如何选择和创建丰富的结果(授予)
已发表: 2018-09-25于 2019 年 12 月 17 日添加此帖子所涉及的专利已于今天获得授权,可在与用户搜索查询相关的丰富结果中找到
Google 图书索引的历史
在 1999 年 Google 的第一个语义搜索发明获得专利中,我写了关于 Google 创始人 Sergey Brin 的一项发明,关于一种称为 DIPRE(双迭代模式关系扩展)的算法。 它首先列出了五本书,以及有关这些书的信息,例如:
- 出版商
- 出版资料
- 长度
- 作者
它使用爬虫在网络上搜索列出这些书籍的站点,在找到它们并为它们索引相关信息后,它会收集可能在同一站点上列出的其他书籍的事实。
因此,当 Google 推出另一项关于收集有关书籍的类似信息并在富媒体搜索结果中显示该信息的专利时,这并不令人意外。
超过 10 个蓝色链接; 谷歌显示丰富的结果
那个新专利还没有被授予,但之前的申请已经在 2015、2013 和 2010 年提交过。该专利是关于谷歌如何在 SERPS 中显示信息丰富的结果,它让我想起了谷歌博客2009 年发布的您可能以前看过的帖子:
介绍富媒体搜索结果
我见过的最接近丰富结果的专利是 Google 提出的关于丰富结果的专利,它为我们提供了引人注目的搜索结果,但并不是丰富的摘要。
Rich Results 上有一个 Google 自定义搜索帮助页面,它告诉我们更多有关如何为诸如抓取您的网站、“评论、人员资料、产品、食谱、音乐和事件”等内容获取丰富网页摘要的信息。
但这似乎是我最早看到的有关 Google 富搜索结果的内容之一,它是关于炫耀有关书籍的其他信息。 该专利以这种方式告诉我们产生这种结果的动机:
搜索引擎的用户经常寻找关于特定实体的信息,例如一本书,而不是单个资源的列表。
丰富的结果专注于满足信息需求
该专利描述了它如何满足这种信息需求,如下所示:
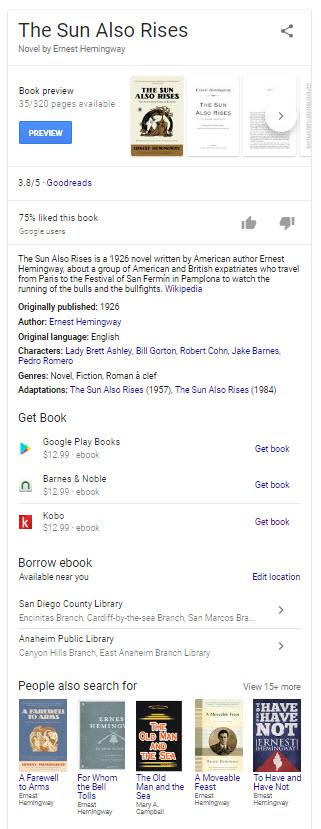
本规范描述了与响应于搜索查询呈现丰富结果相关的技术,其中确定查询与特定书籍或其他出版物有关。 丰富的结果是与查询相关的内容的格式化呈现,其中包含来自多个信息集合的信息片段。 例如,富媒体搜索结果可能包含指向发布者网站、卖家网站或信息网站的链接。 富媒体搜索结果还可以包括关于出版商、出版年份、书中页数以及书中的摘录或概要的信息。
这也是详细描述资源如何评分的信息来源,以便它显示为对查询的响应,该查询可能会在请求有关特定书籍的更多信息时显示丰富的结果。
- 从图书资源中获取响应查询的搜索结果
- 确定排名第一的第一个结果的分数,该分数满足相对于其他发表结果的相应分数的阈值
- 为第一发布结果生成富媒体搜索结果,包括第一发布结果和一个或多个网络资源的数据,并将富媒体搜索结果与发布搜索结果一起提供
丰富的结果来自哪里
该专利对作为丰富片段来源的网站有一些要求,它为我们列出了这些要求,如下所示:
- 如果第一出版结果的分数至少是出版物搜索结果排序中排名第二的图书搜索结果的分数的阈值倍数,则该分数满足阈值。 如果第一出版结果的分数至少是图书搜索结果排序中排名第三或第四的出版物搜索结果的分数的阈值倍数,则该分数满足阈值。
- 生成富媒体结果还包括获取出版物的价格信息以及将价格信息包括在富媒体结果中。 价格信息将从具有 ISBN 的产品语料库中获得,并接收对应于 ISBN 的书籍的价格。
- 为产品语料库提供 ISBN 包括从与第一次发布结果相关联的数据中获取 ISBN。
- 生成丰富的结果包括使用来自网络资源的数据更正来自书籍资源语料库的数据。 校正来自书籍资源语料库的数据包括将来自书籍资源语料库的数据与来自网络资源的数据的一个或多个变体进行比较,并为丰富的结果选择最流行的变体。
- 一个发布片段。 摘要是出版物摘录或出版物摘要。
- 该出版物的一名或多名作者。 更正来自书籍资源的语料库的数据还包括使用来自网络资源的数据更正出版物的一个或多个作者。
- 指向出版物预览的链接。
- 相关网站的链接。
- 链接到书商网站。
- 出版物的出版商信息。 出版商的信息包括到出版物出版商网站的链接。 该方法还包括使用来自网络资源的数据来校正发布者信息。
- 可以向用户提供有关出版物的相关信息,以响应他们的查询。
- 通过提供对与搜索查询中引用的出版物相关的信息的轻松访问的界面,可以为用户提供更丰富的搜索体验。
- 用户可以轻松找到与其搜索查询相关的出版物信息和网站。
- 可以为用户提供方便的方式来购买他们搜索过的出版物。
- 书评网站
- 图书销售网站
- 书籍概要网站
因此,看起来 Book Rich Results 背后的目的之一是提供对可能有兴趣购买搜索书籍的人有用的信息。 最后一部分涉及使用来自网络上的来源的事实信息,使用最流行的可用信息来更正有关这本书的数据。
显示在富媒体搜索结果中的信息
一本书的 Rich Results 可能包含一些特定信息,例如:
图书丰富结果的优势
许多专利告诉我们他们打算解决的问题,以及他们可能使用的流程。 在专利的描述部分,他们有时会列出遵循他们努力保护的专利过程可能涉及的优势,这个丰富的结果专利也告诉我们它提供的优势:

该专利的更新版本可以在这里找到:
与用户搜索查询相关的丰富结果
美国专利申请:20180253498
申请日期:2018年8月5日
出版日期:2018 年 6 月 9 日
申请人:GOOGLE LLC
发明人:Matthew K. Gray、Gregory H. Plesur 和 Garrett H. Rooney
抽象的:
用于响应查询触发丰富结果的方法、系统和装置,包括编码在计算机存储介质上的计算机程序。 在一个方面,一种方法包括接收查询。 从第一语料库获得一个或多个搜索结果。 如果相对于其他搜索结果满足阈值,则基于排名第一的搜索结果的分数触发富搜索结果。 富搜索结果填充有关于从第二个语料库获得的排名第一的搜索结果的附加元数据。 为响应查询而提供丰富的结果。
Rich Results 专利的额外收获
如果您想查看专利的描述,则会有更详细的说明。 例如,它告诉我们可能在 Web 上找到的有关书籍的资源可能包括:
- 出版商的网站
它还告诉我们,关于出版物的信息可能取自多个这些资源,而富媒体搜索结果可能会将这些信息合并为出版物的富媒体搜索结果。
该专利提供了查询“最后一位中国厨师”的丰富结果示例。
请注意,除了有关出版物本身的信息外,还有指向可能提供该书的书商和其他网站(例如出版商的网站)的链接。

该专利告诉我们搜索结果的索引和聚类以及发布索引,我认为关于富搜索引擎的这一部分值得分享,因为它告诉我们何时可能触发某些富搜索结果以响应某些查询:
富结果引擎可以比较多个语料库中的信息,以提高富结果中提供的信息的数据质量。 例如,富搜索引擎可以通过比较多个语料库中书名的变体大小写并选择最流行的变体来确定书名的正确大小写。 富结果引擎还确定是否应触发富结果作为对发布查询的响应的一部分。 例如,富媒体搜索引擎可能仅针对满足特定流行度阈值的出版物触发富媒体搜索结果。
有关触发富媒体搜索结果的受欢迎程度阈值的更多信息:
搜索系统确定富搜索结果是否应该被触发并与搜索结果一起呈现(320)。 在一些实施方式中,当书籍结果中排名第一的结果的得分显着高于任何其他书籍结果时,搜索系统触发丰富结果。
除了触发富媒体结果的特定查询词之外,来自可能与图书结果中排名第一的结果相关联的图书资源的元数据记录的信息可以确定富媒体结果是响应查询而出现的。
如果您对响应查询而出现的富搜索结果背后的所有方面感兴趣,包括如何仅针对某些查询触发富搜索结果(使用阈值),以及有关特定书籍的信息可能如何聚类,请通读推荐整个专利。
我不确定 Google 是否会为大多数图书显示富媒体搜索结果。 他们正在为他们显示有关搜索的知识面板。 但我认为,这项专利背后的一些想法,比如谷歌如何查看资源库以纠正富媒体搜索结果的事实,可能会被用于其他富媒体搜索结果。
知识面板作为丰富结果的替代方案
谷歌可能决定为书籍显示知识面板,而不是丰富的结果,这将是一个业务流程决策,当涉及到它可能会显示答案的其他类型的实体时,它可能会面临这一业务流程决策。 这是《太阳照常升起》这本书的知识面板,其中包含该专利告诉我们丰富的结果将包含的许多内容: