
10 лучших решений для графических баз данных, которые стоит попробовать
Опубликовано: 2022-08-16Базы данных Graph хранят плотно связанные данные и эффективно обрабатывают запросы. Но знаете ли вы, когда какую базу данных графов использовать? Читайте, чтобы узнать больше.
«Данные — это новая нефть». Рост любой организации зависит от того, как они эффективно хранят и используют данные. Каждый день генерируется 2,5 квинтиллиона байтов данных. Итак, нам нужны отказоустойчивые системы и хранилища, где можно эффективно хранить данные и управлять ими. Первоначально использовались реляционные базы данных.
Но со временем количество и тип данных быстро изменились. Следовательно, возникла потребность в хранении видео, аудио, изображений и т. д. Это послужило отправной точкой для разработки SQL, баз данных NoSQL, Hadoop, графовых баз данных и т. д. Каждый из них имеет свои варианты использования и имеет дело с разными форматами данных. Графовые базы данных были разработаны для упрощения операций с данными и для эффективного хранения.
Графические базы данных
Граф — это структура данных, представленная в виде узлов и ребер. База данных — это набор таблиц, в которых хранятся данные и отношения между данными. База данных графа — это база данных, которая хранит данные в узлах и отношения, существующие в данных, в виде ребер. Базы данных графов помогают обрабатывать запросы в реальном времени и эффективно управлять отношениями «многие ко многим» между сущностями.
Популярные графовые модели данных включают графы свойств и графы RDF. Аналитика и запросы в основном выполняются с использованием графиков свойств. Интеграция данных осуществляется с использованием графиков RDF. Отличие графов Property от RDF состоит в том, что RDF-графы представлены в виде троек, т. е. субъекта, предиката и объекта.
Базы данных графов хранят данные в узлах и отношения между данными в виде ребер между узлами. Ребра в графе могут быть направленными (однонаправленными) или ненаправленными (двунаправленными).
Обработка запросов выполняется путем обхода графа. Для эффективного ответа на запросы используются алгоритмы обхода графа, помогающие найти путь от одного узла к другому, расстояние между узлами, найти закономерности, петли внутри графа, возможность формирования кластеров и т. д.

Приложения графических баз данных
Базы данных графов используются для обнаружения мошенничества. Узлы/сущности могут быть именами людей, адресами, датами рождения и т. д., а также некоторыми мошенническими IP-адресами, номерами устройств и т. д. Когда мошеннический узел взаимодействует с немошенническим узлом, между ними формируются связи, которые помечаются как подозрительный.
Веб-сайты социальных сетей используют графические базы данных, чтобы показывать рекомендации людей, с которыми мы хотели бы связаться, и контент, который мы хотим просмотреть. Это делается с помощью обхода графа в базе данных.
Сетевое картографирование и управление инфраструктурой, элементы конфигурации и т. д. также эффективно хранятся и управляются с помощью графовых баз данных.
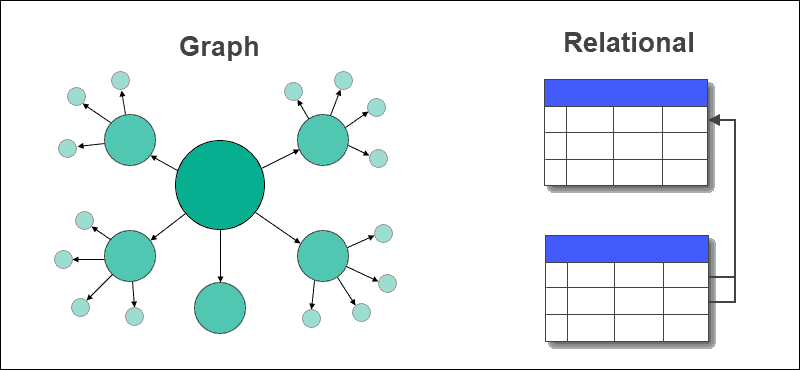
Графовая база данных против реляционной базы данных
В графовой базе данных таблицы со строками и столбцами заменяются узлами и ребрами. Отношения между данными хранятся на ребрах в базе данных графа.
Реляционная база данных хранит связи между таблицами с помощью внешних ключей и другими таблицами. Извлечение данных или выполнение запросов просты и не требуют сложных соединений в графовой базе данных, но это не относится к реляционным базам данных.
Реляционные базы данных больше всего подходят для случаев использования, связанных с транзакциями, тогда как графовые базы данных подходят для приложений с большим количеством отношений и данных.
Графовые базы данных поддерживают структурированные, полуструктурированные и неструктурированные данные, тогда как реляционные базы данных должны иметь фиксированную схему.
Графовые базы данных удовлетворяют динамическим требованиям, тогда как реляционные базы данных обычно используются для известных и статических задач.
Давайте теперь посмотрим на лучшие решения для графовых баз данных.
Кэли
Cayley — графовая база данных с открытым исходным кодом, разработанная Apache 2.0. Он был построен с использованием Go и работает со связанными данными. Cayley — это база данных, используемая при построении Freebase и графика знаний Google. Он поддерживает несколько языков запросов, таких как MQL и Javascript, с графическим объектом на основе Gremlin.

Он прост в использовании, быстр и имеет модульную конструкцию. Он может интегрироваться и взаимодействовать с различными серверными хранилищами, такими как LevelDB, MongoDB и Bolt. Он поддерживает различные сторонние API, написанные на нескольких языках, таких как Java, .NET, Rust, Haskell, Ruby, PHP, Javascript и Clojure. Его можно развернуть в Docker и Kubernetes. Ключевыми областями, в которых используется Cayley, являются информационные технологии, компьютерное программное обеспечение и финансовые услуги.
Амазонка Нептун
Amazon Neptune известен своей исключительно высокой производительностью при работе с наборами данных с высокой степенью подключения. Он надежен, безопасен, полностью управляем и поддерживает API с открытым графом. Он может хранить миллиарды взаимосвязей и запрашивать данные с чрезвычайно низкой задержкой в несколько миллисекунд.
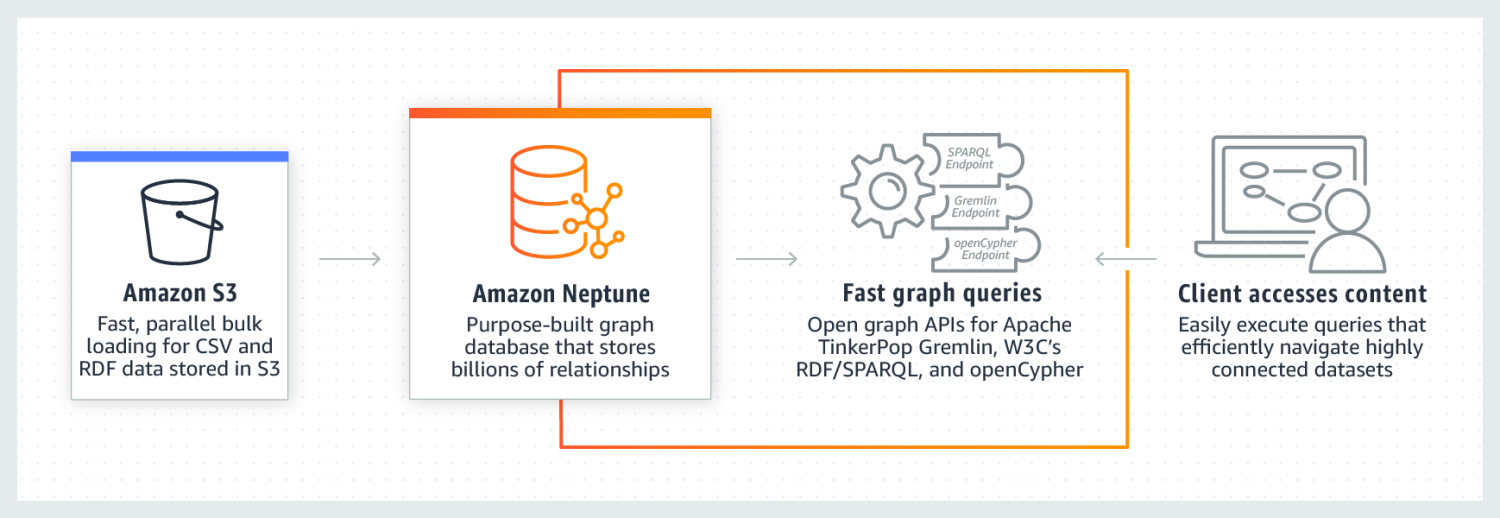
Модель данных графа Neptune состоит из 4 позиций, а именно: субъекта (S), предиката (P), объекта (O) и графа (G). Каждая из этих позиций используется для хранения позиции исходного узла, целевого узла, отношения между ними и их свойств.
Он также использует кеш, который ускоряет выполнение запросов на чтение. Данные хранятся в виде кластеров БД. Каждый кластер состоит из основного экземпляра БД и реплик чтения экземпляров БД. Neptune обладает высокой степенью безопасности, поскольку использует аутентификацию IAM, сертификацию SSL и мониторинг журналов. Также легко перенести данные из других источников в Amazon Neptune. Он также обеспечивает отказоустойчивость за счет создания реплик и периодического резервного копирования. Некоторые компании, использующие Neptune, включают Herren, Onedot, Juncture и Hi Platform.
Нео4дж
Neo4j — это масштабируемая, безопасная, доступная по запросу и надежная база данных графов. Neo4j был построен с использованием Java, используя Cypher в качестве языка запросов. Он использует протокол Bolt, и все транзакции происходят через конечную точку HTTP. Он намного быстрее отвечает на запросы по сравнению с другими реляционными базами данных. У него нет накладных расходов, связанных со сложными соединениями, а его оптимизация хорошо работает, когда размер набора данных велик и имеет высокую степень связанности. Он предлагает преимущество хранения графов наряду со свойствами ACID реляционной базы данных.

Neo4j поддерживает различные языки, такие как Java, .NET, Node.js, Ruby, Python и т. д., с помощью драйверов. Он также используется в графических данных, аналитике и рабочих процессах машинного обучения. Neo4j Aura DB — это отказоустойчивая и полностью управляемая база данных облачного графа. Такие компании, как Microsoft, Cisco, Adobe, eBay, IBM, Samsung и другие, используют Neo4j.
АрангоДБ
ArangoDB — многомодельная база данных с открытым исходным кодом. Мультимодельный подход позволяет пользователям запрашивать данные на любом языке запросов по своему выбору. Узлы и ребра ArangoDB представляют собой документы JSON. Каждый документ имеет уникальный идентификатор. Отношения между двумя узлами указываются в виде ребер, а их уникальные идентификаторы сохраняются. Его хорошая производительность обусловлена наличием хэш-индекса.


Обходы, соединения и поиск в базах данных улучшены. Это помогает в проектировании, масштабировании и адаптации к различным архитектурам. Он играет важную роль в сложных задачах науки о данных, таких как извлечение признаков и расширенный поиск.
ArrangoDB может работать в облачной среде и совместим с Mac Os, Linux и Windows. Аутентификация LDAP, маскирование данных и алгоритмы шифрования обеспечивают безопасность базы данных. Он используется в управлении рисками, IAM, обнаружении мошенничества, сетевой инфраструктуре, механизмах рекомендаций и т. д. Accenture, Cisco, Dish и VMware — некоторые организации, использующие ArangoDB.
ДатаСтакс
DataStax — это облачная база данных NoSQL как услуга, построенная на Apache Cassandra. Он легко масштабируется и использует облачную архитектуру. Это надежно и безопасно. Каждый документ, хранящийся в DataStax, имеет индекс, который упрощает поиск и быстрый поиск данных. Осколки создаются на основе индексированных данных. Для создания приложений с помощью инструментов Datastax Enterprise, Kafka и Docker можно использовать различные источники данных.
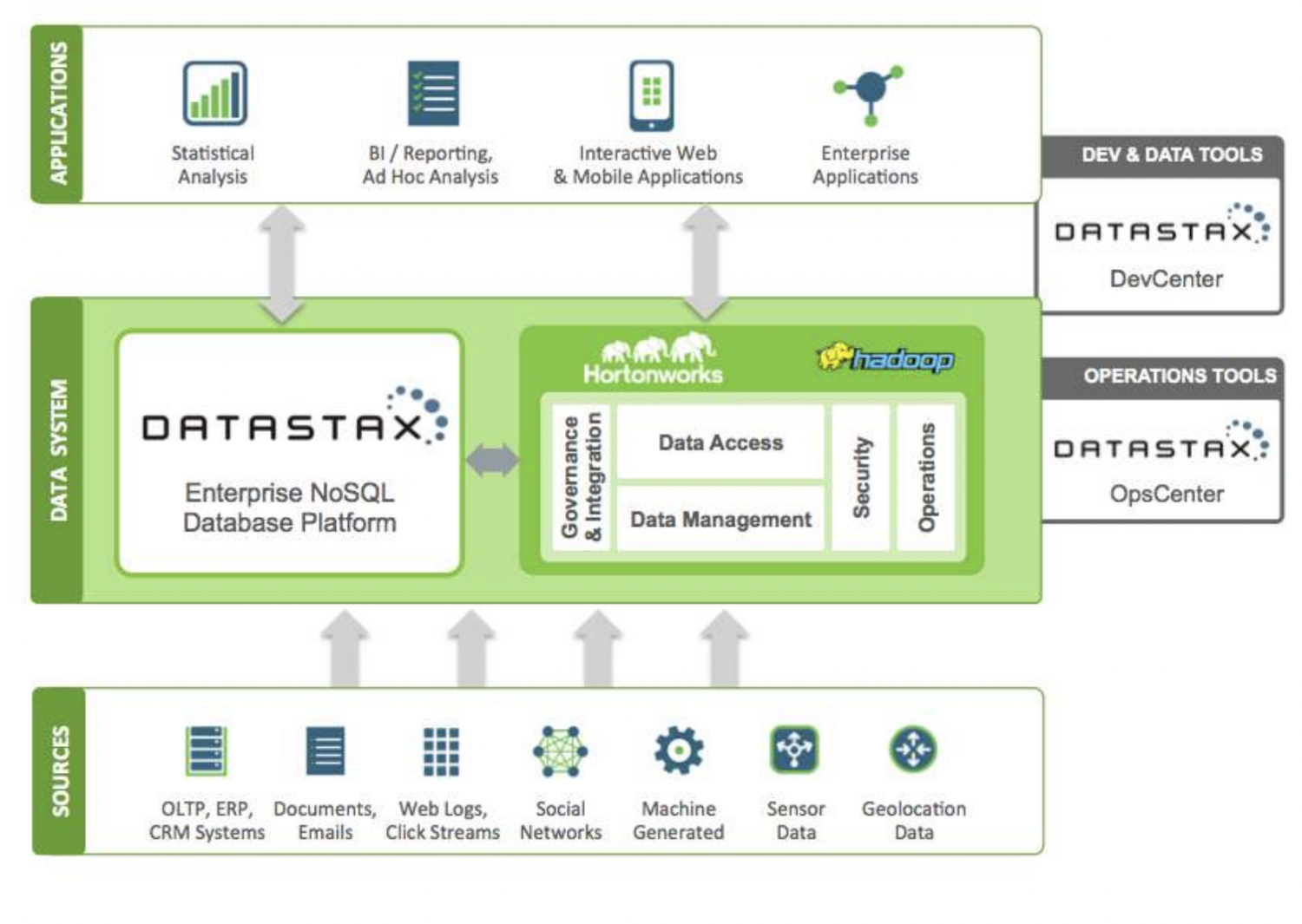
Данные, собранные из источников, отправляются в экосистему Hadoop и DataStax. Hadoop управляет безопасностью, операциями, доступом к данным и управлением, взаимодействуя с DataStax. Данные уточняются с помощью инструментов разработки и эксплуатации Datastax.
Проанализированная информация затем используется для статистического анализа, корпоративных приложений, отчетов и т. д. Поскольку это облачное решение, клиенты платят за то, что используют, и цены являются разумными. Verizon, CapitalOne, TMobile и Overstock — некоторые компании, которые используют DataStax.
Ориент БД
OrientDB — это графическая база данных, которая эффективно управляет данными и помогает создавать визуальные представления для демонстрации данных. Это многомодельная графовая база данных, построенная с использованием Java. Он хранит данные в виде пар ключ-значение, документов, объектных моделей и т. д. Он состоит из 3 важных компонентов: графического редактора, студийного запроса и консоли командной строки.
Графический редактор используется для визуализации данных и взаимодействия с ними. Интерфейс запросов Studio используется для выполнения запросов и немедленного предоставления результатов в графическом и табличном формате. Консоль командной строки используется для запроса данных из OrientDB. Он имеет распределенную архитектуру с несколькими серверами, которые могут выполнять операции чтения и записи. Серверы-реплики используются для выполнения операций чтения и запросов. Он поддерживает индексирование, а также совместим с ACID. Некоторые из компаний, использующих OrientDB, — это Comcast Corporation и Blackfriars Group.
Дграф
Dgraph — это база данных облачных графов, поддерживающая GraphQL. Он был построен с использованием Go. Он сводит к минимуму сетевые вызовы и уменьшает задержку за счет максимальной параллельной обработки запросов. Полная интеграция Dgraph с GraphQL упрощает разработку серверных приложений GraphQL.

Мутация GraphQL передается через функцию Lambda, которая взаимодействует с базой данных и конвейером данных. Это упрощает обработку запросов. Он масштабируется по горизонтали, что означает, что количество ресурсов увеличивается с увеличением количества запросов и данных. Он предоставляет различные функции, такие как авторизация на основе JWT, визуализатор данных, облачная аутентификация, резервное копирование данных и т. д. Некоторые организации, использующие Dgraph, включают Intuit, Intel и Factset.
Тигрограф
Tigergraph — это база данных графов свойств, разработанная с использованием C++. Он обладает высокой масштабируемостью и выполняет расширенную аналитику высокосвязанных данных. Он использует собственную структуру графа для хранения данных и механизм обработки графов для обработки данных. База данных хранится на диске и в памяти, а также использует кэш процессора для быстрого поиска. Он использует функцию Map Reduce для параллельной обработки данных.
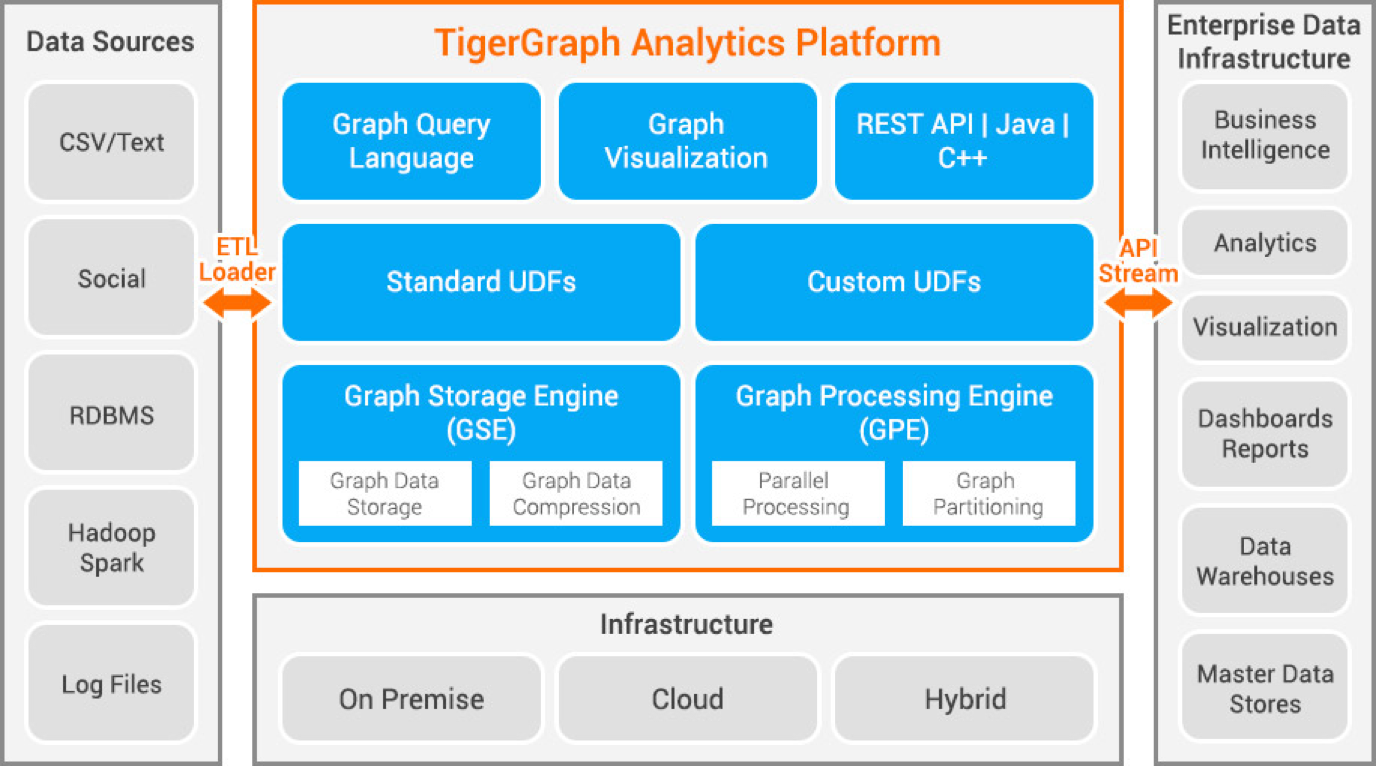
Это очень быстро и масштабируемо. Он выполняет параллельные вычисления и предоставляет обновления в реальном времени. Он использует методы сжатия данных и сжимает данные в 10 раз. Он автоматически распределяет данные между серверами, экономя время и усилия пользователя, необходимые для разделения данных вручную. Он используется для обнаружения мошенничества в домашних хозяйствах, управления цепочками поставок и улучшения здравоохранения. JPMorgan Chase, Intuit и United Health Group — некоторые организации, использующие Tigergraph.
АллегроГраф
AllegroGraph использует технологию графов знаний о сущностях и событиях для выполнения аналитики и принятия решений по высокосвязанным, сложным и плотным данным. Данные хранятся в формате JSON и JSON-LD в узлах графа. Он использует архитектуру протокола REST. Он также работает с очень большими наборами данных, разбивая данные на основе определенных критериев и распределяя их по нескольким репозиториям базы знаний.
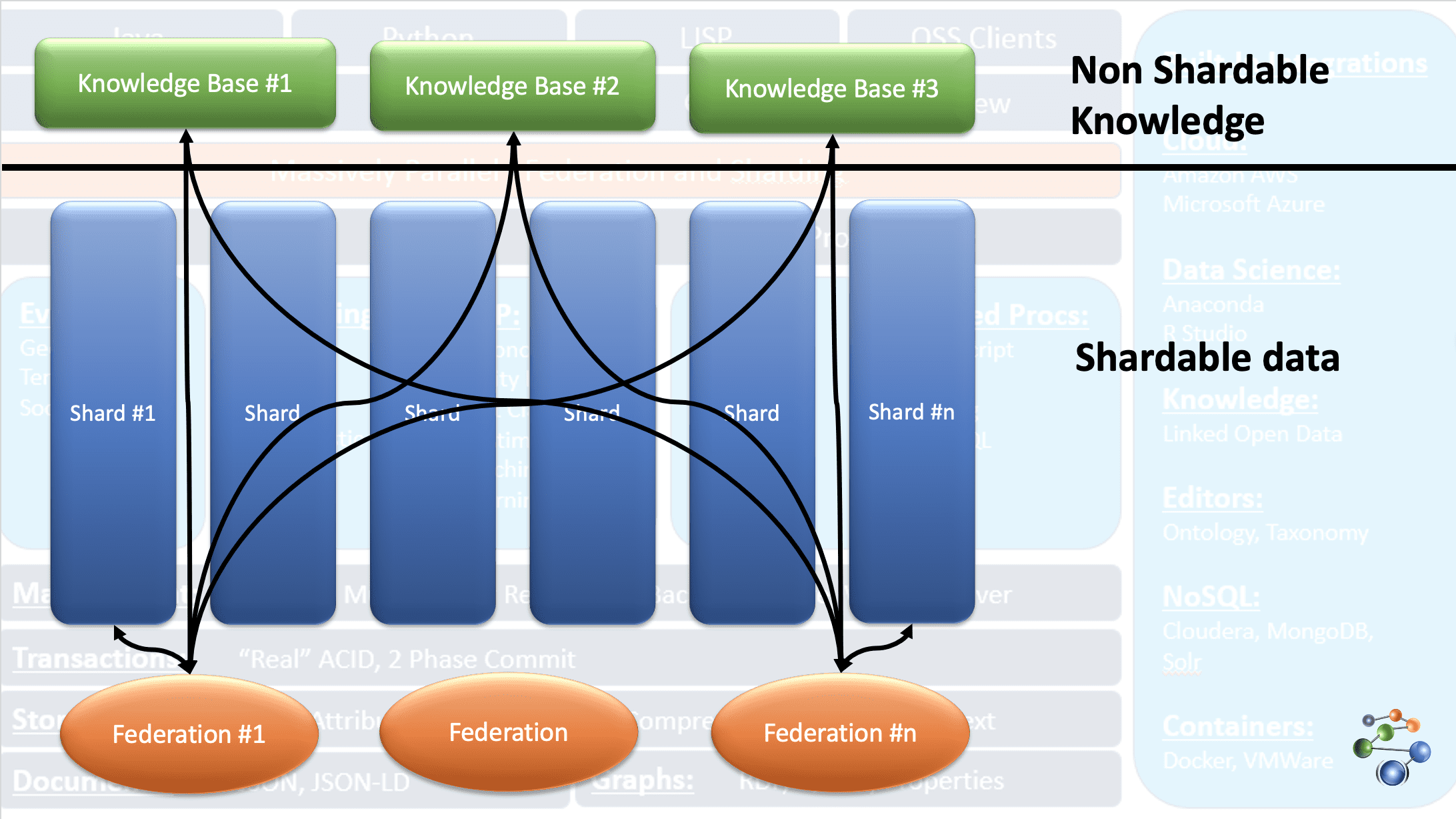
Это возможно благодаря функции FedShard базы данных AllegroGraph. Выполнение запросов происходит путем объединения федераций с репозиториями баз знаний. Он поддерживает типы схемы XML и использует тройные индексы. Он хранит геопространственные данные, такие как широта и долгота, и временные данные, такие как дата, метка времени и т. д. Он также совместим с Windows, Mac и Linux. Он используется для обнаружения мошенничества, здравоохранения, идентификации объектов, прогнозирования рисков и т. д.
Стардог
Stardog — это графовая база данных, которая выполняет виртуализацию графовых данных и связывает данные из хранилищ данных и озер данных без физического копирования данных в новое место хранения. Stardog построен на открытых стандартах RDF. Он поддерживает структурированные, полуструктурированные и неструктурированные данные. Этот вид материализации, сделанный Stardog, обеспечивает гибкость. Это единственная графовая база данных, сочетающая графы знаний и виртуализацию.

Stardog использует механизм логического вывода на основе ИИ для эффективной обработки и предоставления результатов запросов. Это графовая база данных, совместимая с ACID. Одновременное чтение и запись поддерживаются. Он легко обрабатывает сложные запросы благодаря «современной» архитектуре. Он используется в управлении ИТ-активами, управлении данными и аналитике и обеспечивает высокую доступность. Некоторыми компаниями, которые используют Stardog, являются Cisco, eBay, NASA и Finra.
Заключительные слова
Базы данных графов помогают легко запрашивать отношения «многие ко многим» и эффективно хранить данные. Они масштабируемы, безопасны и могут быть интегрированы со многими сторонними инструментами, API и языками. В последние годы они были интегрированы с облаком и обеспечивают наилучшую производительность.
Они упрощают сложные объединения в простые запросы, упрощая задачу для разработчиков. Задачи с интенсивным использованием данных, такие как Интернет вещей и большие данные, также являются базами данных графов. Они будут продолжать развиваться и, несомненно, будут расширены на другие варианты использования в будущем.