
ข้อมูลการฝึกอบรมคืออะไร? ใช้อย่างไรในการเรียนรู้ของเครื่อง
เผยแพร่แล้ว: 2021-07-30โมเดลแมชชีนเลิร์นนิงดีพอๆ กับข้อมูลที่ได้รับการฝึกอบรม
ไม่มีข้อมูลการฝึกอบรมคุณภาพสูง แม้จะมีประสิทธิภาพมากที่สุด การเรียนรู้ของเครื่อง อัลกอริทึมจะล้มเหลวในการดำเนินการ
ความต้องการข้อมูลที่มีคุณภาพ ถูกต้อง ครบถ้วนและเกี่ยวข้องเริ่มต้นตั้งแต่เนิ่นๆ ในกระบวนการฝึกอบรม เฉพาะในกรณีที่อัลกอริธึมได้รับข้อมูลการฝึกที่ดีเท่านั้น จึงจะสามารถรับคุณลักษณะต่างๆ ได้อย่างง่ายดายและค้นหาความสัมพันธ์ที่จำเป็นในการทำนายผล
แม่นยำยิ่งขึ้น ข้อมูลการฝึกอบรมที่ มีคุณภาพเป็นส่วนที่สำคัญที่สุดของการเรียนรู้ของเครื่อง (และปัญญาประดิษฐ์) มากกว่าสิ่งอื่นใด หากคุณแนะนำอัลกอริธึมการเรียนรู้ของเครื่อง (ML) ให้กับข้อมูลที่ถูกต้อง แสดงว่าคุณกำลังตั้งค่าเพื่อความถูกต้องและประสบความสำเร็จ
ข้อมูลการฝึกอบรมคืออะไร?
ข้อมูลการฝึกอบรมเป็นชุดข้อมูลเริ่มต้นที่ใช้ในการฝึกอัลกอริทึมการเรียนรู้ของเครื่อง โมเดลสร้างและปรับแต่งกฎของพวกเขาโดยใช้ข้อมูลนี้ เป็นชุดของตัวอย่างข้อมูลที่ใช้เพื่อให้พอดีกับพารามิเตอร์ของโมเดลการเรียนรู้ของเครื่องเพื่อฝึกโดยใช้ตัวอย่าง
ข้อมูลการฝึกอบรมเรียกอีกอย่างว่าชุดข้อมูลการฝึกอบรม ชุดการเรียนรู้ และชุดการฝึกอบรม เป็นองค์ประกอบสำคัญของโมเดลการเรียนรู้ของเครื่องทุกรูปแบบและช่วยให้พวกเขาคาดการณ์ได้อย่างแม่นยำหรือทำงานที่ต้องการ
พูดง่ายๆ ก็คือ ข้อมูลการฝึกอบรมจะสร้างโมเดลแมชชีนเลิร์นนิง มันสอนว่าผลลัพธ์ที่คาดหวังจะเป็นอย่างไร ตัวแบบจะวิเคราะห์ชุดข้อมูลซ้ำๆ เพื่อให้เข้าใจถึงคุณลักษณะของชุดข้อมูลอย่างลึกซึ้งและปรับเปลี่ยนตัวเองเพื่อประสิทธิภาพที่ดีขึ้น
ในความหมายที่กว้างขึ้น ข้อมูลการฝึกอบรมสามารถจำแนกได้เป็นสองประเภท: ข้อมูลที่มีป้ายกำกับ และ ข้อมูลที่ไม่มีป้ายกำกับ

ข้อมูลที่มีป้ายกำกับคืออะไร?
ข้อมูลที่มีป้ายกำกับ คือกลุ่มของตัวอย่างข้อมูลที่ติดแท็กด้วยป้ายกำกับที่มีความหมายตั้งแต่หนึ่งรายการขึ้นไป ข้อมูลนี้เรียกว่าข้อมูลที่มีคำอธิบายประกอบ และป้ายกำกับระบุลักษณะเฉพาะ คุณสมบัติ การจำแนกประเภท หรือวัตถุที่มีอยู่
ตัวอย่างเช่น สามารถแท็กรูปภาพผลไม้เป็น แอปเปิ้ล กล้วย หรือ องุ่น
ใช้ข้อมูลการฝึกที่มีป้ายกำกับใน การเรียนรู้ภายใต้การดูแล ช่วยให้โมเดล ML สามารถเรียนรู้คุณลักษณะที่เกี่ยวข้องกับป้ายชื่อเฉพาะ ซึ่งสามารถใช้เพื่อจำแนกจุดข้อมูลที่ใหม่กว่า ในตัวอย่างข้างต้น หมายความว่าโมเดลสามารถใช้ข้อมูลรูปภาพที่มีป้ายกำกับเพื่อทำความเข้าใจคุณสมบัติของผลไม้ที่เฉพาะเจาะจง และใช้ข้อมูลนี้เพื่อจัดกลุ่มรูปภาพใหม่
การติดฉลากข้อมูลหรือคำอธิบายประกอบเป็นกระบวนการที่ใช้เวลานาน เนื่องจากมนุษย์จำเป็นต้องติดแท็กหรือติดป้ายกำกับจุดข้อมูล การรวบรวมข้อมูลที่มีป้ายกำกับเป็นสิ่งที่ท้าทายและมีราคาแพง การจัดเก็บข้อมูลที่มีป้ายกำกับไม่ใช่เรื่องง่ายเมื่อเปรียบเทียบกับข้อมูลที่ไม่มีป้ายกำกับ
ข้อมูลที่ไม่มีป้ายกำกับคืออะไร
ตามที่คาดไว้ ข้อมูลที่ไม่มีป้ายกำกับ เป็นสิ่งที่ตรงกันข้ามกับข้อมูลที่ติดป้ายกำกับ เป็นข้อมูลดิบหรือข้อมูลที่ไม่ได้ติดแท็กด้วยป้ายกำกับใดๆ เพื่อระบุการจัดประเภท ลักษณะ หรือคุณสมบัติ ใช้ใน การเรียนรู้ของเครื่องโดยไม่ได้รับการดูแล และโมเดล ML ต้องหารูปแบบหรือความคล้ายคลึงกันในข้อมูลเพื่อให้ได้ข้อสรุป
ย้อนกลับไปที่ตัวอย่างก่อนหน้าของ apples , bananas และ grapes ในข้อมูลการฝึกที่ไม่มีป้ายกำกับ รูปภาพของผลไม้เหล่านั้นจะไม่ติดป้ายกำกับ ตัวแบบจะต้องประเมินแต่ละภาพโดยดูจากลักษณะเฉพาะ เช่น สีและรูปร่าง
หลังจากวิเคราะห์รูปภาพจำนวนมากแล้ว นางแบบจะสามารถแยกรูปภาพใหม่ (ข้อมูลใหม่) ออกเป็นประเภทผลไม้ของ แอปเปิ้ล กล้วย หรือ องุ่น ได้ แน่นอนว่านางแบบไม่รู้ว่าผลไม้นั้นเรียกว่าแอปเปิ้ล แต่รู้ลักษณะเฉพาะที่จำเป็นในการระบุตัวตน
มีโมเดลไฮบริดที่ใช้แมชชีนเลิร์นนิงภายใต้การดูแลและไม่ได้ดูแลร่วมกัน
วิธีการใช้ข้อมูลการฝึกอบรมในการเรียนรู้ของเครื่อง
อัลกอริธึมการเขียนโปรแกรมแบบดั้งเดิมต่างจากอัลกอริธึมการเรียนรู้ของเครื่อง โดยทำตามชุดคำสั่งเพื่อยอมรับข้อมูลอินพุตและจัดเตรียมเอาต์พุต พวกเขาไม่พึ่งพาข้อมูลในอดีต และทุกการกระทำที่พวกเขาทำนั้นอิงตามกฎ นอกจากนี้ยังหมายความว่าจะไม่ปรับปรุงเมื่อเวลาผ่านไป ซึ่งไม่ใช่กรณีของการเรียนรู้ของเครื่อง
สำหรับโมเดลแมชชีนเลิร์นนิง ข้อมูลในอดีตคืออาหารสัตว์ เช่นเดียวกับที่มนุษย์อาศัยประสบการณ์ในอดีตในการตัดสินใจที่ดีขึ้น โมเดล ML จะดูชุดข้อมูลการฝึกอบรมด้วยการสังเกตในอดีตเพื่อคาดการณ์
การคาดคะเนอาจรวมถึงการจำแนกภาพในกรณีของ การจดจำภาพหรือการเข้าใจบริบทของประโยคในการประมวลผลภาษาธรรมชาติ (NLP)
คิดว่านักวิทยาศาสตร์ข้อมูลเป็นครู อัลกอริทึมการเรียนรู้ของเครื่องเป็นนักเรียน และชุดข้อมูลการฝึกอบรมเป็นชุดของหนังสือเรียนทั้งหมด
ความทะเยอทะยานของครูคือการที่นักเรียนต้องทำข้อสอบได้ดีและในโลกแห่งความเป็นจริงด้วย ในกรณีของอัลกอริทึม ML การทดสอบก็เหมือนการสอบ หนังสือเรียน (ชุดข้อมูลการฝึกอบรม) มีตัวอย่างหลายประเภทของคำถามที่จะถูกถามในข้อสอบ
เคล็ดลับ: ตรวจสอบการวิเคราะห์ข้อมูลขนาดใหญ่ เพื่อให้ทราบว่าข้อมูลขนาดใหญ่ถูกรวบรวม จัดโครงสร้าง ทำความสะอาด และวิเคราะห์อย่างไร
แน่นอนว่าจะไม่มีตัวอย่างคำถามทั้งหมดที่จะถูกถามในข้อสอบ และจะไม่มีตัวอย่างทั้งหมดที่รวมอยู่ในตำราเรียนในการสอบด้วย หนังสือเรียนสามารถช่วยเตรียมนักเรียนโดยสอนสิ่งที่คาดหวังและจะตอบสนองอย่างไร
ไม่มีตำราเรียนใดที่จะสมบูรณ์ได้ เมื่อเวลาผ่านไป ประเภทของคำถามที่ถามจะเปลี่ยนไป ดังนั้น ข้อมูลในหนังสือเรียนจึงต้องมีการเปลี่ยนแปลง ในกรณีของอัลกอริธึม ML ชุดการฝึกควรได้รับการอัปเดตเป็นระยะเพื่อรวมข้อมูลใหม่
กล่าวโดยสรุป ข้อมูลการฝึกอบรมเป็นตำราที่ช่วยให้นักวิทยาศาสตร์ด้านข้อมูลสามารถให้แนวคิดเกี่ยวกับอัลกอริธึม ML เกี่ยวกับสิ่งที่คาดหวังได้ แม้ว่าชุดข้อมูลการฝึกอบรมจะไม่มีตัวอย่างที่เป็นไปได้ทั้งหมด แต่จะทำให้อัลกอริทึมสามารถคาดการณ์ได้
ข้อมูลการฝึกอบรมเทียบกับข้อมูลการทดสอบกับข้อมูลการตรวจสอบ
ข้อมูลการฝึก ใช้ในการฝึกแบบจำลอง หรือกล่าวอีกนัยหนึ่ง เป็นข้อมูลที่ใช้เพื่อให้พอดีกับแบบจำลอง ในทางตรงกันข้าม ข้อมูลการทดสอบ ถูกใช้เพื่อประเมินประสิทธิภาพหรือความแม่นยำของแบบจำลอง เป็นตัวอย่างข้อมูลที่ใช้ในการประเมินแบบจำลองสุดท้ายที่เป็นกลางซึ่งเหมาะสมกับข้อมูลการฝึกอบรม
ชุดข้อมูลการฝึกอบรมเป็นชุดข้อมูลเริ่มต้นที่สอนแบบจำลอง ML เพื่อระบุรูปแบบที่ต้องการหรือทำงานเฉพาะ ชุดข้อมูลการทดสอบใช้เพื่อประเมินว่าการฝึกอบรมมีประสิทธิภาพเพียงใดหรือแบบจำลองมีความแม่นยำเพียงใด
เมื่ออัลกอริธึม ML ได้รับการฝึกฝนในชุดข้อมูลใดชุดหนึ่ง และหากคุณทดสอบกับชุดข้อมูลเดียวกัน ก็มีแนวโน้มว่าจะมีความแม่นยำสูงขึ้นเนื่องจากตัวแบบรู้ว่าจะเกิดอะไรขึ้น หากชุดข้อมูลการฝึกอบรมมีค่าที่เป็นไปได้ทั้งหมดที่แบบจำลองอาจพบในอนาคต ทั้งหมดก็ดีและดี
แต่นั่นไม่เคยเป็นอย่างนั้น ชุดข้อมูลการฝึกอบรมไม่สามารถครอบคลุมได้ทั้งหมด และไม่สามารถสอนทุกอย่างที่แบบจำลองอาจพบในโลกแห่งความเป็นจริง ดังนั้นชุดข้อมูลทดสอบที่มีจุดข้อมูลที่ มองไม่เห็น จึงถูกใช้เพื่อประเมินความถูกต้องของแบบจำลอง
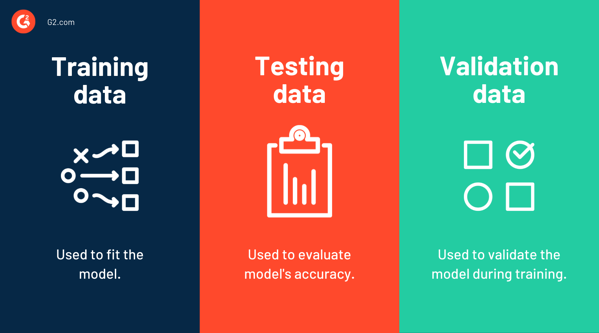
แล้วมี ข้อมูลการตรวจสอบ นี่คือชุดข้อมูลที่ใช้สำหรับการประเมินบ่อยครั้งในระหว่างขั้นตอนการฝึกอบรม แม้ว่าโมเดลจะเห็นชุดข้อมูลนี้เป็นครั้งคราว แต่ก็ไม่ได้ เรียนรู้ จากมัน ชุดตรวจสอบยังเรียกว่าชุดการพัฒนาหรือชุดพัฒนา ช่วยปกป้องนางแบบจากการใส่มากเกินไปและใส่น้อยเกินไป
แม้ว่าข้อมูลการตรวจสอบจะแยกจากข้อมูลการฝึกอบรม แต่นักวิทยาศาสตร์ด้านข้อมูลอาจสงวนส่วนหนึ่งของข้อมูลการฝึกอบรมไว้เพื่อตรวจสอบความถูกต้อง แต่แน่นอนว่านี่หมายความว่าข้อมูลการตรวจสอบความถูกต้องถูกเก็บออกไปในระหว่างการฝึกอบรมโดยอัตโนมัติ
เคล็ดลับ: หากคุณมีข้อมูลจำนวนจำกัด คุณสามารถใช้เทคนิคที่เรียกว่าการตรวจสอบข้ามเพื่อประเมินประสิทธิภาพของแบบจำลองได้ วิธีนี้เกี่ยวข้องกับการแบ่งพาร์ติชั่นข้อมูลการฝึกออกเป็นหลายๆ ชุด และสำรองไว้สำหรับการประเมิน
หลายคนใช้คำว่า "ข้อมูลทดสอบ" และ "ข้อมูลการตรวจสอบ" สลับกันได้ ข้อแตกต่างที่สำคัญระหว่างทั้งสองคือ ข้อมูลการตรวจสอบความถูกต้องจะใช้เพื่อตรวจสอบความถูกต้องของแบบจำลองระหว่างการฝึกอบรม ในขณะที่ชุดการทดสอบจะใช้เพื่อทดสอบแบบจำลองหลังจากการฝึกอบรมเสร็จสิ้น

ชุดข้อมูลการตรวจสอบความถูกต้องช่วยให้โมเดลได้ลิ้มรสข้อมูลที่มองไม่เห็นเป็นครั้งแรก อย่างไรก็ตาม ไม่ใช่ว่านักวิทยาศาสตร์ด้านข้อมูลทุกคนจะทำการตรวจสอบเบื้องต้นโดยใช้ข้อมูลการตรวจสอบความถูกต้อง พวกเขาอาจข้ามส่วนนี้และไปที่ข้อมูลการทดสอบโดยตรง
มนุษย์คืออะไรในวง?
Human in the loop หมายถึง ผู้ที่เกี่ยวข้องในการรวบรวมและเตรียมข้อมูลการฝึกอบรม
ข้อมูลดิบถูกรวบรวมจากหลายแหล่ง รวมถึงอุปกรณ์ IoT แพลตฟอร์มโซเชียลมีเดีย เว็บไซต์ และคำติชมของลูกค้า เมื่อรวบรวมแล้ว บุคคลที่เกี่ยวข้องในกระบวนการจะกำหนดคุณลักษณะที่สำคัญของข้อมูลซึ่งเป็นตัวบ่งชี้ที่ดีของผลลัพธ์ที่คุณต้องการให้แบบจำลองคาดการณ์
ข้อมูลถูกจัดเตรียมโดยการทำความสะอาด การบัญชีสำหรับค่าที่หายไป การลบค่าผิดปกติ การติดแท็กจุดข้อมูล และโหลดลงในตำแหน่งที่เหมาะสมสำหรับการฝึกอัลกอริทึม ML นอกจากนี้ยังมีการตรวจสอบคุณภาพหลายรอบ อย่างที่คุณทราบ ฉลากที่ไม่ถูกต้องอาจส่งผลต่อความแม่นยำของโมเดลได้อย่างมาก
อะไรทำให้ข้อมูลการฝึกอบรมดี
ข้อมูลคุณภาพสูงแปลเป็นโมเดลการเรียนรู้ของเครื่องที่แม่นยำ
ข้อมูลคุณภาพต่ำอาจส่งผลกระทบอย่างมีนัยสำคัญต่อความถูกต้องของแบบจำลอง ซึ่งอาจนำไปสู่การสูญเสียทางการเงินอย่างรุนแรง เกือบจะเหมือนกับการให้หนังสือเรียนที่มีข้อมูลที่ไม่ถูกต้องกับนักเรียนและคาดหวังว่าพวกเขาจะเก่งในการสอบ
ต่อไปนี้เป็นลักษณะหลักสี่ประการของข้อมูลการฝึกอบรมที่มีคุณภาพ
ที่เกี่ยวข้อง
ข้อมูลจะต้องเกี่ยวข้องกับงานที่ทำอยู่ ตัวอย่างเช่น หากคุณต้องการฝึก a วิสัยทัศน์คอมพิวเตอร์ อัลกอริธึมสำหรับรถยนต์ขับเคลื่อนอัตโนมัติ คุณอาจไม่ต้องการรูปภาพผลไม้และผัก คุณจะต้องมีชุดข้อมูลการฝึกอบรมที่มีรูปถ่ายของถนน ทางเท้า คนเดินเท้า และยานพาหนะแทน
ตัวแทน
ข้อมูลการฝึกอบรม AI ต้องมีจุดข้อมูลหรือคุณสมบัติที่แอปพลิเคชันสร้างขึ้นเพื่อทำนายหรือจำแนก แน่นอนว่าชุดข้อมูลไม่สามารถเป็นแบบสัมบูรณ์ได้ แต่อย่างน้อยต้องมีแอตทริบิวต์ที่แอปพลิเคชัน AI ควรจะรับรู้
ตัวอย่างเช่น หากตัวแบบมีไว้เพื่อจดจำใบหน้าในรูปภาพ จะต้องป้อนข้อมูลที่หลากหลายซึ่งประกอบด้วยใบหน้าของผู้คนจากหลากหลายเชื้อชาติ วิธีนี้จะช่วยลดปัญหาอคติของ AI และโมเดลจะไม่ถูกกีดกันจากเชื้อชาติ เพศ หรือกลุ่มอายุใดโดยเฉพาะ
ยูนิฟอร์ม
ข้อมูลทั้งหมดควรมีแอตทริบิวต์เดียวกันและต้องมาจากแหล่งเดียวกัน
สมมติว่าโปรเจ็กต์แมชชีนเลิร์นนิงมีจุดมุ่งหมายเพื่อคาดการณ์อัตราการเลิกใช้งานโดยดูจากข้อมูลลูกค้า เพื่อสิ่งนี้ คุณจะมีฐานข้อมูลลูกค้าที่มีชื่อลูกค้า ที่อยู่ จำนวนคำสั่งซื้อ ความถี่ในการสั่งซื้อ และข้อมูลอื่นๆ ที่เกี่ยวข้อง นี่เป็นข้อมูลในอดีตและสามารถใช้เป็นข้อมูลการฝึกอบรมได้
ข้อมูลส่วนหนึ่งต้องไม่มีข้อมูลเพิ่มเติม เช่น อายุหรือเพศ ซึ่งจะทำให้ข้อมูลการฝึกไม่สมบูรณ์และแบบจำลองไม่ถูกต้อง กล่าวโดยย่อ ความสม่ำเสมอเป็นส่วนสำคัญของข้อมูลการฝึกอบรมที่มีคุณภาพ
ครอบคลุม
อีกครั้ง ข้อมูลการฝึกอบรมไม่สามารถแน่นอนได้ แต่ควรเป็นชุดข้อมูลขนาดใหญ่ที่แสดงถึงกรณีการใช้งานส่วนใหญ่ของโมเดล ข้อมูลการฝึกอบรมต้องมีตัวอย่างเพียงพอเพื่อให้โมเดลเรียนรู้ได้อย่างเหมาะสม ต้องมีตัวอย่างข้อมูลในโลกแห่งความเป็นจริง เนื่องจากจะช่วยให้โมเดลเข้าใจถึงสิ่งที่คาดหวังได้
หากคุณกำลังคิดว่าข้อมูลการฝึกเป็นค่าที่วางไว้ในแถวและคอลัมน์จำนวนมาก ขออภัย คุณคิดผิด อาจเป็นข้อมูลประเภทใดก็ได้ เช่น ข้อความ รูปภาพ เสียง หรือวิดีโอ
อะไรส่งผลต่อคุณภาพข้อมูลการฝึกอบรม?
มนุษย์เป็นสัตว์สังคมชั้นสูง แต่มีอคติบางอย่างที่เราอาจเลือกตั้งแต่ยังเป็นเด็ก และต้องการความเอาใจใส่อย่างต่อเนื่องเพื่อกำจัด แม้ว่าจะไม่เอื้ออำนวย แต่อคติดังกล่าวอาจส่งผลต่อการสร้างสรรค์ของเรา และแอปพลิเคชันการเรียนรู้ของเครื่องก็ไม่ต่างกัน
สำหรับโมเดล ML ข้อมูลการฝึกอบรมเป็นหนังสือเล่มเดียวที่พวกเขาอ่าน ประสิทธิภาพหรือความถูกต้องของหนังสือจะขึ้นอยู่กับความครอบคลุม เกี่ยวข้อง และเป็นตัวแทนของหนังสือนั้นๆ
ดังที่กล่าวไปแล้ว ปัจจัยสามประการที่ส่งผลต่อคุณภาพของข้อมูลการฝึกอบรม:
ผู้คน: ผู้ที่ฝึกโมเดลมีผลกระทบอย่างมากต่อความแม่นยำหรือประสิทธิภาพของโมเดล หากมีอคติ จะส่งผลต่อวิธีที่แท็กข้อมูลและวิธีการทำงานของโมเดล ML ในท้ายที่สุด
กระบวนการ: กระบวนการ ติดฉลากข้อมูลต้องมีการตรวจสอบการควบคุมคุณภาพอย่างเข้มงวด สิ่งนี้จะเพิ่มคุณภาพของข้อมูลการฝึกอบรมอย่างมาก
เครื่องมือ: เครื่องมือ ที่เข้ากันไม่ได้หรือล้าสมัยอาจทำให้คุณภาพของข้อมูลลดลง การใช้ซอฟต์แวร์การติดฉลากข้อมูลที่มีประสิทธิภาพสามารถลดต้นทุนและเวลาที่เกี่ยวข้องกับกระบวนการได้
จะรับข้อมูลการฝึกอบรมได้ที่ไหน
มีหลายวิธีในการรับข้อมูลการฝึกอบรม แหล่งข้อมูลที่คุณเลือกอาจแตกต่างกันไปตามขนาดของโปรเจ็กต์แมชชีนเลิร์นนิง งบประมาณ และเวลาที่มี ต่อไปนี้เป็นแหล่งข้อมูลหลักสามแหล่งสำหรับการรวบรวมข้อมูล
ข้อมูลการฝึกอบรมโอเพ่นซอร์ส
นักพัฒนา ML มือสมัครเล่นส่วนใหญ่และธุรกิจขนาดเล็กที่ไม่สามารถรวบรวมหรือติดฉลากข้อมูลได้ ต้องอาศัยข้อมูลการฝึกอบรมโอเพนซอร์ซ เป็นตัวเลือกที่ง่ายเพราะได้รวบรวมและฟรีแล้ว อย่างไรก็ตาม ส่วนใหญ่แล้ว คุณอาจจะต้องปรับแต่งหรือใส่คำอธิบายประกอบชุดข้อมูลดังกล่าวใหม่เพื่อให้เหมาะกับความต้องการในการฝึกของคุณ ImageNet, Kaggle และ Google Dataset Search เป็นตัวอย่างของชุดข้อมูลโอเพนซอร์ส
อินเทอร์เน็ตและ IoT
บริษัทขนาดกลางส่วนใหญ่รวบรวมข้อมูลโดยใช้อินเทอร์เน็ตและอุปกรณ์ IoT กล้อง เซ็นเซอร์ และอุปกรณ์อัจฉริยะอื่นๆ ช่วยรวบรวมข้อมูลดิบ ซึ่งจะถูกล้างและใส่คำอธิบายประกอบในภายหลัง วิธีการรวบรวมข้อมูลนี้จะถูกปรับให้เข้ากับความต้องการของโปรเจ็กต์แมชชีนเลิร์นนิงของคุณโดยเฉพาะ ซึ่งแตกต่างจากชุดข้อมูลโอเพนซอร์ส อย่างไรก็ตาม การทำความสะอาด การกำหนดมาตรฐาน และการติดฉลากข้อมูลเป็นกระบวนการที่สิ้นเปลืองเวลาและใช้ทรัพยากรมาก
ข้อมูลการฝึกประดิษฐ์
ตามชื่อที่แนะนำ ข้อมูลการฝึกประดิษฐ์นั้นสร้างข้อมูลเทียมโดยใช้โมเดลการเรียนรู้ของเครื่อง เรียกอีกอย่างว่าข้อมูลสังเคราะห์ และเป็นตัวเลือกที่ยอดเยี่ยมหากคุณต้องการข้อมูลการฝึกอบรมที่มีคุณภาพดีพร้อมคุณสมบัติเฉพาะสำหรับการฝึกอัลกอริทึม แน่นอนว่าวิธีนี้ต้องใช้ทรัพยากรในการคำนวณจำนวนมากและมีเวลาเหลือเฟือ
ข้อมูลการฝึกอบรมเพียงพอหรือไม่
ไม่มีคำตอบที่เจาะจงว่าข้อมูลการฝึกมีข้อมูลการฝึกเพียงพอแค่ไหน ขึ้นอยู่กับอัลกอริทึมที่คุณกำลังฝึกอบรม – ผลลัพธ์ที่คาดหวัง แอปพลิเคชัน ความซับซ้อน และปัจจัยอื่นๆ อีกมากมาย
สมมติว่าคุณต้องการฝึกตัวแยกประเภทข้อความที่จัดหมวดหมู่ประโยคตามการเกิดขึ้นของคำว่า "แมว" และ "สุนัข" และคำพ้องความหมาย เช่น "คิตตี้" "ลูกแมว" "แมวเหมียว" "ลูกสุนัข" หรือ "สุนัข" . ซึ่งอาจไม่ต้องการชุดข้อมูลขนาดใหญ่ เนื่องจากมีคำศัพท์เพียงไม่กี่คำที่จะจับคู่และจัดเรียง
แต่ถ้านี่คือตัวแยกประเภทรูปภาพที่จัดหมวดหมู่รูปภาพเป็น "แมว" และ "สุนัข" จำนวนจุดข้อมูลที่จำเป็นในชุดข้อมูลการฝึกอบรมจะเพิ่มขึ้นอย่างมาก กล่าวโดยสรุป มีหลายปัจจัยเข้ามามีบทบาทในการตัดสินใจว่าข้อมูลการฝึกใดเป็นข้อมูลการฝึกที่เพียงพอ
ปริมาณข้อมูลที่ต้องการจะเปลี่ยนไปตามอัลกอริทึมที่ใช้
สำหรับบริบท การเรียนรู้เชิงลึก ซึ่งเป็นชุดย่อยของแมชชีนเลิร์นนิง ต้องใช้จุดข้อมูลหลายล้านจุดเพื่อฝึกเครือข่ายประสาทเทียม (ANN) ในทางตรงกันข้าม อัลกอริธึมการเรียนรู้ของเครื่องต้องการจุดข้อมูลเพียงพันจุดเท่านั้น แต่แน่นอนว่านี่เป็นลักษณะทั่วไปที่ยากจะเข้าใจ เนื่องจากปริมาณข้อมูลที่ต้องการจะแตกต่างกันไปตามแอปพลิเคชัน
ยิ่งฝึกฝนโมเดลมากเท่าไหร่ก็ยิ่งแม่นยำมากขึ้นเท่านั้น ดังนั้นจึงเป็นการดีกว่าเสมอที่จะมีข้อมูลจำนวนมากเป็นข้อมูลการฝึกอบรม
ขยะเข้าขยะออก
วลี "ขยะเข้า ขยะออก" เป็นหนึ่งในวลีที่เก่าแก่และใช้มากที่สุดในวิทยาศาสตร์ข้อมูล แม้ว่าอัตราการสร้างข้อมูลจะเพิ่มขึ้นแบบทวีคูณ แต่ก็ยังคงเป็นจริง
กุญแจสำคัญคือการป้อนข้อมูลคุณภาพสูงและเป็นตัวแทนไปยังอัลกอริธึมการเรียนรู้ของเครื่อง การทำเช่นนี้สามารถเพิ่มความแม่นยำของแบบจำลองได้อย่างมาก ข้อมูลการฝึกอบรมที่มีคุณภาพดีเป็นสิ่งสำคัญสำหรับการสร้างแอปพลิเคชันการเรียนรู้ของเครื่องที่เป็นกลาง
เคยสงสัยหรือไม่ว่าคอมพิวเตอร์ที่มีสติปัญญาเหมือนมนุษย์จะมีความสามารถอะไร? คอมพิวเตอร์ที่เทียบเท่ากับความฉลาดของมนุษย์เรียกว่าปัญญาประดิษฐ์ และเรายังไม่สรุปว่ามันจะเป็นสิ่งประดิษฐ์ที่ยิ่งใหญ่ที่สุดหรืออันตรายที่สุดเท่าที่เคยมีมา