
Redes neurais - como é o futuro da inteligência artificial?
Publicados: 2020-01-14O que são redes neurais?
Inspirado nas redes neurais biológicas, esse sistema de computação “aprende” a realizar várias tarefas levando em consideração alguns exemplos, geralmente sem ser programado com regras específicas para cada tarefa.
As redes neurais são uma unidade funcional de aprendizado profundo e são inspiradas na estrutura do cérebro humano. No entanto, as redes neurais artificiais mais recentes são unidades funcionais de aprendizado profundo.
Por exemplo, no reconhecimento de imagens, como a identificação de uma imagem de gato.
Os sistemas de computação podem aprender a identificar imagens que contêm gatos, analisando imagens de exemplo que foram rotuladas manualmente como "gato" ou "sem gato". Ao usar os resultados para identificar gatos em outras imagens, eles são capazes de aprender a identificar a imagem real. Eles fazem isso sem nenhum conhecimento prévio dos gatos ou de suas características, por exemplo, que eles têm pelos, rabos, bigodes e rostos de gato.
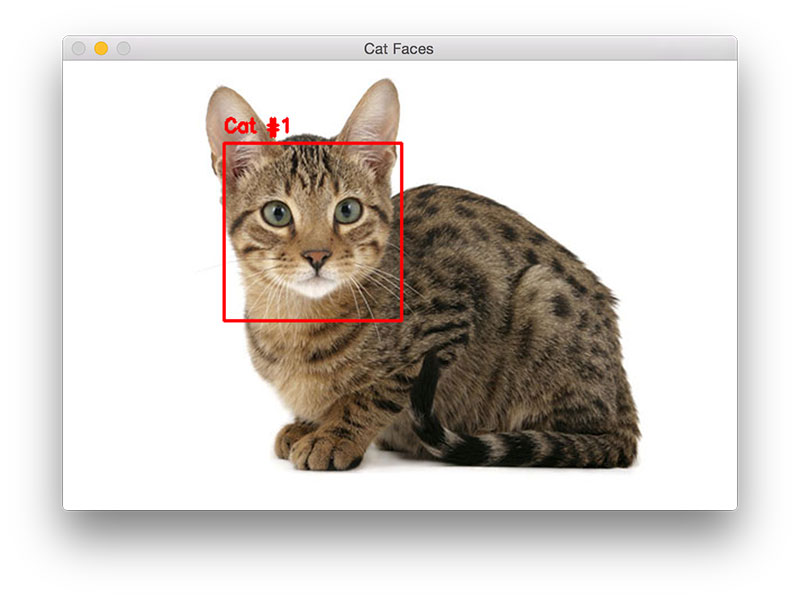
Fig 2: Identificação do gato
O aprendizado profundo usa redes neurais artificiais que imitam o comportamento do cérebro humano para resolver problemas complexos baseados em dados. O aprendizado profundo é em si uma parte do aprendizado de máquina que se enquadra no grande guarda-chuva da inteligência artificial (IA).
Aprendizado de máquina - uma aplicação de inteligência artificial (IA), o aprendizado de máquina fornece aos sistemas a capacidade de aprender e melhorar automaticamente com a experiência, sem ser explicitamente programado. O aprendizado de máquina se concentra no desenvolvimento de programas de computador que podem acessar dados e usá-los para aprender por si próprios.
O processo de aprendizagem começa quando eles começam a observar os dados, como exemplos, experiências diretas ou instruções, a fim de buscar padrões que os ajudem a tomar melhores decisões no futuro. O objetivo principal é permitir que os computadores aprendam automaticamente sem intervenção humana ou assistência e ajustem suas ações de acordo.
Aprendizado profundo - o aprendizado profundo (também conhecido como aprendizado estruturado profundo ou aprendizado hierárquico) faz parte de uma família mais ampla de métodos de aprendizado de máquina baseados em redes neurais artificiais. No Deep Learning, o processo de aprendizagem pode ser supervisionado, semissupervisionado ou não supervisionado. Aprendizado profundo é uma classe de algoritmos de aprendizado de máquina que usa várias camadas para extrair progressivamente recursos de nível superior da entrada bruta.
Por exemplo, no processamento de imagem, as camadas inferiores podem identificar as bordas, enquanto as camadas superiores podem identificar os conceitos relevantes para um ser humano, como dígitos, letras ou rostos.
Estrutura da rede neural
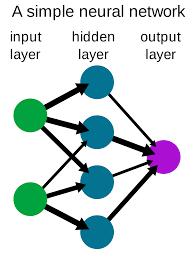
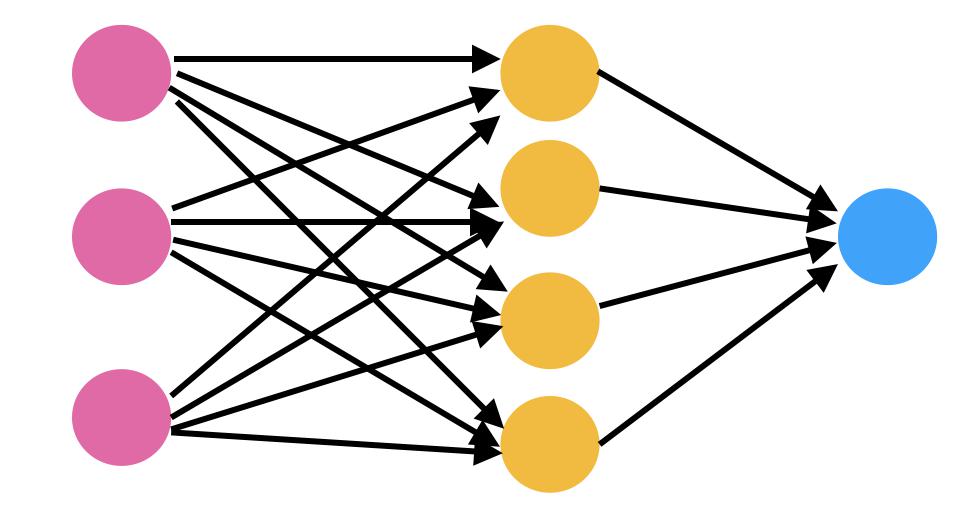
As redes neurais são feitas de neurônios, que é a unidade central de processamento da rede. As redes neurais são basicamente compostas por 3 camadas diferentes, a saber: camada de entrada, camada oculta e camada de saída.
A camada de entrada é a camada onde a entrada é fornecida à rede. A camada de saída usa a saída dessa camada Oculta específica, onde ocorre a maior parte do cálculo. Isso está associado a algum valor numérico chamado bias, que é então adicionado à soma de entrada que é passada para a função de limite chamada função de ativação.
A função de ativação determina se um determinado neurônio deve ser ativado ou não. O neurônio ativado transmite dados para a próxima camada.
Um canal se conecta entre esses neurônios.

Trabalho de redes neurais com exemplo
Passos básicos:
- Nossos neurônios de entrada representam uma entrada, com base nas informações que estamos tentando classificar.
- Cada número nos neurônios de entrada recebe um peso em cada sinapse (canal).
- Em cada neurônio na próxima camada, adicionamos as saídas de todas as sinapses que chegam a esse neurônio junto com um viés e aplicamos uma função de ativação (comumente uma função sigmóide) à soma ponderada (isso torna o número algo entre 0 e 1).
Soma de entrada = (w1 * x1) + (w1 * x2) + (w1 * x3) + b1 calculado para cada entrada de neurônio - A saída dessa função será tratada como a entrada para a próxima camada de sinapse
- Continue até chegar à saída.
Considere um exemplo de classificação de folha, como folha normal ou folha defeituosa.
Aqui, estamos fornecendo uma imagem de folha para nosso sistema classificar com base em sua condição.
A imagem é dividida em pedaços com base em sua dimensão, por exemplo, se tiver 28 pixels de altura e peso, ela é dividida em 28X28 px de 784 px e alimentada para a camada de entrada. Mas, neste caso, é 30px de largura e 900px de altura, que é alimentado para a camada de entrada.
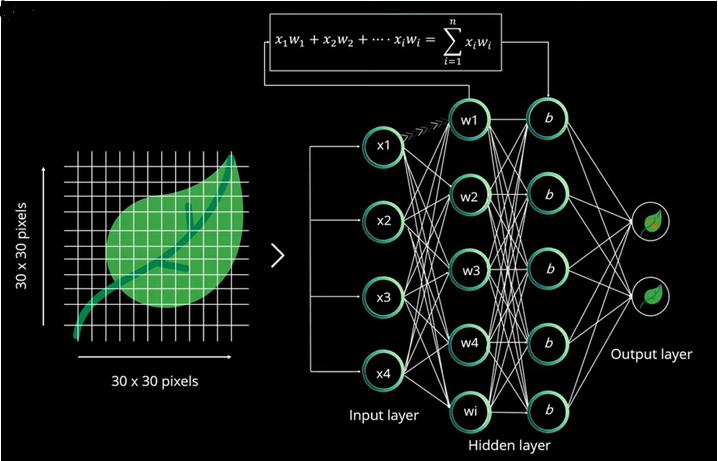
O neurônio de uma camada é conectado a outra camada com um peso aleatório que é usado para calcular a soma. A soma de entrada de uma camada é enviada para a próxima camada (camada oculta) e cada camada oculta é associada a um valor numérico que é adicionado à soma de entrada.
A função de ativação decide qual neurônio será ativado e qualquer que seja o neurônio ativado, o valor do neurônio é passado para a próxima camada. Isso é conhecido como propagação direta.
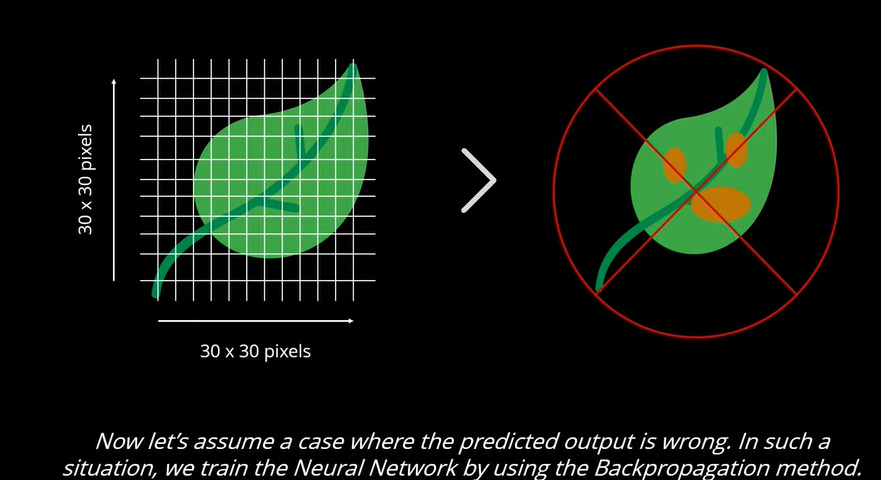
Na camada de saída, o neurônio com valor mais alto determina a saída. O valor é basicamente um valor de probabilidade. Se o valor de probabilidade mais alto predizer saída errada, a rede ainda não foi treinada. Neste caso, é determinada como uma folha defeituosa, portanto, precisa ser treinada, após o que a detecção / classificação pode ser realizada.
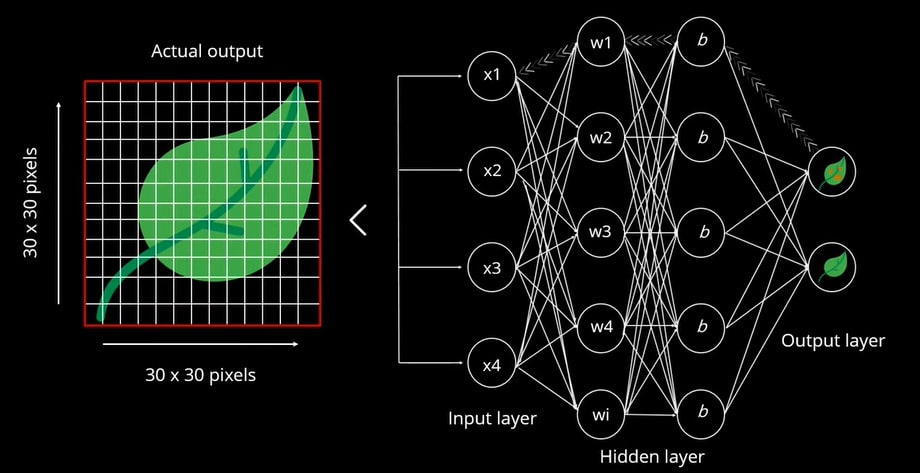
A propagação de retorno é executada para prever a saída correta, que é baseada em um valor previsto. Isso é comparado com a saída real. Iterativamente, pesos são atribuídos até que prevejam a folha corretamente. O peso é então reinicializado para minimizar o erro.
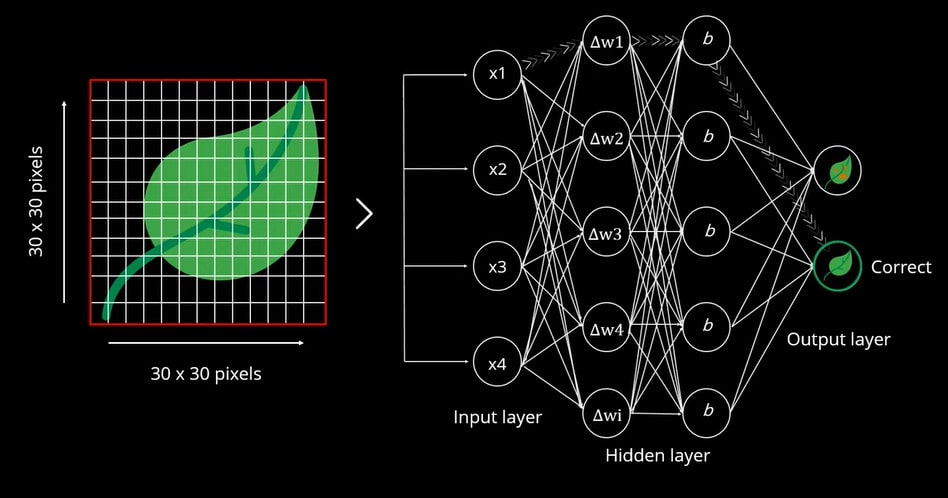
Após reinicializar o peso, com base na diferença de erro do valor previsto, obtivemos o resultado exato como uma folha normal.
Algumas das aplicações da rede neural
- tradução do Google
- Reconhecimento facial
- Carros autodirigidos
- Detecção de objetos
- Composição musical
- Reconhecimento de fala
- Verificação ortográfica
- Reconhecimento de personagem
Vantagens
- Quando o elemento da rede neural falha, ele pode continuar sem nenhum problema com a ajuda da natureza paralela.
- As redes neurais aprendem e não precisam ser reprogramadas.
- Pode ser implementado em qualquer aplicativo.
- As redes neurais realizam tarefas que um programa linear não pode.
Desvantagens
- As redes neurais precisam de treinamento para operar.
- Requer alto tempo de processamento para redes neurais maiores.
- Quantidade de dados.