豊富な結果を選択して作成する方法(付与)
公開: 2018-09-252019年12月17日追加この投稿に関する特許は本日付与され、ユーザーの検索クエリに関連するリッチな結果で見つけることができます
Googleによる書籍の索引付けの歴史
1999年に特許を取得したGoogleの最初のセマンティック検索の発明で、私はGoogleの創設者であるSergey Brinによる発明について、DIPRE(Dual Iterative Pattern Relation Expansion)として知られるアルゴリズムについて書きました。 それは5冊の本のリストとそれらの本に関する情報から始まりました。
- 出版社
- 出版物データ
- 長さ
- 著者
クローラーを使用して、これらの本をリストしているサイトをWebで検索し、それらを見つけて関連情報をインデックスに登録した後、同じサイトにリストされている可能性のある他の本に関する事実を収集しました。
したがって、Googleが本に関する同様の情報を収集し、その情報を豊富な結果で表示することについて別の特許を取得した場合、それは驚くことではありません。
10個の青いリンクを超えて; グーグルは豊富な結果を示しています
その新しい特許はまだ付与されていませんが、以前の出願は2015年、2013年、2010年に提出されていました。この特許は、GoogleがSERPSで情報豊富な結果を表示する方法に関するものであり、Googleブログを思い出させました。あなたが以前に見たかもしれない2009年に出た投稿:
豊富な結果のご紹介
リッチな結果について私が見た中で最も近い特許は、Googleがリッチな結果について発表した特許であり、人目を引く検索結果が得られましたが、リッチなスニペットがどのように出てきたかはまったくわかりませんでした。
リッチリザルトにはGoogleカスタム検索のヘルプページがあり、サイトのクロール、「レビュー、ユーザープロファイル、製品、レシピ、音楽、イベント」などのリッチスニペットを実現する方法について詳しく説明しています。
しかし、これは私がグーグルからの豊富な結果について見た中で最も早いものの1つであるように思われます、そしてそれは本についての追加情報を披露することについてです。 この特許は、このような結果の動機を次のように示しています。
検索エンジンのユーザーは、個々のリソースのリストではなく、本などの特定のエンティティに関する情報を探していることがよくあります。
豊富な結果は、情報ニーズを満たすことに焦点を当てています
この特許は、次のように、このような情報のニーズをどのように満たすかを説明しています。
この仕様は、検索クエリが特定の本または他の出版物に関連していると判断された場合に、検索クエリに応答して豊富な結果を提示することに関連する技術について説明しています。 豊富な結果は、クエリに関連し、複数の情報コレクションからの情報を含む、フォーマットされたコンテンツのプレゼンテーションです。 たとえば、リッチな結果には、発行者のWebサイト、販売者のWebサイト、または情報Webサイトへのリンクが含まれる場合があります。 豊富な結果には、出版社、発行年、本のページ、および本の抜粋または概要に関する情報が追加で含まれる場合があります。
これは、特定の本に関する詳細情報の要求に対して豊富な結果を示す可能性のあるクエリへの応答として表示されるように、リソースがどのようにスコアリングされるかを詳細に説明する情報源でもあります。
- 書籍リソースからのクエリに応答する検索結果の取得
- 他の出版物の結果のそれぞれのスコアと比較してしきい値を満たす、最初にランク付けされた最初の結果のスコアを決定する
- 最初のパブリケーション結果と1つ以上のWebリソースからのデータで構成される、最初のパブリケーション結果のリッチ結果を生成し、パブリケーション検索結果とともにリッチ結果を提供します。
豊富な結果がどこから来るのか
この特許には、リッチスニペットのソースであるサイトに対するいくつかの要件があり、次のようにそれらをレイアウトします。
- 最初の出版物のスコアは、出版物の検索結果のランク付けされた順序で2番目にランク付けされた本の検索結果のスコアの少なくともしきい値の倍数である場合にしきい値を満たします。 最初の出版物のスコアは、本の検索結果のランク付けされた順序で3番目または4番目にランク付けされた出版物の検索結果のスコアの少なくともしきい値の倍数である場合にしきい値を満たします。
- 豊富な結果を生成することには、出版物の価格情報を取得すること、および豊富な結果に価格情報を含めることも含まれます。 価格情報は、ISBNを使用して製品コーパスから取得され、ISBNに対応する書籍の価格を受け取ります。
- 製品コーパスにISBNを提供することは、最初の発行結果に関連付けられたデータからISBNを取得することを含みます。
- 豊富な結果を生成するには、Webリソースのデータを使用して、書籍リソースのコーパスからデータを修正する必要があります。 書籍リソースのコーパスからのデータを修正することは、書籍リソースのコーパスからのデータをWebリソースからのデータの1つ以上のバリアントと比較し、豊富な結果を得るために最も人気のあるバリアントを選択することを含みます。
- パブリケーションスニペット。 スニペットは、パブリケーションの抜粋またはパブリケーションの要約です。
- 出版物の1人以上の著者。 書籍リソースのコーパスからのデータを修正することは、ウェブリソースからのデータを使用して出版物の1人または複数の著者を修正することをさらに含む。
- 出版物のプレビューへのリンク。
- 関連するウェブサイトへのリンク。
- 書店のウェブサイトへのリンク。
- 出版物の出版社情報。 出版社の情報は、出版社の出版社のWebサイトへのリンクで構成されています。 この方法は、ウェブリソースからのデータを使用して発行者情報を修正することをさらに含む。
- ユーザーは、クエリに応じて出版物に関する関連情報を提示できます。
- ユーザーは、検索クエリで参照されている出版物に関連する情報に簡単にアクセスできるインターフェイスを通じて、より豊富な検索エクスペリエンスを提供できます。
- ユーザーは、検索クエリに関連する出版物情報やWebサイトを簡単に見つけることができます。
- ユーザーは、検索した出版物を購入するための便利な方法を提供できます。
- 書評のウェブサイト
- 本の売り手のウェブサイト
- あらすじのウェブサイトを予約する
したがって、Book Rich Resultsの背後にある目的の1つは、検索した本の購入に興味があるかもしれない人に役立つ情報を提供することであるように見えます。 その最後の部分では、Web全体のソースからの事実情報を使用して、入手可能な最も人気のある情報を使用して、本に関するデータを修正します。
豊富な結果に表示される情報
書籍のリッチリザルトには、次のような特定の情報が含まれている場合があります。
ブックリッチな結果の利点
多くの特許は、彼らが解決しようとしている問題と、それを行うために使用する可能性のあるプロセスについて教えてくれます。 特許の説明の部分で、彼らは保護するために働く特許のプロセスに従うことが含むかもしれない利点のリストを提供することがあります、そしてこの豊富な結果の特許はそれが提供する利点について私たちに教えてくれます:

この特許の更新版はここにあります:
ユーザー検索クエリに関連する豊富な結果
米国特許出願:20180253498
応募日:2018年8月5日
発行日:2018年6月9日
応募者:GOOGLE LLC
発明者:Matthew K. Gray、Gregory H. Plesur、およびGarrett H. Rooney
概要:
クエリに応答して豊富な結果をトリガーするための、コンピュータストレージメディアにエンコードされたコンピュータプログラムを含む方法、システム、および装置。 一態様では、方法は、クエリを受信することを含む。 1つ以上の検索結果が最初のコーパスから取得されます。 リッチな結果は、他の検索結果と比較してしきい値を満たしている場合、最初にランク付けされた検索結果のスコアに基づいてトリガーされます。 豊富な結果には、2番目のコーパスから取得された最初にランク付けされた検索結果に関する追加のメタデータが入力されます。 クエリに応答して、豊富な結果が提供されます。
リッチリザルト特許からの追加のポイント
あなたがそれらを見たいのであれば、特許の説明はより詳細になります。 たとえば、Webで見つかる可能性のある本に関するリソースには、次のものが含まれる可能性があることがわかります。
- 出版社のウェブサイト
また、出版物に関する情報がこれらのリソースの複数から取得される可能性があり、豊富な結果がその情報を組み合わせて出版物の豊富な結果になる可能性があることも示しています。
この特許は、「最後の中国人シェフ」というクエリの豊富な結果の例を示しています。
出版物自体に関する情報に加えて、本を提供する可能性のある書店や出版社のサイトなどの他の書店へのリンクがあることに注意してください。

この特許は、検索結果とパブリケーションインデックスのインデックス作成とクラスタリングについて説明しています。リッチ結果エンジンに関するこのセクションでは、特定のクエリに応答して特定のリッチ結果がトリガーされるタイミングについて説明しているため、共有する価値があると思いました。
リッチリザルトエンジンは、複数のコーパスの情報を比較して、リッチリザルトで提供される情報のデータ品質を向上させることができます。 たとえば、リッチリザルトエンジンは、複数のコーパスでの本のタイトルの異形の大文字と小文字を比較し、最も人気のある異形を選択することで、本のタイトルの正しい大文字と小文字を判別できます。 リッチ結果エンジンは、パブリケーションクエリへの応答の一部としてリッチ結果をトリガーする必要があるかどうかも決定します。 たとえば、リッチリザルトエンジンは、特定の人気のしきい値を満たすパブリケーションに対してのみリッチリザルトをトリガーする場合があります。
豊富な結果をトリガーするための人気のしきい値について詳しくは、こちらをご覧ください。
検索システムは、豊富な結果をトリガーして検索結果とともに表示するかどうかを決定します(320)。 一部の実装では、本の結果で最初にランク付けされた結果のスコアが他のどの本の結果よりも大幅に高い場合に、検索システムが豊富な結果をトリガーします。
豊富な結果をトリガーする特定のクエリ用語に加えて、書籍の結果で最初にランク付けされた結果に関連付けられている可能性のある書籍リソースのメタデータレコードからの情報により、クエリに応答して豊富な結果が表示されることがわかります。
一部のクエリに対してのみリッチ結果がトリガーされる方法(しきい値を使用)や、特定の書籍に関する情報がどのようにクラスター化されるかなど、クエリに応答して表示されるリッチ結果の背後にあるすべての側面に関心がある場合は、以下をお読みください。特許全体が推奨されます。
Googleがほとんどの本で豊富な結果を表示するかどうかはわかりません。 彼らは今やっていることの検索で彼らのための知識パネルを示しています。 しかし、この特許の背後にあるアイデアのいくつかは、Googleがリソースのコーパスを調べて、豊富な結果の事実を修正する方法など、他の豊富な結果に使用される可能性があると思います。
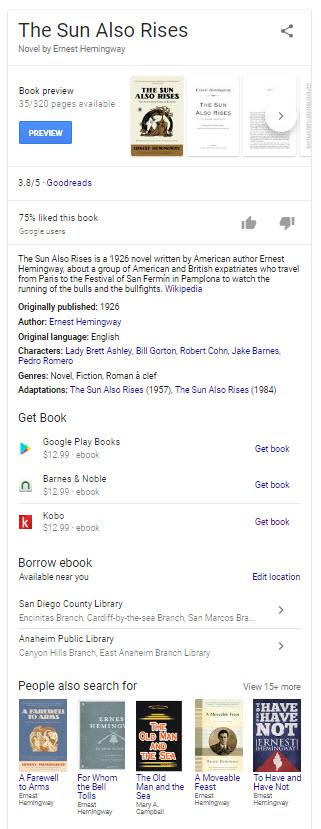
豊富な結果の代替としてのナレッジパネル
豊富な結果の代わりに、Googleは本の知識パネルを表示することを決定した可能性があります。これは、回答を表示する可能性のある他のタイプのエンティティに関して直面する可能性のあるビジネスプロセスの決定です。 これは、この特許が豊富な結果に含まれると私たちに告げている多くのことを含む本、The Sun AlsoRisesのナレッジパネルです。