
了解索引覆盖率报告
已发表: 2018-12-20如果您在过去几周看到过这样的消息,请深呼吸并继续阅读! 在本文中,我将分解为什么您会看到来自 Google Search Console 的覆盖问题以及如何解决这些问题。
什么是索引覆盖率报告
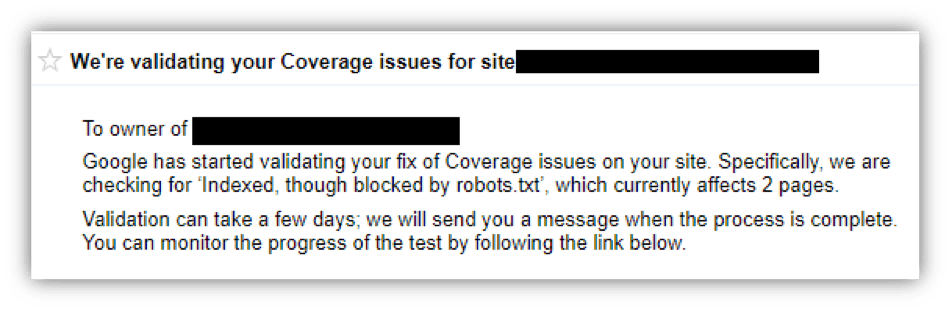
随着经过改进的 Google Search Console 的推出,有许多增强功能需要注意。 其中一项功能是索引覆盖率报告,它概述了 Google 已编目(或编入索引)并将出现在 Google 搜索结果中的站点 URL 的数量。 此报告以前位于旧版 Search Console 界面中的“索引状态”下:
旧与新
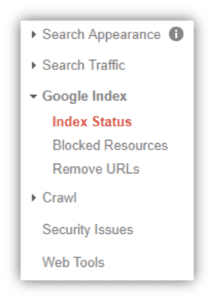

现在,可以在“索引”菜单下找到“索引覆盖率报告”,然后单击“覆盖率”。 您将看到哪些网址存在索引错误、警告(或有效但有警告)、有效或已从 Google 索引中排除。 为了正确理解这份报告,让我们探讨一下每个组的含义。
错误:这些页面目前没有提供给 Google 上的搜索者,但 Google 也认为这不是您的意图。
错误可以通过许多不同的方式触发,包括像 robots.txt 阻止爬虫从您提交索引的页面到更复杂的东西,例如服务器错误(500 级错误)。 好消息? 在您的网站管理员、数字营销机构或 Web 开发团队的帮助下,大多数这些错误都可以相对轻松地修复。
我们在 Top Floor 看到的更常见的错误是“已提交的 URL 被 robots.txt 阻止”和“已提交的 URL 标记为‘noindex’”。这些是不太险恶的错误,是通过通过 Google Search Console 提交用于索引的 URL 引起的而 robots.txt 文件不允许抓取到此 URL 或它包含 noindex 标记。 这是一个相互矛盾的信号,因为您的网站既告诉搜索引擎不要抓取此页面或将其编入索引,同时又要求将其编入索引。 Google 会将其视为无意并将其标记为“错误”而不是“排除”(或故意取消索引)。
有关遇到错误的其他方法,请参见下文:
- 服务器错误 (5xx) :服务器在请求时找不到 URL 并返回 500 级错误。
- 解决方案:与您的开发团队联系以修复此服务器端。 如果没有适当的经验,其他团队在这里也无能为力。
- 重定向错误:与此 URL 关联的重定向链中存在问题。 要么存在重定向循环,要么链中的 URL 存在 400 或 500 级错误。
- 解决方案:使用 Screaming Frog 或其他工具抓取 URL,并在重定向链中的一个 URL 中识别 400 或 500 级错误。 如果不确定,请与您的数字营销机构联系,他们会为您检查。
- 提交的 URL 被 robots.txt 阻止:您提交此页面以在 Google Search Console 中编入索引,但该页面当前被 robots.txt 文件阻止。
- 解决方案:在 www.yoursite.com/robots.txt 上仔细检查您的 robots.txt 文件。 确保以“disallow”开头的行没有引用您的 URL 所在的 URL 或子文件夹。 您的数字营销机构可以帮助识别 robots.txt 中的任何问题。
- 提交的 URL 标记为“noindex ”:您提交此页面以进行索引,但该页面具有“noindex”元标记或 HTTP 标头。
- 解决方案:评估网址,您是否希望在 Google 搜索时找到此页面? 如果这样做,只需删除元标记或 HTTP 标头。 如果通过查看页面源代码 (Control + U) 找不到 noindex 标签,请询问您的数字营销机构或开发团队。
- 提交的 URL 似乎是软 404 :您提交此页面用于索引,但 Google 认为此页面是软 404。
- 解决方案:软404错误是指页面显示404错误内容,但状态码不是404,而是200。检查页面,是否真的是错误页面,状态码不正确? 有时,Google 会将内容较少的页面误解为软 404。无论哪种情况,请考虑使用 301 重定向将用户带到相关的实时页面。
- 未找到提交的 URL (404) :您提交了一个 404 错误代码 URL 以通过 Google Search Console 进行索引。
- 解决方案:您不希望索引中出现错误页面,因为它提供了糟糕的用户体验。 如果预计此页面在未来某个时候不会恢复为实时的 200 状态页面,则 301 会将其重定向到您网站上的相关内容。
警告:显示在“警告”或“带警告”部分下的 URL 被 Google 归类为“页面……可能需要您注意,根据具体结果可能已编入索引,也可能未编入索引”1

那么这是什么意思? 对我来说,这意味着 Google 不确定如何处理 URL,但不情愿地将其编入索引。 不管每个 URL 的情况如何,消除这种不确定性并深入研究每个 URL 被标记的原因。 从我目前所见,归结为有人使用 robots.txt 文件作为去索引工具。 由于几个原因,这是不正确的。
robots.txt 文件用于设置规则以防止搜索引擎抓取您网站的某些区域。 如果某个 URL 正在向 Google 上的搜索者显示并且您希望它停止,请不要在您的 robots.txt 文件中添加 disallow 子句,因为这将暗示 Google 停止使用其抓取工具、蜘蛛程序或其他任何内容检查此页面你想给他们起的名字。 要真正从 Google 或任何搜索引擎中获取 URL,请在 HTML 的 <head> 中或通过 HTTP 标头为其添加 noindex 标记。
尽管本文的重点是错误和警告,但让我们快速介绍有效和排除部分。
有效:很简单,这是一个已成功编入索引的 URL 列表。 此处唯一要做的 QA 是针对您的 XML 站点地图,并确保您不会索引您不想要的内容。 为此,只需单击“有效”框(通过一次仅突出显示一个框来消除混淆)并查看“详细信息”部分。
您将遇到两种主要的详细信息类型,“已提交并编入索引”和“已编入索引,未在站点地图中提交”:
- 已提交并编入索引:这是您网站中 Google 确认已成功编入索引的 URL 列表。
- 已编入索引,未在站点地图中提交:这些已编入索引的 URL 未出现在您的 XML 站点地图中。 根据您的站点,通常不应有大量此类。 如果您希望将 URL 编入索引,您应该帮助搜索引擎和您自己,并将它们添加到您的 XML 站点地图中。 如果不确定如何执行此操作,请联系您的数字营销机构,他们可以适当地对您的站点地图进行质量检查。
排除:这些是有意从 Google 索引中排除的网址。 这可以通过许多不同的途径发生,但 Google 认为您的网站已采取措施防止这些 URL 被搜索。 这绝不是问题,并且是健康站点的一部分。 内部资源,例如受密码保护的页面或由 WordPress 站点生成的图像 URL,应排除在索引之外,因为它们对于在线搜索者来说是糟糕的着陆页体验。
有问题吗?
如果您已阅读本文但仍不确定如何处理覆盖范围问题,请致电我们,我们的搜索营销团队将很乐意帮助您解决问题。