
Google 的會話式搜索查詢(前幾屆會議的上下文)
已發表: 2019-04-05如果您還記得蜂鳥更新是在 Google 15 歲生日時宣布的,他們還展示了他們如何響應會話搜索,以及如何理解查詢會話中先前查詢中的代詞。 我在一篇題為用代詞搜索:它們是什麼? 後續查詢中的共同引用
谷歌在過去幾週內獲得了一項關於搜索引擎如何理解和使用會話查詢的專利。 谷歌蜂鳥更新於 2013 年 9 月 26 日公佈。這項對話式搜索專利於 2014 年 7 月 31 日向美國專利商標局提交,它提供了有關谷歌對話式搜索如何運作的大量細節。
會話搜索基於自然語言處理,其中搜索引擎使用人們說話的方式來回答人們可能使用自然語言提出的問題。 這可能涉及已編入索引的內容,這些內容可能以一種使搜索引擎能夠理解查詢上下文的方式進行標記。 正如專利中的描述在早期告訴我們的那樣:
本規範描述了通過確定查詢引用索引庫中的一個或多個標籤、確定與索引庫中的標籤關聯的一個或多個特定會話標識符、檢索特定上下文與數據儲存庫中的特定會話標識符相關聯的數據,並基於檢索到的特定上下文數據響應查詢執行動作。
該專利告訴我們,該專利背後的流程具有創新性,因為第一個查詢可能會指代上一次會話中的某些內容,例如代詞(“巴拉克的妻子是誰?”,然後是“她的生日是什麼時候?”)或時間(“我昨天從航空公司收到的電子郵件是什麼?”)
這些查詢可能可由搜索引擎回答,因為在所有潛在答案都用上下文信息標記後,這些查詢的上下文就被理解了。
查詢標籤和回答會話搜索查詢
要了解該專利背後的過程中發生了什麼,有助於理解專利中提到的“標籤”的含義。 我喜歡將標籤分解為會話標籤或項目標籤。 請記住,標籤與會話查詢相關聯,並有助於這些查詢的答案的上下文:
在一些示例中,一個或多個標籤包括會話標籤或項目標籤中的至少一個。 會話標籤可以與關於特定標識符的特定對應用戶會話的信息相關聯。 項目標籤可以與特定對應用戶會話中的特定查詢或響應於特定查詢的特定搜索結果中的至少一個相關聯。 會話搜索系統可以確定特定查詢或特定搜索結果中的至少一個涉及對應於項目標籤的特定項目並且基於所確定的特定項目響應於第一查詢而動作。 在一些情況下,在確定第一查詢引用第一存儲庫中的一個或多個標籤之前,會話搜索系統可以確定第一查詢缺少執行動作所需的附加信息並且第一查詢不與針對以下內容的先前查詢相關聯。第一個用戶會話。
從以前的會話中查看上下文的優點
我喜歡那些提供了遵循這些專利中描述的過程的優點列表的專利,而這個給了我們這樣一個列表。 以下是谷歌遵循這一專利流程的好處:
- 會話搜索系統可以通過快速無縫地檢索和使用先前會話搜索中的上下文數據到當前會話搜索中,使會話搜索更智能、更自然
- 會話搜索系統可以根據用戶記住的很少、有限或部分信息來確定相關的先前搜索,從而最大限度地減少用戶輸入並幫助用戶進行搜索
- 對話搜索系統可以有效地提供快速響應,例如,通過將短對話會話與會話標籤(例如,時間標籤、用戶位置標籤、用戶動作標籤和/或共存信息標籤)和/或項目標籤相關聯。索引庫,並根據標籤對應的查詢段在索引庫中搜索相關會話會話,而不是搜索所有以前的查詢和答案,這可能會導致檢索時出現大量虛假匹配。
我也喜歡專利在專利所涉及的過程中描述實體的使用,這也包括在內,並且通過展示對話範圍的示例查詢提供對過程如何工作的更多見解:
索引庫可以由實體註釋作為關鍵字,例如,“我今天早上在談論什麼書?” 用戶可能一直在使用書名,而在之前的查詢中從未提到過“書”這個詞,會話搜索系統可能會根據實體註釋來確定“書”這個詞。 索引庫也可以由實體的屬性(例如,餐館的地址)和實體的其他元數據(例如,餐館的顧客評級)作為關鍵字。 第四,會話搜索系統可以實現高精度和可靠性,例如,通過基於存儲數百萬個項目和相關項目標籤的註釋數據庫確定諸如實體的項目的項目標籤。 第五,會話搜索系統可以擴展到除英語之外的任何合適的語言。
涵蓋會話搜索查詢以及在應用自然語言處理來回答這些查詢時使用標籤的專利是:
從以前的會話中檢索上下文
發明人:Ajay Joshi
受讓人:谷歌有限責任公司
美國專利:10,235,413
授予時間:2019 年 3 月 19 日
提交日期:2014 年 7 月 31 日

抽象的
方法、系統和裝置,包括編碼在計算機存儲介質上的計算機程序,用於在會話搜索中檢索和使用來自先前會話會話的上下文數據。 在一個方面,一種方法包括接收對第一用戶會話的第一查詢,確定第一查詢涉及第一儲存庫中的一個或多個標籤,第一儲存庫將相應標識符與相應標籤相關聯,每個標識符代表相應的用戶會話,確定與第一儲存庫中的一個或多個標籤相關聯的一個或多個特定標識符,在第二儲存庫中檢索與所確定的特定標識符相關聯的特定上下文數據,第二儲存庫將相應標識符與與所表示的相應用戶會話相關聯的相應上下文數據相關聯通過相應的標識符,並基於檢索到的特定上下文數據響應第一查詢而動作。
該專利告訴我們更多有關何時標記內容的信息,這對於能夠回答對話式搜索查詢至關重要:
搜索引擎能夠在對話搜索中檢索和使用與先前用戶會話相關聯的上下文數據。 搜索引擎使用索引存儲庫中的關聯標籤存儲和索引先前的用戶會話。 當在新的會話搜索中接收到查詢時,搜索引擎確定查詢引用索引庫中的一個或多個標籤,例如時間標籤,然後確定用標籤索引的一個或多個先前會話。 搜索引擎然後例如在數據儲存庫中檢索與所確定的先前會話相關聯的上下文數據,並且基於所檢索的上下文數據響應於查詢而動作。
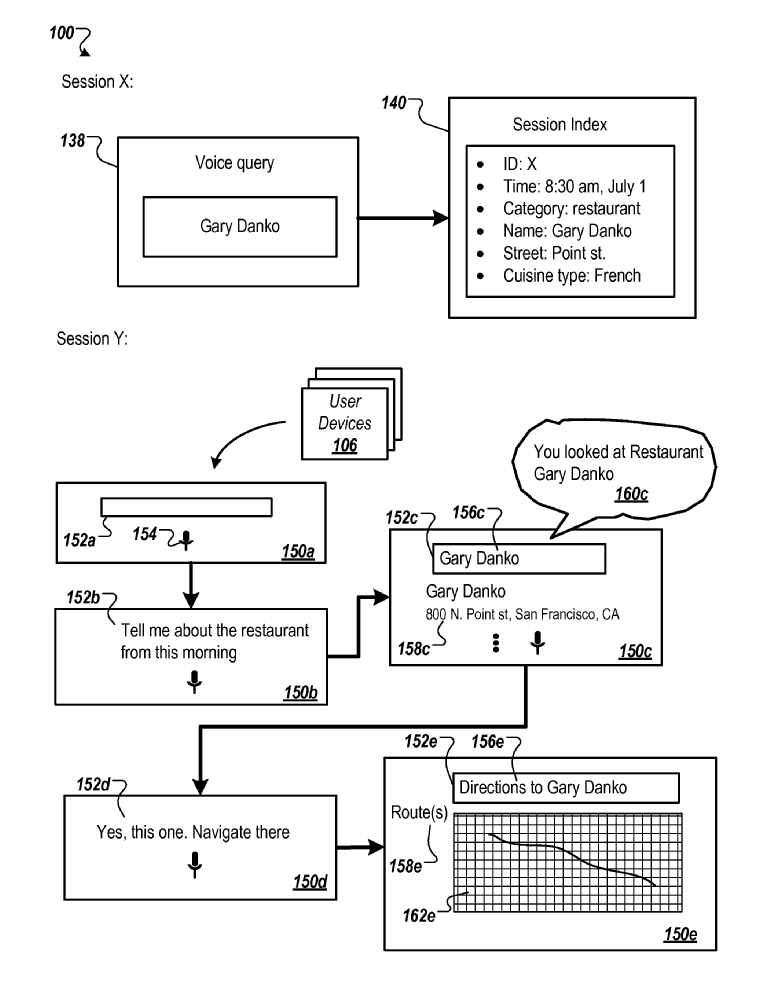
該專利中的這張圖片提供了一些有關谷歌會話搜索的信息,以及可能與這些查詢相關的不同類型的操作:
更多關於會話搜索
我對這項專利的撰寫來自專利說明書中的專利摘要。 如果您想了解所有部分是如何協同工作的,那麼說明中有一部分標記為“詳細說明”,它會更深入和詳細地介紹。 例如:
在一些實施方式中,數據與來自搜索請求的標識符相關聯,從而可以訪問每個標識符的搜索歷史。 因此,搜索引擎可以使用選擇日誌和查詢日誌來確定用戶設備提交的查詢的相應序列、響應於查詢所採取的動作以及查詢被提交的頻率。
我們確實在本專利中看到了對前面提到的實體的引用,以及何時可以用代詞來引用它們:
在一些示例中,搜索引擎通過確定查詢或響應於該查詢的搜索結果是否包括對先前查詢的顯式或隱式引用來確定查詢是否與先前查詢相關聯。 在特定示例中,如果先前查詢涉及實體並且該查詢包括該實體的對應代詞,則搜索引擎確定該查詢與先前查詢相關聯。 在另一特定示例中,例如,使用如下文進一步描述的模板,如果查詢具有與先前查詢相同的意圖,則搜索引擎確定該查詢與先前查詢相關聯。
關於標籤和實體的更多細節也出現在專利的其餘部分:
註釋數據庫將每個項目與一個或多個項目標籤、標籤或註釋相關聯。 物品標籤可以與物品的屬性或特性相關聯。 例如,如果項目指的是一個人,例如“Lady Gaga”,則與該人相關聯的項目標籤可以包括職業標籤,例如“音樂藝術家”、“作曲家”和/或“流行歌手”,國籍標籤,例如“美國”,或性別標籤,“女性”。 如果項目涉及一本書,例如“富爸爸窮爸爸”,則與該書相關聯的項目標籤可以包括類別標籤,例如“書”,作者標籤,例如“Robert T. Kiyosaki”,或發布者標籤,例如“Plata Publishing”。 如果項目涉及餐廳,例如“Gary Danko”,則與餐廳相關聯的項目標籤可以包括類別標籤“餐廳”、街道標籤例如“Point Street”、城市標籤例如“舊金山”或美食類型標籤,例如“法國菜”。
添加於 2019 年 12 月 13 日。 Google 已獲得另一項關於其自動助手的專利,我在“Google 助手和基於上下文的自然語言處理”一文中寫道。 看到 Google 助理背後的各個部分如何組合在一起很有趣。