生できます。 データのセキュリティが心配な場合は、OpenRefine が最適です。 マシン上のデータをクリーンアップするため、この目的でクラウドにデータを移行する必要はありません。
Trifacta デザイナー クラウド

データのクレンジングは複雑になる可能性がありますが、Trifacta Designer Cloud を使用すると簡単になります。 組織がデータのスクラブから最大限の価値を引き出すことができるように、データのスクラビングに新しいデータ準備アプローチを使用します。
ユーザーフレンドリーなインターフェースにより、技術者ではないユーザーでも高度な分析のためにデータをクリーニングおよびスクラブできます。 現在、企業は、Trifacta Designer Cloud の ML を活用したインテリジェントな提案を活用して、データをさらに活用できます。
さらに、彼らはこのプロセスに費やす時間を減らし、対処しなければならないミスの数を減らす必要があります。 より多くの分析結果を得るには、削減されたリソースを使用する必要があります。
クラウディンゴ
収集されたデータの品質について心配している Salesforce ユーザーはいますか? Cloudingo を使用して顧客データをクリーンアップし、必要なデータのみを取得します。 このアプリケーションは、重複排除、インポート、移行などの機能により、顧客データの管理を容易にします。
ここでは、カスタマイズ可能なフィルターとルールを使用してレコードのマージを制御し、データを標準化できます。 役に立たない非アクティブなデータを削除し、欠落しているデータ ポイントを更新して、米国の郵送先住所の正確性を確保します。
また、企業は Cloudingo をスケジュールしてデータを自動的に重複排除できるため、常にクリーンなデータにアクセスできます。 データを Salesforce と同期し続けることは、このツールのもう 1 つの重要な機能です。 これにより、Salesforce データをスプレッドシートに保存された情報と比較することもできます。
ズーム情報

ZoomInfo は、チームの生産性と有効性に貢献するデータ クレンジング ソリューション プロバイダーです。 このソフトウェアは重複のないデータを企業の CRM および MAT に提供するため、企業はより多くの収益性を体験できます。
コストのかかる重複データをすべて削除することで、データ品質管理を簡素化します。 ユーザーは、ZoomInfo を使用して CRM と MAT の境界を保護することもできます。 自動化された重複排除、マッチング、および正規化により、数分以内にデータをクレンジングできます。
このアプリケーションのユーザーは、一致基準とマージ結果を柔軟に制御できます。 あらゆる種類のデータを標準化することで、費用対効果の高いデータ ストレージ システムを構築するのに役立ちます。
最後の言葉
データ サイエンス プロジェクトでは、入力データの品質に注意する必要があります。 これは、機械学習 (ML) や AI ベースの自動化のためのニューラル ネットワークなど、大きなプロジェクトの基本的なフィードです。フィードに問題がある場合は、そのようなプロジェクトの結果がどうなるかを考えてください。
したがって、組織は実績のあるデータ クレンジング戦略を採用し、それを標準操作手順 (SOP) として実装する必要があります。 その結果、入力データの品質も向上します。
プロジェクト、マーケティング、販売で十分に忙しい場合は、データクレンジングの部分を専門家に任せたほうがよいでしょう。 エキスパートは、上記のデータ クレンジング ツールのいずれかです。
また、データ クレンジング戦略を簡単に実装するためのサービス ブループリント ダイアグラムにも関心があるかもしれません。