
Grundlegendes zum Bericht zur Indexabdeckung
Veröffentlicht: 2018-12-20Wenn Sie in den letzten Wochen eine solche Nachricht gesehen haben, atmen Sie tief durch und lesen Sie weiter! In diesem Artikel werde ich aufschlüsseln, warum Sie Abdeckungsprobleme in der Google Search Console sehen und wie Sie diese beheben können.
Was ist der Indexabdeckungsbericht?
Mit der Vorstellung der überarbeiteten Google Search Console gibt es eine Reihe von verbesserten Funktionen zu beachten. Eine dieser Funktionen ist der Bericht zur Indexabdeckung, der darlegt, wie viele URLs Ihrer Website von Google katalogisiert (oder indexiert) wurden und in den Google-Suchergebnissen erscheinen. Dieser Bericht wurde früher unter "Indexstatus" in der alten Search Console-Benutzeroberfläche gefunden:
ALT VS NEU
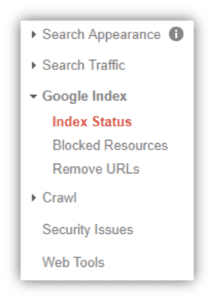

Jetzt finden Sie den Index-Coverage-Bericht im Menü „Index“ und klicken Sie dann auf „Coverage“. Ihnen wird angezeigt, welche URLs Indexierungsfehler, Warnungen (oder Gültig mit Warnungen), gültig oder vom Google-Index ausgeschlossen sind. Um diesen Bericht richtig zu verstehen, lassen Sie uns untersuchen, was jede dieser Gruppen bedeutet.
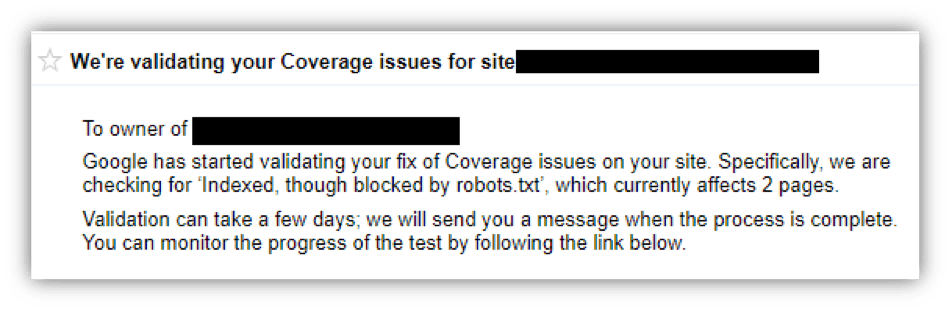
Fehler : Dies sind Seiten, die Google-Suchern derzeit nicht angezeigt werden, aber Google ist auch der Ansicht, dass dies nicht Ihre Absicht ist.
Fehler können auf viele verschiedene Arten ausgelöst werden, darunter etwas so Einfaches wie Ihre robots.txt-Blockierung von Crawlern von einer Seite, die Sie zur Indexierung eingereicht haben, bis hin zu etwas Komplizierterem wie einem Serverfehler (500-Level-Fehler). Die guten Nachrichten? Die meisten dieser Fehler können mit Hilfe Ihres Webmasters, Ihrer Agentur für digitales Marketing oder Ihres Webentwicklungsteams relativ einfach behoben werden.
Die häufigsten Fehler, die wir bei Top Floor gesehen haben, sind „Gesendete URL blockiert durch robots.txt“ und „Gesendete URL markiert 'noindex'“. Dies sind weniger schlimme Fehler und entstehen durch das Einreichen einer URL zur Indexierung über die Google Search Console während entweder die robots.txt-Datei das Crawlen zu dieser URL nicht zulässt oder ein noindex-Tag enthält. Dies ist ein widersprüchliches Signal, da Ihre Website Suchmaschinen anweist, diese Seite nicht zu crawlen oder zu indizieren, aber gleichzeitig darum bittet, dass sie indiziert wird. Google sieht dies als unbeabsichtigt und markiert es unter Fehler und nicht als Ausgeschlossen (oder absichtliche Deindexierung).
Weitere Möglichkeiten zum Auftreten eines Fehlers finden Sie unten:
- Serverfehler (5xx) : Der Server konnte die URL bei Anforderung nicht finden und gab einen Fehler der Stufe 500 zurück.
- Lösung : Sprechen Sie mit Ihrem Entwicklungsteam, um dieses serverseitige Problem zu beheben. Es gibt nicht viel mehr, was ein anderes Team hier ohne die entsprechende Erfahrung machen kann.
- Weiterleitungsfehler : Es gibt ein Problem in der Weiterleitungskette, die dieser URL zugeordnet ist. Entweder gibt es eine Umleitungsschleife oder eine URL in der Kette weist einen Fehler der Ebene 400 oder 500 auf.
- Lösung : Crawlen Sie die URL mit Screaming Frog oder einem anderen Tool und identifizieren Sie einen 400- oder 500-Level-Fehler in einer der URLs in der Weiterleitungskette. Wenn Sie sich nicht sicher sind, sprechen Sie mit Ihrer Agentur für digitales Marketing und sie prüft dies für Sie.
- Eingesendete URL von robots.txt blockiert : Sie haben diese Seite zur Indexierung in der Google Search Console eingereicht, aber die Seite wird derzeit von der robots.txt-Datei blockiert.
- Lösung : Überprüfen Sie Ihre robots.txt-Datei unter www.yoursite.com/robots.txt. Stellen Sie sicher, dass eine Zeile, die mit „disallow“ beginnt, nicht auf die URL oder den Unterordner mit Ihrer fraglichen URL verweist. Ihre Agentur für digitales Marketing kann Ihnen bei der Identifizierung von Problemen in der robots.txt-Datei helfen.
- Eingesendete URL mit der Kennzeichnung „noindex “: Sie haben diese Seite zur Indexierung eingereicht, aber die Seite hat ein „noindex“-Meta-Tag oder einen HTTP-Header.
- Lösung : Bewerten Sie die URL. Soll diese Seite bei der Google-Suche gefunden werden? Entfernen Sie in diesem Fall einfach das Meta-Tag oder den HTTP-Header. Wenn Sie das noindex-Tag anhand der Seitenquelle (Strg + U) nicht finden können, wenden Sie sich an Ihre Agentur für digitales Marketing oder Ihr Entwicklungsteam.
- Die übermittelte URL scheint ein Soft 404 zu sein : Sie haben diese Seite zur Indexierung eingereicht, aber Google geht davon aus, dass diese Seite ein Soft 404 ist.
- Lösung: Ein Soft 404-Fehler liegt vor, wenn eine Seite mit 404-Fehlerinhalt angezeigt wird, der Statuscode jedoch nicht 404, sondern 200 lautet. Überprüfen Sie die Seite, soll es sich wirklich um eine Fehlerseite handeln und der Statuscode ist falsch? Manchmal interpretiert Google eine Seite mit wenig Inhalt fälschlicherweise als Soft 404. Ziehen Sie in jedem Fall eine 301-Weiterleitung in Betracht, um Benutzer auf eine relevante Live-Seite zu leiten.
- Gesendete URL nicht gefunden (404) : Sie haben eine 404-Fehlercode-URL zur Indexierung über die Google Search Console eingereicht.
- Lösung : Sie möchten keine Fehlerseiten im Index, da dies eine schlechte Benutzererfahrung bietet. Wenn nicht erwartet wird, dass diese Seite irgendwann in der Zukunft wieder zu einer Live-Seite mit 200 Status wird, leitet 301 sie zu relevanten Inhalten auf Ihrer Website weiter.
Warnung : URLs, die im Abschnitt "Warnung" oder "Gültig mit Warnungen" angezeigt werden, werden von Google als "Seiten ... erfordern möglicherweise Ihre Aufmerksamkeit und können je nach Ergebnis indexiert oder nicht indexiert werden"1 . kategorisiert

Was bedeutet das? Für mich bedeutet dies, dass Google sich nicht sicher ist, wie eine URL zu handhaben ist, sie jedoch ungern indiziert hat. Beseitigen Sie unabhängig von der Situation jeder URL diese Unsicherheit und untersuchen Sie, warum jede URL gekennzeichnet wird. Nach allem, was ich bisher gesehen habe, kommt es darauf an, dass jemand die robots.txt-Datei als De-Indexierungstool verwendet. Dies ist aus mehreren Gründen falsch.
Die Datei robots.txt wird verwendet, um Regeln einzurichten, die verhindern, dass Suchmaschinen bestimmte Bereiche Ihrer Website crawlen. Wenn Suchern bei Google eine URL angezeigt wird und Sie möchten, dass dies aufhört, fügen Sie Ihrer robots.txt-Datei keine Disallow-Klausel hinzu, da dies Google anweist, die Überprüfung dieser Seite mit seinen Crawlern, Spidern oder was auch immer einzustellen Namen, den Sie ihnen geben möchten. Um eine URL wirklich von Google oder einer anderen Suchmaschine zu entfernen, geben Sie ihr ein noindex-Tag entweder im <head> des HTML-Codes oder über einen HTTP-Header.
Obwohl der Schwerpunkt dieses Artikels auf Fehlern und Warnungen liegt, lassen Sie uns kurz die Abschnitte Gültig und Ausgeschlossen behandeln.
Valid : Dies ist ganz einfach eine Liste von URLs, die erfolgreich indiziert wurden. Die einzige QA, die hier durchgeführt werden muss, ist für Ihre XML-Sitemap und um sicherzustellen, dass Sie nichts indizieren, was Sie nicht möchten. Klicken Sie dazu einfach auf das Kästchen „Gültig“ (beseitigen Sie Verwirrung, indem Sie jeweils nur ein Kästchen markieren) und überprüfen Sie den Abschnitt Details.
Sie werden mit zwei Hauptdetailtypen konfrontiert, "Eingereicht und indiziert" und "Indiziert, nicht in der Sitemap eingereicht:"
- Eingereicht und indexiert: Dies ist eine Liste von URLs Ihrer Website, die von Google bestätigt wurden, dass sie erfolgreich indexiert wurden.
- Indexiert, nicht in Sitemap eingereicht: Dies sind indizierte URLs, die nicht in Ihrer XML-Sitemap erscheinen. Abhängig von Ihrer Website sollte es in der Regel nicht viele davon geben. Wenn Sie möchten, dass eine URL indiziert wird, sollten Sie Suchmaschinen und sich selbst helfen und sie zu Ihrer XML-Sitemap hinzufügen. Wenn Sie sich nicht sicher sind, wie Sie dies tun sollen, wenden Sie sich bitte an Ihre Agentur für digitales Marketing, damit diese Ihre Sitemap entsprechend einer QA-Analyse unterziehen kann.
Ausgeschlossen : Dies sind URLs, die absichtlich aus dem Google-Index ausgeschlossen wurden. Dies kann auf viele verschiedene Arten geschehen, aber Google ist der Ansicht, dass Ihre Website Schritte unternommen hat, um zu verhindern, dass diese URLs durchsucht werden. Dies ist keineswegs ein Problem und gehört zu einer gesunden Website. Interne Ressourcen wie passwortgeschützte Seiten oder Bild-URLs, die von einer WordPress-Site generiert werden, sollten aus dem Index ausgeschlossen werden, da sie für Online-Sucher eine schlechte Landingpage-Erfahrung darstellen.
Habe Fragen?
Wenn Sie diesen Artikel gelesen haben und sich immer noch nicht sicher sind, wie Sie mit Ihren Abdeckungsproblemen umgehen sollen, rufen Sie uns bitte an. Unser Suchmaschinenmarketing-Team hilft Ihnen gerne bei der Lösung.