
Googleはスキーマを使用して注目のスニペットの回答パッセージを記述していますか?
公開: 2019-01-25パッセージと注目のスニペットに答える
構造化データ(スキーマなど)と非構造化データがあることを示すスコアに基づいて回答パッセージが選択される可能性があるという特許が付与されたことで、これまで注目スニペットに関するこの質問に対する回答はありませんでした。 (散文のパッセージなど)答えを提供します。
グーグルは先週、質問応答に関して検索エンジンのクエリ処理について説明する特許を取得した。
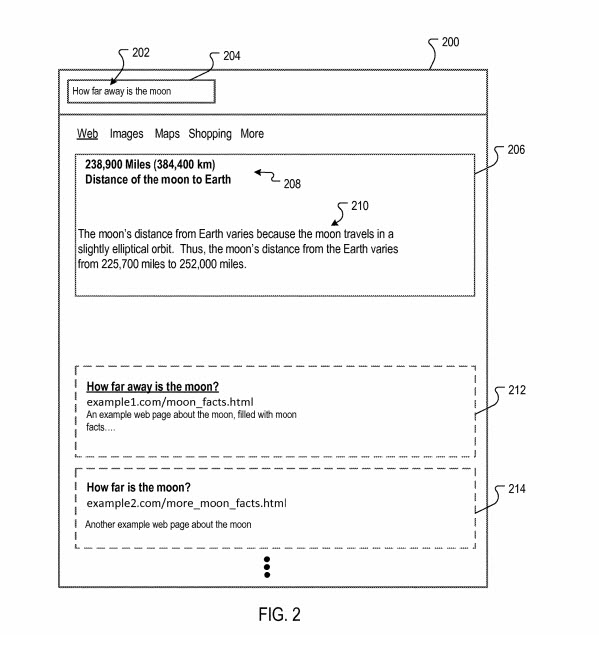
この特許は、質問応答の注目スニペットの結果が異なり、ユニークである理由について説明しています。
検索システムのユーザーは、リソースのリストではなく、特定の質問に対する回答を検索することがよくあります。 たとえば、ユーザーは特定の場所の天気、株式の現在の見積もり、州の首都などを知りたい場合があります。質問の形式のクエリを受信すると、一部の検索エンジンが実行する場合があります。クエリの質問形式に応じた特殊な検索操作。 たとえば、一部の検索エンジンは、質問に対する「ワンボックス」の形式で提供される情報など、「回答」の形式でそのようなクエリに応答する情報を提供する場合があります。
2006年に「Googleの定義を見る」の投稿で書いたGoogle辞書の結果を思い出しました。 ワンボックスタイプの回答への言及は、グーグルのワンボックス特許を思い出させます。これは、グーグルがワンボックスの結果を返すことを決定したときに見る可能性のある大量のデータについて教えてくれます。 2017年のワンボックス特許の更新については、Google Updates their One BoxPatentの投稿に書いています。
候補者回答パッセージとは何ですか?
Googleでの質問応答に関するこの新しい特許は、候補応答パッセージの概念を導入しています。これは、この候補回答パッセージ特許の開始時に定義されています。
一部の質問クエリは、「長い回答」または「回答のパッセージ」とも呼ばれる説明的な回答によってより適切に処理されます。 たとえば、質問クエリ[なぜスカイブルーなのか]の場合、レイリー散乱を説明する回答が役立ちます。 このような回答のパッセージは、質問と回答に関連する段落などのテキストを含むリソースから選択できます。 テキストのセクションにスコアが付けられ、スコアが最も高いセクションが回答として選択されます。
グーグルが回答パッセージをどのように採点するかについて何かを知っていると、グーグルが[なぜ空色なのか]などの回答に使用する可能性のある回答パッセージをページ上に作成する可能性が高くなります。
Googleは回答のパッセージをどのように採点しますか?
まず、Googleは受信したクエリを調べて、探していると思われる応答の種類を確認します。 注目のスニペットと「クエリに応答すると判断されたリソースを識別するデータ」を探しているのは質問クエリですか?

回答の元となるデータリソースは、次の要因に基づいてスコアリングされる場合があります。
リソースにはいくつかのパッセージが含まれており、それぞれが回答として含まれる資格のあるコンテンツです。
パッセージは、以下を検討できる「選択基準」に基づいて判断することができます。
- クエリに応答する構造化データ(スキーマなど)と非構造化コンテンツ(Webページ上のテキストなど)があるかどうか。 答えとして。
- リソースは、回答のパッセージに加えて含まれる可能性のある検索結果とは別のものですか?
Googleが回答パッセージに構造化コンテンツと非構造化コンテンツを必要とするのはなぜですか?
特許は、この要件を特許の背後にあるプロセスの利点と呼んでいます。
両方を要求することで、Googleは、非構造化コンテンツによって検索者が「proseタイプの説明」を受け取ることができ、構造化コンテンツによって事実情報を返すことができると言います。つまり、回答は散文と事実の組み合わせである可能性があります。検索者が見つけようとしていたものに非常に関連している。

回答パッセージを使用して検索者の情報ニーズに対応
この特許は、候補者の回答のパッセージをスコアリングするときに、クエリに依存するシグナルとクエリに依存しないシグナルを調べることを示しています。
クエリ依存シグナルは、パッセージを見つけるためにクエリで使用される用語にパッセージがどの程度関連しているかに基づくシグナルです。 したがって、映画「ボヘミアン・ラプソディ」でラミ・マレックが歌ったかどうかを尋ねる質問は、俳優、映画について言及し、彼が歌っている場合、クエリに依存する信号に基づいてスコアが高くなります。
クエリに依存しないシグナルとは、パッセージが表示されているページを指すリンクの数や、質問が非常にタイムリーなニュースを含む場合、そのページがどれほど新鮮でタイムリーであるかなど、クエリ用語との関連性以外のものを調べるシグナルです(ボヘミアン・ラプソディのゴールデングローブ賞で最高のドラマ映画を受賞したなど。)
この特許は、クエリ依存信号とクエリ非依存信号の両方に基づくこのスコアリングは、次のことを示していると述べています。
クエリに依存する信号は、最も関連性の高いリソースのセットに基づいて重み付けされる場合があります。これは、リソースのより大きなコーパスでスコアリングされたパッセージよりも関連性の高い回答パッセージを表示する傾向があります。 これにより、処理要件が軽減され、クエリ時のスコア分析が容易になります。
質問を含むクエリへの回答の提供について話していた以前の特許は、権威の高いサイトからの回答を探していると述べていましたが、詳細はあまり提供されていませんでした。 投稿の1つであるDirectAnswers – IntentQueriesの自然言語検索結果について書きました。 私が5年前にそれを書いたとは信じがたいです。 グーグルがそれらの質問への答えのために構造化データを見ているかもしれないと言って以来、私は何かを待っていました。
この新しく付与された特許は、もともと2015年に出願されました。ページに構造化データがあると、注目のスニペットが表示される可能性が高くなるため、サイトに構造化データを含めるもう1つの理由があります。
特許は次のとおりです。
候補者の回答文
発明者:Steven D. Baker、Srinivasan Venkatachary、Robert Andrew Brennan、Per Bjornsson、Yi Liu、Nitin Gupta、Diego Federici、Lingkun Chu
譲受人:Google LLC
米国特許:10,180,964
付与:2019年1月15日
提出日:2015年8月12日
概要
候補回答パッセージを生成するための、コンピュータ記憶媒体上に符号化されたコンピュータプログラムを含む方法、システム、および装置。 一態様では、方法は、クエリに応答すると決定されたリソースを識別する質問クエリデータであると決定されたクエリを受信することを含む。 リソースのトップランクのサブセット内の各リソースに対して:リソース内の複数の通過ユニットを識別します。 パッセージユニット選択基準のセットをパッセージユニットに適用し、各パッセージユニット選択基準は、候補回答パッセージにパッセージユニットを含めるための条件を指定し、パッセージユニット選択基準の第1のサブセットは構造化コンテンツに適用され、第2のサブセットはパッセージユニットの選択基準は、構造化されていないコンテンツに適用されます。 そして、パッセージユニット選択基準のセットを満たすパッセージユニットから、候補回答パッセージのセットを生成する。
2020年10月15日追加– Googleがページ上の質問を見つけてそれらに回答する方法に興味がある場合は、回答のパッセージについて他のいくつかの投稿を書きました。回答のパッセージをスコアリングして、注目のスニペットとして表示するものを決定します。 これらの投稿は次のとおりです。
- 2020年9月23日–注目のスニペット回答スコアランキングシグナル
- 2020年10月9日–コンテキストによる注目のスニペット回答の調整
- 2020年10月14日–回答パッセージをスコアリングするための加重回答条件