
Googleでの会話型検索クエリ(前のセッションのコンテキスト)
公開: 2019-04-05Googleの15歳の誕生日にHummingbirdUpdateが発表されたときのことを覚えているなら、彼らは会話検索にどのように反応しているか、クエリセッションからの以前のクエリの代名詞を理解していることも示しました。 私は彼らがそれをしていることについて、「代名詞を使った検索:彼らは何ですか?」というタイトルの投稿に書きました。 フォローアップクエリでの共参照
Googleは、検索エンジンが会話型クエリをどのように理解して使用するかについて、過去2週間以内に特許を取得しています。 GoogleでのHummingbirdUpdateは、2013年9月26日に発表されました。この会話型検索特許は2014年7月31日にUSPTOに出願され、Googleでの会話型検索の仕組みに関する多くの詳細を提供します。
会話型検索は、自然言語処理に基づいており、検索エンジンは、自然言語を使用して人々が尋ねる可能性のある質問に回答するために、人々の話し方を使用します。 これには、検索エンジンがクエリのコンテキストを理解できるようにタグ付けされている可能性のあるインデックス付きのコンテンツが含まれる場合があります。 特許の説明が早い段階で私たちに教えているように:
この仕様では、クエリがインデックスリポジトリ内の1つ以上のタグを参照していることを確認し、インデックスリポジトリ内のタグに関連付けられている特定のセッション識別子を特定し、特定のコンテキストを取得することにより、会話型検索で以前のセッションからコンテキストデータを取得して使用する方法について説明します。データリポジトリ内の特定のセッション識別子に関連付けられたデータ、および取得された特定のコンテキストデータに基づいてクエリに応答するアクションを実行します。
この特許は、この特許の背後にあるプロセスが革新的であることを示しています。最初のクエリは、代名詞(「バラクの妻は誰ですか?」の後に「彼女の誕生日はいつですか?」)や時間など、前のセッションの何かを参照する可能性があるためです。 (「昨日航空会社から受け取ったメールは何でしたか?」)
これらのクエリのコンテキストは、すべての潜在的な回答がコンテキスト情報でタグ付けされた後に理解されるため、これらのクエリは検索エンジンによって回答可能である可能性があります。
タグのクエリと会話型検索クエリへの回答
この特許の背後にあるプロセスで何が起こっているのかを理解するには、特許で言及されている「タグ」が何を意味するのかを理解するのに役立ちます。 このタグのセッションタグまたはアイテムタグへの分解が気に入りました。 タグは会話型クエリに関連付けられており、それらのクエリに対する回答のコンテキストに役立つことに注意してください。
いくつかの例では、1つまたは複数のタグは、セッションタグまたはアイテムタグのうちの少なくとも1つを含む。 セッションタグは、特定の識別子に対応する特定のユーザーセッションに関する情報に関連付けることができます。 アイテムタグは、特定の対応するユーザセッションまたは特定のクエリに応答する特定の検索結果における特定のクエリの少なくとも1つに関連付けられ得る。 会話型検索システムは、特定のクエリまたは特定の検索結果の少なくとも1つがアイテムタグに対応する特定のアイテムを参照し、決定された特定のアイテムに基づいて最初のクエリに応答して行動することを決定し得る。 場合によっては、最初のクエリが最初のリポジトリ内の1つ以上のタグを参照していると判断する前に、会話型検索システムは、最初のクエリに行動に必要な追加情報がなく、最初のクエリが前のクエリに関連付けられていないと判断することがあります。最初のユーザーセッション。
以前のセッションからコンテキストを見る利点
私は、それらの特許に記載されているプロセスに従うことの利点のリストを提供する特許を楽しんでいます、そしてこれは私たちにそのようなリストを与えます。 この特許取得済みのプロセスに従ったGoogleのメリットは次のとおりです。
- 会話型検索システムは、以前の会話型検索から現在の会話型検索にコンテキストデータをすばやくシームレスに取得して使用することにより、会話型検索をよりスマートかつ自然にすることができます。
- 会話型検索システムは、ユーザーが覚えている情報がほとんどないか、限られているか、部分的であるかに基づいて、関連する以前の検索を判別できます。これにより、ユーザー入力が最小限に抑えられ、ユーザーの検索に役立ちます。
- 会話型検索システムは、たとえば、短い会話セッションをセッションラベル(たとえば、時間ラベル、ユーザーロケーションラベル、ユーザーアクションラベル、および/または共存情報ラベル)および/またはアイテムラベルに関連付けることによって、迅速な応答を効率的に提供できます。以前のすべてのクエリと回答を検索する代わりに、インデックスリポジトリと、ラベルに対応するクエリセグメントに基づいてインデックスリポジトリ内の関連する会話セッションを検索します。これにより、取得時に大量の偽の一致が発生する可能性があります。
私はまた、特許が関与するプロセスでのエンティティの使用を説明するときに楽しんでいます。これには、プロセスがどのように機能するかについてのより多くの洞察が含まれ、会話の範囲を示すサンプルクエリが含まれています。
インデックスリポジトリは、エンティティの注釈によってキー設定される場合があります。たとえば、「今朝、どの本について話していましたか?」などです。 ユーザーは、前のクエリで「本」という単語に言及せずに本のタイトルを使用していた可能性があり、会話型検索システムは、エンティティの注釈に基づいて「本」という単語を判別する場合があります。 インデックスリポジトリは、エンティティの属性(たとえば、レストランの住所)およびエンティティの他のメタデータ(たとえば、レストランの顧客評価)によってキー設定される場合もあります。 第4に、会話型検索システムは、たとえば、数百万のアイテムと関連するアイテムラベルを格納する注釈データベースに基づいて、エンティティなどのアイテムのアイテムラベルを決定することにより、高い精度と信頼性を実現できます。 第五に、会話型検索システムは、英語以外の適切な言語に拡張できます。

会話型検索クエリと、それらのクエリに答えるために自然言語処理を適用する際のタグの使用を対象とする特許は次のとおりです。
以前のセッションからコンテキストを取得する
発明者:Ajay Joshi
譲受人:Google LLC
米国特許:10,235,413
付与:2019年3月19日
提出日:2014年7月31日
概要
会話型検索で以前の会話セッションからコンテキストデータを取得および使用するための、コンピュータ記憶媒体にエンコードされたコンピュータプログラムを含む方法、システム、および装置。 一態様では、方法は、第1のユーザセッションの第1のクエリを受信し、第1のクエリが第1のリポジトリ内の1つまたは複数のタグを参照することを決定し、第1のリポジトリがそれぞれの識別子をそれぞれのタグに関連付け、各識別子が対応するユーザセッションを表すことを含む。 、第1のリポジトリ内の1つまたは複数のタグに関連する1つまたは複数の特定の識別子を決定し、第2のリポジトリ内の決定された特定の識別子に関連する特定のコンテキストデータを検索し、第2のリポジトリは、表される対応するユーザセッションに関連するそれぞれのコンテキストデータにそれぞれの識別子を関連付ける。それぞれの識別子によって、取得された特定のコンテキストデータに基づいて最初のクエリに応答して動作します。
この特許は、コンテンツがいつタグ付けされるかについて詳しく説明しています。これは、会話型検索クエリに回答できるようにするために不可欠です。
検索エンジンを使用すると、会話型検索で以前のユーザーセッションに関連付けられたコンテキストデータを取得して使用できます。 検索エンジンは、以前のユーザーセッションを、関連付けられたタグとともにインデックスリポジトリに保存してインデックスを作成します。 新しい会話型検索でクエリを受信すると、検索エンジンは、クエリがインデックスリポジトリ内の1つ以上のタグ(たとえば、タイムタグ)を参照していると判断し、タグでインデックス付けされた1つ以上の以前のセッションを判断します。 次に、検索エンジンは、たとえばデータリポジトリ内で、決定された前のセッションに関連付けられたコンテキストデータを取得し、取得されたコンテキストデータに基づいてクエリに応答して動作します。
この特許の画像は、Googleでの会話型検索と、それらのクエリに関連する可能性のあるさまざまな種類のアクションに関する情報を提供します。
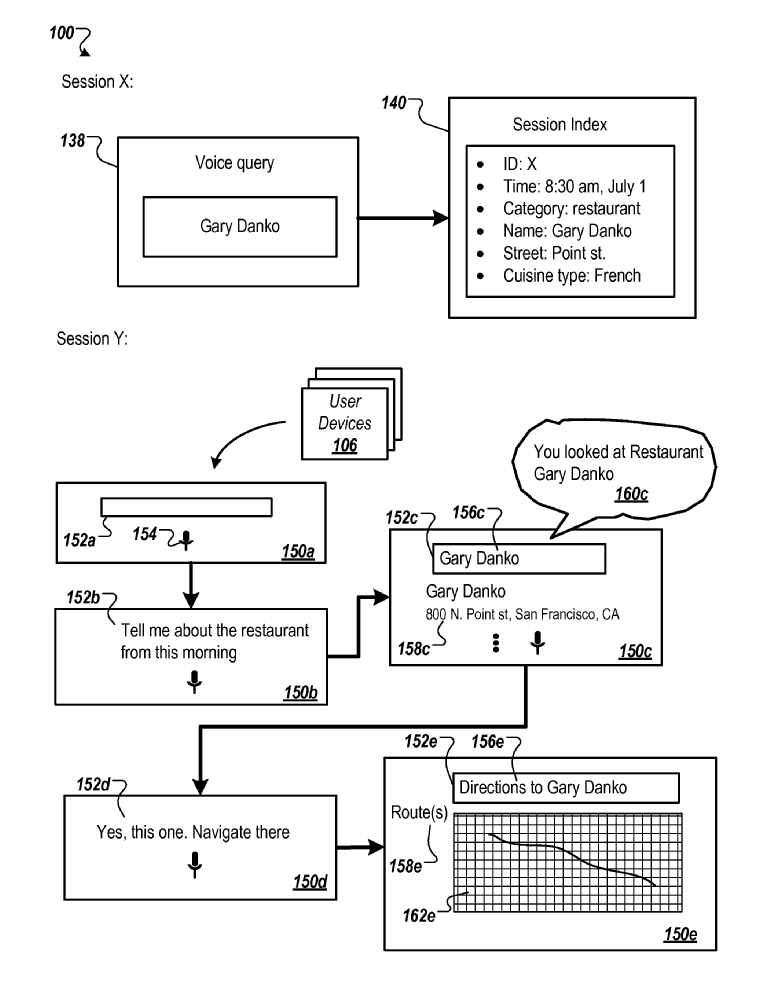
会話型検索の詳細
この特許についての私の記述は、特許の説明にある特許の要約からのものです。 「詳細な説明」というラベルの付いた説明のセクションがあります。これは、すべてのパーツがどのように連携するかを理解したい場合に、より詳細に説明します。 例えば:
一部の実装では、データは検索要求からの識別子に関連付けられているため、各識別子の検索履歴にアクセスできます。 したがって、選択ログおよびクエリログを検索エンジンで使用して、ユーザーデバイスによって送信されたクエリのそれぞれのシーケンス、クエリに応答して実行されたアクション、およびクエリが送信された頻度を判別できます。
この特許には、前述のエンティティへの参照があり、代名詞によって参照される場合があります。
いくつかの例では、検索エンジンは、クエリまたはクエリに応答する検索結果が前のクエリへの明示的または暗黙的な参照を含むかどうかを決定することによって、クエリが前のクエリに関連付けられているかどうかを決定する。 特定の例では、前のクエリがエンティティを参照していて、クエリにエンティティに対応する代名詞が含まれている場合、検索エンジンはクエリが前のクエリに関連付けられていると判断します。 別の特定の例では、検索エンジンは、クエリが前のクエリと同じ意図を持っている場合、たとえば、以下でさらに説明するテンプレートを使用して、クエリが前のクエリに関連付けられていると判断します。
タグとエンティティに関する詳細は、特許の残りの部分にも表示されます。
注釈データベースは、各アイテムを1つ以上のアイテムタグ、ラベル、または注釈に関連付けます。 アイテムタグは、アイテムの属性またはプロパティに関連付けることができます。 たとえば、アイテムが「レディーガガ」などの人物を指す場合、その人物に関連付けられたアイテムタグには、「ミュージシャン」、「作曲家」、「人気歌手」などの職業タグが含まれる場合があります。国籍タグ、たとえば「米国」、または性別タグ、「女性」。 アイテムが「金持ち父さん貧乏父さん」などの本を参照している場合、その本に関連付けられているアイテムタグには、「本」などのカテゴリタグ、「ロバートT.キヨサキ」などの著者タグ、または「PlataPublishing」などの発行者タグ。 アイテムがレストランを参照している場合、たとえば「Gary Danko」の場合、レストランに関連付けられているアイテムタグには、カテゴリタグ、「レストラン」、ストリートタグ、たとえば「ポイントストリート」、都市タグ、たとえば「サンフランシスコ」、または「フランス料理」などの料理タイプのタグ。
2019年12月13日に追加されました。Googleアシスタントとコンテキストベースの自然言語処理の投稿で私が書いた自動アシスタントについて、別の特許がGoogleに付与されました。 Googleアシスタントの背後にある要素がどのように組み合わされているかを見るのは興味深いことです。