
Начало работы с Google Page Speed API
Опубликовано: 2019-03-11Скорость страницы — один из важнейших показателей того, сколько времени кто-то проведет на вашем сайте. Медленная загрузка страниц может привести к более высоким показателям отказов, более низким коэффициентам конверсии и, следовательно, к снижению доходов.
Чтобы получить некоторое представление о том, может ли время загрузки влиять на удержание и конверсию вашей аудитории, отлично подходит инструмент Google Page Speed Insights. Google Page Speed API — это то, как вы можете подключиться к этим данным и включить идеи в свой стек данных. Мы использовали его для создания нашего собственного аналитического трекера Page Speed для отслеживания ключевых показателей взаимодействия с пользователем для наших клиентов.
Чем хорош Page Speed Insights API?
С помощью этого инструмента вы можете подключить URL-адрес и получить сводку о его производительности. Это отлично подходит для выборки нескольких URL-адресов, но что, если у вас большой веб-сайт и вы хотите увидеть всесторонний обзор производительности по нескольким разделам и типам страниц?
Вот здесь и приходит на помощь API. Google Page Speed Insights API дает нам возможность анализировать производительность для многих страниц и регистрировать результаты без необходимости явно запрашивать URL-адреса по одному и интерпретировать результаты вручную.
Имея это в виду, мы составили простое руководство, которое поможет вам начать использовать API для вашего собственного веб-сайта. После того, как вы ознакомитесь с описанным ниже процессом, вы увидите, как его можно использовать для анализа скорости вашего сайта в масштабе, отслеживания ее изменений с течением времени или даже для настройки инструментов мониторинга.
Это руководство предполагает некоторое знакомство со сценариями. Здесь мы используем Python для взаимодействия с API и анализа результатов.
Цели
В этом посте вы узнаете, как:
- Создайте запрос API Google Page Speed Insights
- Запросы API для таблицы URL-адресов
- Извлечение базовой информации из ответа API
- Запустите данный пример скрипта в Python
Подготовка
Перед запросом Page Speed Insights API с помощью Python необходимо выполнить несколько шагов.
- Настройка API. Для многих API Google требуются ключи API, пароли и другие меры аутентификации. Однако для начала работы с Google Page Speeds API ничего из этого не требуется!
- Установка Python 3. Если вы никогда раньше не использовали Python, мы рекомендуем начать с дистрибутива Anaconda (версия Python 3.x), который устанавливает Python вместе с популярными библиотеками анализа данных, такими как Pandas.
Выполнение запросов
Основы запроса
API можно запросить в этой конечной точке с помощью запросов GET:
GET https://www.googleapis.com/pagespeedonline/v5/runPagespeedЗатем мы добавляем дополнительные параметры, чтобы указать URL-адрес, для которого мы хотим найти скорость страницы, и тип используемого устройства, как показано ниже:
https://www.googleapis.com/pagespeedonline/v5/runPagespeed?url={url}&strategy={device_type} При отправке запросов вы должны заменить {url} URL-адресом страницы вашего веб-сайта в кодировке URL, а {device_type} мобильным или настольным, чтобы указать тип устройства.
Пакеты Python
Чтобы делать запросы, принимать их, а затем записывать результаты в таблицы, мы будем использовать несколько библиотек Python:
- urllib : для выполнения HTTP-запросов.
- json : для анализа и чтения объектов ответа.
- панды : чтобы сохранить результаты в формате CSV.
Создание запроса
Чтобы сделать запрос API с помощью Python, мы можем использовать метод urllib.request.urlopen :
import urllib.request import urllib.parse url = 'http://www.example.com' escaped_url = urllib.parse.quote(url) device_type = 'mobile' # Construct request url contents = urllib.request.urlopen( 'https://www.googleapis.com/pagespeedonline/v5/runPagespeed?url={}&strategy={}' .format(escaped_url, device_type) ).read().decode('UTF-8')Этот запрос должен возвращать (на удивление большой) ответ JSON. Вскоре мы обсудим это более подробно.
Выполнение нескольких запросов
Основным преимуществом этого API является то, что он позволяет нам контролировать скорость страниц для пакетов URL-адресов. Давайте посмотрим, как это можно сделать с помощью Python.
Один из вариантов — сохранить параметры запроса ( url и device_type ) в CSV, который мы можем загрузить в Pandas DataFrame для повторения. Обратите внимание, что каждый запрос или уникальная пара url + device_type имеет свою собственную строку.
Хранить данные в CSV
URL, device_type 0, https://www.example.com, desktop 1, https://www.example.com, mobile 2, https://www.example.com/blog, desktop 3, https://www.example.com/blog, mobileЗагрузите CSV-файл
import pandas as pd df = pd.read_csvimport pandas as pd df = pd.read_csv(url_file)
Когда у нас есть набор данных со всеми URL-адресами для запроса, мы можем перебрать их и сделать запрос API для каждой строки. Это показано ниже:
import time # This is where the responses will be stored response_object = {} # Iterating through df for i in range(0, len(df)): # Error handling try: print('Requesting row #:', i) # Define the request parameters url = df.iloc[i]['URL'] device_type = df.iloc[i]['device_type'] # Making request contents = urllib.request.urlopen( 'https://www.googleapis.com/pagespeedonline/v5/runPagespeed?url={}&strategy={}' .format(url, device_type) ).read().decode('UTF-8') # Converts to json format contents_json = json.loads(contents) # Insert returned json response into response_object response_object[device_type][url] = contents_json print('Sleeping for 20 seconds between responses.') time.sleep(20) except Exception as e: print('Error:', e) print('Returning empty response for url:', url) response_object[device_type][url] = {}Чтение ответа
Прежде чем применять какие-либо фильтры или форматирование к данным, мы можем сначала сохранить полные ответы для будущего использования следующим образом:
import json from datetime import datetime f_name ='data/{}-response.json'.format(datetime.now().strftime("%Y-%m-%d_%H:%M:%S")) with open(f_name, 'w') as outfile: json.dump(response_object, outfile, indent=4)Как упоминалось выше, каждый ответ возвращает объект JSON. У них много разных свойств, связанных с данным URL, и они слишком велики, чтобы их можно было расшифровать без фильтрации и форматирования.

Для этого мы будем использовать библиотеку Pandas, которая позволяет легко извлекать нужные данные в формате таблицы и экспортировать в CSV.
Это общая структура ответа. Данные о времени загрузки были сведены к минимуму из-за его размера.
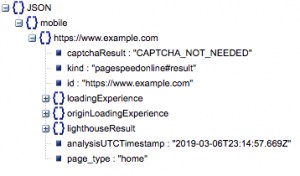
Общая структура ответа
Помимо другой информации, в ответ включены два основных источника данных о скорости страницы: лабораторные данные, хранящиеся в «lighthouseResult», и полевые данные, хранящиеся в «loadingExperience». В этом посте мы сосредоточимся только на полевых данных, которые получены из краудсорсинга на основе реальных пользователей в браузере Chrome.
В частности, мы собираемся извлечь следующие показатели:
- Запрошенный URL и конечный URL
- Нам нужны и запрошенный, и конечный разрешенный URL-адрес, которые прошли аудит, чтобы убедиться, что они совпадают. Это поможет нам определить, что результат пришел с предполагаемого URL-адреса, а не с перенаправления.
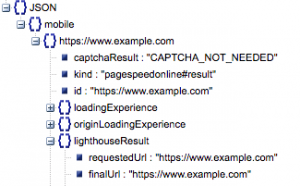
Мы можем видеть, что оба URL-адреса одинаковы в «lighthouseResult» выше.
- Первая содержательная отрисовка (мс)
- Это время между первым переходом пользователя на страницу и моментом, когда браузер впервые отображает фрагмент содержимого, сообщая пользователю о загрузке страницы.
- Этот показатель измеряется в миллисекундах.
- Первая содержательная отрисовка (пропорции медленной, средней, быстрой)
- Это показывает процент страниц с медленным, средним и быстрым временем загрузки First Contentful Paint.
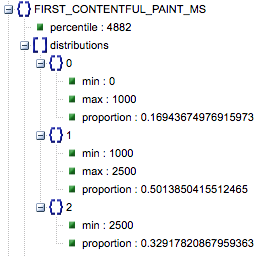
Время загрузки First Contentful Paint в миллисекундах, помеченное как «процентиль», и пропорция медленного, среднего и быстрого.
Все эти результаты могут быть извлечены как для мобильных, так и для настольных данных.
Если мы назовем наш фрейм данных Pandas df_field_responses, вот как мы извлечем эти свойства:
import pandas as pd # Specify the device_type (mobile or desktop) device_type = 'mobile' # Create dataframe to store responses df_field_responses = pd.DataFrame( columns=['requested_url', 'final_url', 'FCM_ms', 'FCP_category', 'FCP_fast', 'FCP_avg', 'FCP_slow' ] ) for (url, i) in zip( response_object[device_type].keys(), range(0, len(df_field_responses)) ): try: print('Trying to insert response for url:', url) # We reuse this below when selecting data from the response fcp_loading = response_object[device_type][url] ['loadingExperience']['metrics']['FIRST_CONTENTFUL_PAINT_MS'] # URLs df_field_responses.loc[i, 'requested_url'] = response_object[device_type][url]['lighthouseResult']['requestedUrl'] df_field_responses.loc[i, 'final_url'] = response_object[device_type][url]['lighthouseResult']['finalUrl'] # Loading experience: First Contentful Paint (ms) df_field_responses.loc[i, 'FCP_ms'] = fcp_loading['percentile'] df_field_responses.loc[i, 'FCP_category'] = fcp_loading['category'] # Proportions: First Contentful Paint df_field_responses.loc[i, 'FCP_fast'] = fcp_loading['distributions'][0]['proportion'] df_field_responses.loc[i, 'FCP_avg'] = fcp_loading['distributions'][1]['proportion'] df_field_responses.loc[i, 'FCP_slow'] = fcp_loading['distributions'][2]['proportion'] print('Inserted for row {}: {}'.format(i, df_field_responses.loc[i])) except Exception as e: print('Error:', e) print('Filling row with Error for row: {}; url: {}'.format(i, url)) # Fill in 'Error' for row if a field couldn't be found df_field_responses.loc[i] = ['Error' for i in range(0, len(df_field_responses.columns))]Затем, чтобы сохранить кадр данных df_field_responses в CSV:
df_field_responses.to_csv('page_speeds_filtered_responses.csv', index=False)Запуск скриптов на GitHub
Репозиторий на GitHub содержит инструкции по запуску файлов, но вот краткое описание.
- Перед запуском примеров скриптов на GitHub вам необходимо клонировать репозиторий, используя
-
git clone https://github.com/Ayima/page-speed-blog-post.git
-
- Затем создайте CSV-файл с URL-адресами для запроса.
- Заполните файл конфигурации именем файла URL.
- Команда для запуска скриптов:
python main.py --config-file config.jsonЧто нужно иметь в виду:
API имеет ограничение на количество запросов, которые вы можете делать в день и в секунду.
Есть несколько способов подготовиться к этому, в том числе:
- Обработка ошибок: повторные запросы, которые возвращают ошибку
- Регулирование: в вашем сценарии для ограничения количества запросов, отправляемых в секунду, и повторного запроса в случае сбоя URL-адреса.
- При необходимости получите ключ API (обычно, если вы делаете более одного запроса в секунду).
Надеемся, что после прочтения этого руководства вы сможете приступить к работе с некоторыми базовыми запросами API Google Page Speed Insights. Не стесняйтесь обращаться к нам в твиттере @ayima с любыми вопросами или если у вас возникнут какие-либо проблемы!
Как мы используем Page Speeds API в Ayima
Здесь, в Ayima, мы постоянно собираем и храним информацию о скорости страниц для клиентов. Это помогает нам следить за состоянием их веб-сайтов и выявлять отрицательные или положительные тенденции. Отслеживая скорость для различных страниц, мы можем визуализировать производительность по разделам сайта или типам страниц (например, страницы продуктов и страницы категорий для веб-сайтов электронной коммерции).
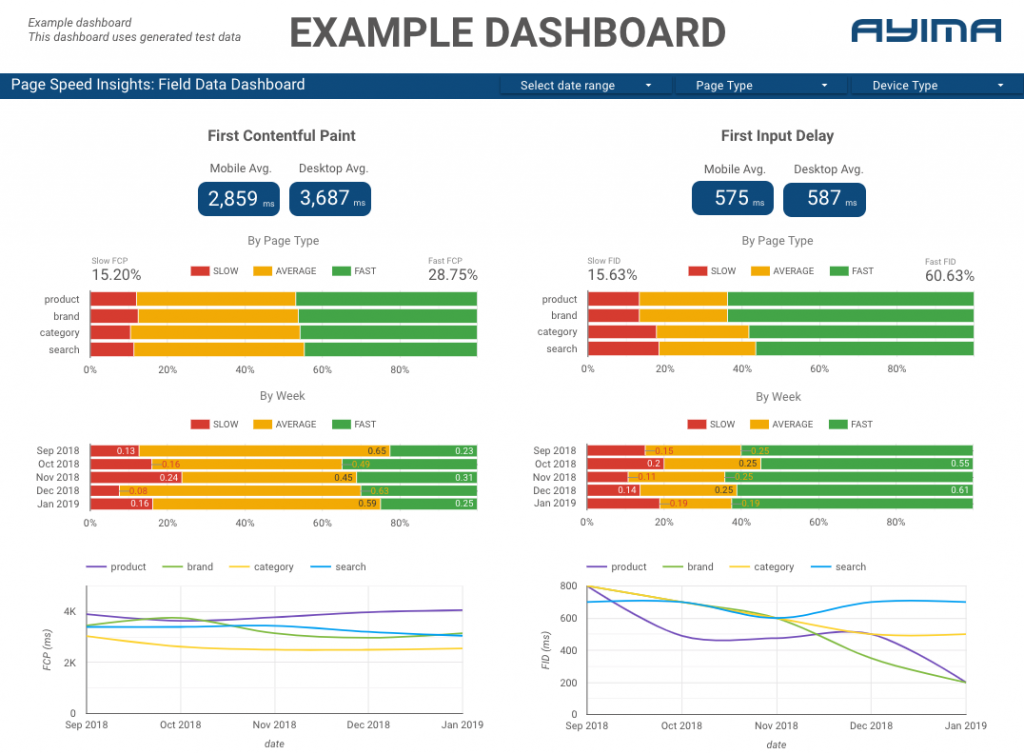
Мы также отслеживаем другие интересные показатели, предоставляемые API, в том числе данные Google Lab, и представляем все это на интерактивной панели. Для получения дополнительной информации об этом, пожалуйста, свяжитесь с нами, мы будем рады пообщаться с вами!
Исходный код: вы можете найти проект GitHub с примером скрипта для запуска здесь.