
Google помогает идентифицировать семантические сущности в аудио
Опубликовано: 2020-02-11Автоматический помощник всегда прислушивается к семантическим объектам
Я слежу за публикациями Google о сущностях в поиске, в патентах или статьях, или даже в твитах.
Новая патентная заявка касается того, с чем могут быть знакомы многие люди с телефонами Android, но, возможно, не слышали об этом ничего официального от Google.
Иногда я участвую в подкастах и видеоконференциях, где обсуждаю SEO с другими, и эти разговоры часто включают упоминания Google. Иногда эти упоминания заставляют телефон отвечать и отвечать на вопросы.
Я также недавно получил новый телефон Android, использующий операционную систему Android 10, и он определяет песни, играющие в фоновом режиме, будь то по телевизору, радио или на моем компьютере, и определит, от кого эта песня, и имя песня.
Интересно видеть эту идентификацию песни, и это полезно. Но это также вызывает такие вопросы, как: «Этот телефон всегда все слушает?» (Спойлер: «Всегда включен».)
Идентификация семантических сущностей в аудио
Представьте, что вы разговариваете с кем-то по телефону или слушаете телепередачу, радиостанцию или подкаст, и в нем упоминается человек или место, или книга, или фильм. И ваш телефон слышит это упоминание и записывает его, чтобы вы могли получить дополнительную информацию об упомянутом человеке, месте или предмете.
Именно об этом и идет речь в новой заявке на патент - идентификации семантических сущностей, упомянутых в аудио, которые вы можете слышать, и предоставлении вам дополнительной информации об этих сущностях.
Заявка на патент начинается с того, что сообщает нам:
Настоящее раскрытие в целом относится к системам и способам идентификации семантических объектов в аудиосигналах.
Более подробно, в нем говорится, что он будет использовать подход, который использует машинное обучение для идентификации семантических сущностей в аудиосигналах, которые слышит пользователь, для отображения этих семантических сущностей пользователю и для предоставления пользователю дополнительной информации об этих семантических объектах. сущности. Эти сущности больше, чем просто люди, говорящие посредством звуковых сигналов.
Google знает, что мы слышим множество разных типов звуков из разных источников на наших телефонах (по крайней мере, я это делаю).
Например, человек может слушать музыку и фильмы, хранящиеся локально, на своих смартфонах; потоковая передача фильмов, музыки, телешоу, подкастов и другого контента из множества дополнительных услуг и услуг на основе подписки; доступ к мультимедийному контенту, доступному в Интернете; и Т. Д.
И люди тоже используют телефоны для общения друг с другом.
Они могут даже использовать свои телефоны для оказания переводческих услуг.
Этот патент определяет проблему, которую он должен был решить, сообщая нам:
Таким образом, люди могут услышать об определенных интересующих темах, используя свои мобильные вычислительные устройства в различных средах и ситуациях.
Однако, хотя конкретная тема может кого-то заинтересовать, часто человек может быть не в состоянии прервать выполняемую задачу, чтобы найти дополнительную информацию по конкретной теме.
Таким образом, Google намерен прислушиваться к нашим разговорам и к тому, что мы слушаем, чтобы помочь нам, предоставив больше информации о том, что мы слышим.
И это, похоже, начинается с возможности идентифицировать семантические сущности в аудиосигналах, которые он может слышать. Другими словами, объекты, которые упоминаются в этих аудиосигналах.
Эту патентную заявку можно найти по адресу:
Системы и методы идентификации и предоставления информации о семантических объектах в аудиосигналах
Номер публикации WO2020027771
Изобретатели: Тим Уантленд и Брэндон Барбелло.
Дата публикации 6 февраля 2020 г.
Претенденты: Google LLC.
Абстрактный
Предоставляются системы и методы для определения идентифицирующих семантических сущностей в аудиосигналах. Способ может включать получение с помощью вычислительного устройства, содержащего один или несколько процессоров и одно или несколько устройств памяти, аудиосигнала, одновременно слышимого пользователем. Способ может дополнительно включать в себя анализ с помощью модели машинного обучения, хранящейся на вычислительном устройстве, по меньшей мере, части аудиосигнала в фоновом режиме вычислительного устройства для определения одного или нескольких семантических объектов. Способ может дополнительно включать отображение одного или нескольких семантических объектов на экране дисплея вычислительного устройства.
Информация о семантических объектах в аудио
Процесс, описанный в патенте, начинается с сообщения нам, что он находится в «постоянно включенном рабочем режиме», чтобы позволить ему «идентифицировать семантические объекты, которые пользователь слышит из различных аудиосигналов», таких как:
- Воспроизведение медиафайлов на вычислительном устройстве
- Личные разговоры или другой звук, который пользователь подслушивает в своем окружении.
- Телефонные разговоры
- И Т. Д.
Эти разговоры могут быть не только о том, кого слушают, но также могут касаться упомянутых семантических сущностей. Как сказано в патенте, этот подход может предоставить дополнительную информацию о семантических объектах, упомянутых в аудио (относительно людей, мест и вещей):
- Человек, слушающий подкаст на своем смартфоне, может быть заинтересован в том, чтобы узнать больше о конкретном писателе, обсуждаемом в подкасте.
- Человек, разговаривающий с гидом, говорящим на иностранном языке, может быть заинтересован в получении дополнительной информации о конкретной туристической достопримечательности, обсуждаемой гидом.
- Человеку, который разговаривает по телефону с другом, может быть любопытно узнать, что находится в меню ресторана, рекомендованного его другом.
Предоставление дополнительной информации о семантических объектах
В дополнение к идентификации семантических объектов (например, людей, мест, местоположений и т. Д.) В звуковом сигнале, слышимом пользователем, устройство может также отображать эти семантические объекты пользователю с пользовательским интерфейсом, отображаемым на вычислительном устройстве.
Затем этот пользователь может также выбрать этот конкретный семантический объект, используя пользовательский интерфейс для доступа к дополнительной информации о выбранном семантическом объекте.

Машинное обучение в этом аудио процессе
В патенте говорится, что он может использовать модель машинного обучения, хранящуюся на вычислительном устройстве, для анализа аудиосигнала с целью определения одной или нескольких семантических сущностей.
Одним из примеров является использование модели машинного обучения распознавания речи, которая была обучена распознавать различных людей, места, вещи, даты / время, события или другие семантические объекты в аудиосигналах, которые включают речь.
Когда в этом патенте говорится, что этот процесс может выполняться «в фоновом режиме», это означает, что анализ аудиосигнала на вычислительном устройстве может выполняться одновременно с другой задачей, выполняемой на вычислительном устройстве, или когда вычислительное устройство находится в нерабочем состоянии.
Человек, смотрящий фильм на своем смартфоне, может анализировать звук из фильма во время просмотра фильма.
Если во время этого фильма упоминаются семантические объекты, такие как конкретные люди, места или предметы, устройство может отображать эти семантические объекты на экране дисплея устройства, используя «текст, значки, изображения и т. Д., Которые указывают на семантические объекты».
Затем пользователь может выбрать один из этих объектов, и вычислительное устройство может предоставить дополнительную дополнительную информацию о выбранном семантическом объекте.
Варианты дополнительной информации могут включать:
- Записи базы данных (например, записи веб-ссылок, записи Википедии и т. Д.)
- Результаты поисковой системы (например, результаты поиска Google и т. Д.)
- Варианты взаимодействия с приложением (например, приложения для обзора ресторанов, приложения для бронирования, приложения для покупки билетов на мероприятия и т. Д.)
Аудиосигналы можно услышать во многих приложениях
Аудиосигналы можно воспроизводить с помощью таких приложений, как:
- интернет браузер
- Музыкальный проигрыватель
- Проигрыватель фильмов
- Телефонный разговор
- Речь в текст под диктовку
Определение песен и предоставление о них дополнительной информации
Процесс, лежащий в основе этого патента, включает модель семантического идентификатора объекта распознавания песни, обученную распознавать песни (см. Изображение ниже для уведомления «Сейчас исполняется»).
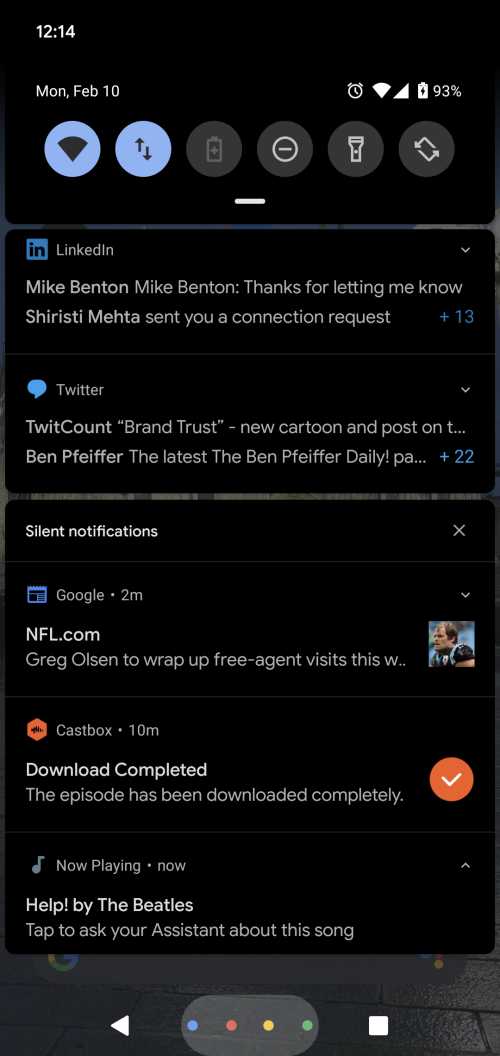
В дополнение к уведомлению внизу экрана о песне «Help» от Beatles и интерфейсу, который позволяет вам узнать, есть ли у автоматического помощника больше информации об идентифицированной семантической сущности, у Google также есть история воспроизведения:
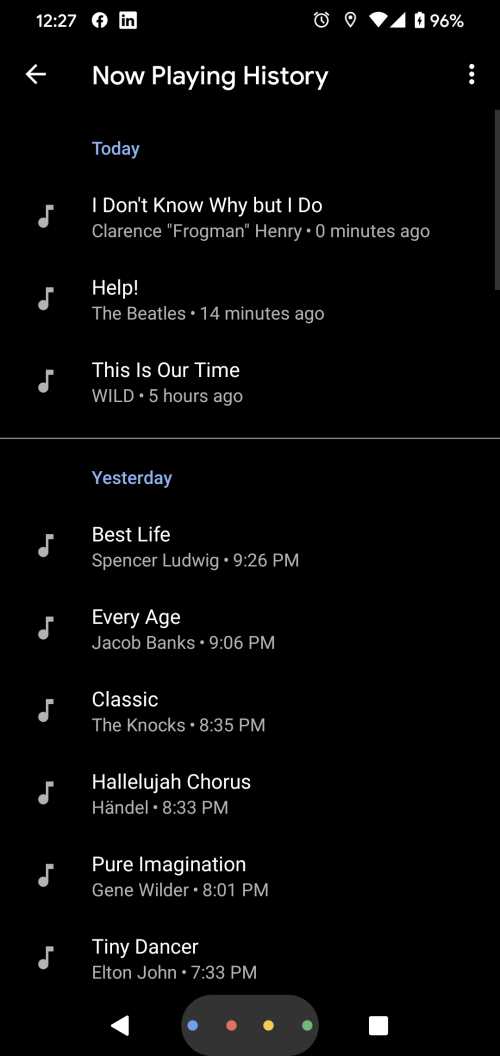
В Android уже есть приложение, которое Google анонсировало и которое похоже связано с тем, что описано в этом патенте. Эта модель машинного обучения «проигрываются песни» является дополнением к другой модели машинного обучения, которая идентифицирует семантические сущности в другом аудио, и другой модели, которая прослушивает во время переводов упоминание о семантических сущностях. Остальные части идентификации семантических сущностей пока не объявлены.
Дополнительные возможности этого процесса прослушивания семантических сущностей
Устройство, использующее этот процесс, например смартфон, будет находиться в режиме «всегда включен».
Пользователь устройства сможет отозвать или изменить согласие на прослушивание с идентифицированными объектами.
Лично идентифицируемая информация может быть защищена в рамках этого процесса.
Эта система будет обучена распознавать и / или переводить различные семантические объекты на иностранный язык.
Этот процесс может происходить во время телефонного разговора по телефону.
Можно настроить отображение объектов, когда устройство находится в заблокированном или неактивном режиме.
Семантическая сущность, идентифицированная во время звука, может быть добавлена в буфер обмена и отображена для просмотра пользователем.
Семантическая сущность может отображаться на «живой плитке» в виде значка, и может отображаться скользящий список этих сущностей.
Связанное периферийное устройство, такое как вычислительное устройство, такое как смартфон, может отображать информацию семантического объекта для аудиоустройства, такого как интеллектуальный динамик.
Семантические объекты могут быть объявлены на аудиоустройстве, таком как интеллектуальный динамик.
Семантические сущности, которые были идентифицированы, могут быть зарегистрированы и доступны позже.
Книга, упомянутая в подкасте, может включать дополнительную информацию, такую как ссылка на веб-сайт автора и возможность покупки книги, направления в ближайшую библиотеку.
Фильм, упомянутый в подкасте, может включать в себя ссылку на трейлер фильма, возможность купить билет в кино, возможность видеть расписание сеансов в ближайшем кинотеатре, направления к этому кинотеатру.
Анализ звука на фоне других запущенных приложений означает, что семантические сущности могут быть идентифицированы и представлены без прерывания других задач на устройстве.
Выводы
Модель машинного обучения для идентификации песен, описанная в этом патенте, уже работает и позволяет получить дополнительную информацию о песнях, которые вы можете услышать. Модели машинного обучения, которые прослушивают семантические сущности во время аудио и во время перевода, по-видимому, еще не реализованы. Это все еще заявка на патент, и может пройти некоторое время, прежде чем все аспекты этого патента будут реализованы.
Я вижу, что было бы полезно, если бы люди, места или вещи, упомянутые в аудио, упоминались так же, как сейчас песни, и иметь возможность увидеть больше информации об этих семантических объектах, независимо от того, упоминаются ли они в разговорах, телефонных звонках, радио или телеканалов, или в приложениях на телефоне.