
Google 搜索結果的個性化排名
已發表: 2020-12-02Google 如何計算搜索結果的個性化排名?
我在 2012 年在 Google 的用戶配置文件個性化和 Google Plus 一文中寫了該專利的早期版本,當時它仍然是專利申請。 這項專利已被 Google 提交了 4 次,直到我今天寫的第四個版本才被授予。
任何專利的基本部分都是權利要求部分,專利局在決定是否授予專利時會查看該部分。
該專利的第一個版本(網絡搜索的個性化)於 2003 年 9 月 30 日提交。最初由於與 Microsoft、Utopy 和 NEC USA 的專利相似而被非最終駁回。
該專利的前三個版本在專利局被谷歌放棄,看起來他們無法表明谷歌的申請與其他公司之前提交的其他專利有何不同。
它們被列為這項最新授權專利的早期版本,這是一項延續專利,採用早期版本的申請日期。 所以它被認為是該專利的更新版本。
以下是該專利申請的 3 個早期版本:
- 2003 年 9 月 30 日提交 - 網絡搜索的個性化
- 2010 年 5 月 12 日歸檔 – 使用術語、類別和基於鏈接的用戶配置文件個性化 Web 搜索結果
- 2011 年 11 月 11 日歸檔 – 使用基於術語、類別和鏈接的用戶配置文件個性化 Web 搜索結果
來自 2003 年版 Web 搜索個性化專利的第一個聲明如下:
1. 一種個性化搜索引擎的搜索結果的方法,包括: 基於關於用戶的信息訪問用戶的用戶簡檔,所述用戶信息包括從一組文檔中導出的信息,所述一組文檔包括多個文檔從由來自搜索引擎的搜索結果標識的文檔、用戶訪問的文檔、鏈接到來自搜索引擎的搜索結果標識的文檔的文檔以及鏈接到用戶訪問的文檔的文檔組成的集合中選擇;
– 接收來自用戶的搜索查詢;
– 識別與搜索查詢匹配的一組搜索結果文檔; 為至少多個搜索結果文檔中的每一個分配通用分數;
– 根據分配給文檔和用戶簡檔的通用評分,為多個搜索結果文檔中的每個文檔分配個性化評分;
– 並根據其個性化分數對搜索結果文檔集進行排名。
從 2011 年提交的專利申請的第二版開始,以下是該專利的第一項權利要求,描述了其工作原理:
2.一種計算機實現的方法,包括: 訪問用戶的用戶簡檔和用戶的組簡檔; 接收來自用戶的搜索查詢;
– 識別一組與搜索查詢匹配的通用搜索結果文檔; 為通用搜索結果文檔集的至少一個子集的每個文檔分配通用分數;
– 按照分配給文檔、用戶配置文件和組配置文件的通用評分,為搜索結果文檔子集的每個文檔分配個性化評分;
– 根據各自的個性化分數對搜索結果文檔的子集進行排名;
– 向與用戶相關聯的客戶端系統提供標識搜索結果文檔的排名子集中的多個文檔的信息;
– 以及基於用戶從多個文檔中選擇的文檔更新用戶配置文件。
以下是 2020 年 11 月授予的最近授予的專利版本中的第一項權利要求:
1.一種個性化搜索引擎搜索結果的方法,該方法包括:
– 訪問用戶的用戶簡檔,其中用戶簡檔至少部分基於關於用戶的信息,用戶簡檔包括從一組文檔導出的信息,該組文檔包括由搜索結果識別的文檔引擎、用戶訪問的文檔、鏈接到由搜索引擎的搜索結果識別的文檔的文檔以及鏈接到用戶訪問的文檔的文檔; 接收來自用戶的搜索查詢;
– 識別一組響應搜索查詢的文檔,每個文檔都與一個獨立於用戶配置文件的通用分數相關聯;
– 為所識別的文檔集的至少一個子集的每一個分配個性化分數,該個性化分數至少部分基於用戶簡檔;
– 並為所識別的一組文檔的子集中的每個文檔確定最終分數,最終分數是文檔的個性化分數、與文檔相關聯的通用分數以及一個或多個的置信度分數的函數of:獲取的關於用戶的信息量,搜索查詢與用戶資料的匹配程度,以及用戶資料的年齡;
–並且在最終得分之後向與用戶相關聯的客戶端系統提供識別所識別的文檔集的至少一個子集的結果,其中提供結果包括至少部分地基於個性化得分提供至少一個結果對應的文檔,並在與其他結果對應但獨立於用戶簡檔的文檔的通用分數下提供所獲得的搜索結果的其他結果。
搜索結果的置信度得分和個性化排名
該專利的 2020 年授權版本的第一項權利要求中最有趣的部分是在該權利要求的後半部分提到了“置信度得分”:
為所識別的文檔集的子集中的每個文檔確定最終分數,最終分數是文檔的個性化分數、與文檔相關聯的通用分數以及考慮以下一項或多項的置信分數的函數:獲取的關於用戶的信息量、搜索查詢與用戶資料的匹配程度以及用戶資料的年齡; 並且通過最終分數,向與用戶相關聯的客戶端系統提供識別所識別的文檔集的至少一個子集的結果,其中提供結果包括至少部分地基於針對該個性化的分數提供至少一個結果對應的文檔,並根據與其他結果相對應但獨立於用戶簡檔的文檔的通用分數提供所獲得的搜索結果的其他結果。
該置信度分數基於:
- 獲取的用戶信息量
- 搜索查詢與用戶個人資料的匹配程度
- 用戶檔案的年齡
專利的第一個版本中沒有提到置信度分數,但添加到了第二個版本中。
使用術語、類別和基於鏈接的用戶配置文件的個性化排名
這 4 項專利的另一個顯著區別是標題從第一個“Web 搜索的個性化”更改為“使用術語、類別和基於鏈接的用戶配置文件的 Web 搜索結果的個性化”最近 3 個版本。 這是因為第一個專利提到了基於術語、類別和鏈接的用戶配置文件,但它們在後三個版本中更加突出。
正如我在上一篇文章中所寫:
這些配置文件可能由許多子配置文件組成,而不是對生成的用戶配置文件使用單個焦點,每個子配置文件都可以從不同的角度表徵搜索者的興趣。 這些可能包括:
具有多個術語的基於術語的配置文件具有指示其相對於其他術語的重要性的權重。
使用多個類別的基於類別的配置文件,可能組織成一個層次結構圖(就像您在 DMOZ 中看到的組織成的層次結構)。
基於鏈接的配置文件,包含多個鏈接,這些鏈接可能與用戶搜索歷史中識別的頁面或文檔直接或間接相關,每個鏈接都具有指示鏈接重要性的權重(如 PageRank)。
為什麼在搜索結果中使用個性化?
我喜歡這些專利解釋了為什麼谷歌認為在搜索結果中提供個性化是有價值的。
在某種程度上,他們將價值放在搜索者的用戶配置文件中,這可以幫助定制搜索結果,當搜索結果返回給搜索者以響應搜索者可能已提交給搜索引擎的查詢時。
該專利告訴我們查詢通常是簡潔的(平均 2-3 個詞,並且隨著搜索引擎索引中文檔數量的增加,可以返回的結果數量也會增加。但是,他們告訴我們“不從用戶的角度來看,匹配查詢的每個文檔都同樣重要。”
這些個性化專利旨在解決的問題是使搜索者不會被可能為查詢返回的許多搜索結果所淹沒。 搜索引擎將通過基於搜索結果與用戶查詢的相關性對搜索結果進行排序來實現這一點。 它將使用個性化來提供與特定搜索者更相關的結果。
提高搜索結果與搜索查詢相關性的一種方法是使用不同網頁的鏈接結構來計算可用於影響搜索結果排名的全局“重要性”分數。 (這就是該專利如何引用 PageRank。)
結果的個性化是對隨機衝浪模型的響應,PageRank 遵循了該模型。 該專利告訴我們:

實際上,像隨機衝浪者這樣的用戶是不存在的。
每個用戶在向搜索引擎提交查詢時都有自己的偏好。
引擎返回的搜索結果的質量必須由其用戶的滿意度來評估。
當查詢本身可以很好地定義用戶的偏好時,或者當用戶的偏好與隨機衝浪者對特定查詢的偏好相似時,用戶更有可能對搜索結果感到滿意。
但是,如果用戶的偏好受到一些個人因素的顯著偏見,而這些個人因素在搜索查詢本身並沒有明確反映,或者如果用戶的偏好與隨機用戶的偏好差異很大,那麼來自同一搜索引擎的搜索結果可能不太有用對用戶來說,如果不是沒用的話。
有時我發現自己改進了我的搜索器,以返回與我可能要查找的內容更相關的結果。
該專利還解決了這樣的優化結果,告訴我們查詢優化有時需要比搜索者可能擁有的更多的主題知識甚至更多的搜索引擎專業知識,需要比搜索者願意花費的更多時間和精力。
個性化基於用戶配置文件來自定義搜索結果
用戶配置文件由表徵搜索者偏好的多個項目組成。
這些項目可以從各種信息源中提取:
- 用戶提交的先前搜索查詢
- 從或到由先前查詢標識的文檔的鏈接
- 來自已識別文檔的採樣內容以及用戶隱式或明確提供的個人信息
個性化在 Google 的運作方式:
- 當搜索引擎收到來自搜索者的查詢時,它首先返回與查詢匹配的文檔
- 每個搜索結果都有一個基於 PageRank、與文檔關聯的文本和查詢的通用排名
- 搜索者的個人資料被識別,並且與每個被識別的文檔相關聯
- 文檔和用戶配置文件之間的相關性為文檔生成了一個配置文件等級,這表明文檔與用戶的相關性
- 然後搜索引擎會將文檔的通用排名和個人資料排名組合成一個個性化的排名,並根據它們的個性化排名對這些結果進行排序
搜索結果個性化排序流程
搜索者簡檔可能基於多個子簡檔,每個子簡檔可以從不同的角度表徵搜索的興趣。
基於術語的配置文件基於許多術語,每個術語都帶有權重,表明其相對於其他術語的重要性。 這些術語可以在網頁上找到,並且可以在頁面上識別重要和不重要的術語,以確定這些術語是否適合基於術語符合配置文件的搜索者,如專利中的這張圖所示:
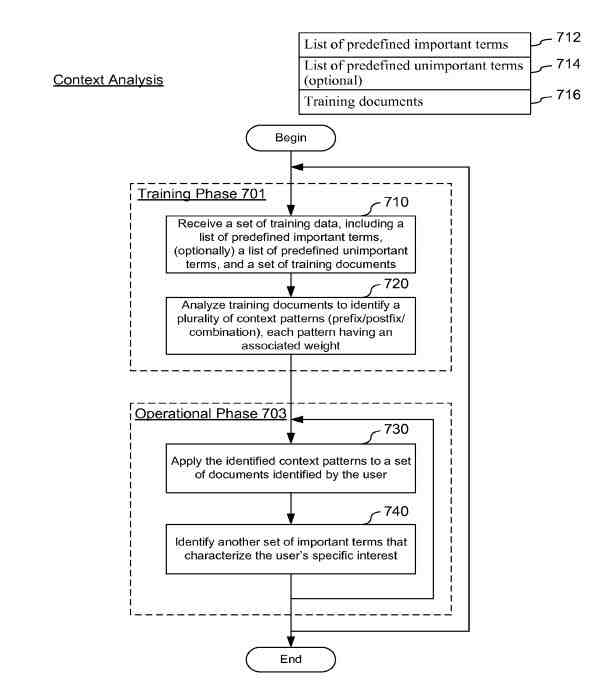
頁面上術語的使用將被加權:
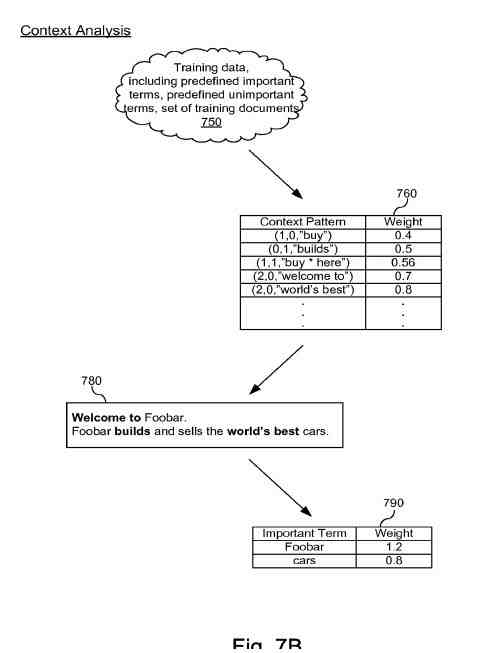
基於多個類別的基於類別的配置文件,可以組織成層次結構圖,如下面的專利圖所示:

並且搜索者的搜索偏好可以與多個類別中的至少一些相關聯,每個類別具有指示搜索者對可能落入這些類別的文檔的興趣的相關權重。 不同的類別可能有不同的權重:

一個用戶也可能有多個基於類別的配置文件。
並且子簡檔可以包括基於鏈接的簡檔,其包括與識別的文檔直接或間接相關的幾個鏈接,每個鏈接具有指示鏈接對搜索者的重要性的權重。 基於鏈接的配置文件中的鏈接可以關於不同的主機和域被進一步組織。
Google 可能會收集這些基於術語的個人資料權重、基於類別的個人資料權重和基於鏈接的個人資料權重,並使用它們來確定哪些文檔應作為個性化搜索結果返回,如專利圖所示:

搜索結果的個性化排名是按照以下專利流程圖確定的:
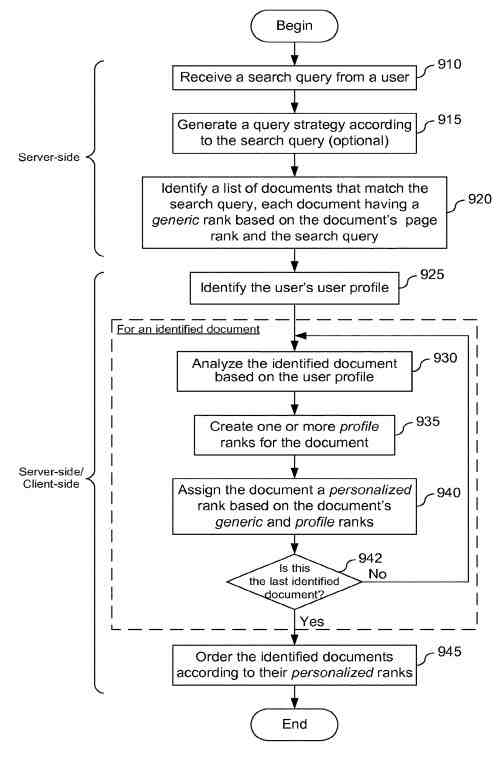
使用基於術語、類別和鏈接的用戶配置文件個性化 Web 搜索結果
發明人:Stephen R. Lawrence;
受讓人:GOOGLE LLC
美國專利:10,839,029
授予時間:2020 年 11 月 17 日
提交時間:2016 年 3 月 3 日
抽象的
一種用於創建用戶簡檔並使用該用戶簡檔對搜索引擎返回的搜索結果進行排序的系統和方法。 用戶配置文件基於用戶提交的搜索查詢、用戶與搜索引擎識別的文檔的特定交互以及用戶提供的個人信息。 可以通過執行段落採樣或上下文分析從用戶訪問的文檔中選擇用戶簡檔。 用戶簡檔調整與搜索結果相關聯的通用分數以衡量它們與用戶偏好和興趣的相關性。 搜索結果會相應地重新排序,以便最相關的結果出現在列表的頂部。 可以在客戶端-服務器網絡環境的客戶端或服務器端創建和/或存儲用戶配置文件。
Google 網頁搜索的個性化排名
如果您一直在使用 Google Now 查看個性化的新聞結果,您就會看到 Google 如何通過個性化來影響您看到的搜索結果。
使用 Google 即時,您有時可以通過填寫表格告訴 Google 您對什麼感興趣,從而明確表達您對特定主題的興趣。
您選擇點擊和閱讀的故事也會影響您將來可能看到的內容。 您不選擇某些故事的決定也可能會影響選擇向您展示的內容。
Google 現在還有一項功能,可讓您表明您希望查看更多或更少某種類型的文章。
如果您為受眾創建內容以吸引他們訪問特定的網頁或網站,那麼了解這些受眾的喜好和厭惡可能會對您有所幫助,並了解他們可能喜歡訪問網絡上的哪些地方。
與我從 Google 撰寫的其他專利(例如 Google 的個性化搜索結果中的一項專利相比,該專利對搜索結果的個性化排名如何提供了更多關於個性化如何在 Google 工作的詳細信息,該專利告訴我們將添加到的偏見文檔)非個性化搜索結果。