
Reti neurali: come sarà il futuro dell'intelligenza artificiale?
Pubblicato: 2020-01-14Cosa sono le reti neurali?
Ispirato alle reti neurali biologiche, questo sistema informatico "impara" a svolgere vari compiti prendendo in considerazione alcuni esempi, di solito senza essere programmato con regole specifiche per il compito.
Le reti neurali sono un'unità funzionale del deep learning e si ispirano alla struttura del cervello umano. Tuttavia, le reti neurali artificiali più recenti sono unità funzionali di deep learning.
Ad esempio, nel riconoscimento di immagini, come l'identificazione dell'immagine di un gatto.
I sistemi informatici potrebbero imparare a identificare le immagini che contengono gatti analizzando immagini di esempio che sono state etichettate manualmente come "gatto" o "nessun gatto". Utilizzando i risultati per identificare i gatti in altre immagini, sono in grado di imparare a identificare l'immagine reale. Lo fanno senza alcuna conoscenza preliminare dei gatti o delle loro caratteristiche, ad esempio che hanno pelliccia, coda, baffi e facce da gatto.
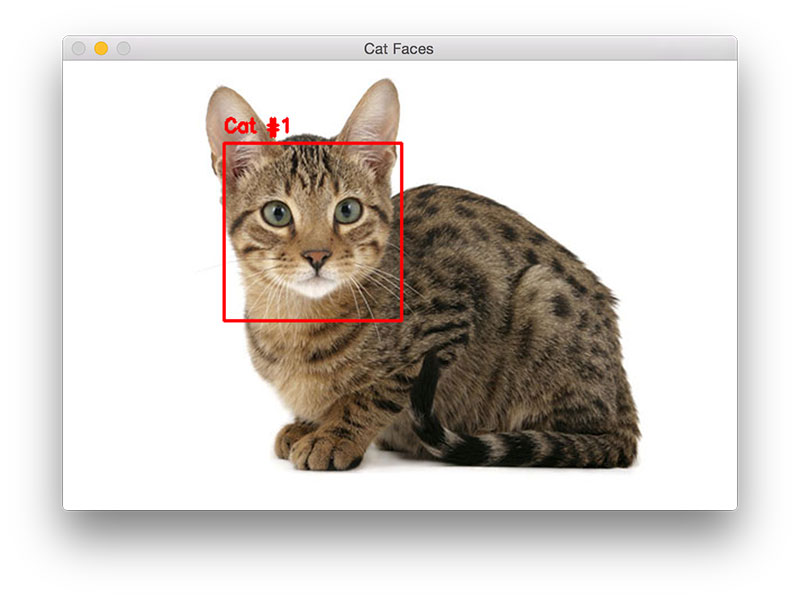
Fig 2: Identificazione del gatto
Il deep learning utilizza reti neurali artificiali che imitano il comportamento del cervello umano per risolvere problemi complessi basati sui dati. L'apprendimento profondo è di per sé una parte dell'apprendimento automatico che rientra nel grande ombrello dell'intelligenza artificiale (AI).
Apprendimento automatico : un'applicazione dell'intelligenza artificiale (AI), l'apprendimento automatico fornisce la capacità dei sistemi di apprendere e migliorare automaticamente dall'esperienza senza essere programmati in modo esplicito. L'apprendimento automatico si concentra sullo sviluppo di programmi per computer in grado di accedere ai dati e utilizzarli per apprendere da soli.
Il processo di apprendimento inizia quando iniziano a osservare i dati, come esempi, esperienza diretta o istruzioni, al fine di cercare modelli che li aiutino a prendere decisioni migliori in futuro. L'obiettivo principale è consentire ai computer di apprendere automaticamente senza l'intervento o l'assistenza umana e adattare le proprie azioni di conseguenza.
Apprendimento profondo: l'apprendimento profondo (noto anche come apprendimento strutturato profondo o apprendimento gerarchico) fa parte di una famiglia più ampia di metodi di apprendimento automatico basati su reti neurali artificiali. Sotto Deep Learning, il processo di apprendimento può essere supervisionato, semi-supervisionato o non supervisionato. Il deep learning è una classe di algoritmi di apprendimento automatico che utilizza più livelli per estrarre progressivamente funzionalità di livello superiore dall'input non elaborato.
Ad esempio, nell'elaborazione delle immagini, i livelli inferiori possono identificare i bordi, mentre i livelli superiori possono identificare i concetti rilevanti per un essere umano come cifre o lettere o volti.
Struttura della rete neurale
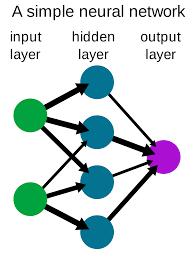
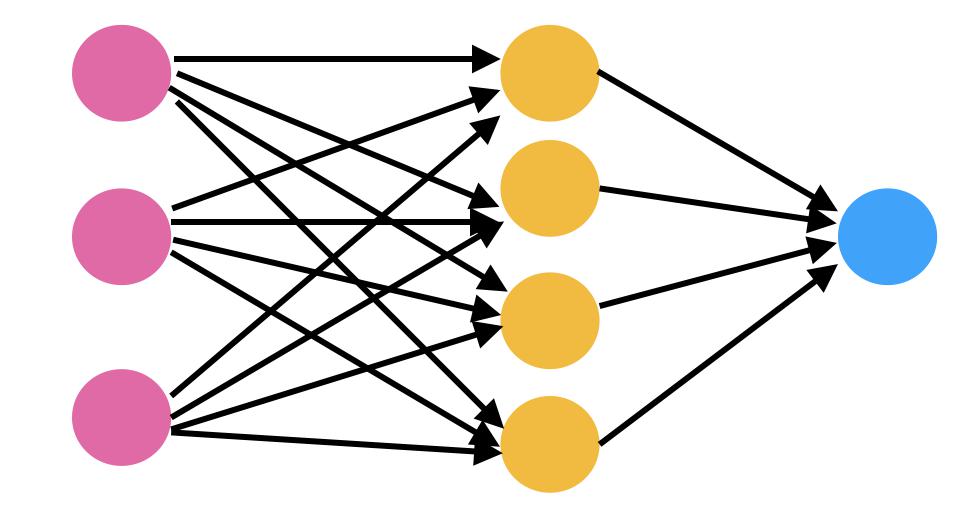
Le reti neurali sono costituite da neuroni, che è l'unità di elaborazione centrale della rete. Le reti neurali sono fondamentalmente costituite da 3 livelli diversi, vale a dire livello di input, livello nascosto e livello di output.
Il livello di input è il livello in cui l'input viene inviato alla rete. Il livello di output utilizza l'output di quel particolare livello nascosto, dove avviene la maggior parte del calcolo. Questo è associato a un valore numerico chiamato bias, che viene quindi aggiunto alla somma di input che viene passata alla funzione di soglia chiamata funzione di attivazione.
La funzione di attivazione determina se un particolare neurone deve essere attivato o meno. Il neurone attivato trasmette i dati al livello successivo.
Un canale si connette tra questi neuroni.

Funzionamento delle reti neurali con esempio
Passaggi di base:
- I nostri neuroni di input rappresentano un input, in base alle informazioni che stiamo cercando di classificare.
- Ad ogni numero nei neuroni di input viene assegnato un peso ad ogni sinapsi (canale).
- Ad ogni neurone nel livello successivo, aggiungiamo gli output di tutte le sinapsi che arrivano a quel neurone insieme a un bias e applichiamo una funzione di attivazione (di solito una funzione sigmoide) alla somma pesata (questo rende il numero qualcosa tra 0 e 1).
Somma input= (w1*x1) + (w1*x2) + (w1*x3) + b1 calcolato per ogni neurone in ingresso - L'output di quella funzione sarà trattato come l'input per il prossimo livello di sinapsi
- Continua fino a raggiungere l'uscita.
Considera un esempio di classificazione della foglia come foglia normale o foglia difettosa.
Qui stiamo fornendo un'immagine foglia al nostro sistema per classificare in base alle sue condizioni.
L'immagine è divisa in blocchi in base alla sua dimensione, ad esempio, se è 28 pixel di altezza e peso, viene divisa come 28X28 px di 784 px e alimentata al livello di input. Ma in questo caso sono 30 px di larghezza e 900 px di altezza, che vengono inviati al livello di input.
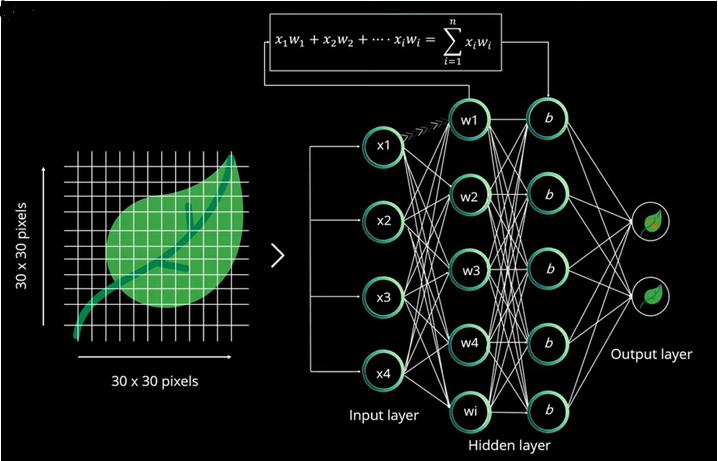
Il neurone di uno strato è collegato a un altro strato con un peso casuale che viene utilizzato per calcolare la somma. La somma in input di un layer viene inviata al layer successivo (layer nascosto) e ad ogni layer nascosto viene associato un valore numerico che viene aggiunto alla somma in input.
La funzione di attivazione decide quale neurone verrà attivato e qualunque neurone venga attivato, il valore del neurone viene passato al livello successivo. Questo è noto come propagazione in avanti.
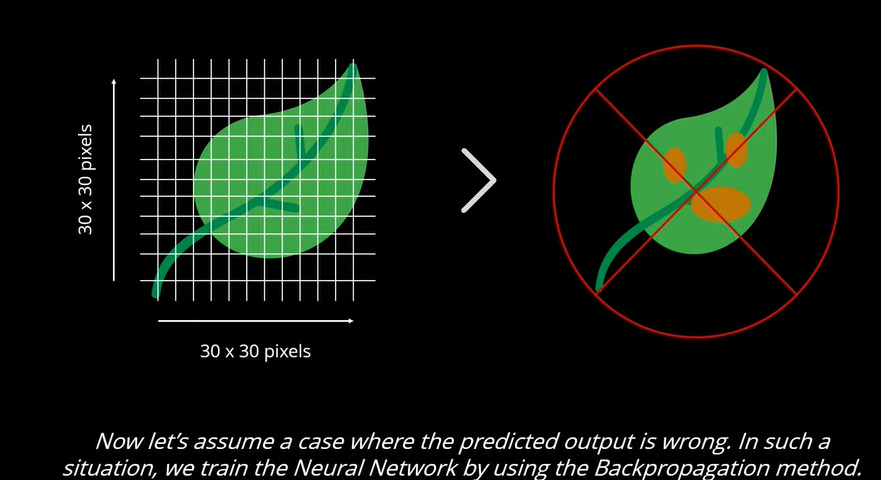
Nello strato di output il neurone con un valore più alto determina l'output. Il valore è fondamentalmente il valore della probabilità. Se il valore di probabilità più alto prevede un output errato, la rete deve ancora essere addestrata. In questo caso viene determinata come foglia difettosa quindi necessita di essere addestrata, dopodiché può essere effettuata la rilevazione/classificazione.
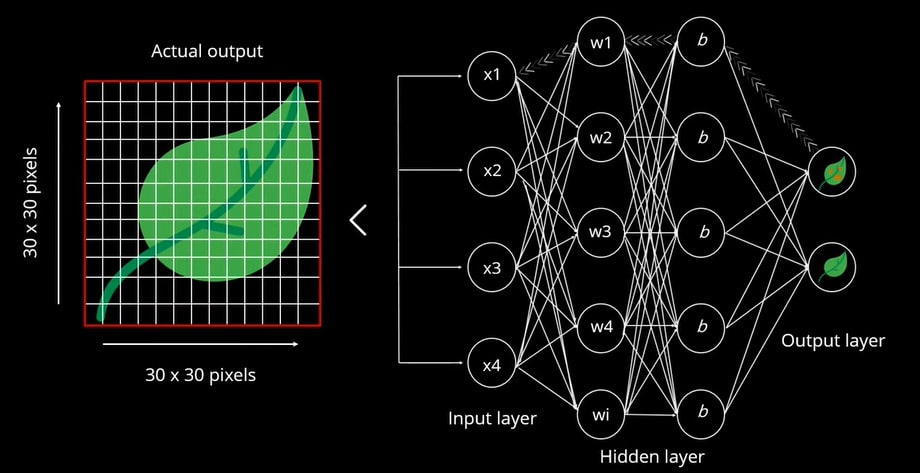
La propagazione all'indietro viene eseguita per prevedere l'output corretto, che si basa su un valore previsto. Questo viene confrontato con l'output effettivo. I pesi vengono assegnati iterativamente fino a quando non prevedono correttamente la foglia. Il peso viene quindi reinizializzato per ridurre al minimo l'errore.
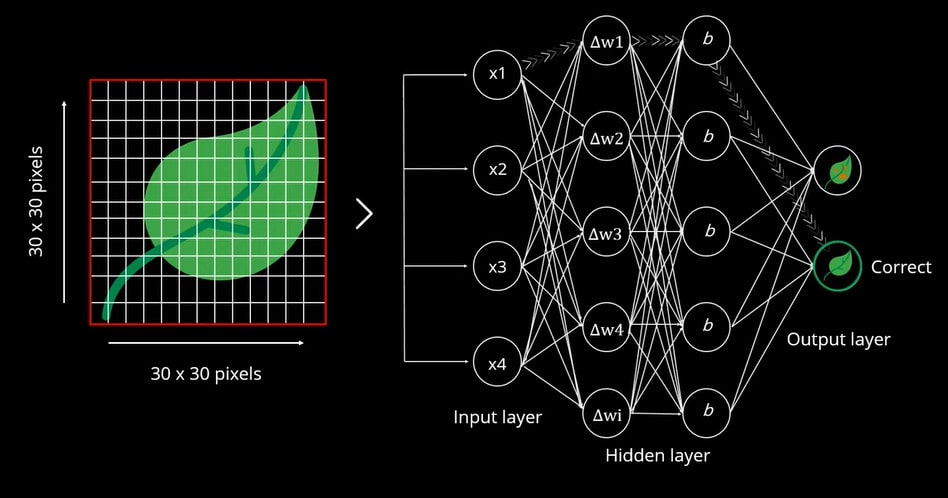
Dopo aver reinizializzato il peso, in base alla differenza di errore del valore previsto, abbiamo ottenuto il risultato esatto come una foglia normale.
Alcune applicazioni della rete neurale
- traduzione di Google
- Riconoscimento facciale
- Auto a guida autonoma
- Rilevamento di oggetti
- Composizione musicale
- Riconoscimento vocale
- Controllo ortografico
- Riconoscimento dei caratteri
Vantaggi
- Quando l'elemento della rete neurale fallisce, può continuare senza problemi con l'aiuto della natura parallela.
- Le reti neurali apprendono e non hanno bisogno di essere riprogrammate.
- Può essere implementato in qualsiasi applicazione.
- Le reti neurali svolgono compiti che un programma lineare non può.
Svantaggi
- Le reti neurali hanno bisogno di formazione per funzionare.
- Richiede un tempo di elaborazione elevato per reti neurali più grandi.
- Quantità di dati.