
9個人用およびビジネス用の音声認識ソリューション
公開: 2021-05-04特にAlexaのような音声検索サービスの出現後、Speech-to-Textソリューションが普及しつつあります。
これらのソリューションは、個人と企業の両方にとって、より効率的なものになります。
実際、書くことは、プレゼンテーションの準備、アイデアの文書化、メモの作成など、プロとしてのキャリアにおいて誰もが行う必要のある重要なタスクです。メール、ブログ投稿、ニュースレター、小説を書くことです。
速く入力しても、この速度は話しているときの速度よりも遅くなります。 問題は、物理的に書くことはあなたの脳の実際の処理速度よりもはるかに遅いということです。 これは、入力に費やす時間を節約できる十分な範囲があることを意味します。
自動化のこの時代では、手を使わずに声で入力することが可能です。
はい、それは本当です、そしてこの技術はスピーチからテキストへのソフトウェアです。
それはあなたがあなたの声を使ってより速くタイプするのを助け、あなたのワークフローを加速し、あなたの効率を高め、そしてあなたの手に休息を提供します。
この記事では、Speech toTextソフトウェアとそれがどのように役立つかについていくつか説明します。
音声認識ソフトウェアとは何ですか?

Speech to Textソフトウェアは、音声認識のテクノロジーを活用して、話した単語をテキストに変換するツールです。
これらのソリューションは、機械学習や人工知能などの最新テクノロジーで強化されており、人間の音声を識別して理解し、正確な単語に処理します。
多くの音声テキストソリューションは、グローバルに話される複数の言語もサポートしており、英語だけに限定されていません。 また、マイクやコンピューターやクラウドに保存されているファイルなど、さまざまなオーディオ入力もサポートしています。
なぜ音声認識ソリューションが必要なのですか?
音声認識ソフトウェアは、あなたが作家、ソロプレナー、またはビジネスオーナーであるかどうかにかかわらず、あなたの生活を楽にすることを目的としています。
一人で事業を営んでいると、アイデアを書く時間がほとんどないかもしれません。 現時点では、このソフトウェアはあなたを大いに助けます。 または、ビジネスを運営していて、組織の効率を高めたい場合は、このソフトウェアを使用できます。
それは誰にとっても機能し、マルチタスクを可能にします。 もう怒りでキーボードに指をぶつける必要はありません。 必要なのはあなたの声だけです。
音声認識ソフトウェアを使用することには、次のような多くの利点があります。
時間を節約する
お皿にたくさんのものがあり、すべてを書く時間がほとんどない場合、そのときにドアをノックする面白いアイデアを失う可能性があります。
このシナリオでは、音声認識ソフトウェアを使用して、音声をキャプチャすることで素晴らしいアイデアを入力できます。 タイピング速度がそれほど速くなく、早くても大きなドキュメントを完成させる必要がある場合にも、時間を節約できます。
効率を向上させます
音声認識ソフトウェアを使用すると、ワークフローを迅速化することで組織の効率を高めることができます。 手で入力するときに時間がかかるプレゼンテーションやドキュメントなどに使用できます。
特定の障害を持つ人々への祝福
チーム内の誰かが特定の身体障害またはアクセシビリティの問題を抱えている場合、音声テキスト変換ソフトウェアは彼らにとって非常に役立ちます。 これは、外傷、失読症、または従来の入力デバイスの使用を制限するその他の障害のために、人々が手を使用するのが困難になるのを助けることができます。
キーボードを使わなくても、自分の声で好きなようにドラフトできます。 さらに、特に一日中書くことにうんざりしている人には、誰でもそれを利用して手を休めることができます。
それでは、これらすべての利点を活用するのに役立つ、市場で最高の音声テキスト変換ソフトウェアのいくつかについて説明しましょう。
まず、個人的な使用のために探検しましょう。
ニュアンスドラゴン
AIを活用したDargon音声認識ソリューションを活用して言葉を活用し、従業員が高品質のドキュメントを作成できるようにします。
Dragon ProfessionalIndividualを使用して、音声でメール、フォーム、レポートなどを作成できます。 最新世代の音声エンジンを備えており、正確にすばやく書き起こし、口述することができるため、文書化にかかる時間を節約し、他の重要な活動に専念させることができます。 また、より重要な利益を得るために作業方法を調整するのにも役立ちます。
スマートフォーマットルールは、略語、電話番号、日付などを書き込むときに自動的に適応します。 音声で下線または太字を適用することもできます。 さらに、頭字語やその他の用語のカスタムリストをインポート/エクスポートしたり、カスタム音声コマンドや時間節約マクロを作成したりできます。 このツールを使用すると、.wav、.wma、.dss、.ds2、.mp3、および.m4aから転記することもできます。

Dragon音声認識を使用するには、少なくとも4 GBのRAM、IntelまたはAMD CPU、8 GBのハードディスク空き容量、およびWindows7以降のオペレーティングシステムが必要です。 モバイル版を入手して、モバイルデバイスからドキュメントを作成、編集、共有、およびフォーマットします。
地元のコーヒーショップや求人サイトのクライアントを訪問している場合でも、モバイル版はどこにでも持ち運びできます。 このようにして、99%の精度で、単語の制限なしに、モバイルデバイスで同じソリューションを取得できます。 データセキュリティに関して、Dragon Anywhere Mobileのクラウドソリューションは99.5%の稼働時間を維持し、HITRUSTCSF認定のホスティングインフラストラクチャであるMSAzureでホストされる地理的に分散したデータセンターで実行されます。
すべてのデータは256ビット暗号化で暗号化されており、比類のない柔軟性、精度、速度が得られます。 500ドルの最小サブスクリプションプランでビジネスの生産性を高め、30日間の返金保証を取得します。 モバイル版を選択した場合は、1週間の無料トライアルを利用して、月額$ 15でサブスクリプションを継続できます。
ディクテーション
Dictationを使用して、電子メールやその他のドキュメントを作成しながら、速度認識の魔法の世界を探索してください。 音声をリアルタイムで正確にテキストに変換し、GoogleChromeで直接機能します。
音声コマンドを使用して、段落、スマイリー、句読点、特殊文字を簡単に追加できます。 また、特定の便利なコマンドを実行するのに役立つ多くのフレーズが含まれています。 このオンラインアプリケーションは、ブラウザにテキストを保存します。 したがって、どのサイトにも何もアップロードされません。
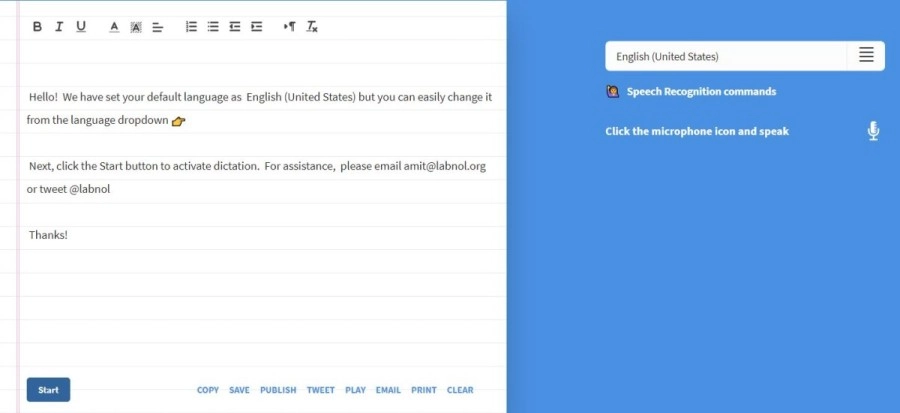
たとえば、スマイリーを挿入したい場合は、これらの単語を簡単な英語の「SmilingFace」で言うことができます。 ディクテーションは、何百もの言語や方言も認識し、それらを簡単に書き写すことができます。 英語の他に、スペイン語、フランス語、ポルトガル語、イタリア語、ヒンディー語などの人気のある言語を含む言語をサポートしています。
それに加えて、DictationはGoogle音声認識を利用して、話し言葉を書き言葉に書き写します。 実際、豊富なフォーマットオプションを備えたテキストエディタの下にテキストを保存します。 簡単にコピー、ツイート、公開、テキストをプレーンテキストとして保存、スピーチとして再生、テキストの印刷、または電子メールで送信できます。
SpeechTexter
SpeechTexterで口述を開始し、問題なく音声を単語に変換します。 これは無料の多言語音声認識アプリで、音声だけを使用して、ドキュメント、レポート、書籍、ブログ投稿などの文字起こしを支援することを目的としています。
そのカスタム辞書を使用すると、住所、電話番号、句読点などの一般的に使用されるデータを挿入する場合に、短いコマンドを追加できます。

Chromeブラウザは、スマートフォン向けのAndroid OSとともに、デスクトップ向けのこのアプリテクノロジーをサポートしています。 モバイルでChromeを含む他のブラウザにはまだ実装されていません。 SpeechTexterは、世界中の作家、ブロガー、教師、学生、ジャーナリストなどに最適です。
このアプリケーションは、一般に90%以上の精度を提供し、米国英語では95%以上の精度を提供します。 また、このツールを使用して、話すスキルを流暢にしながら、外国語で特定の単語を発音する方法を学ぶことができます。
SpeechTexterに含まれる機能は、リアルタイムでの継続的で強力な音声認識、カスタムコマンドを備えたカスタム辞書、および60以上のサポートされている言語です。 これらの言語には、アラビア語、ブルガリア語、中国語、デンマーク語、英語、ドイツ語、フランス語、ヒンディー語、日本語、韓国語、ポーランド語、ロシア語、スペイン語、タミル語、ウルドゥー語、ズールー語などがあります。
スピーチノート
何年にもわたってバトルテストが行われているSpeechnotesは、何千、何百万ものブロガー、ライター、思想家、ドライバー、そして簡単で高速なタイピングを好む人々から信頼されています。 長いテキストを書くのに苦労する必要がなくなるので、それはあなたの人生を楽にします。
スピーチノートは、他のスピーチからテキストへのソリューションとは異なり、考えたり呼吸したりするために休憩を取りながら聞くのをやめることはありません。 簡単なディクテーションと記号や句読点のタップにより、書き込みプロセスを高速化するように設計されたキーボードが組み込まれています。
この音声対応のメモ帳は、オプションのGoogleドライブバックアップなどの機能で創造性とアイデアを強化するため、メモを失うことはありません。 グーグル音声認識を組み込むことでより高い精度を提供し、既存の日付または時刻のワンタップスタンプを楽しむことができます。
Google Chromeブラウザで直接オンラインで動作するため、インストールやダウンロードは必要ありません。 このソリューションは、デスクトップ、PC、Chromebook、およびラップトップで実行できます。 さらに、Speechnotesはスペルミスやタイプミスを減らし、ドキュメントを共有したり、ワンタップでエクスポートして印刷したりできます。
それに含まれる他の機能は、自動キャピタライゼーションと間隔、自動保存、ドライブバックアップ、口述中のテキスト編集、同時音声入力、ワンクリック文字起こし用のウィジェット、楽しい絵文字です。 また、改行、句読点などの複数の言語コマンドも認識します。
任意のテキストを挿入するために使用できる10個の編集可能なキーを取得します。このツールは、頻繁に使用する一般的なテキスト、アドレス、電子メール、フレーズ、挨拶などにも最適なので、再入力する必要はありません。毎回。

彼らはユーザーのプライバシーを尊重しているため、データを保存したり、サードパーティと共有したりすることはありません。 このソリューションはGoogleの音声認識エンジンを使用しているため、関連するデータのみがそれらに送られます。 オプションのGoogleOAuthを使用して、ファイルをGoogleドライブにアップロードすることもできます。
そして、以下は企業が強力なアプリケーションを構築するのに適しています。 それらはすべてAIを利用しています。
カワウソ
Otterを使用して、会議、講義、インタビュー、およびその他の重要な音声会話のための豊富なメモを作成します。 このAIを活用したアシスタントは、組織やチームがどんなに大きくても小さくても、重要な会話を書き写すのに役立ちます。
彼らの新しいリリースであるOtter2.0は、より多くの機能をもたらし、生産性とコラボレーションの向上に役立ちます。 また、彼らのビジネスプランには、特にSMBや企業向けにカスタマイズされた機能があります。 必要なのは、音声を録音してリアルタイムで確認することだけです。 そして、選択したデバイスから自由に会話を検索、再生、整理、編集、共有できます。
Webブラウザまたはスマートフォンで会話を録音できます。 Otterは、他のサービスから録音をインポートして同期する柔軟性も提供し、Zoomと統合することもできます。
ライブの文字起こし機能を利用して、文字起こしをリアルタイムでストリーミングし、リッチテキスト、画像、音声、キーフレーズ、スピーカーIDを数分で含めることができます。 音声メモをエクスポートして他の人に通知すると、全員が同じページにいることができます。 また、グループを作成し、プロジェクトに共同作業者を招待して、効果的に整理することもできます。
Otterは、必要なものをすばやく書き写し、記録し、検索できるようにすることで、お金と時間を節約します。 要約キーワードからジャンプして、メモ内のインスタンスを表示したり、すばやく検索したり、再生を高速化したり、無音をスキップしたり、長い録音をざっと読んだりすることができます。
アンビエントボイスインテリジェンスはOtterを強化します。これが、Otterが毎日学習して賢くなる理由です。 Otterをトレーニングして、声を認識し、コラボレーションとスマートな作業を支援し、特別なフレーズや用語を学ぶことができます。
Otterの基本プランは無料で、毎月600分の音声文字変換クォータと40分の音声文字変換/会話を利用できます。 有料プランは、月額8.33ドルから始まり、月間文字起こし割り当ての6,000分と文字起こし/会話の4時間です。
Rev.ai
Rev.aiは、世界トップクラスの音声認識APIを搭載した優れた音声テキストライブストリーミングアプリです。 マイクのスイッチを入れて話し始めるだけで、音声がテキストに変換されます。
これは、エンターテインメントおよびメディア企業が組織するすべてのライブブロードキャスト/ Webコンテンツのアクセシビリティを向上させるのに役立ちます。 Rev.aiはまた、教育機関がライブストリーミングを使用して、講義、イベント、およびウェビナーのリーチを拡大するのを支援します。
また、電話を転記して営業またはサポートエージェントをトレーニングしたり、会議やイベントをリアルタイムで転記したりすることもできます。 彼らの英語モデルは、世界中の主要な英語のアクセントをすべてカバーしているため、さまざまな会話や話者をキャプチャするために追加料金を支払ったり、モデルを切り替えたりする必要がありません。 さらに、彼らは今後数日でさらに多くの言語を追加する予定です。
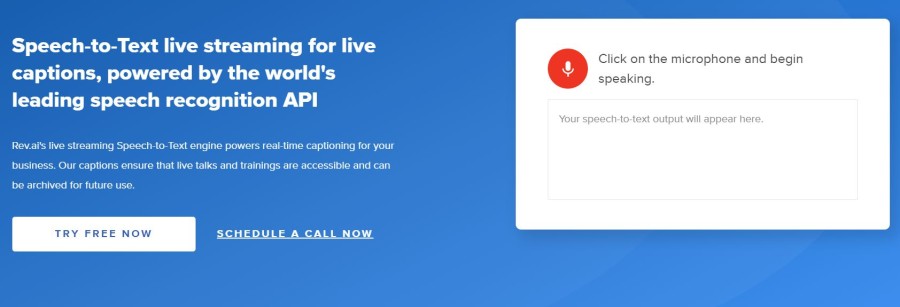
Rev.aiを使用すると、リアルタイムのキャプションと制限されたラグを取得できます。 自然処理言語(NPL)を利用して、読み取り可能で、コンテキストを認識し、完全に句読された非常に正確なトランスクリプトを生成します。 業界固有の用語、一意の名前などを共有して、トランスクリプトの精度を高めます。
また、キャプションから約600の不快な言葉をすばやく除外することもできます。 スタンプを追加して、すべての単語の開始と終了のタイミングを表示することもできます。 Rev.aiは、RTMPSやWebSocketなどの複数のストリーミングプロトコルをサポートしています。
これらの音声認識オプションはすべて、個人的な使用に最適であり、企業でも機能します。 それでは、ビジネス向けの優れた音声認識製品を構築したい場合は、さらにいくつかのAPIオプションを見つけましょう。
Google Cloud
Googleが提供するAIテクノロジーで構築された強力なAPIを使用して、音声をテキストに正確に変換します。 それはあなたがファイルにまたはリアルタイムで保存されたものを転記することを可能にします。 このソリューションを使用すると、音声コマンドを通じて優れたユーザーエクスペリエンスを提供できます。
これとは別に、サービスを強化するための顧客とのやり取りに関する深い洞察を得ることができます。 自動音声認識(ASR)にGoogleの最も洗練されたディープラーニングとニューラルネットワークアルゴリズムを適用することにより、トップレベルの精度を実現します。
ユーザーがどこにいても、125以上の言語とそのバリエーションをサポートする音声認識ソリューションを使用して、世界中のユーザーに連絡することができます。 APIまたはSpeech-to-TextOn-Premを使用してオンプレミスにデプロイすることで、クラウド内のどこにでもソリューションをデプロイできます。
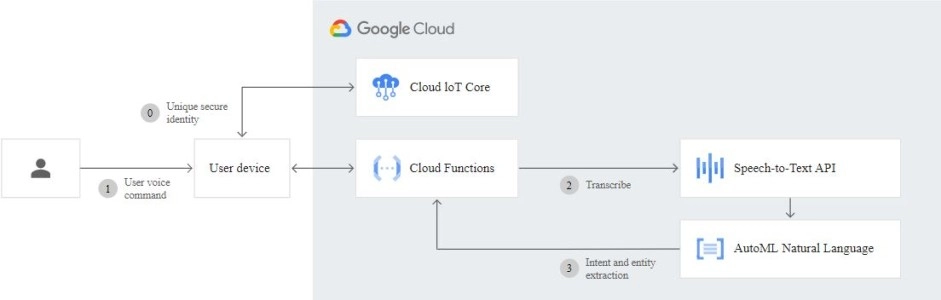
Speech-to-Text APIを使用すると、アプリに音声文字変換を簡単に組み込むことができます。 マイクを使用するか、デバイスに保存されているファイルをアップロードするかの2つのオプションで音声を録音できます。 次に、言語を選択して文字起こしを開始できます。
音声認識をカスタマイズして、いくつかのヒントを提供し、精度を高めることで、まれな単語やドメイン固有の単語を転記できる音声適応などの機能を利用できます。 話された番号を住所、通貨、年などに自動的に変換できます。
電話や音声制御に利用できる多くのトレーニング済みモデルから選択し、ドメイン固有の品質ニーズを満たすためにビデオ文字変換を最適化します。 APIがマイクまたは事前に録音されたファイルから提供された音声入力を処理するときに、音声認識出力をリアルタイムで受信します。
IBMワトソン
IBMのWatsonSpeech to Textは、AIを活用した高度な音声認識および音声文字変換ソリューションです。 音声分析、エージェントアシスタンス、顧客セルフサービスなど、さまざまな言語とユースケースでの正確で高速な文字起こしを可能にします。
洗練された機械学習モデルの使用を開始するのは簡単で、独自のユースケース、オーディオ特性、ドメイン言語に基づいてカスタマイズすることもできます。 IBMのAIはクラス最高であり、Watson Speech toTextとシームレスに組み込まれています。
データはIBMの堅固なデータ・ガバナンス慣行の下で保護されたままなので、このソリューションを自信を持って使用してください。 グローバル言語向けに設計されており、オンプレミスまたは任意のクラウド(プライベート、パブリック、ハイブリッド)にデプロイできます。
一般的なクエリに効率的かつ迅速に対応することで、顧客の待ち時間を短縮します。 また、これを使用して、ベストアクションプロンプトおよびドキュメント検索を使用して通話中にエージェントを支援することもできます。 また、顧客の苦情、通話パターン、およびエージェントトレーニングの問題を特定することもできます。
その機能には、言語や音響トレーニングなどのオプションで認識精度を向上させるために、ニューラルテクノロジーとモデルトレーニングオプションを活用した自動音声認識が含まれます。
Microsoft Azure
MicrosoftAzureのSpeechto Textサービスは、音声をより正確にテキストに変換します。 この最先端のソフトウェアは、85以上のグローバル言語とバリアントをサポートしています。 特定の単語を追加してモデルをカスタマイズし、ドメイン固有のフレーズのテキストの精度を高めることができます。
選択したプログラミング言語でも、文字起こしされたテキストの分析または検索を有効にします。 コンテナの端またはクラウドの任意の場所に音声をテキストに展開します。 あなたが彼らの技術で開発するソフトウェアは、他のマイクロソフト製品を動かす同じ強力な技術によって支えられているでしょう。
このソリューションは、オーディオファイル、BLOBストレージ、マイクなどの複数のソースからのオーディオ入力をサポートします。 スピーカーのダイアリゼーションを使用して正確な単語を判別できます。また、句読点と書式設定を使用して、読みやすいトランスクリプトを自動的に取得できます。
業界固有の用語を学習するために、スピーチをテキストモデルに合わせて設計します。 アクセント、背景、固有の語彙などの音声認識の障壁を克服することもできます。トランスクリプトと音声データをアップロードしてモデルをカスタマイズし、Office 365データを使用してカスタム音声認識モデルを自動的に生成し、精度を最適化します。
Azureは、HIPAA、PCI DSS、ISO、HITECH、およびFedRAMPによる認証を含む、包括的なデータセキュリティとプライバシーを提供します。 データが保存されることはなく、暗号化された音声データまたはモデルをいつでも自由に表示または削除できます。
結論
これは自動化の時代であり、効率を高めて手作業を減らすために利用できるオプションがたくさんあります。 そのような解決策の1つは、音声を使用して入力するのに役立つ音声認識ソフトウェアです。
したがって、時間を節約し、手にふさわしい残りの部分を与えるために、上記の音声テキスト変換ソフトウェアを選択して、このテクノロジーを利用してください。