
13 ferramentas de big data para conhecer como um cientista de dados
Publicados: 2021-11-30Na era da informação, os data centers coletam grandes quantidades de dados. Os dados coletados vêm de várias fontes, como transações financeiras, interações com clientes, mídias sociais e muitas outras fontes e, mais importante, acumulam-se mais rapidamente.
Os dados podem ser diversos e sensíveis e requerem as ferramentas certas para torná-los significativos, pois têm potencial ilimitado para modernizar estatísticas de negócios, informações e mudar vidas.

Ferramentas de Big Data e cientistas de dados são proeminentes em tais cenários.
Uma quantidade tão grande de dados diversos dificulta o processamento usando ferramentas e técnicas tradicionais, como o Excel. O Excel não é realmente um banco de dados e tem um limite (65.536 linhas) para armazenar dados.
A análise de dados no Excel mostra uma integridade de dados ruim. A longo prazo, os dados armazenados no Excel têm segurança e conformidade limitadas, taxas de recuperação de desastres muito baixas e nenhum controle de versão adequado.
Para processar conjuntos de dados tão grandes e diversos, é necessário um conjunto exclusivo de ferramentas, chamadas ferramentas de dados, para examinar, processar e extrair informações valiosas. Essas ferramentas permitem que você se aprofunde em seus dados para encontrar insights e padrões de dados mais significativos.
Lidar com ferramentas e dados de tecnologia tão complexos naturalmente requer um conjunto de habilidades único, e é por isso que o cientista de dados desempenha um papel vital no big data.
A importância das ferramentas de big data
Os dados são a base de qualquer organização e são usados para extrair informações valiosas, realizar análises detalhadas, criar oportunidades e planejar novos marcos e visões de negócios.
Mais e mais dados são criados todos os dias que devem ser armazenados de forma eficiente e segura e recuperados quando necessário. O tamanho, a variedade e a rápida mudança desses dados exigem novas ferramentas de big data, armazenamento diferente e métodos de análise.
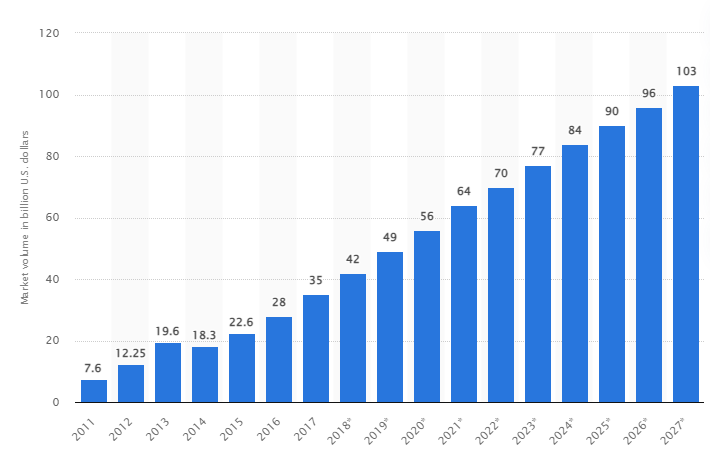
De acordo com um estudo, o mercado global de big data deve crescer para US$ 103 bilhões até 2027, mais que o dobro do tamanho do mercado esperado em 2018.
Os desafios atuais da indústria
O termo “big data” foi usado recentemente para se referir a conjuntos de dados que cresceram tanto que são difíceis de usar com sistemas tradicionais de gerenciamento de banco de dados (DBMS).
Os tamanhos dos dados estão aumentando constantemente e hoje variam de dezenas de terabytes (TB) a muitos petabytes (PB) em um único conjunto de dados. O tamanho desses conjuntos de dados excede a capacidade de um software comum de processar, gerenciar, pesquisar, compartilhar e visualizar ao longo do tempo.
A formação de big data levará ao seguinte:
- Gestão e melhoria da qualidade
- Cadeia de suprimentos e gestão de eficiência
- Inteligência do cliente
- Análise de dados e tomada de decisão
- Gerenciamento de riscos e detecção de fraudes
Nesta seção, analisamos as melhores ferramentas de big data e como os cientistas de dados usam essas tecnologias para filtrá-las, analisá-las, armazená-las e extraí-las quando as empresas desejam uma análise mais profunda para melhorar e expandir seus negócios.
Apache Hadoop
Apache Hadoop é uma plataforma Java de código aberto que armazena e processa grandes quantidades de dados.
O Hadoop funciona mapeando grandes conjuntos de dados (de terabytes a petabytes), analisando tarefas entre clusters e dividindo-os em partes menores (64 MB a 128 MB), resultando em um processamento de dados mais rápido.
Para armazenar e processar dados, os dados são enviados para o cluster do Hadoop, o HDFS (sistema de arquivos distribuído do Hadoop) armazena os dados, o MapReduce processa os dados e o YARN (Yet another resource negociator) divide tarefas e atribui recursos.
É adequado para cientistas de dados, desenvolvedores e analistas de várias empresas e organizações para pesquisa e produção.
Características
- Replicação de dados: várias cópias do bloco são armazenadas em nós diferentes e servem como tolerância a falhas em caso de erro.
- Altamente escalável: oferece escalabilidade vertical e horizontal
- Integração com outros modelos Apache, Cloudera e Hortonworks
Considere fazer este brilhante curso online para aprender Big Data com o Apache Spark.
Rapidminer
O site do Rapidminer afirma que aproximadamente 40.000 organizações em todo o mundo usam seu software para aumentar as vendas, reduzir custos e evitar riscos.
O software recebeu vários prêmios: Gartner Vision Awards 2021 para plataformas de ciência de dados e aprendizado de máquina, análise preditiva multimodal e soluções de aprendizado de máquina da plataforma de aprendizado de máquina e ciência de dados mais fácil de usar da Forrester e Crowd no relatório G2 da primavera de 2021.
É uma plataforma de ponta a ponta para o ciclo de vida científico e é perfeitamente integrada e otimizada para a construção de modelos de ML (machine learning). Ele documenta automaticamente cada etapa de preparação, modelagem e validação para total transparência.
É um software pago disponível em três versões: Prep Data, Create and Validate e Deploy Model. Está disponível gratuitamente para instituições de ensino, e o RapidMiner é usado por mais de 4.000 universidades em todo o mundo.
Características
- Ele verifica os dados para identificar padrões e corrigir problemas de qualidade
- Ele usa um designer de fluxo de trabalho sem código com mais de 1500 algoritmos
- Integrando modelos de aprendizado de máquina em aplicativos de negócios existentes
Quadro
O Tableau oferece flexibilidade para analisar visualmente plataformas, resolver problemas e capacitar pessoas e organizações. Ele é baseado na tecnologia VizQL (linguagem visual para consultas de banco de dados), que converte arrastar e soltar em consultas de dados por meio de uma interface de usuário intuitiva.
O Tableau foi adquirido pela Salesforce em 2019. Ele permite vincular dados de fontes como bancos de dados SQL, planilhas ou aplicativos em nuvem, como Google Analytics e Salesforce.
Os usuários podem adquirir suas versões Creator, Explorer e Viewer com base em preferências comerciais ou individuais, pois cada uma possui características e funções próprias.
É ideal para analistas, cientistas de dados, setor educacional e usuários de negócios implementarem e equilibrarem uma cultura orientada por dados e avaliá-la por meio de resultados.
Características
- Os painéis fornecem uma visão geral completa dos dados na forma de elementos visuais, objetos e texto.
- Grande seleção de gráficos de dados: histogramas, gráficos de Gantt, gráficos, gráficos de movimento e muito mais
- Proteção de filtro em nível de linha para manter os dados seguros e estáveis
- Sua arquitetura oferece análises e previsões previsíveis
Aprender o Tableau é fácil.
Cloudera
A Cloudera oferece uma plataforma segura para nuvem e data centers para gerenciamento de big data. Ele usa análise de dados e aprendizado de máquina para transformar dados complexos em insights claros e acionáveis.
A Cloudera oferece soluções e ferramentas para nuvens privadas e híbridas, engenharia de dados, fluxo de dados, armazenamento de dados, ciência de dados para cientistas de dados e muito mais.
Uma plataforma unificada e análises multifuncionais aprimoram o processo de descoberta de insights orientado por dados. Sua ciência de dados fornece conectividade a qualquer sistema que a organização use, não apenas Cloudera e Hortonworks (ambas as empresas têm parceria).
Os cientistas de dados gerenciam suas próprias atividades, como análise, planejamento, monitoramento e notificações por e-mail por meio de planilhas interativas de ciência de dados. Por padrão, é uma plataforma compatível com segurança que permite que os cientistas de dados acessem dados do Hadoop e executem consultas do Spark facilmente.
A plataforma é adequada para engenheiros de dados, cientistas de dados e profissionais de TI em vários setores, como hospitais, instituições financeiras, telecomunicações e muitos outros.
Características
- Suporta todas as principais nuvens privadas e públicas, enquanto o data Science workbench suporta implantações locais
- Canais de dados automatizados convertem dados em formulários utilizáveis e os integram com outras fontes.
- O fluxo de trabalho uniforme permite a construção, treinamento e implementação rápidos de modelos.
- Ambiente seguro para autenticação, autorização e criptografia do Hadoop
Colmeia Apache
Apache Hive é um projeto de código aberto desenvolvido em cima do Apache Hadoop. Ele permite ler, escrever e gerenciar grandes conjuntos de dados disponíveis em vários repositórios e permite que os usuários combinem suas próprias funções para análises personalizadas.
O Hive foi projetado para tarefas de armazenamento tradicionais e não se destina a tarefas de processamento online. Seus robustos quadros em lote oferecem escalabilidade, desempenho, escalabilidade e tolerância a falhas.
É adequado para extração de dados, modelagem preditiva e documentos de indexação. Não recomendado para consultar dados em tempo real, pois apresenta latência na obtenção de resultados.
Características
- Suporta o mecanismo de computação MapReduce, Tez e Spark
- Processe grandes conjuntos de dados, vários petabytes de tamanho
- Muito fácil de codificar em comparação com Java
- Fornece tolerância a falhas armazenando dados no sistema de arquivos distribuído Apache Hadoop
Apache Storm
O Storm é uma plataforma gratuita e de código aberto usada para processar fluxos de dados ilimitados. Ele fornece o menor conjunto de unidades de processamento usado para desenvolver aplicativos que podem processar grandes quantidades de dados em tempo real.
Uma tempestade é rápida o suficiente para processar um milhão de tuplas por segundo por nó e é fácil de operar.
O Apache Storm permite adicionar mais nós ao cluster e aumentar o poder de processamento do aplicativo. A capacidade de processamento pode ser duplicada adicionando nós à medida que a escalabilidade horizontal é mantida.
Os cientistas de dados podem usar o Storm para DRPC (chamadas de procedimento remoto distribuído), análise de ETL (Retrieval-Conversion-Load) em tempo real, computação contínua, aprendizado de máquina online, etc. Ele é configurado para atender às necessidades de processamento em tempo real do Twitter , Yahoo e Flipboard.
Características
- Fácil de usar com qualquer linguagem de programação
- Ele está integrado em todos os sistemas de filas e em todos os bancos de dados.
- O Storm usa o Zookeeper para gerenciar clusters e escala para tamanhos de cluster maiores
- A proteção de dados garantida substitui as tuplas perdidas se algo der errado
Ciência de dados do floco de neve
O maior desafio para os cientistas de dados é preparar dados de diferentes recursos, pois o tempo máximo é gasto na recuperação, consolidação, limpeza e preparação dos dados. Ele é abordado por Snowflake.

Ele oferece uma plataforma única de alto desempenho que elimina o incômodo e o atraso causados pelo ETL (Load Transformation and Extraction). Ele também pode ser integrado com as mais recentes ferramentas e bibliotecas de aprendizado de máquina (ML), como Dask e Saturn Cloud.
O Snowflake oferece uma arquitetura exclusiva de clusters de computação dedicados para cada carga de trabalho para executar essas atividades de computação de alto nível, portanto, não há compartilhamento de recursos entre as cargas de trabalho de ciência de dados e BI (business intelligence).
Ele suporta tipos de dados de dados estruturados, semiestruturados (JSON, Avro, ORC, Parquet ou XML) e não estruturados. Ele usa uma estratégia de data lake para melhorar o acesso, o desempenho e a segurança dos dados.
Cientistas e analistas de dados usam flocos de neve em vários setores, incluindo finanças, mídia e entretenimento, varejo, saúde e ciências da vida, tecnologia e setor público.
Características
- Alta compactação de dados para reduzir os custos de armazenamento
- Fornece criptografia de dados em repouso e em trânsito
- Mecanismo de processamento rápido com baixa complexidade operacional
- Perfil de dados integrado com visualizações de tabela, gráfico e histograma
Datarobot
A Datarobot é líder mundial na nuvem com IA (Inteligência Artificial). Sua plataforma exclusiva foi projetada para atender a todos os setores, incluindo usuários e diferentes tipos de dados.
A empresa afirma que o software é usado por um terço das empresas da Fortune 50 e fornece mais de um trilhão de estimativas em vários setores.
O Dataroabot usa machine learning (ML) automatizado e foi projetado para que profissionais de dados corporativos criem, adaptem e implantem rapidamente modelos de previsão precisos.
Ele oferece aos cientistas acesso fácil a muitos dos mais recentes algoritmos de aprendizado de máquina com total transparência para automatizar o pré-processamento de dados. O software desenvolveu clientes R e Python dedicados para cientistas resolverem problemas complexos de ciência de dados.
Ele ajuda a automatizar os processos de qualidade de dados, engenharia de recursos e implementação para facilitar as atividades dos cientistas de dados. É um produto premium, e o preço está disponível mediante solicitação.
Características
- Aumenta o valor do negócio em termos de rentabilidade, previsão simplificada
- Processos de implementação e automação
- Suporta algoritmos de Python, Spark, TensorFlow e outras fontes.
- A integração da API permite que você escolha entre centenas de modelos
TensorFlow
O TensorFlow é uma biblioteca baseada em IA (inteligência artificial) da comunidade que usa diagramas de fluxo de dados para criar, treinar e implantar aplicativos de aprendizado de máquina (ML). Isso permite que os desenvolvedores criem grandes redes neurais em camadas.
Ele inclui três modelos: TensorFlow.js, TensorFlow Lite e TensorFlow Extended (TFX). Seu modo javascript é usado para treinar e implantar modelos no navegador e no Node.js ao mesmo tempo. Seu modo lite é para implantar modelos em dispositivos móveis e incorporados, e o modelo TFX é para preparar dados, validar e implantar modelos.
Devido à sua plataforma robusta, pode ser implantado em servidores, dispositivos de borda ou na web, independentemente da linguagem de programação.
O TFX contém mecanismos para impor pipelines de ML que podem ser ascendentes e fornecem tarefas de desempenho geral robustas. Os pipelines de engenharia de dados, como Kubeflow e Apache Airflow, dão suporte ao TFX.
A plataforma Tensorflow é adequada para iniciantes. Intermediário e para especialistas para treinar uma rede generativa de adversários para gerar imagens de dígitos manuscritos usando Keras.
Características
- Pode implantar modelos de ML no local, na nuvem e no navegador, independentemente do idioma
- Construção fácil de modelos usando APIs inatas para repetição rápida de modelos
- Suas várias bibliotecas e modelos complementares apoiam atividades de pesquisa para experimentar
- Construção de modelo fácil usando vários níveis de abstração
Matplotlib
Matplotlib é um software comunitário abrangente para visualizar dados animados e gráficos gráficos para a linguagem de programação Python. Seu design exclusivo é estruturado para que um gráfico de dados visual seja gerado usando algumas linhas de código.
Existem vários aplicativos de terceiros, como programas de desenho, GUIs, mapas de cores, animações e muitos outros, projetados para serem integrados ao Matplotlib.
Sua funcionalidade pode ser estendida com muitas ferramentas como Basemap, Cartopy, GTK-Tools, Natgrid, Seaborn e outras.
Seus melhores recursos incluem o desenho de gráficos e mapas com dados estruturados e não estruturados.
Bigml
Bigml é uma plataforma coletiva e transparente para engenheiros, cientistas de dados, desenvolvedores e analistas. Ele realiza a transformação de dados de ponta a ponta em modelos acionáveis.
Ele efetivamente cria, experimenta, automatiza e gerencia fluxos de trabalho de ml, contribuindo para aplicativos inteligentes em uma ampla variedade de setores.
Essa plataforma programável de ML (aprendizado de máquina) ajuda no sequenciamento, previsão de séries temporais, detecção de associação, regressão, análise de cluster e muito mais.
Sua versão totalmente gerenciável com locatários únicos e múltiplos e uma implantação possível para qualquer provedor de nuvem facilita para as empresas fornecerem acesso a big data a todos.
Seu preço começa em US$ 30 e é gratuito para pequenos conjuntos de dados e fins educacionais, e é usado em mais de 600 universidades.
Devido aos seus algoritmos de ML robustos, é adequado em vários setores, como farmacêutico, entretenimento, automotivo, aeroespacial, saúde, IoT e muitos outros.
Características
- Automatize fluxos de trabalho demorados e complexos em uma única chamada de API.
- Ele pode processar grandes quantidades de dados e executar tarefas paralelas
- A biblioteca é suportada por linguagens de programação populares como Python, Node.js, Ruby, Java, Swift, etc.
- Seus detalhes granulares facilitam o trabalho de auditoria e requisitos regulatórios
Apache Spark
É um dos maiores mecanismos de código aberto amplamente utilizado por grandes empresas. O Spark é usado por 80% das empresas da Fortune 500, de acordo com o site. É compatível com nós únicos e clusters para big data e ML.
Ele é baseado em SQL (Structured Query Language) avançado para suportar grandes quantidades de dados e trabalhar com tabelas estruturadas e dados não estruturados.
A plataforma Spark é conhecida por sua facilidade de uso, grande comunidade e velocidade da luz. Os desenvolvedores usam o Spark para criar aplicativos e executar consultas em Java, Scala, Python, R e SQL.
Características
- Processa dados em lote e em tempo real
- Suporta grandes quantidades de petabytes de dados sem downsampling
- Facilita a combinação de várias bibliotecas como SQL, MLib, Graphx e Stream em um único fluxo de trabalho.
- Funciona no Hadoop YARN, Apache Mesos, Kubernetes e até na nuvem e tem acesso a várias fontes de dados
Knime
O Konstanz Information Miner é uma plataforma intuitiva de código aberto para aplicativos de ciência de dados. Um cientista de dados e analista pode criar fluxos de trabalho visuais sem codificar com a funcionalidade simples de arrastar e soltar.
A versão do servidor é uma plataforma de negociação usada para automação, gerenciamento de ciência de dados e análise de gerenciamento. O KNIME torna os fluxos de trabalho de ciência de dados e componentes reutilizáveis acessíveis a todos.
Características
- Altamente flexível para integração de dados de Oracle, SQL, Hive e muito mais
- Acesse dados de várias fontes, como SharePoint, Amazon Cloud, Salesforce, Twitter e muito mais
- O uso de ml está na forma de construção de modelo, ajuste de desempenho e validação de modelo.
- Insights de dados na forma de visualização, estatísticas, processamento e relatórios
Qual é a importância dos 5 V's do big data?
Os 5 Vs de big data ajudam os cientistas de dados a entender e analisar big data para obter mais insights. Também ajuda a fornecer mais estatísticas úteis para as empresas tomarem decisões informadas e obterem uma vantagem competitiva.
Volume: Big data é baseado em volume. O volume quântico determina o tamanho dos dados. Geralmente contém uma grande quantidade de dados em terabytes, petabytes, etc. Com base no tamanho do volume, os cientistas de dados planejam várias ferramentas e integrações para análise do conjunto de dados.
Velocidade: A velocidade da coleta de dados é fundamental porque algumas empresas exigem informações de dados em tempo real e outras preferem processar dados em pacotes. Quanto mais rápido o fluxo de dados, mais os cientistas de dados podem avaliar e fornecer informações relevantes para a empresa.
Variedade: Os dados vêm de diferentes fontes e, mais importante, não em um formato fixo. Os dados estão disponíveis nos formatos estruturado (formato de banco de dados), semiestruturado (XML/RDF) e não estruturado (dados binários). Com base em estruturas de dados, as ferramentas de big data são usadas para criar, organizar, filtrar e processar dados.
Veracidade: A precisão dos dados e as fontes confiáveis definem o contexto do big data. O conjunto de dados é proveniente de diversas fontes como computadores, dispositivos de rede, dispositivos móveis, mídias sociais, etc. Dessa forma, os dados devem ser analisados para serem enviados ao seu destino.
Valor: Por fim, quanto vale o big data de uma empresa? O papel do cientista de dados é fazer o melhor uso dos dados para demonstrar como os insights de dados podem agregar valor a um negócio.
Conclusão
A lista de big data acima inclui as ferramentas pagas e ferramentas de código aberto. Informações breves e funções são fornecidas para cada ferramenta. Se você estiver procurando por informações descritivas, poderá visitar os sites relevantes.
As empresas que buscam obter uma vantagem competitiva usam big data e ferramentas relacionadas, como IA (inteligência artificial), ML (aprendizado de máquina) e outras tecnologias para realizar ações táticas para melhorar o atendimento ao cliente, pesquisa, marketing, planejamento futuro etc.
As ferramentas de big data são usadas na maioria dos setores, pois pequenas mudanças na produtividade podem se traduzir em economias significativas e grandes lucros. Esperamos que o artigo acima tenha lhe dado uma visão geral das ferramentas de big data e seu significado.
Você pode gostar:
Cursos online para aprender os conceitos básicos de Engenharia de Dados.