
Przegląd infrastruktury chmury i monitorowania aplikacji
Opublikowany: 2021-07-12Przedsiębiorstwa zdecydowały się na usługi w chmurze, aby pozostać na czasie w erze przemysłu 4.0.
Administratorzy systemu i programiści chmury mogą teraz udostępniać zasoby sieciowe, zasoby pamięci masowej, maszyny wirtualne, systemy ERP, oprogramowanie systemowe i oprogramowanie aplikacji na większości platform chmur publicznych, prywatnych lub hybrydowych.
Przejście organizacji na chmurę można przypisać dostępności na żądanie, tworzeniu wartości i optymalizacji w czasie rzeczywistym, co jest możliwe tylko w przypadku chmury.
Ale z niezliczonymi korzyściami wiąże się ciężar monitorowania infrastruktury i aplikacji działających w chmurze.
Ten artykuł rzuci światło na monitorowanie w chmurze, a na koniec dostarczy informacji o narzędziach, które ułatwią tobie jako programiście w chmurze monitorowanie infrastruktury i aplikacji.
Monitorowanie infrastruktury i aplikacji
Monitorowanie infrastruktury i aplikacji to po prostu strategia zarządzania. Strategia zarządzania obejmuje dowolny operacyjny przepływ pracy, który ocenia zasoby obliczeniowe i aplikacje w celu uzyskania wglądu w wydajność, kondycję i dostępność usług działających w dowolnej infrastrukturze.
Monitorowanie chmury polega zatem na obserwowaniu wskaźników wydajności serwerów internetowych, aplikacji, serwerów pamięci masowej, wirtualnych sieci w chmurze, maszyn wirtualnych i wszelkich innych usług działających w chmurze.
Przyjrzyjmy się niektórym zaletom monitorowania w chmurze.
Rzuć światło na zużycie zasobów w chmurze
Monitorowanie jako usługa w chmurze pomaga organizacjom zrozumieć działające zasoby i związane z nimi koszty za pomocą tagów. Administratorzy mogą następnie używać danych o zasobach do ustalania priorytetów i skalowania zasobów na podstawie kosztów i popytu.
Optymalizacja wydajności
W oparciu o wyniki alertów systemowych, zdarzeń i wyzwalaczy skonfigurowanych do śledzenia zasobów infrastruktury, programiści mogą przeprowadzać dostrajanie zasobów, takie jak równoważenie obciążenia, w celu skalowania infrastruktury w górę iw dół.
Gwarantowane bezpieczeństwo systemu
Monitorowanie użytkowników w czasie rzeczywistym, monitorowanie ruchu przychodzącego i wychodzącego oraz częste testy przeprowadzane na punktach końcowych API służą jako modele bezpieczeństwa dla infrastruktury/aplikacji Cloud. Widoczność oznacza, że każdą anomalię w systemie można łatwo oznaczyć przed eskalacją.
Popularne narzędzia do monitorowania dla programistów chmury
Poniżej znajdują się niektóre z najczęściej używanych narzędzi do monitorowania w chmurze dostępnych do wypróbowania każdego administratora systemu lub programisty w chmurze!
CloudWatch
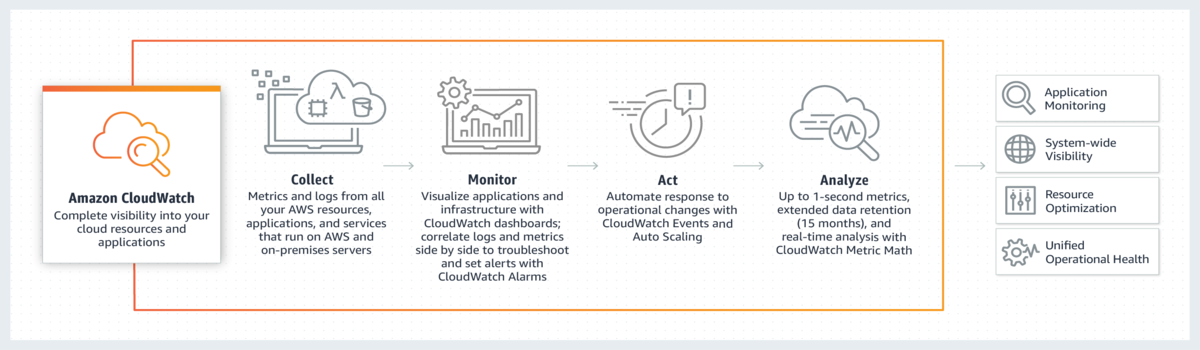
CloudWatch, zbudowany przez Amazon, to narzędzie do obserwacji i monitorowania, które dostarcza dane/wglądy dotyczące wydajności systemu, działania aplikacji i stanu infrastruktury chmury.
Amazon CloudWatch to narzędzie dla zespołów DevOps, inżynierów Site Reliability i Cloud Developers. Deweloperzy mogą bezpłatnie rozpocząć korzystanie z CloudWatch w modelu poziomu Free.
Aplikacje i zasoby infrastruktury działające w Amazon Cloud generują dane operacyjne w dziennikach, metrykach i zdarzeniach. Dlatego programiści mogą używać CloudWatch do zbierania i monitorowania metryk oraz danych dziennika w celu wykrywania wydajności aplikacji i wszelkich zmian w infrastrukturze.
CloudWatch zapewnia doskonałą kontrolę nad infrastrukturą chmury dzięki proaktywnemu rozwiązywaniu problemów, optymalizacji zasobów, analizie dzienników i skróceniu średniego czasu do rozwiązania. (czas średni)
Dzięki CloudWatch możesz monitorować kontenery, instancje ECS, Amazon EKS i wszystkie instancje aplikacji działające w środowiskach Cloud.
Dynatrace
Dynatrace to platforma inteligencji oprogramowania, która dostarcza Twoje wymagania dotyczące monitorowania w jednym miejscu. Narzędzie opiera się na sztucznej inteligencji, aby zapewnić zautomatyzowaną i inteligentną obserwację całej infrastruktury i aplikacji w chmurze.
Dynatrace to narzędzie do obserwacji oparte na agentach. Zawiera OneAgent, instalowalny i inteligentny agent, który automatyzuje monitorowanie całego systemu. OneAgent zbiera metryki z każdej warstwy stosu aplikacji.
W celu monitorowania infrastruktury OneAgent może zbierać metryki z infrastruktury bezserwerowej, kontenerów, podów, VPC, a nawet baz danych w chmurze i nie tylko.
Dynatrace wykorzystuje technologię PurePath, aby zapewnić widoczność aplikacji mobilnych i internetowych na poziomie kodu. W rezultacie programiści uzyskują wgląd w dostępność i wydajność transakcji front-facing i backend działających w dowolnym środowisku chmury.
Co więcej, narzędzie to nie tylko dostarcza ślady, metryki i dane dziennika dla samych środowisk lokalnych. Umożliwia integrację wielu technologii chmurowych i rozszerzanie narzędzi innych firm w celu utrzymania bezprzerwowego monitorowania aplikacji znajdujących się w chmurze. Poza tym programiści mogą korzystać Dynatrace API wstrzyknąć zebrane dane do innych sprawozdawczych strona 3 rd i analitycznych narzędzi do bardziej intuicyjnych raportów systemowych.

Aby rozpocząć korzystanie z Dynatrace, możesz zarejestrować się w bezpłatnej wersji próbnej i wdrożyć narzędzie w swoim środowisku w celu pełnego monitorowania.
Datadog
Podłączenie Datadog do infrastruktury lokalnej lub w chmurze zapewnia szczegółowy wgląd w wydajność infrastruktury i aplikacji.
Wszystko można wyświetlić w sposób wyczerpujący, od hostów w sieci po instancje kontenerów, a nawet procesy na żywo działające w dowolnej infrastrukturze. To narzędzie do monitorowania ma wbudowane funkcje, takie jak Datadog Agent, monitor wydajności aplikacji Datadog, menedżer dzienników Datadog i Continuous profiler. Wbudowane narzędzia odpowiadają za zbieranie metryk systemowych i wykrywanie wszelkich zmian w systemie.
Deweloperzy mogą następnie obserwować i analizować zebrane metryki wydajności za pomocą elastycznych pulpitów nawigacyjnych. Tworzone dashboardy prezentują trendy w metrykach.
Na przykład można wyświetlić wskaźniki błędów aplikacji w chmurze, opóźnienia w punktach końcowych sieci oraz obsługiwane lub nieudane żądania HTTPS. W związku z tym administratorzy/programiści chmury mogą tworzyć podsumowania metryk z pulpitu nawigacyjnego za dowolny okres.
Datadog zapewnia integrację opartą na agentach, opartą na uwierzytelnianiu i bibliotekach, aby osiągnąć ujednolicone monitorowanie systemu w przypadkach, gdy systemy i aplikacje są rozproszone.
Najfajniejszą cechą Datadog jest wygoda, jaką daje programistom w przeprowadzaniu syntetycznego monitorowania wydajności aplikacji za pomocą syntetycznych testów. Testy syntetyczne to symulowane żądania, które symulują usługi internetowe i interfejsy API, aby zapewnić kompleksową widoczność aplikacji.
Prometeusz
Prometheus to doskonałe narzędzie open source do monitorowania i ostrzegania dla systemów chmurowych, hybrydowych i lokalnych. To narzędzie agreguje metryki systemowe jako dane szeregów czasowych, wielowymiarowy model danych, który jest identyfikowany przez nazwę metryki i pary klucz-wartość.
Na przykład żądanie HTPP jako nazwa (klucz) metryki i odpowiadająca im łączna liczba tych żądań jako wartość.
Prometheus współpracuje z autonomicznym, pojedynczym serwerem Prometheus, który pobiera metryki z kilku źródeł danych i przechowuje je jako dane szeregów czasowych.
Ponadto narzędzie zawiera platformy wizualizacyjne, takie jak przeglądarki Grafana, Consoles i Expression.
W przypadku alertów systemowych Prometheus oferuje menedżera alertów, który umożliwia elastyczne wysyłanie powiadomień i zarządzanie nimi za pośrednictwem wiadomości e-mail, systemów dyżurnych i platform czatowych, takich jak Slack, gdzie programiści mogą proaktywnie reagować na zgłaszane problemy systemowe.
Pożar metryczny
MetricFire to zestaw narzędzi typu open source, które pomagają administratorom gromadzić, przechowywać i wizualizować metryki infrastruktury chmury. Metryki są istotne w identyfikowaniu obciążenia systemu, niezawodności systemu i potrzeby optymalizacji zasobów. Narzędzie do monitorowania obsługuje trzy narzędzia typu open source — Graphite, Prometheus i Grafana jako usługi, które współpracują ze sobą w celu poprawy jakości monitorowania.
Graphite, na przykład, obsługuje gromadzenie metryk za pośrednictwem agenta Hosted Graphite, który oferuje usługi gromadzenia danych, takie jak diament. Diamond, demon Pythona, zbiera metryki procesora, metryki wykorzystania dysku, sieciowe operacje we/wy, metryki aplikacji internetowych i nie tylko.
Deweloperzy mogą następnie wyświetlać metryki w bogatych w funkcje hostowanych pulpitach Grafana lub pulpitach nawigacyjnych Graphite. Za pomocą pulpitów nawigacyjnych programiści mogą obserwować metryki z wielu źródeł, takich jak Graphite, Prometheus i inne zewnętrzne oprogramowanie do monitorowania chmury.
Pulpity nawigacyjne Grafana są wysoce konfigurowalne i mogą być przekształcane w celu spełnienia większości wymagań dotyczących wizualizacji. Deweloperzy mogą również tworzyć złożone wykresy i wykresy zawierające wiele metryk i śladów, aby dostarczać jednoznaczne raporty na temat wydajności systemów.
Dzięki hostowanym narzędziom programiści mogą błyskawicznie zrozumieć dane systemowe bez konieczności instalowania kilku narzędzi innych firm.
Zawijanie
W tym celu zobaczyliśmy, czym jest monitorowanie infrastruktury i aplikacji w chmurze. Ponadto przyjrzeliśmy się również niektórym korzyściom płynącym z monitorowania.
Podsumowując, wyróżnione narzędzia sprawią, że monitorowanie będzie bezproblemowe dzięki ich dużej autonomii i elastyczności. Możesz wypróbować bezpłatne wersje próbne i mieć dane systemowe na wyciągnięcie ręki.
Miłego monitorowania!