
10 Solusi Database Grafik Terbaik untuk Dicoba
Diterbitkan: 2022-08-16Database grafik menyimpan data padat yang sangat terhubung dan memproses kueri secara efisien. Tapi, tahukah Anda kapan harus menggunakan basis data grafik yang mana? Baca untuk mempelajari lebih lanjut.
“Data adalah minyak baru.” Pertumbuhan organisasi mana pun didasarkan pada bagaimana mereka secara efektif menyimpan dan menggunakan data. 2,5 triliun byte data dihasilkan setiap hari. Jadi, kita membutuhkan sistem dan gudang yang toleran terhadap kesalahan di mana data dapat disimpan dan dikelola secara efektif. Awalnya, database relasional digunakan.
Namun seiring berjalannya waktu, jumlah dan jenis data berubah dengan cepat. Oleh karena itu, ada kebutuhan untuk menyimpan video, audio, gambar, dll. Ini adalah titik pemicu untuk pengembangan SQL, database NoSQL, Hadoop, database grafik, dll. Masing-masing memiliki kasus penggunaan sendiri dan menangani format data yang berbeda. Database grafik dikembangkan untuk menyederhanakan operasi pada data dan untuk penyimpanan yang efektif.
Database Grafik
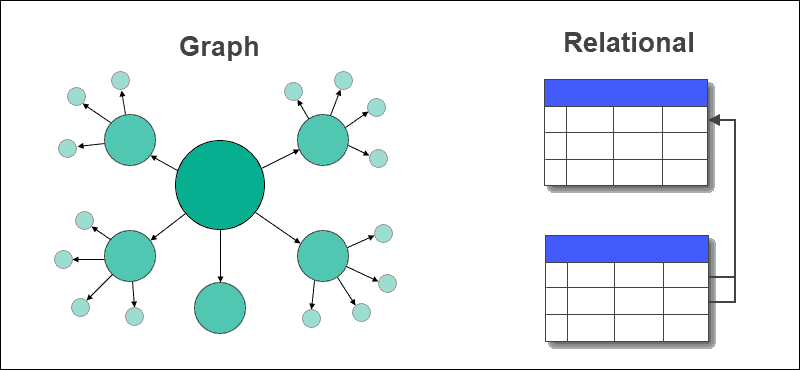
Graf adalah struktur data yang direpresentasikan dalam bentuk node dan edge. Database adalah kumpulan tabel yang menyimpan data dan hubungan antar data. Basis data grafik adalah basis data yang menyimpan data dalam node dan hubungan yang ada di dalam data dalam bentuk tepi. Database grafik membantu menangani kueri waktu nyata dan mengelola hubungan banyak ke banyak antar entitas secara efektif.
Model data grafik yang populer termasuk grafik properti dan grafik RDF. Analisis dan kueri sebagian besar dilakukan menggunakan grafik properti. Integrasi data dilakukan dengan menggunakan grafik RDF. Perbedaan antara graf Properti dan graf RDF adalah graf RDF direpresentasikan dalam bentuk rangkap tiga, yaitu subjek, predikat, dan objek.
Graph database menyimpan data dalam node dan hubungan antar data berupa edge antar node. Sisi-sisi dalam graf dapat berarah (uni-directional) atau tidak berarah (bi-directional).
Pemrosesan query dilakukan dengan melintasi grafik. Algoritma traversal grafik yang membantu menemukan jalur dari satu node ke node lain, jarak antara node, menemukan pola, loop dalam grafik, dan kemungkinan pembentukan cluster, dll., digunakan untuk menjawab pertanyaan secara efektif.

Aplikasi Database Grafik
Database grafik digunakan dalam deteksi penipuan. Node/ entitas dapat berupa nama orang, alamat, tanggal lahir, dll., dan beberapa alamat IP palsu, nomor perangkat, dll. Ketika node palsu berinteraksi dengan node non-penipuan, tautan terbentuk di antara mereka dan ditandai sebagai mencurigakan.
Situs web media sosial menggunakan basis data grafik untuk menunjukkan rekomendasi dari orang-orang yang mungkin ingin kita hubungi dan konten yang ingin kita lihat. Ini dilakukan dengan bantuan traversal grafik dalam database.
Pemetaan jaringan dan manajemen infrastruktur, item konfigurasi, dll., juga disimpan dan dikelola secara efektif menggunakan basis data grafik.
Basis Data Grafik vs. Basis Data Relasional
Dalam database grafik, tabel dengan baris dan kolom diganti dengan node dan edge. Hubungan antara data disimpan di tepi dalam database grafik.
Database relasional menyimpan hubungan antara tabel menggunakan kunci asing dan tabel lainnya. Mengekstrak data atau membuat kueri itu mudah dan tidak memerlukan penggabungan yang rumit dalam database grafik, tetapi tidak demikian halnya dengan database relasional.
Basis data relasional paling cocok untuk kasus penggunaan yang melibatkan transaksi, sedangkan basis data grafik cocok untuk aplikasi yang padat hubungan dan intensif data.
Database grafik mendukung data terstruktur, semi-terstruktur, dan tidak terstruktur, sedangkan database relasional harus memiliki skema tetap.
Basis data grafik memenuhi persyaratan dinamis, sedangkan basis data relasional umumnya digunakan untuk masalah yang diketahui dan statis.
Sekarang mari kita lihat solusi database grafik terbaik.
Cayley
Cayley adalah database grafik open-source yang dikembangkan oleh Apache 2.0. Itu dibangun menggunakan Go dan bekerja pada data yang ditautkan. Cayley adalah database yang digunakan saat membangun Freebase dan grafik pengetahuan Google. Ini mendukung beberapa bahasa kueri seperti MQL dan Javascript dengan objek grafik berbasis Gremlin.

Mudah digunakan, cepat dan memiliki desain modular. Itu dapat mengintegrasikan dan berinteraksi dengan berbagai toko backend seperti LevelDB, MongoDB, dan Bolt. Ini mendukung berbagai API pihak ketiga yang ditulis dalam berbagai bahasa seperti Java, .NET, Rust, Haskell, Ruby, PHP, Javascript, dan Clojure. Itu dapat digunakan di Docker dan Kubernetes. Area utama di mana Cayley digunakan adalah Teknologi Informasi, Perangkat Lunak Komputer, dan Layanan Keuangan.
Amazon Neptunus
Amazon Neptune dikenal berkinerja sangat baik pada kumpulan data yang sangat terhubung. Ini dapat diandalkan, aman, terkelola sepenuhnya, dan mendukung API grafik terbuka. Itu dapat menyimpan miliaran hubungan dan data kueri dengan latensi yang sangat rendah beberapa milidetik.
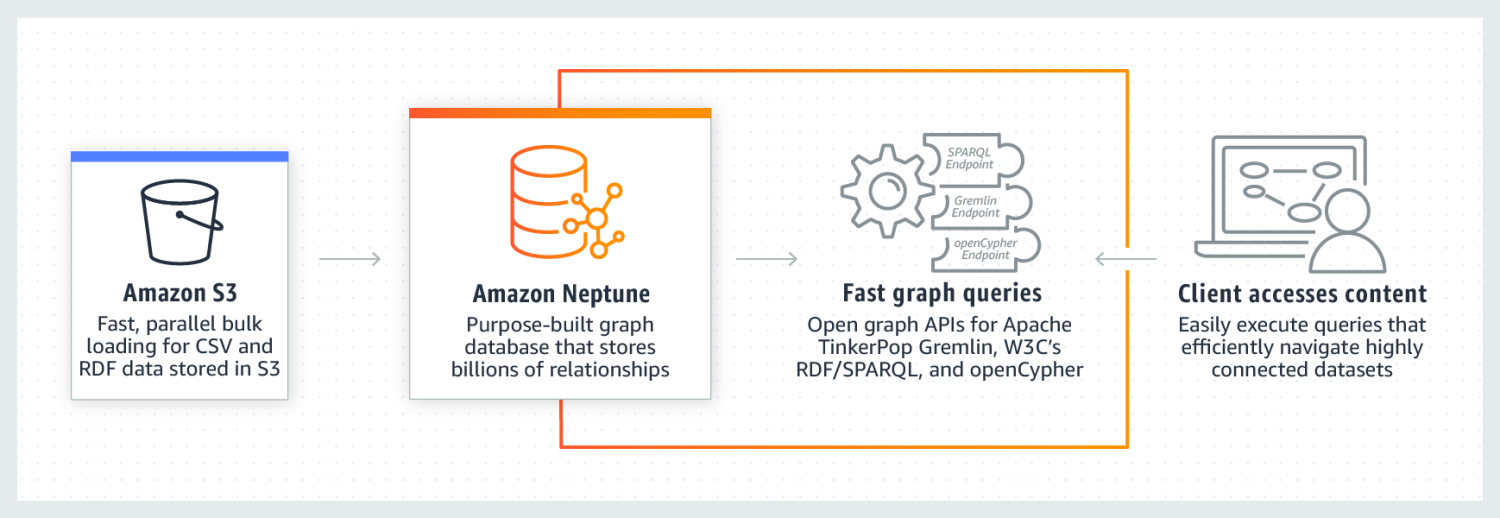
Model data graf Neptunus terdiri dari 4 posisi yaitu subjek (S), predikat (P), objek (O), dan Graf (G). Masing-masing posisi ini digunakan untuk menyimpan posisi node sumber, node target, hubungan di antara mereka, dan propertinya.
Itu juga menggunakan cache yang mempercepat eksekusi kueri membaca. Data disimpan dalam bentuk cluster DB. Setiap cluster terdiri dari instans DB primer dan replika baca instans DB. Neptune sangat aman karena menggunakan Otentikasi IAM, sertifikasi SSL, dan pemantauan log. Memigrasikan data dari sumber lain ke Amazon Neptune juga mudah. Ini juga memastikan ketahanan dengan membuat replika dan pencadangan berkala. Beberapa perusahaan yang menggunakan Neptunus antara lain Herren, Onedot, Juncture, dan Hi Platform.
Neo4j
Neo4j adalah basis data grafik yang dapat diskalakan, aman, sesuai permintaan, dan andal. Neo4j dibangun menggunakan Java, menggunakan Cypher sebagai bahasa query. Ini menggunakan protokol Bolt, dan semua transaksi terjadi melalui titik akhir HTTP. Jauh lebih cepat dalam menjawab pertanyaan dibandingkan dengan database relasional lainnya. Itu tidak memiliki overhead gabungan kompleks, dan pengoptimalannya bekerja dengan baik ketika ukuran kumpulan data besar dan sangat terhubung. Ini menawarkan keuntungan dari penyimpanan grafik bersama dengan properti ACID dari database relasional.

Neo4j mendukung berbagai bahasa seperti Java, .NET, Node.js, Ruby, Python, dll., dengan bantuan driver. Ini juga digunakan dalam ilmu data grafik, analitik, dan alur kerja pembelajaran mesin. Neo4j Aura DB adalah database grafik cloud yang toleran terhadap kesalahan dan terkelola sepenuhnya. Perusahaan seperti Microsoft, Cisco, Adobe, eBay, IBM, Samsung, dll., menggunakan Neo4j.
ArangoDB
ArangoDB adalah database multi-model sumber terbuka. Pendekatan multi-model memungkinkan pengguna untuk menanyakan data dalam bahasa kueri pilihan mereka. Node dan tepi ArangoDB adalah dokumen JSON. Setiap dokumen memiliki id unik. Hubungan antara dua node ditunjukkan dalam bentuk tepi, dan id uniknya disimpan. Performanya yang baik adalah karena adanya indeks hash.


Traversal, bergabung, dan pencarian di database ditingkatkan. Ini membantu dalam merancang, menskalakan, dan beradaptasi dengan berbagai arsitektur. Ini memainkan peran penting dalam tugas-tugas ilmu data yang kompleks seperti ekstraksi fitur dan pencarian lanjutan.
ArrangoDB dapat berjalan di lingkungan berbasis cloud dan kompatibel dengan Mac Os, Linux, dan Windows. LDAP Otentikasi, penyembunyian data, dan algoritma enkripsi memastikan database aman. Ini digunakan dalam manajemen risiko, IAM, deteksi penipuan, infrastruktur jaringan, mesin rekomendasi, dll. Accenture, Cisco, Dish, dan VMware adalah beberapa organisasi yang menggunakan ArangoDB.
DataStax
DataStax adalah database cloud NoSQL sebagai layanan yang dibangun di atas Apache Cassandra. Ini sangat skalabel dan menggunakan arsitektur cloud-native. Hal ini dapat diandalkan dan aman. Setiap dokumen yang disimpan dalam DataStax memiliki indeks yang membantu dalam pencarian yang mudah dan pengambilan data yang cepat. Pecahan dibuat di atas data yang diindeks. Berbagai sumber data dapat digunakan untuk membangun aplikasi dengan alat Datastax Enterprise, Kafka dan Docker.
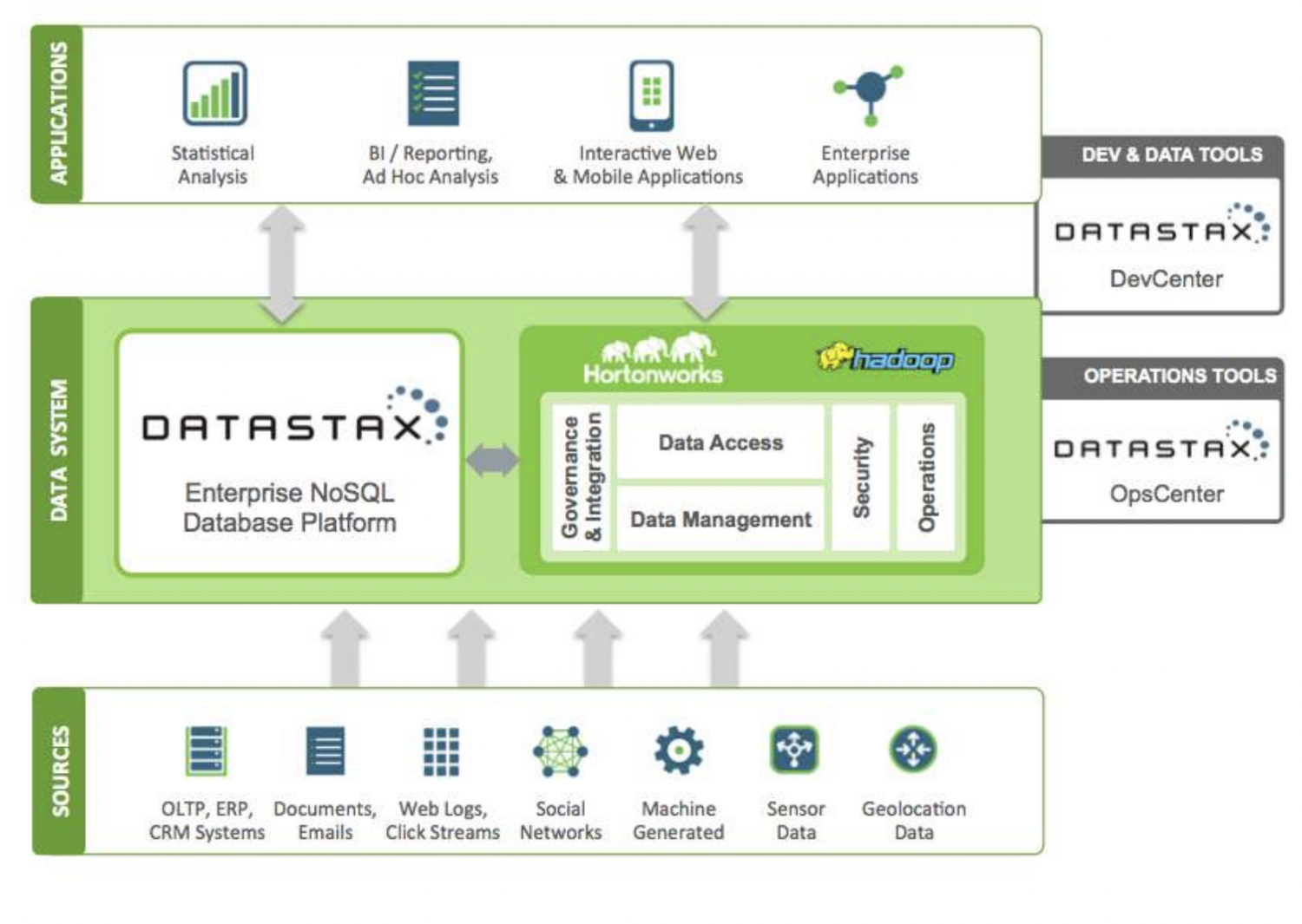
Data yang dikumpulkan dari sumber dikirim ke ekosistem Hadoop dan DataStax. Hadoop mengelola keamanan, operasi, akses data, dan manajemen dengan berinteraksi dengan DataStax. Data disempurnakan menggunakan alat pengembangan dan operasi Datastax.
Informasi yang dianalisis kemudian digunakan untuk analisis statistik, aplikasi perusahaan, Pelaporan, dll. Karena berbasis cloud, pelanggan membayar untuk apa yang mereka gunakan, dan harganya masuk akal. Verizon, CapitalOne, TMobile, dan Overstock adalah beberapa perusahaan yang menggunakan DataStax.
Orient DB
OrientDB adalah database grafik yang mengelola data secara efektif dan membantu membuat representasi visual untuk menampilkan data. Ini adalah database grafik multi-model dan dibangun menggunakan Java. Ini menyimpan data dalam bentuk pasangan nilai kunci, dokumen, model objek, dll. Ini terdiri dari 3 komponen penting: editor grafik, kueri studio, dan konsol baris perintah.
Editor grafik digunakan untuk memvisualisasikan dan berinteraksi dengan data. Antarmuka kueri Studio digunakan untuk mengeksekusi kueri dan memberikan output segera dalam format gambar dan tabel. Konsol baris perintah digunakan untuk meminta data dari OrientDB. Ini memiliki arsitektur terdistribusi dengan beberapa server yang dapat melakukan operasi baca dan tulis. Server replika digunakan untuk melakukan operasi baca dan kueri. Ini mendukung pengindeksan dan juga sesuai dengan ACID. Beberapa perusahaan yang menggunakan OrientDB adalah Comcast Corporation dan Blackfriars Group.
Dgrafik
Dgraph adalah database grafik awan yang mendukung GraphQL. Itu dibangun menggunakan Go. Ini meminimalkan panggilan jaringan dan mengurangi latensi dengan memaksimalkan pemrosesan kueri bersamaan. Integrasi Dgraph yang mulus dengan GraphQL membantu pengembangan aplikasi backend GraphQL dengan mudah.

Mutasi GraphQL dilewatkan melalui fungsi Lambda yang berinteraksi dengan database dan saluran data. Ini menyederhanakan pemrosesan kueri. Ini dapat diskalakan secara horizontal, artinya jumlah sumber daya meningkat dengan meningkatnya kueri dan data. Ini menyediakan berbagai fitur seperti otorisasi berbasis JWT, visualisator data, otentikasi cloud, cadangan data, dll. Beberapa organisasi yang menggunakan Dgraph termasuk Intuit, intel, dan Factset.
Tigergraph
Tigergraph adalah database grafik properti yang dikembangkan menggunakan C++. Ini sangat skalabel dan melakukan analitik tingkat lanjut pada data yang sangat terhubung. Ini menggunakan struktur grafik asli untuk penyimpanan data dan mesin pengolah grafik untuk memproses data. Basis data disimpan di disk dan di memori dan juga menggunakan cache CPU untuk pengambilan cepat. Ini menggunakan fungsi Pengurangan Peta untuk pemrosesan data paralel.
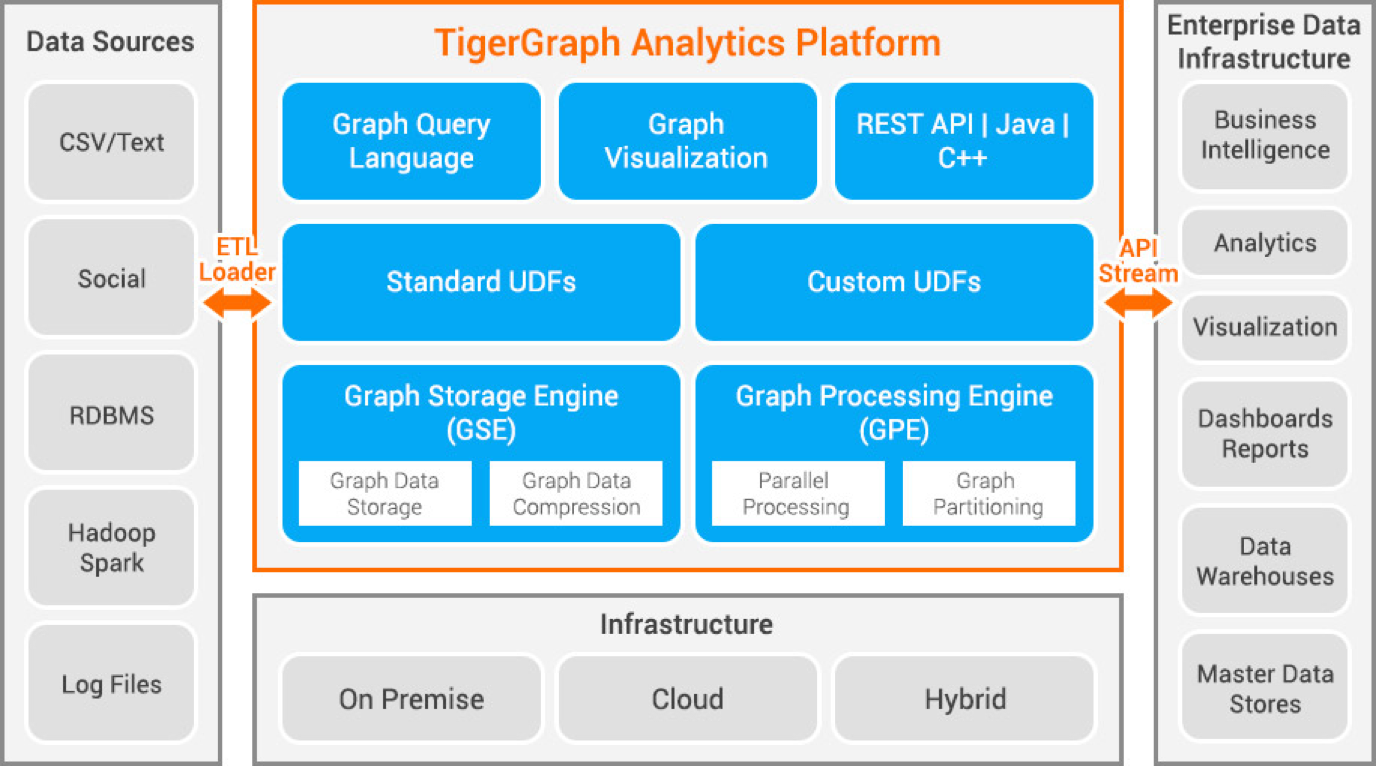
Ini sangat cepat dan terukur. Itu melakukan komputasi paralel dan menyediakan pembaruan waktu nyata. Ini menggunakan teknik kompresi data dan kompres data 10x. Ini mempartisi data di seluruh server secara otomatis, menghemat waktu dan upaya pengguna yang diperlukan untuk melakukan sharding data secara manual. Ini digunakan untuk mendeteksi penipuan di rumah tangga, manajemen rantai pasokan, dan meningkatkan perawatan kesehatan. JPMorgan Chase, Intuit, dan United Health Group adalah beberapa organisasi yang menggunakan Tigergraph.
AllegroGraph
AllegroGraph menggunakan teknologi grafik pengetahuan peristiwa entitas untuk melakukan analisis dan keputusan pada data yang sangat terhubung, kompleks, dan padat. Data disimpan dalam format JSON dan JSON-LD di node grafik. Ini menggunakan arsitektur protokol REST. Ini juga menangani kumpulan data yang sangat besar dengan membagi data berdasarkan kriteria tertentu dan menyebarkannya ke beberapa repositori basis pengetahuan.
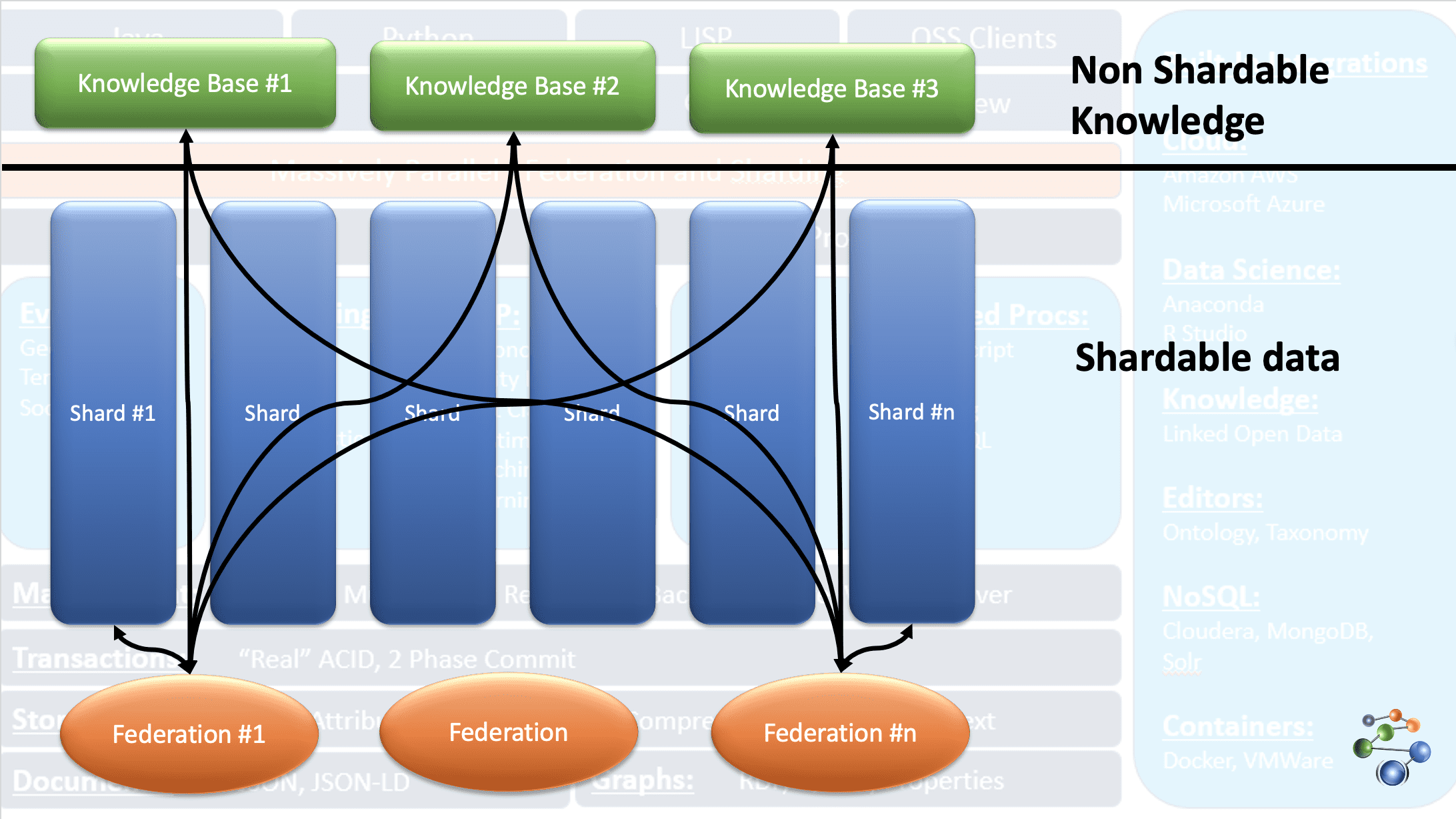
Ini dimungkinkan karena fitur FedShard dari database AllegroGraph. Eksekusi kueri dilakukan dengan menggabungkan federasi dengan repositori basis pengetahuan. Ini mendukung jenis skema XML dan menggunakan indeks rangkap tiga. Ini menyimpan data geospasial seperti lintang & bujur dan data temporal seperti tanggal, stempel waktu, dll. Ini juga kompatibel dengan Windows, Mac, dan Linux. Ini digunakan dalam deteksi penipuan, perawatan kesehatan, identifikasi entitas, prediksi risiko, dll.
anjing bintang
Stardog adalah database grafik yang melakukan virtualisasi data grafik dan menghubungkan data dari gudang data dan data lake tanpa menyalin data secara fisik ke lokasi penyimpanan baru. Stardog dibangun di atas standar terbuka RDF. Ini mendukung data terstruktur, semi-terstruktur, dan tidak terstruktur. Perwujudan seperti ini yang dilakukan oleh Stardog menawarkan fleksibilitas. Ini adalah satu-satunya basis data grafik yang menggabungkan grafik pengetahuan dan virtualisasi.

Stardog menggunakan mesin inferensi yang didukung oleh AI untuk memproses dan menyediakan keluaran kueri secara efisien. Ini adalah database grafik yang sesuai dengan ACID. Membaca dan menulis secara bersamaan didukung. Ini menangani pertanyaan kompleks dengan mudah karena arsitektur "canggih". Ini digunakan dalam Manajemen Aset TI, manajemen data & analitik dan menyediakan ketersediaan tinggi. Beberapa perusahaan yang menggunakan Stardog adalah Cisco, eBay, NASA, dan Finra.
Kata-kata terakhir
Database grafik membantu untuk menanyakan hubungan banyak ke banyak dengan mudah dan menyimpan data secara efektif. Mereka dapat diskalakan, aman, dan dapat diintegrasikan dengan banyak alat, API, dan bahasa pihak ketiga. Dalam beberapa tahun terakhir, mereka telah terintegrasi dengan cloud dan memberikan kinerja terbaik.
Mereka menyederhanakan gabungan kompleks menjadi kueri sederhana sehingga menjadi tugas yang mudah bagi pengembang. Tugas intensif data seperti IoT dan Big Data juga merupakan basis data grafik. Ini akan terus berkembang dan pasti akan berkembang ke kasus penggunaan lain di masa depan.