
試してみる 10 の最高のグラフ データベース ソリューション
公開: 2022-08-16グラフ データベースは、高度に接続された密なデータを格納し、クエリを効率的に処理します。 しかし、どのグラフデータベースをいつ使用するか知っていますか? 詳細については、こちらをご覧ください。
「データは新しい石油です。」 組織の成長は、データを効果的に保存および使用する方法に基づいています。 毎日 250 京バイトのデータが生成されています。 そのため、データを効果的に保存および管理できるフォールト トレラントなシステムとウェアハウスが必要です。 当初は、リレーショナル データベースが使用されていました。
しかし、時が経つにつれ、データの量と種類は急速に変化しました。 したがって、ビデオ、オーディオ、画像などを保存する必要がありました。これが、SQL、NoSQL データベース、Hadoop、グラフ データベースなどの開発のトリガー ポイントでした。それぞれに独自のユース ケースがあり、さまざまなデータ形式を処理します。 グラフ データベースは、データの操作を簡素化し、効果的なストレージを実現するために開発されました。
グラフ データベース
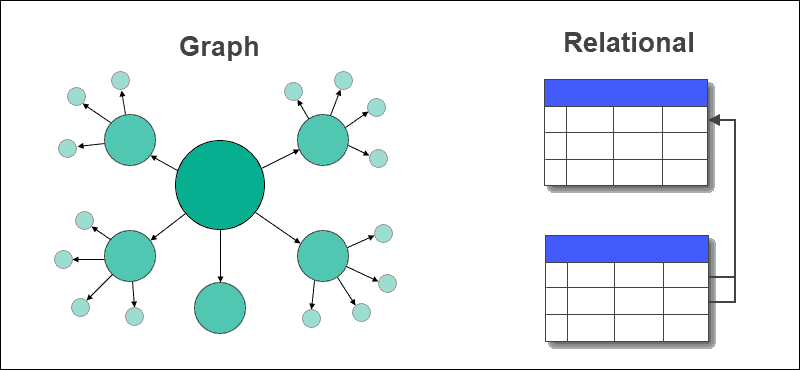
グラフは、ノードとエッジの形式で表されるデータ構造です。 データベースは、データとデータ間の関係を格納するテーブルのコレクションです。 グラフ データベースは、データをノードに格納し、データ内に存在する関係をエッジの形で格納するデータベースです。 グラフ データベースは、リアルタイムのクエリを処理し、エンティティ間の多対多の関係を効果的に管理するのに役立ちます。
一般的なグラフ データ モデルには、プロパティ グラフと RDF グラフが含まれます。 分析とクエリは、ほとんどの場合、プロパティ グラフを使用して行われます。 データ統合は、RDF グラフを使用して行われます。 プロパティ グラフと RDF グラフの違いは、RDF グラフがトリプル、つまり主語、述語、目的語の形式で表現されることです。
グラフ データベースは、データをノードに格納し、データ間の関係をノード間のエッジの形で格納します。 グラフのエッジは、有向 (単方向) または無向 (双方向) にすることができます。
クエリ処理は、グラフをトラバースすることによって行われます。 あるノードから別のノードへのパス、ノード間の距離、パターンの検索、グラフ内のループ、クラスター形成の可能性などを見つけるのに役立つグラフ トラバーサル アルゴリズムは、クエリに効果的に回答するために使用されます。

グラフデータベースの応用
グラフ データベースは不正検出に使用されます。 ノード/エンティティは、人々の名前、住所、生年月日などである可能性があり、不正な IP アドレス、デバイス番号などもあります。不正なノードが不正でないノードと対話すると、それらの間にリンクが形成され、次のようにマークされます。疑わしい。
ソーシャル メディアの Web サイトでは、グラフ データベースを使用して、つながりを持ちたいと考えている人々や閲覧したいコンテンツの推奨事項を表示しています。 これは、データベース内のグラフ トラバーサルを利用して行われます。
ネットワーク マッピングとインフラストラクチャ管理、構成アイテムなども、グラフ データベースを使用して効果的に保存および管理されます。
グラフ データベースとリレーショナル データベース
グラフ データベースでは、行と列を持つテーブルがノードとエッジに置き換えられます。 データ間の関係は、グラフ データベースのエッジに格納されます。
リレーショナル データベースは、外部キーを使用するテーブルと他のテーブルとの間の関係を格納します。 データの抽出やクエリは簡単で、グラフ データベースでは複雑な結合は必要ありませんが、リレーショナル データベースではそうではありません。
リレーショナル データベースはトランザクションを伴うユース ケースに最も適していますが、グラフ データベースは関係が多く、データ集約型のアプリケーションに適しています。
グラフ データベースは構造化データ、半構造化データ、および非構造化データをサポートしますが、リレーショナル データベースは固定のスキーマを持つ必要があります。
グラフ データベースは動的な要件を満たしますが、リレーショナル データベースは通常、既知の静的な問題に使用されます。
それでは、最適なグラフ データベース ソリューションを見てみましょう。
ケイリー
Cayley は、Apache 2.0 によって開発されたオープンソースのグラフ データベースです。 Go を使用して構築され、リンクされたデータで動作します。 Cayley は、Google の Freebase とナレッジ グラフを構築する際に使用されるデータベースです。 MQL や Javascript などの複数のクエリ言語をサポートし、Gremlin ベースのグラフ オブジェクトを使用します。

使いやすく、高速で、モジュール設計になっています。 LevelDB、MongoDB、Bolt などのさまざまなバックエンド ストアと統合して対話できます。 Java、.NET、Rust、Haskell、Ruby、PHP、Javascript、Clojure などの複数の言語で記述されたさまざまなサードパーティ API をサポートしています。 Docker と Kubernetes にデプロイできます。 Cayley が使用される主な分野は、情報技術、コンピューター ソフトウェア、および金融サービスです。
アマゾン海王星
Amazon Neptune は、高度に接続されたデータセットで非常に優れたパフォーマンスを発揮することで知られています。 信頼性が高く、安全で、完全に管理されており、オープン グラフ API をサポートしています。 数ミリ秒という非常に短いレイテンシーで、数十億のリレーションシップとクエリ データを格納できます。
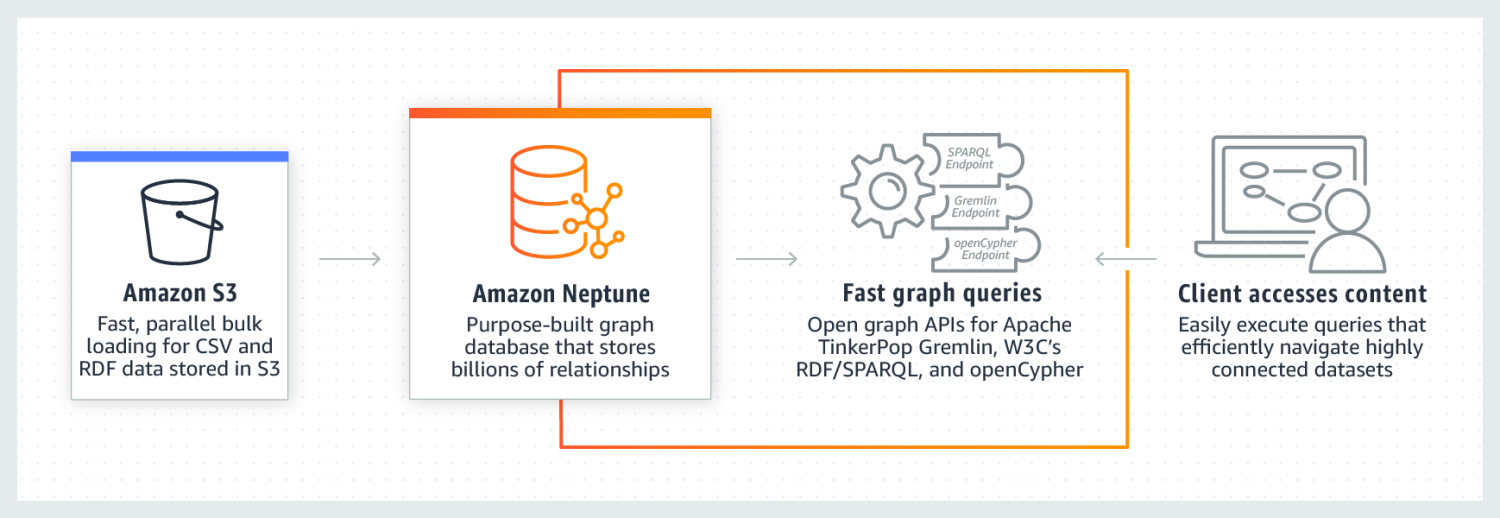
Neptune グラフ データ モデルは、主語 (S)、述語 (P)、目的語 (O)、およびグラフ (G) の 4 つの位置で構成されます。 これらの各位置は、ソース ノード、ターゲット ノード、それらの間の関係、およびそれらのプロパティの位置を格納するために使用されます。
また、読み取りクエリの実行を高速化するキャッシュも使用します。 データは DB クラスターの形式で保存されます。 各クラスターは、プライマリ DB インスタンスと DB インスタンスのリードレプリカで構成されます。 Neptune は、IAM 認証、SSL 証明書、およびログ監視を使用するため、非常に安全です。 他のソースから Amazon Neptune にデータを移行することも簡単です。 また、レプリカと定期的なバックアップを作成することで回復力を確保します。 Neptune を使用している企業には、Herren、Onedot、Juncture、Hi Platform などがあります。
Neo4j
Neo4j は、スケーラブルで安全、オンデマンドで信頼性の高いグラフ データベースです。 Neo4j は、クエリ言語として Cypher を使用して、Java を使用して構築されました。 これは Bolt プロトコルを使用し、すべてのトランザクションは HTTP エンドポイントを介して発生します。 他のリレーショナル データベースと比較して、クエリへの応答がはるかに高速です。 複雑な結合のオーバーヘッドがなく、その最適化は、データ セットのサイズが大きく、高度に接続されている場合にうまく機能します。 これは、リレーショナル データベースの ACID プロパティと共に、グラフ ストレージの利点を提供します。

Neo4j は、ドライバーの助けを借りて、Java、.NET、Node.js、Ruby、Python などのさまざまな言語をサポートします。 また、グラフ データ サイエンス、分析、機械学習のワークフローでも使用されます。 Neo4j Aura DB は、フォールト トレラントで完全に管理されたクラウド グラフ データベースです。 Microsoft、Cisco、Adobe、eBay、IBM、Samsung などの企業は、Neo4j を使用しています。

ArangoDB
ArangoDB は、オープンソースのマルチモデル データベースです。 マルチモデル アプローチにより、ユーザーは任意のクエリ言語でデータをクエリできます。 ArangoDB のノードとエッジは JSON ドキュメントです。 すべてのドキュメントには一意の ID があります。 2 つのノード間の関係はエッジの形で示され、それらの一意の ID が保存されます。 その優れたパフォーマンスは、ハッシュ インデックスの存在によるものです。

データベース内のトラバーサル、結合、および検索が強化されました。 さまざまなアーキテクチャの設計、スケーリング、および適応に役立ちます。 特徴抽出や高度な検索などの複雑なデータ サイエンス タスクで重要な役割を果たします。
ArrangoDB はクラウドベースの環境で実行でき、Mac Os、Linux、および Windows と互換性があります。 LDAP 認証、データ マスキング、および暗号化アルゴリズムにより、データベースのセキュリティが確保されます。 リスク管理、IAM、不正検出、ネットワーク インフラストラクチャ、レコメンデーション エンジンなどで使用されています。Accenture、Cisco、Dish、および VMware は、ArangoDB を使用している組織の一部です。
データスタックス
DataStax は、Apache Cassandra 上に構築されたサービスとしての NoSQL クラウド データベースです。 スケーラビリティが高く、クラウドネイティブ アーキテクチャを使用します。 信頼性が高く安全です。 DataStax に保存されているすべてのドキュメントには、データの検索と高速な取得を容易にするインデックスがあります。 シャードは、インデックス付きデータに対して作成されます。 さまざまなデータ ソースを使用して、Datastax Enterprise ツール、Kafka、Docker でアプリケーションを構築できます。
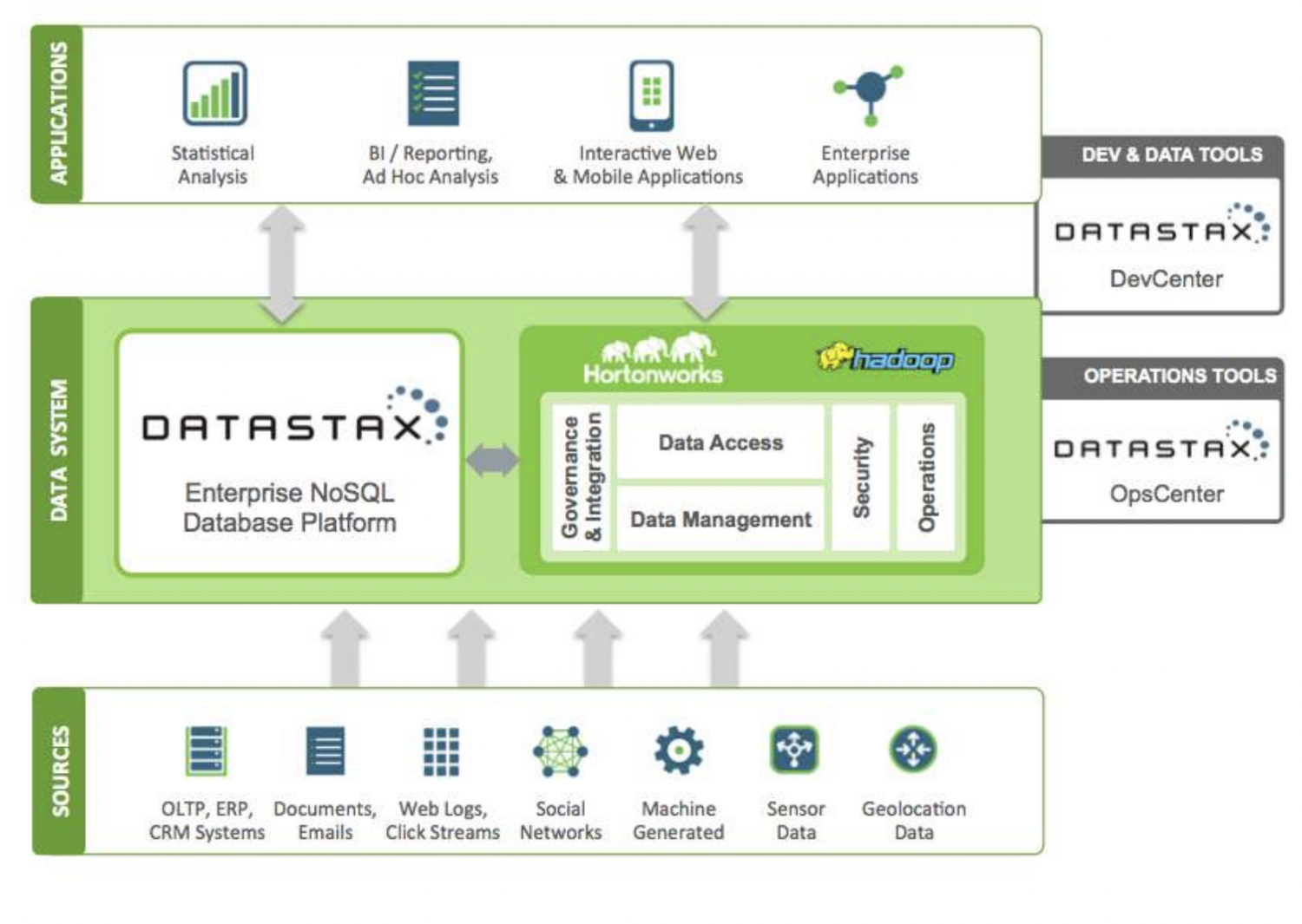
ソースから収集されたデータは、Hadoop エコシステムと DataStax に送信されます。 Hadoop は、DataStax とやり取りすることで、セキュリティ、運用、データ アクセス、および管理を管理します。 データは、Datastax 開発および運用ツールを使用して調整されます。
分析された情報は、統計分析、エンタープライズ アプリケーション、レポート作成などに使用されます。クラウドベースであるため、顧客は使用した分だけ料金を支払い、価格も合理的です。 Verizon、CapitalOne、TMobile、および Overstock は、DataStax を使用している企業です。
オリエントDB
OrientDB は、データを効果的に管理し、データを表示するための視覚的表現を作成するのに役立つグラフ データベースです。 マルチモデル グラフ データベースであり、Java を使用して構築されました。 キーと値のペア、ドキュメント、オブジェクト モデルなどの形式でデータを保存します。グラフ エディター、Studio クエリ、およびコマンド ライン コンソールの 3 つの重要なコンポーネントで構成されます。
グラフ エディターは、データの視覚化と操作に使用されます。 Studio クエリ インターフェイスを使用してクエリを実行し、画像および表形式ですぐに出力を提供します。 コマンド ライン コンソールは、OrientDB からデータを照会するために使用されます。 読み取りおよび書き込み操作を実行できる複数のサーバーを備えた分散アーキテクチャを備えています。 レプリカ サーバーは、読み取り操作とクエリ操作の実行に使用されます。 インデックス作成をサポートし、ACID にも準拠しています。 OrientDB を使用している企業には、Comcast Corporation や Blackfriars Group などがあります。
Dグラフ
Dgraph は、GraphQL をサポートするクラウド グラフ データベースです。 Goを使用して構築されました。 同時クエリ処理を最大化することで、ネットワーク呼び出しを最小限に抑え、待ち時間を短縮します。 Dgraph と GraphQL のシームレスな統合により、GraphQL バックエンド アプリケーションの開発が容易になります。

GraphQL ミューテーションは、データベースおよびデータ パイプラインと対話する Lambda 関数を介して渡されます。 これにより、クエリ処理が簡素化されます。 水平方向にスケーラブルです。つまり、クエリとデータの増加に伴ってリソースの数が増加します。 JWT ベースの認証、データ ビジュアライザー、クラウド認証、データ バックアップなどのさまざまな機能を提供します。Dgraph を使用している組織には、Intuit、intel、Factset などがあります。
タイガーグラフ
Tigergraph は、C++ を使用して開発されたプロパティ グラフ データベースです。 スケーラビリティが高く、高度に接続されたデータに対して高度な分析を実行します。 データの保存にはネイティブのグラフ構造を使用し、データの処理にはグラフ処理エンジンを使用します。 データベースはディスクとメモリに保存され、高速検索のために CPU キャッシュも使用されます。 並列データ処理に Map Reduce 関数を使用します。
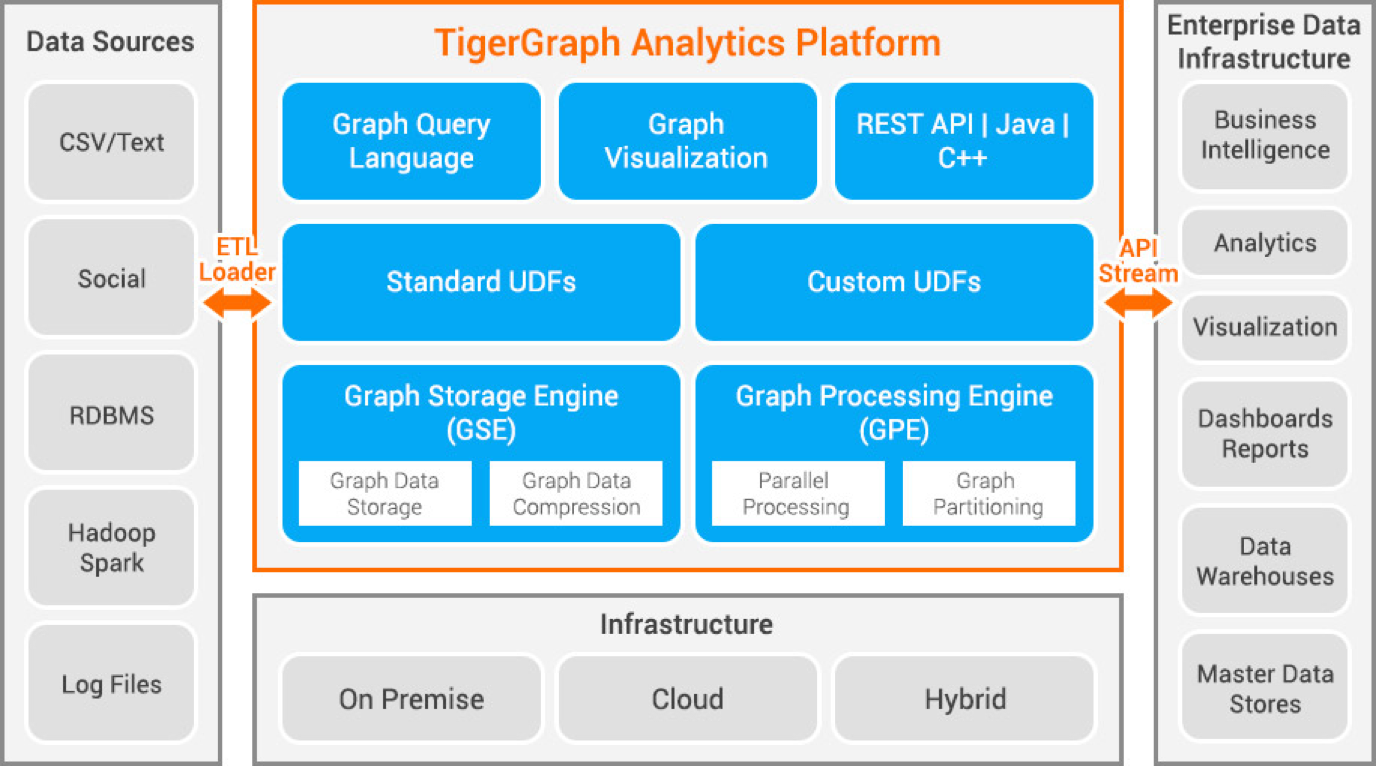
非常に高速でスケーラブルです。 並列計算を行い、リアルタイムの更新を提供します。 データ圧縮技術を使用し、データを 10 倍に圧縮します。 サーバー間でデータを自動的に分割するため、ユーザーは手動でデータを分割するために必要な時間と労力を節約できます。 家庭での不正検出、サプライ チェーン管理、ヘルスケアの改善に使用されます。 JPMorgan Chase、Intuit、および United Health Group は、Tigergraph を使用している組織の一部です。
アレグログラフ
AllegroGraph は、エンティティ イベント ナレッジ グラフ テクノロジを使用して、高度に接続された複雑で高密度のデータに対して分析と意思決定を実行します。 データは、グラフのノードに JSON および JSON-LD 形式で格納されます。 REST プロトコル アーキテクチャを使用します。 また、特定の基準に基づいてデータをシャーディングし、複数のナレッジベース リポジトリに分散することで、非常に大きなデータセットを処理します。
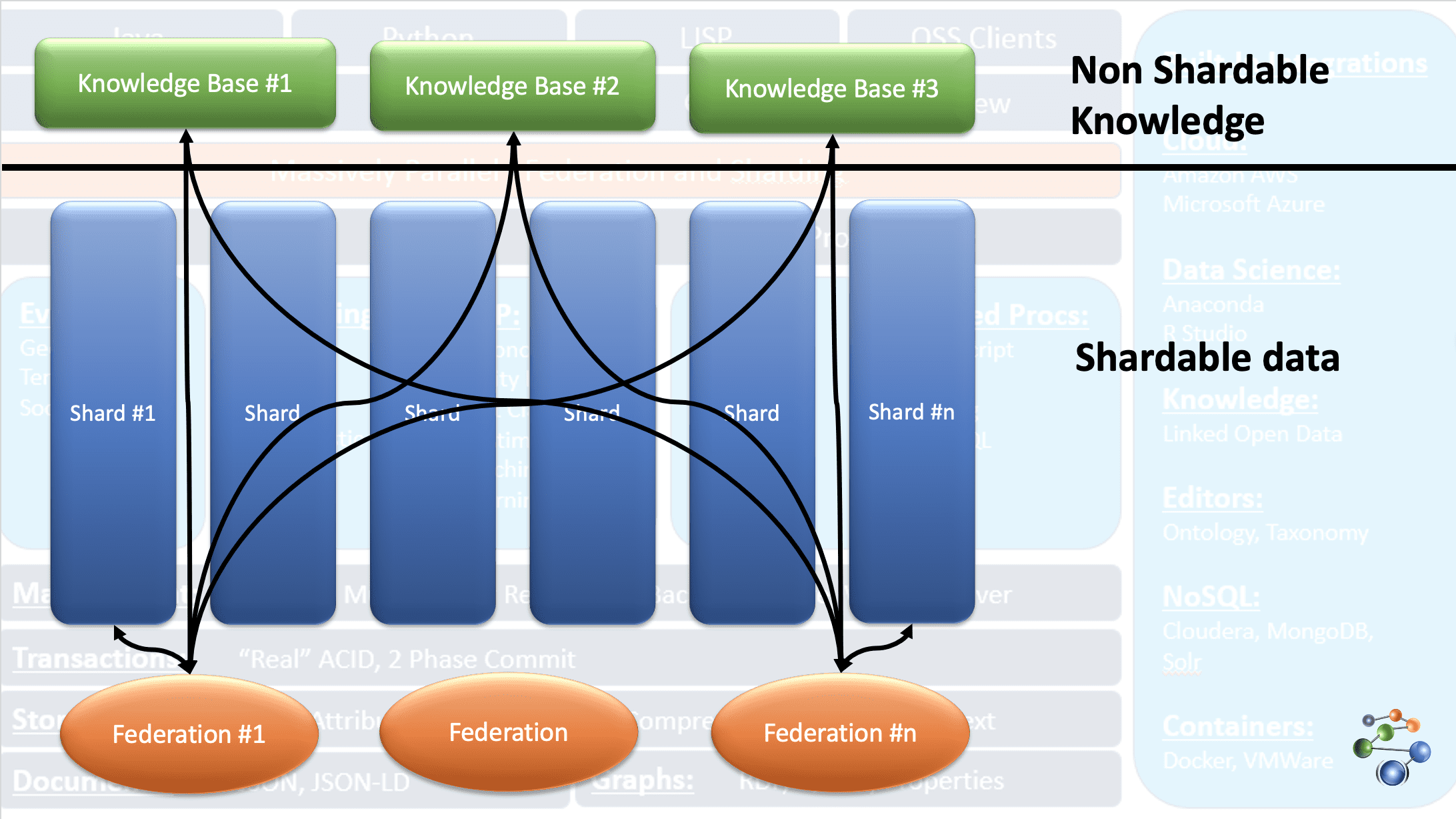
これは、AllegroGraph データベースの FedShard 機能によって可能になります。 クエリの実行は、フェデレーションとナレッジベース リポジトリを組み合わせることによって行われます。 XML スキーマ タイプをサポートし、トリプル インデックスを使用します。 緯度と経度などの地理空間データと、日付、タイムスタンプなどの一時データを保存します。Windows、Mac、および Linux とも互換性があります。 不正検出、ヘルスケア、エンティティ識別、リスク予測などに使用されます。
スタードッグ
Stardog は、グラフ データの仮想化を実行し、データを新しいストレージの場所に物理的にコピーすることなく、データ ウェアハウスやデータ レイクからデータをリンクするグラフ データベースです。 Stardog は、RDF オープン スタンダードに基づいて構築されています。 構造化、半構造化、および非構造化データをサポートします。 Stardog によって行われるこの種のマテリアライゼーションは、柔軟性を提供します。 ナレッジグラフと仮想化を組み合わせた唯一のグラフデータベースです。

Stardog は、AI を搭載した推論エンジンを使用して、クエリ出力を効率的に処理および提供します。 ACID準拠のグラフデータベースです。 同時読み取りと書き込みがサポートされています。 「最先端の」アーキテクチャにより、複雑なクエリを簡単に処理できます。 IT 資産管理、データ管理、分析で使用され、高可用性を提供します。 Stardog を使用している企業には、Cisco、eBay、NASA、Finra などがあります。
最後の言葉
グラフ データベースは、多対多のリレーションシップを簡単にクエリし、データを効果的に格納するのに役立ちます。 それらはスケーラブルで安全であり、多くのサードパーティ ツール、API、および言語と統合できます。 近年ではクラウドと統合され、最高のパフォーマンスを提供しています。
複雑な結合を単純なクエリに単純化して、開発者にとって簡単な作業にします。 IoT やビッグ データなどのデータ集約型タスクもグラフ データベースです。 これらは進化し続け、将来的には確実に他のユースケースに拡大するでしょう。