
Neuronale Netze – Wie sieht die Zukunft der Künstlichen Intelligenz aus?
Veröffentlicht: 2020-01-14Was sind neuronale Netze?
Inspiriert von den biologischen neuronalen Netzen „lernt“ dieses Rechensystem unter Berücksichtigung bestimmter Beispiele verschiedene Aufgaben zu erledigen, meist ohne mit aufgabenspezifischen Regeln programmiert zu sein.
Neuronale Netze sind eine funktionale Einheit des Deep Learning und sind von der Struktur des menschlichen Gehirns inspiriert. Die neueren Künstlichen Neuronalen Netze sind jedoch funktionale Einheiten des Deep Learning.
Zum Beispiel bei der Bilderkennung, wie der Identifizierung eines Katzenbildes.
Die Computersysteme können lernen, Bilder zu identifizieren, die Katzen enthalten, indem sie Beispielbilder analysieren, die manuell als "Katze" oder "keine Katze" gekennzeichnet wurden. Indem sie die Ergebnisse verwenden, um Katzen in anderen Bildern zu identifizieren, können sie lernen, das tatsächliche Bild zu identifizieren. Sie tun dies ohne Vorkenntnisse über Katzen oder deren Eigenschaften, zum Beispiel dass sie Fell, Schwänze, Schnurrhaare und katzenartige Gesichter haben.
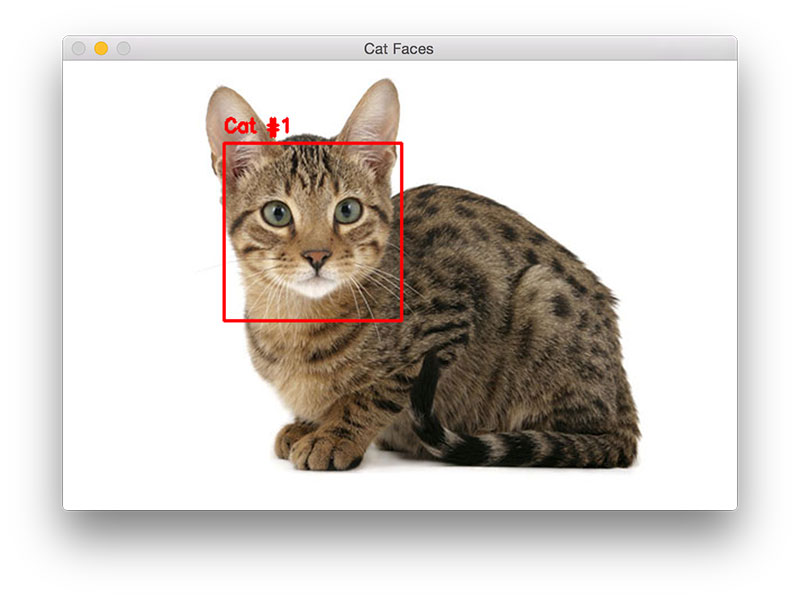
Abb. 2: Katzenidentifikation
Deep Learning verwendet künstliche neuronale Netze, die das Verhalten des menschlichen Gehirns nachahmen, um komplexe problemdatengesteuerte Probleme zu lösen. Deep Learning ist selbst ein Teil des maschinellen Lernens, das unter den großen Schirm der künstlichen Intelligenz (KI) fällt.
Maschinelles Lernen – Maschinelles Lernen, eine Anwendung von künstlicher Intelligenz (KI), bietet die Fähigkeit des Systems, automatisch aus Erfahrungen zu lernen und sich zu verbessern, ohne explizit programmiert zu werden. Machine Learning konzentriert sich auf die Entwicklung von Computerprogrammen, die auf Daten zugreifen und diese zum selbstständigen Lernen nutzen können.
Der Lernprozess beginnt, wenn sie beginnen, die Daten wie Beispiele, direkte Erfahrungen oder Anweisungen zu beobachten, um nach Mustern zu suchen, die ihnen helfen, in Zukunft bessere Entscheidungen zu treffen. Das primäre Ziel ist es, den Computern zu ermöglichen, automatisch ohne menschliches Eingreifen oder Zutun zu lernen und ihre Aktionen entsprechend anzupassen.
Deep Learning – Deep Learning (auch bekannt als Deep Structured Learning oder Hierarchical Learning) ist Teil einer breiteren Familie von maschinellen Lernmethoden, die auf künstlichen neuronalen Netzen basieren. Unter Deep Learning kann der Lernprozess überwacht, teilüberwacht oder unüberwacht erfolgen. Deep Learning ist eine Klasse von Algorithmen für maschinelles Lernen, die mehrere Schichten verwendet, um nach und nach Funktionen auf höherer Ebene aus der Roheingabe zu extrahieren.
Beispielsweise können bei der Bildverarbeitung niedrigere Schichten Kanten identifizieren, während höhere Schichten die für einen Menschen relevanten Konzepte wie Ziffern oder Buchstaben oder Gesichter identifizieren können.
Struktur des neuronalen Netzes
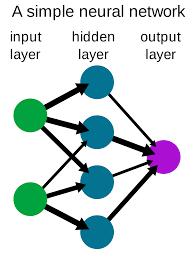
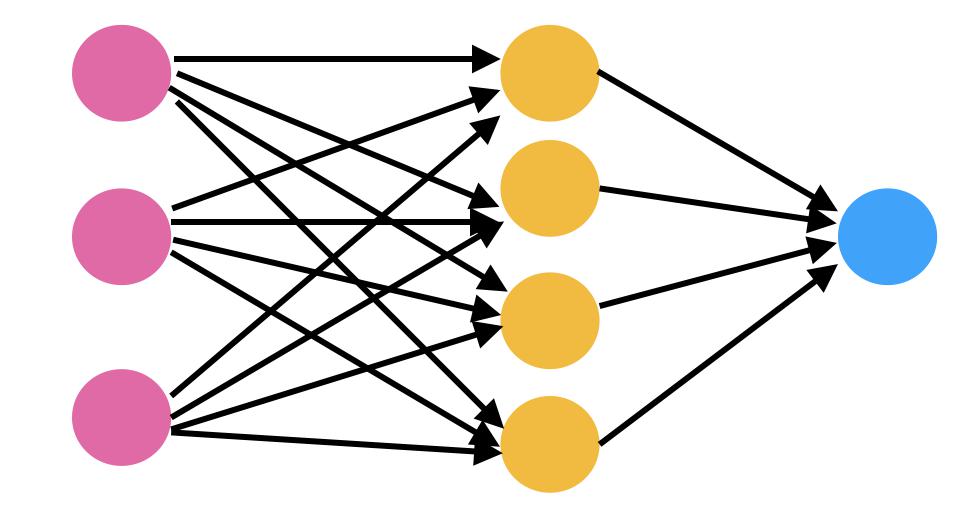
Neuronale Netze bestehen aus Neuronen, die die Kernverarbeitungseinheit des Netzes darstellen. Neuronale Netze bestehen grundsätzlich aus 3 verschiedenen Schichten, nämlich der Eingabeschicht, der versteckten Schicht und der Ausgabeschicht.
Eingabeschicht ist die Schicht, auf der die Eingabe in das Netzwerk eingespeist wird. Die Ausgabeschicht verwendet die Ausgabe dieser speziellen Hidden-Schicht, auf der die meisten Berechnungen stattfinden. Dies ist mit einem numerischen Wert verbunden, der Bias genannt wird, der dann zu der Eingangssumme addiert wird, die an die Schwellenwertfunktion namens Aktivierungsfunktion weitergegeben wird.
Die Aktivierungsfunktion bestimmt, ob ein bestimmtes Neuron aktiviert werden soll oder nicht. Aktiviertes Neuron überträgt Daten an die nächste Schicht.
Ein Kanal verbindet diese Neuronen.

Funktionsweise neuronaler Netze mit Beispiel
Grundlagen:
- Unsere Eingabeneuronen stellen einen Input dar, basierend auf den Informationen, die wir zu klassifizieren versuchen.
- Jede Zahl in den Eingabeneuronen wird an jeder Synapse (Kanal) gewichtet.
- An jedem Neuron in der nächsten Schicht addieren wir die Ausgaben aller Synapsen, die zu diesem Neuron kommen, zusammen mit einem Bias und wenden eine Aktivierungsfunktion (normalerweise eine Sigmoidfunktion) auf die gewichtete Summe an (dies macht die Zahl zwischen 0 und 1).
Eingabesumme = (w1*x1) + (w1*x2) + (w1*x3) + b1 berechnet für jeden Neuroneneingang - Die Ausgabe dieser Funktion wird als Eingabe für die nächste Synapsenschicht behandelt
- Fahren Sie fort, bis Sie den Ausgang erreichen.
Betrachten Sie ein Beispiel für die Klassifizierung von Blättern wie normales Blatt oder defektes Blatt.
Hier stellen wir unserem System ein Blattbild zur Verfügung, um es basierend auf seinem Zustand zu klassifizieren.
Das Bild wird basierend auf seiner Größe in Blöcke unterteilt, z. Aber in diesem Fall sind es 30px Breite und 900px Höhe, die der Eingabeschicht zugeführt werden.
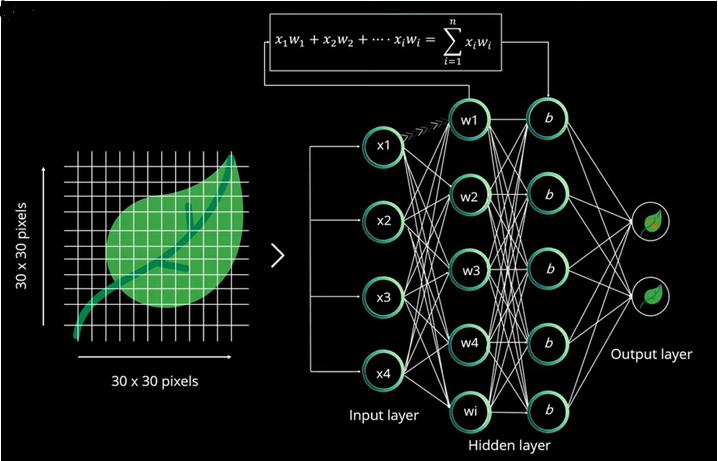
Das Neuron einer Schicht ist mit einer zufälligen Gewichtung mit einer anderen Schicht verbunden, die verwendet wird, um die Summe zu berechnen. Die Eingabesumme einer Schicht wird an die nächste Schicht (versteckte Schicht) gesendet und jeder versteckten Schicht wird ein numerischer Wert zugeordnet, der zur Eingabesumme addiert wird.
Die Aktivierungsfunktion entscheidet, welches Neuron aktiviert wird und welches Neuron auch immer aktiviert wird, der Neuronenwert wird an die nächste Schicht weitergegeben. Dies wird als Vorwärtsausbreitung bezeichnet.
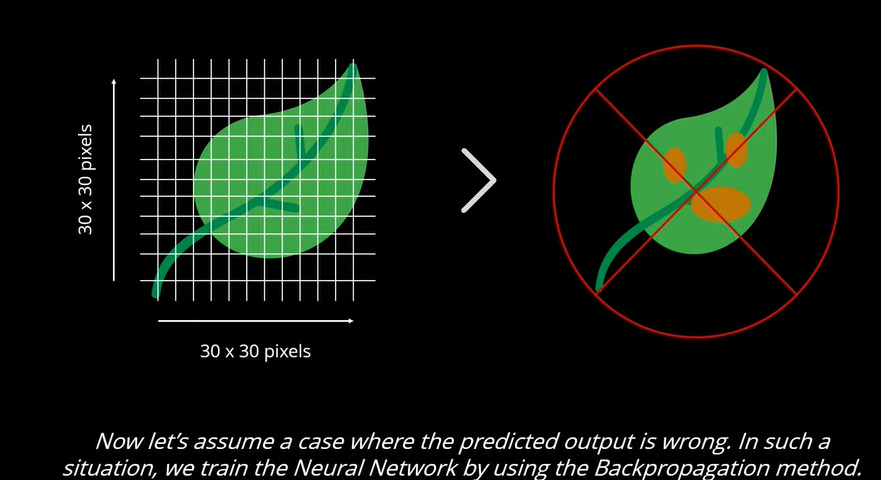
In der Ausgabeschicht bestimmt ein Neuron mit einem höheren Wert die Ausgabe. Der Wert ist im Grunde ein Wahrscheinlichkeitswert. Wenn der höhere Wahrscheinlichkeitswert eine falsche Ausgabe vorhersagt, muss das Netzwerk noch trainiert werden. In diesem Fall wird es als defektes Blatt erkannt und muss trainiert werden, wonach die Erkennung/Klassifizierung durchgeführt werden kann.
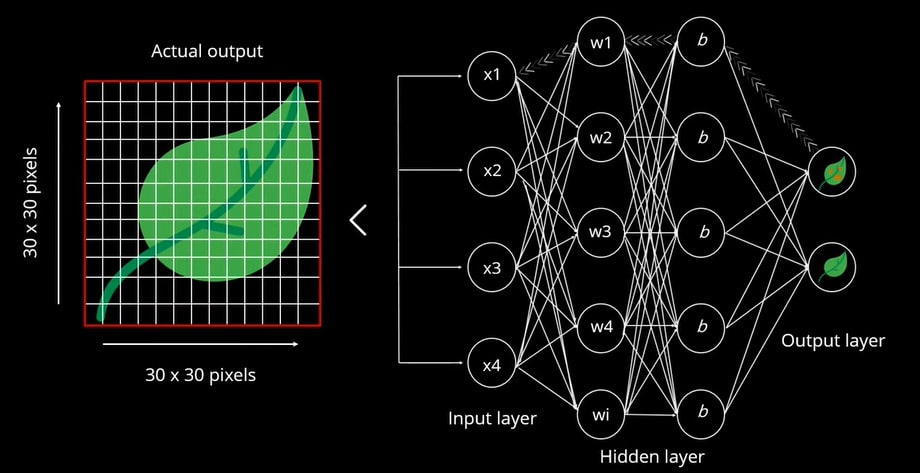
Die Rückwärtsausbreitung wird durchgeführt, um die korrekte Ausgabe vorherzusagen, die auf einem vorhergesagten Wert basiert. Diese wird mit der tatsächlichen Leistung verglichen. Iterativ werden Gewichte zugewiesen, bis sie das Blatt richtig vorhersagen. Das Gewicht wird dann neu initialisiert, um den Fehler zu minimieren.
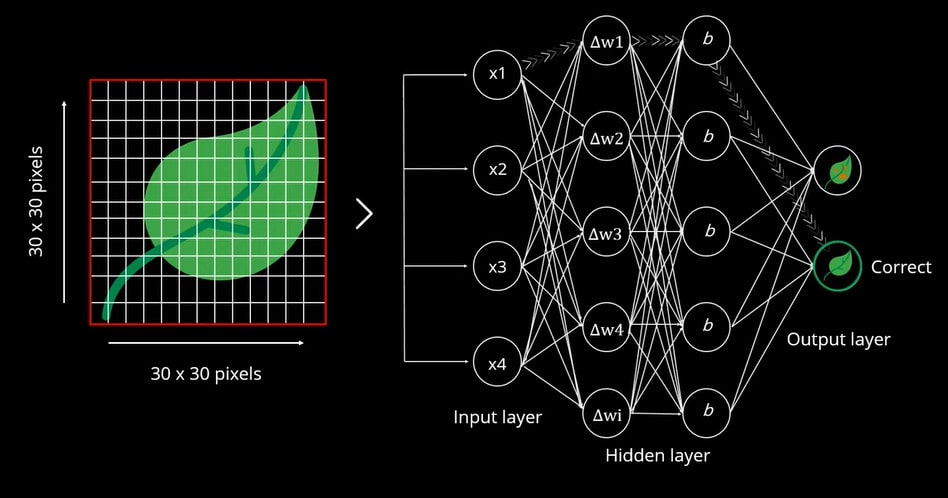
Nach der Neuinitialisierung des Gewichts, basierend auf der Fehlerdifferenz des vorhergesagten Wertes, erhielten wir das genaue Ergebnis als normales Blatt.
Einige Anwendungen des neuronalen Netzes
- Google Übersetzung
- Gesichtserkennung
- Selbstfahrende Autos
- Objekterkennung
- Musik Komposition
- Spracherkennung
- Rechtschreibprüfung
- Zeichenerkennung
Vorteile
- Wenn das Element des neuronalen Netzes ausfällt, kann es mit Hilfe der Parallelität problemlos fortgesetzt werden.
- Neuronale Netze lernen und müssen nicht umprogrammiert werden.
- Es kann in jeder Anwendung implementiert werden.
- Neuronale Netze führen Aufgaben aus, die ein lineares Programm nicht kann.
Nachteile
- Neuronale Netze brauchen Training, um zu funktionieren.
- Erfordert hohe Verarbeitungszeit für größere neuronale Netze.
- Datenmenge.