
Présentation du rapport sur la couverture de l'index
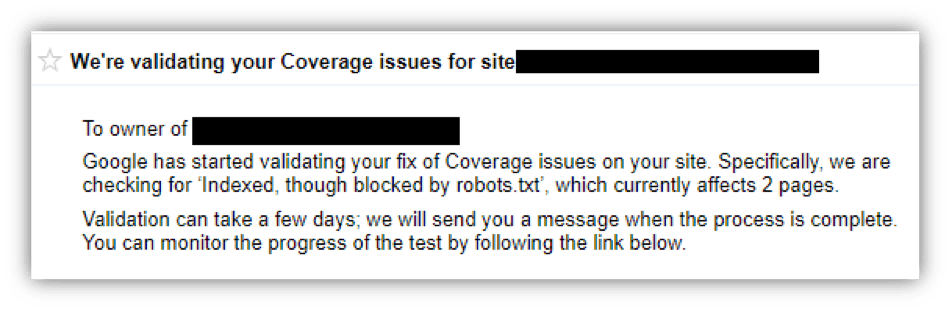
Publié: 2018-12-20Si vous avez vu un message comme celui-ci au cours des deux dernières semaines, respirez profondément et continuez à lire ! Dans cet article, je vais expliquer pourquoi vous rencontrez des problèmes de couverture de la console de recherche Google et comment les résoudre.
Qu'est-ce que le rapport de couverture de l'indice
Avec le dévoilement de la Google Search Console remaniée, il y a un certain nombre de fonctionnalités améliorées à connaître. L'une de ces fonctionnalités est le rapport de couverture d'index qui décrit le nombre d'URL de votre site que Google a cataloguées (ou indexées) et qui apparaîtront dans les résultats de recherche Google. Ce rapport se trouvait auparavant sous « État de l'index » dans l'ancienne interface de la Search Console :
ANCIEN VS NOUVEAU
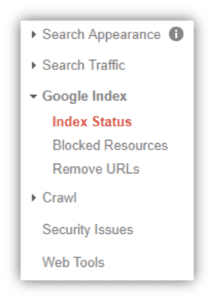

Maintenant, le rapport de couverture d'index peut être trouvé dans le menu "Index", puis cliquez sur "Couverture". Vous verrez quelles URL ont des erreurs d'indexation, des avertissements (ou valides avec des avertissements), sont valides ou exclues de l'index de Google. Pour bien comprendre ce rapport, explorons la signification de chacun de ces groupes.
Erreur : Ce sont des pages qui ne sont actuellement pas diffusées aux chercheurs sur Google, mais Google pense également que ce n'est pas votre intention.
Les erreurs peuvent être déclenchées de différentes manières, y compris quelque chose d'aussi simple que votre robots.txt bloquant les robots d'exploration d'une page que vous avez soumise pour indexation à quelque chose de plus compliqué comme une erreur de serveur (erreur de niveau 500). La bonne nouvelle? La plupart de ces erreurs peuvent être corrigées relativement facilement avec l'aide de votre webmaster, agence de marketing numérique ou équipe de développement Web.
Les erreurs les plus courantes que nous avons vues à Top Floor sont « URL soumise bloquée par robots.txt » et « URL soumise marquée « noindex ». alors que le fichier robots.txt interdit l'exploration vers cette URL ou qu'il contient une balise noindex. C'est un signal contradictoire car votre site dit à la fois aux moteurs de recherche de ne pas explorer ou indexer cette page, tout en demandant en même temps qu'elle soit indexée. Google considérera cela comme non intentionnel et le signalera sous Erreur plutôt qu'Exclus (ou désindexation intentionnelle).
Pour d'autres façons de rencontrer une erreur, voir ci-dessous :
- Erreur serveur (5xx) : Le serveur n'a pas pu trouver l'URL lorsqu'il a été demandé et a renvoyé une erreur de niveau 500.
- Solution : Parlez à votre équipe de développement pour résoudre ce problème côté serveur. Il n'y a pas grand-chose d'autre qu'une autre équipe peut faire ici sans l'expérience appropriée.
- Erreur de redirection : Il y a un problème dans la chaîne de redirection associée à cette URL. Soit il y a une boucle de redirection, soit une URL dans la chaîne a une erreur de niveau 400 ou 500.
- Solution : explorez l'URL, à l'aide de Screaming Frog ou d'un autre outil, et identifiez une erreur de niveau 400 ou 500 dans l'une des URL de la chaîne de redirection. En cas de doute, parlez-en à votre agence de marketing numérique et elle vérifiera cela pour vous.
- URL soumise bloquée par robots.txt : vous avez soumis cette page pour l'indexation dans Google Search Console, mais la page est actuellement bloquée par le fichier robots.txt.
- Solution : vérifiez votre fichier robots.txt sur www.yoursite.com/robots.txt. Assurez-vous qu'une ligne commençant par « disallow » ne fait pas référence à l'URL ou au sous-dossier avec votre URL en question. Votre agence de marketing numérique peut vous aider à identifier tout problème dans le fichier robots.txt.
- URL soumise marquée « noindex » : vous avez soumis cette page pour l'indexation, mais la page a une balise méta « noindex » ou un en-tête HTTP.
- Solution : Évaluez l'URL, voulez-vous que cette page soit trouvée lors de la recherche Google ? Si vous le faites, supprimez simplement la balise meta ou l'en-tête HTTP. Si vous ne trouvez pas la balise noindex en regardant la source de la page (Contrôle + U), demandez à votre agence de marketing numérique ou à votre équipe de développement.
- L'URL soumise semble être une soft 404 : vous avez soumis cette page pour indexation, mais Google pense que cette page est une soft 404.
- Solution : Une erreur Soft 404 se produit lorsqu'une page avec un contenu d'erreur 404 est affichée, mais que le code d'état n'est pas 404, mais 200. Examinez la page, est-elle censée être vraiment une page d'erreur et le code d'état est incorrect ? Parfois, Google interprétera à tort une page à faible contenu comme un soft 404. Dans les deux cas, envisagez une redirection 301 pour amener les utilisateurs vers une page pertinente et en direct.
- URL soumise introuvable (404) : vous avez soumis une URL de code d'erreur 404 pour l'indexation via la console de recherche Google.
- Solution : vous ne voulez pas de pages d'erreur dans l'index car cela offre une mauvaise expérience utilisateur. Si cette page n'est pas censée redevenir une page d'état 200 en direct dans le futur, 301 la redirigez vers le contenu pertinent de votre site.
Avertissement : les URL affichées dans la section Avertissement, ou Valide avec avertissements, sont classées par Google en tant que « Pages… pourraient nécessiter votre attention, et peuvent ou non avoir été indexées, selon le résultat spécifique »1

Qu'est-ce que cela signifie? Pour moi, cela signifie que Google ne sait pas comment gérer une URL, mais l'a maintenue indexée à contrecœur. Quelle que soit la situation de chaque URL, supprimez cette incertitude et découvrez pourquoi chaque URL est signalée. D'après ce que j'ai vu jusqu'à présent, cela revient à quelqu'un qui utilise le fichier robots.txt comme outil de désindexation. Ceci est incorrect pour plusieurs raisons.
Le fichier robots.txt est utilisé pour définir des règles pour empêcher les moteurs de recherche d'explorer certaines zones de votre site. Si une URL est affichée aux chercheurs sur Google et que vous souhaitez que cela s'arrête, n'ajoutez pas de clause d'interdiction à votre fichier robots.txt car cela indiquera à Google d'arrêter de vérifier cette page avec ses robots d'exploration, ses araignées ou autre. nom que vous voulez leur donner. Pour vraiment retirer une URL de Google ou de tout moteur de recherche, attribuez-lui une balise noindex soit dans le <head> du HTML, soit via un en-tête HTTP.
Bien que cet article se concentre sur les erreurs et les avertissements, couvrons rapidement les sections Valide et Exclu.
Valide : Tout simplement, il s'agit d'une liste d'URL qui ont été indexées avec succès. Le seul contrôle qualité à faire ici est pour votre plan de site XML et pour vous assurer que vous n'indexez pas quelque chose que vous ne voulez pas. Pour ce faire, cliquez simplement sur la case « Valide » (supprimez la confusion en n'ayant qu'une seule case en surbrillance à la fois) et passez en revue la section Détails.
Vous rencontrerez deux types de détails principaux, « Soumis et indexé » et « Indexé, non soumis dans le plan du site : »
- Soumis et indexé : il s'agit d'une liste d'URL de votre site dont Google confirme qu'elles sont indexées avec succès.
- Indexé, non soumis dans le plan du site : il s'agit d'URL indexées qui n'apparaissent pas dans votre plan de site XML. Selon votre site, il ne devrait généralement pas y en avoir un grand nombre. Si vous souhaitez qu'une URL soit indexée, vous devez aider les moteurs de recherche et vous-même, et les ajouter à votre plan de site XML. Si vous ne savez pas comment procéder, veuillez contacter votre agence de marketing numérique et elle pourra effectuer le contrôle qualité de votre plan de site de manière appropriée.
Exclus : il s'agit d'URL volontairement exclues de l'index de Google. Cela peut se produire de différentes manières, mais Google pense que votre site a pris des mesures pour empêcher la recherche de ces URL. Ce n'est en aucun cas un problème et fait partie d'un site sain. Les ressources internes, telles que les pages protégées par mot de passe ou les URL d'images générées par un site WordPress, doivent être exclues de l'index car elles constituent une mauvaise expérience de page de destination pour les chercheurs en ligne.
Avoir des questions?
Si vous avez lu cet article et que vous ne savez toujours pas comment gérer vos problèmes de couverture, veuillez nous appeler et notre équipe de marketing de recherche se fera un plaisir de vous aider à résoudre le problème.