
13 инструментов для работы с большими данными, которые нужно знать специалисту по данным
Опубликовано: 2021-11-30В век информации центры обработки данных собирают большие объемы данных. Собранные данные поступают из различных источников, таких как финансовые транзакции, взаимодействие с клиентами, социальные сети и многие другие источники, и, что более важно, накапливаются быстрее.
Данные могут быть разнообразными и конфиденциальными, и для их значимости требуются правильные инструменты, поскольку они обладают неограниченным потенциалом для модернизации бизнес-статистики, информации и изменения жизни.

Инструменты больших данных и специалисты по обработке данных занимают видное место в таких сценариях.
Такое большое количество разнообразных данных затрудняет обработку с использованием традиционных инструментов и методов, таких как Excel. Excel на самом деле не является базой данных и имеет ограничение (65 536 строк) для хранения данных.
Анализ данных в Excel показывает плохую целостность данных. В долгосрочной перспективе данные, хранящиеся в Excel, имеют ограниченную безопасность и соответствие требованиям, очень низкие показатели аварийного восстановления и отсутствие надлежащего контроля версий.
Для обработки таких больших и разнообразных наборов данных необходим уникальный набор инструментов, называемых инструментами обработки данных, для изучения, обработки и извлечения ценной информации. Эти инструменты позволяют вам углубиться в свои данные, чтобы найти более содержательную информацию и шаблоны данных.
Работа с такими сложными технологическими инструментами и данными, естественно, требует уникального набора навыков, и именно поэтому специалист по данным играет жизненно важную роль в работе с большими данными.
Важность инструментов больших данных
Данные являются структурным элементом любой организации и используются для извлечения ценной информации, выполнения подробного анализа, создания возможностей и планирования новых бизнес-вех и концепций.
Каждый день создается все больше и больше данных, которые необходимо эффективно и надежно хранить и вызывать при необходимости. Размер, разнообразие и быстрое изменение этих данных требуют новых инструментов для работы с большими данными, различных методов хранения и анализа.
Согласно исследованию, ожидается, что к 2027 году мировой рынок больших данных вырастет до 103 миллиардов долларов США, что более чем вдвое превышает размер рынка, ожидаемый в 2018 году.
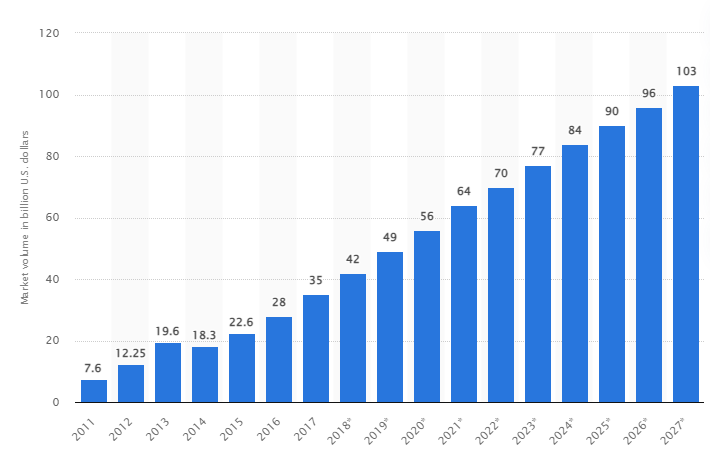
Сегодняшние вызовы отрасли
Термин «большие данные» недавно стал использоваться для обозначения наборов данных, которые стали настолько большими, что их трудно использовать с традиционными системами управления базами данных (СУБД).
Объемы данных постоянно увеличиваются и сегодня варьируются от десятков терабайт (ТБ) до многих петабайт (ПБ) в одном наборе данных. Размер этих наборов данных превышает возможности обычного программного обеспечения для обработки, управления, поиска, совместного использования и визуализации с течением времени.
Формирование больших данных приведет к следующему:
- Управление качеством и улучшение
- Цепочка поставок и управление эффективностью
- Клиентская аналитика
- Анализ данных и принятие решений
- Управление рисками и обнаружение мошенничества
В этом разделе мы рассмотрим лучшие инструменты для работы с большими данными и то, как ученые, работающие с данными, используют эти технологии для фильтрации, анализа, хранения и извлечения данных, когда компаниям нужен более глубокий анализ для улучшения и развития их бизнеса.
Апач Хадуп
Apache Hadoop — это платформа Java с открытым исходным кодом, которая хранит и обрабатывает большие объемы данных.
Hadoop работает, сопоставляя большие наборы данных (от терабайтов до петабайтов), анализируя задачи между кластерами и разбивая их на более мелкие фрагменты (от 64 МБ до 128 МБ), что приводит к более быстрой обработке данных.
Для хранения и обработки данных данные отправляются в кластер Hadoop, HDFS (распределенная файловая система Hadoop) хранит данные, MapReduce обрабатывает данные, а YARN (еще один механизм согласования ресурсов) разделяет задачи и назначает ресурсы.
Он подходит для специалистов по данным, разработчиков и аналитиков из различных компаний и организаций, занимающихся исследованиями и производством.
Функции
- Репликация данных: несколько копий блока хранятся в разных узлах и служат отказоустойчивостью в случае ошибки.
- Высокая масштабируемость: предлагает вертикальную и горизонтальную масштабируемость.
- Интеграция с другими моделями Apache, Cloudera и Hortonworks
Подумайте о том, чтобы пройти этот блестящий онлайн-курс, чтобы изучить большие данные с помощью Apache Spark.
Рапидмайнер
На веб-сайте Rapidminer утверждается, что около 40 000 организаций по всему миру используют свое программное обеспечение для увеличения продаж, снижения затрат и предотвращения рисков.
Программное обеспечение получило несколько наград: Gartner Vision Awards 2021 за платформы для обработки данных и машинного обучения, мультимодальную прогностическую аналитику и решения для машинного обучения от Forrester и самой удобной платформы машинного обучения и обработки данных Crowd в весеннем отчете G2 2021.
Это комплексная платформа для научного жизненного цикла, которая легко интегрируется и оптимизируется для создания моделей ML (машинного обучения). Он автоматически документирует каждый шаг подготовки, моделирования и проверки для полной прозрачности.
Это платное программное обеспечение, доступное в трех версиях: Prep Data, Create and Validate и Deploy Model. Он даже доступен бесплатно образовательным учреждениям, а RapidMiner используется более чем в 4000 университетах по всему миру.
Функции
- Он проверяет данные для выявления закономерностей и устранения проблем с качеством.
- Он использует конструктор рабочих процессов без кода с более чем 1500 алгоритмами.
- Интеграция моделей машинного обучения в существующие бизнес-приложения
Таблица
Tableau обеспечивает гибкость для визуального анализа платформ, решения проблем и расширения возможностей людей и организаций. Он основан на технологии VizQL (визуальный язык для запросов к базе данных), которая преобразует перетаскивание в запросы данных через интуитивно понятный пользовательский интерфейс.
Tableau была приобретена Salesforce в 2019 году. Она позволяет связывать данные из таких источников, как базы данных SQL, электронные таблицы или облачные приложения, такие как Google Analytics и Salesforce.
Пользователи могут приобрести его версии Creator, Explorer и Viewer в зависимости от деловых или индивидуальных предпочтений, поскольку каждая из них имеет свои характеристики и функции.
Он идеально подходит для аналитиков, специалистов по данным, образовательного сектора и бизнес-пользователей, чтобы внедрить и сбалансировать культуру, основанную на данных, и оценить ее по результатам.
Функции
- Панели мониторинга предоставляют полный обзор данных в виде визуальных элементов, объектов и текста.
- Большой выбор диаграмм данных: гистограммы, диаграммы Ганта, диаграммы, диаграммы движения и многое другое.
- Фильтрация на уровне строк для обеспечения безопасности и стабильности данных
- Его архитектура предлагает предсказуемый анализ и прогнозирование
Изучить Tableau легко.
Клаудера
Cloudera предлагает безопасную платформу для облачных вычислений и центров обработки данных для управления большими данными. Он использует аналитику данных и машинное обучение, чтобы превратить сложные данные в четкую и полезную информацию.
Cloudera предлагает решения и инструменты для частных и гибридных облаков, инженерии данных, потоков данных, хранения данных, обработки данных для специалистов по данным и многого другого.
Единая платформа и многофункциональная аналитика улучшают процесс поиска информации на основе данных. Его наука о данных обеспечивает подключение к любой системе, которую использует организация, а не только к Cloudera и Hortonworks (обе компании сотрудничают).
Специалисты по данным управляют своими собственными действиями, такими как анализ, планирование, мониторинг и уведомления по электронной почте, с помощью интерактивных рабочих листов по науке о данных. По умолчанию это платформа, соответствующая требованиям безопасности, которая позволяет специалистам по данным получать доступ к данным Hadoop и легко выполнять запросы Spark.
Платформа подходит для инженеров данных, специалистов по данным и ИТ-специалистов в различных отраслях, таких как больницы, финансовые учреждения, телекоммуникации и многие другие.
Функции
- Поддерживает все основные частные и общедоступные облака, а рабочая среда Data Science поддерживает локальное развертывание.
- Автоматизированные каналы данных преобразуют данные в пригодные для использования формы и интегрируют их с другими источниками.
- Единый рабочий процесс позволяет быстро создавать, обучать и внедрять модели.
- Безопасная среда для аутентификации, авторизации и шифрования Hadoop
Апачский улей
Apache Hive — это проект с открытым исходным кодом, разработанный на основе Apache Hadoop. Он позволяет читать, записывать и управлять большими наборами данных, доступными в различных репозиториях, и позволяет пользователям комбинировать свои собственные функции для пользовательского анализа.
Hive предназначен для традиционных задач хранения и не предназначен для задач онлайн-обработки. Его надежные пакетные кадры обеспечивают масштабируемость, производительность, масштабируемость и отказоустойчивость.
Он подходит для извлечения данных, прогнозного моделирования и индексирования документов. Не рекомендуется для запроса данных в реальном времени, так как это приводит к задержке при получении результатов.
Функции
- Поддерживает вычислительный движок MapReduce, Tez и Spark.
- Обрабатывать огромные наборы данных размером в несколько петабайт
- Очень легко кодировать по сравнению с Java
- Обеспечивает отказоустойчивость за счет хранения данных в распределенной файловой системе Apache Hadoop.
Апач Шторм
Storm — это бесплатная платформа с открытым исходным кодом, используемая для обработки неограниченных потоков данных. Он предоставляет наименьший набор процессорных блоков, используемых для разработки приложений, которые могут обрабатывать очень большие объемы данных в режиме реального времени.
Storm достаточно быстр, чтобы обрабатывать один миллион кортежей в секунду на узел, и с ним легко работать.
Apache Storm позволяет добавлять в кластер дополнительные узлы и увеличивать вычислительную мощность приложений. Вычислительную мощность можно удвоить путем добавления узлов при сохранении горизонтальной масштабируемости.
Специалисты по данным могут использовать Storm для DRPC (распределенных удаленных вызовов процедур), анализа ETL (извлечение-преобразование-загрузка) в реальном времени, непрерывных вычислений, онлайн-машинного обучения и т. д. Он настроен для удовлетворения потребностей Twitter в обработке данных в реальном времени. , Yahoo и Flipboard.
Функции
- Простота использования с любым языком программирования
- Он интегрирован в каждую систему массового обслуживания и каждую базу данных.
- Storm использует Zookeeper для управления кластерами и масштабирования до больших размеров кластеров.
- Гарантированная защита данных заменяет потерянные кортежи, если что-то пойдет не так
Снежинка Data Science
Самой большой проблемой для специалистов по данным является подготовка данных из различных ресурсов, поскольку максимальное время тратится на извлечение, консолидацию, очистку и подготовку данных. К нему обращается Снежинка.

Он предлагает единую высокопроизводительную платформу, которая устраняет проблемы и задержки, связанные с ETL (преобразование и извлечение нагрузки). Его также можно интегрировать с новейшими инструментами и библиотеками машинного обучения (ML), такими как Dask и Saturn Cloud.
Snowflake предлагает уникальную архитектуру выделенных вычислительных кластеров для каждой рабочей нагрузки для выполнения таких высокоуровневых вычислительных действий, поэтому нет совместного использования ресурсов между рабочими нагрузками по обработке данных и BI (бизнес-аналитике).
Он поддерживает типы данных из структурированных, полуструктурированных (JSON, Avro, ORC, Parquet или XML) и неструктурированных данных. Он использует стратегию озера данных для улучшения доступа к данным, производительности и безопасности.
Ученые и аналитики данных используют снежинки в различных отраслях, включая финансы, СМИ и развлечения, розничную торговлю, здравоохранение и науки о жизни, технологии и государственный сектор.
Функции
- Высокое сжатие данных для снижения затрат на хранение
- Обеспечивает шифрование данных в состоянии покоя и при передаче
- Быстродействующий движок с низкой операционной сложностью
- Интегрированное профилирование данных с представлениями таблиц, диаграмм и гистограмм
Датаробот
Datarobot — мировой лидер в области облачных вычислений с искусственным интеллектом. Его уникальная платформа предназначена для обслуживания всех отраслей, включая пользователей и различные типы данных.
Компания утверждает, что это программное обеспечение используется третью компаний из списка Fortune 50, и предоставляет более триллиона оценок в различных отраслях.
Dataroabot использует автоматизированное машинное обучение (ML) и предназначен для специалистов по корпоративным данным, чтобы они могли быстро создавать, адаптировать и развертывать точные модели прогнозов.
Это дает ученым легкий доступ ко многим новейшим алгоритмам машинного обучения с полной прозрачностью для автоматизации предварительной обработки данных. Программное обеспечение разработало специальные клиенты R и Python для ученых, чтобы решать сложные задачи обработки данных.
Это помогает автоматизировать качество данных, разработку функций и процессы внедрения, чтобы облегчить работу специалиста по обработке и анализу данных. Это премиальный продукт, и цена доступна по запросу.
Функции
- Повышает ценность бизнеса с точки зрения рентабельности, упрощает прогнозирование
- Процессы внедрения и автоматизация
- Поддерживает алгоритмы из Python, Spark, TensorFlow и других источников.
- Интеграция с API позволяет выбирать из сотен моделей
ТензорФлоу
TensorFlow — это библиотека на основе ИИ (искусственного интеллекта), которая использует диаграммы потоков данных для создания, обучения и развертывания приложений машинного обучения (ML). Это позволяет разработчикам создавать большие многоуровневые нейронные сети.
Он включает в себя три модели — TensorFlow.js, TensorFlow Lite и TensorFlow Extended (TFX). Его режим javascript используется для обучения и развертывания моделей в браузере и на Node.js одновременно. Его упрощенный режим предназначен для развертывания моделей на мобильных и встроенных устройствах, а модель TFX — для подготовки данных, проверки и развертывания моделей.
Благодаря надежной платформе его можно развернуть на серверах, периферийных устройствах или в Интернете независимо от языка программирования.
TFX содержит механизмы для реализации конвейеров машинного обучения, которые можно расширять и обеспечивать надежную общую производительность. Конвейеры обработки данных, такие как Kubeflow и Apache Airflow, поддерживают TFX.
Платформа Tensorflow подходит для начинающих. Промежуточный и для экспертов для обучения генеративно-состязательной сети для создания изображений рукописных цифр с использованием Keras.
Функции
- Может развертывать модели машинного обучения локально, в облаке и в браузере независимо от языка.
- Простое построение модели с использованием встроенных API для быстрого повторения модели
- Его различные дополнительные библиотеки и модели поддерживают исследовательскую деятельность для экспериментов.
- Простое построение модели с использованием нескольких уровней абстракции
Матплотлиб
Matplotlib — это комплексное программное обеспечение сообщества для визуализации анимированных данных и графической графики для языка программирования Python. Его уникальный дизайн структурирован таким образом, что визуальный график данных создается с помощью нескольких строк кода.
Существуют различные сторонние приложения, такие как программы для рисования, графические интерфейсы, карты цветов, анимация и многие другие, предназначенные для интеграции с Matplotlib.
Его функциональность может быть расширена с помощью многих инструментов, таких как Basemap, Cartopy, GTK-Tools, Natgrid, Seaborn и других.
Его лучшие функции включают рисование графиков и карт со структурированными и неструктурированными данными.
Бигмл
Bigml — это коллективная и прозрачная платформа для инженеров, специалистов по данным, разработчиков и аналитиков. Он выполняет сквозное преобразование данных в действенные модели.
Он эффективно создает, экспериментирует, автоматизирует рабочие процессы машинного обучения и управляет ими, способствуя созданию интеллектуальных приложений в самых разных отраслях.
Эта программируемая платформа ML (машинного обучения) помогает выполнять секвенирование, прогнозирование временных рядов, обнаружение ассоциаций, регрессию, кластерный анализ и многое другое.
Его полностью управляемая версия с одним или несколькими арендаторами и одним возможным развертыванием для любого облачного провайдера позволяет предприятиям легко предоставлять всем доступ к большим данным.
Его цена начинается с 30 долларов США, он бесплатен для небольших наборов данных и образовательных целей и используется более чем в 600 университетах.
Благодаря надежным разработанным алгоритмам машинного обучения он подходит для различных отраслей, таких как фармацевтика, развлечения, автомобилестроение, аэрокосмическая промышленность, здравоохранение, Интернет вещей и многие другие.
Функции
- Автоматизируйте трудоемкие и сложные рабочие процессы с помощью одного вызова API.
- Он может обрабатывать большие объемы данных и выполнять параллельные задачи.
- Библиотека поддерживается популярными языками программирования, такими как Python, Node.js, Ruby, Java, Swift и др.
- Его детализированные детали облегчают работу по аудиту и нормативным требованиям.
Апач Спарк
Это один из крупнейших движков с открытым исходным кодом, широко используемый крупными компаниями. По данным сайта, Spark используют 80% компаний из списка Fortune 500. Он совместим с отдельными узлами и кластерами для больших данных и машинного обучения.
Он основан на расширенном SQL (язык структурированных запросов) для поддержки больших объемов данных и работы со структурированными таблицами и неструктурированными данными.
Платформа Spark известна своей простотой использования, большим сообществом и молниеносной скоростью. Разработчики используют Spark для создания приложений и выполнения запросов на Java, Scala, Python, R и SQL.
Функции
- Обрабатывает данные как в пакетном режиме, так и в режиме реального времени.
- Поддерживает большие объемы петабайт данных без субдискретизации
- Это упрощает объединение нескольких библиотек, таких как SQL, MLib, Graphx и Stream, в единый рабочий процесс.
- Работает на Hadoop YARN, Apache Mesos, Kubernetes и даже в облаке и имеет доступ к нескольким источникам данных.
нож
Konstanz Information Miner — это интуитивно понятная платформа с открытым исходным кодом для приложений обработки данных. Специалист по данным и аналитик может создавать визуальные рабочие процессы без программирования с помощью простой функции перетаскивания.
Серверная версия представляет собой торговую платформу, используемую для автоматизации, управления наукой о данных и управленческого анализа. KNIME делает рабочие процессы обработки данных и повторно используемые компоненты доступными для всех.
Функции
- Высокая гибкость для интеграции данных с Oracle, SQL, Hive и т. д.
- Доступ к данным из нескольких источников, таких как SharePoint, Amazon Cloud, Salesforce, Twitter и т. д.
- Использование машинного обучения в форме построения модели, настройки производительности и проверки модели.
- Понимание данных в форме визуализации, статистики, обработки и отчетности
Какова важность 5 V больших данных?
5 V больших данных помогают специалистам по данным понимать и анализировать большие данные, чтобы получить больше информации. Это также помогает предоставлять больше статистических данных, полезных для предприятий, чтобы принимать обоснованные решения и получать конкурентные преимущества.
Объем: Большие данные основаны на объеме. Квантовый объем определяет, насколько велики данные. Обычно содержит большой объем данных в терабайтах, петабайтах и т. д. В зависимости от размера тома специалисты по данным планируют различные инструменты и интеграции для анализа набора данных.
Скорость: скорость сбора данных имеет решающее значение, поскольку некоторым компаниям требуется информация о данных в режиме реального времени, а другие предпочитают обрабатывать данные в пакетах. Чем быстрее поток данных, тем больше специалисты по данным могут оценить и предоставить компании актуальную информацию.
Разнообразие: данные поступают из разных источников и, что важно, не в фиксированном формате. Данные доступны в структурированном (формат базы данных), полуструктурированном (XML/RDF) и неструктурированном (двоичные данные) форматах. На основе структур данных инструменты больших данных используются для создания, организации, фильтрации и обработки данных.
Достоверность: точность данных и надежные источники определяют контекст больших данных. Набор данных поступает из различных источников, таких как компьютеры, сетевые устройства, мобильные устройства, социальные сети и т. д. Соответственно, данные должны быть проанализированы, чтобы быть отправленными по назначению.
Ценность. Наконец, сколько стоят большие данные компании? Роль специалиста по данным состоит в том, чтобы наилучшим образом использовать данные, чтобы продемонстрировать, как понимание данных может повысить ценность бизнеса.
Вывод
Приведенный выше список больших данных включает платные инструменты и инструменты с открытым исходным кодом. Краткая информация и функции предоставляются для каждого инструмента. Если вам нужна описательная информация, вы можете посетить соответствующие веб-сайты.
Компании, стремящиеся получить конкурентное преимущество, используют большие данные и связанные с ними инструменты, такие как AI (искусственный интеллект), ML (машинное обучение) и другие технологии, чтобы предпринимать тактические действия для улучшения обслуживания клиентов, исследований, маркетинга, планирования будущего и т. д.
Инструменты больших данных используются в большинстве отраслей, поскольку небольшие изменения в производительности могут привести к значительной экономии и большой прибыли. Мы надеемся, что статья выше дала вам обзор инструментов работы с большими данными и их значения.
Вам также может понравиться:
Онлайн-курсы для изучения основ Data Engineering.