
質問をするクエリの良い答えは何ですか?
公開: 2020-03-24回答を求めるクエリの要素と回答の要素
Googleは最近、回答を求めるクエリに焦点を当て、そのようなクエリに適切な回答を提供する特許を取得しました。
回答を求めるクエリの要素が何であるかを理解することは、それらのクエリに回答を提供するために公開する必要があるかもしれないものを人々が理解するのに役立ちます。
したがって、この特許が、クエリに対する適切な回答の観点からGoogleが探しているものについて何を述べているかを見るのは興味深いかもしれません。
この特許は以下に焦点を当てています。
検索システムが回答を求めるクエリの特徴的な要素と回答を求めるクエリへの回答をどのように学習できるか。
特許の説明は、質問に対する適切な回答について詳しく説明することから始まります。
一般に、検索システムは、検索クエリを受信し、検索クエリを満たす検索結果を取得します。 検索結果は、インターネットにアクセス可能なリソースなど、検索クエリに関連または応答するリソースを識別します。 検索システムは、受信した検索クエリに応答して、さまざまな種類の検索結果を識別できます。たとえば、Webページ、画像、ビデオ、書籍、ニュース記事を識別する検索結果、運転ルートを示す検索結果、その他多くの検索結果があります。検索結果の種類。
これには、Googleがこれらのクエリのエンティティに関する情報を認識し、その情報を回答に使用することが含まれる場合があります。
検索システムは、さまざまなサブシステムを利用して、クエリに関連するリソースを取得できます。 たとえば、検索システムは、さまざまなエンティティに関する情報を格納し、検索クエリがエンティティのエイリアスを参照するときにエンティティに関する情報を提供するナレッジベースを維持できます。 システムは、1つ以上のテキスト文字列エイリアスを各エンティティに割り当てることができます。 たとえば、自由の女神は、エイリアス「自由の女神」と「自由の女神」に関連付けることができます。 エイリアスはエンティティ間で一意である必要はありません。 たとえば、「ジャガー」は動物と自動車メーカーの両方の別名になります。
また、Googleがクエリのさまざまな品詞を理解し、その情報を回答に使用することも含まれます。
別の検索サブシステムの例は、品詞タガーです。 品詞タガーは、クエリ内の用語を分析し、各用語を特定の品詞(名詞、動詞、直接目的語など)として分類します。 別の検索サブシステムの例は、ルートワード識別子です。 特定のクエリが与えられると、ルートウッド識別子はクエリ内の用語をルートワードとして分類できます。ルートワードは、クエリ内の他の単語に依存しない単語です。 たとえば、「ラザニアを調理する方法」というクエリでは、ルートワード識別子によって「クック」がクエリのルートワードであると判断できます。
とりわけ、この特許は、検索者の質問に対する回答の表示に焦点を当てたクエリに対する簡潔な回答を見つけることを目的としています。
この仕様では、クエリを回答を求めるものとして分類し、回答を求めるクエリに対する回答を生成するためのテクノロジについて説明します。 回答を求めるクエリは、簡潔な回答を求めるユーザーによって発行されるクエリです。 たとえば、「ジョージワシントンが生まれたのはいつか」は、システムによって回答を求めるクエリとして分類されます。これは、システムが、それを発行したユーザーが簡潔な回答を求める可能性が高いと判断できるためです。 22、1732。」
特許の図面からの質問を求める回答の例:

クエリを回答を求めるものとして分類し、回答を求めるクエリに対する回答を生成する
回答を求めるクエリは、簡潔な回答を探している検索者が求めるクエリです。
一例として、「ジョージワシントンはいつ生まれたのですか?」です。 これは、検索者が次のような回答を求めている可能性が高いと判断できるため、回答を求めるクエリとして分類できます。 22、1732。」
この特許は、すべてのクエリが回答を求めているわけではなく、それらは検索結果のみを返し、回答のあるボックスには回答しない可能性があることを示しています。
一部のクエリでは、クエリに関連する複数のドキュメントの並べ替えられたリストを検索者に提供することが最善の答えのように思われる場合があります。 誰かが「ニューヨークのレストラン」を検索し、ニューヨークのさまざまな場所に関するドキュメントのリストが必要になる可能性があります。
この特許の背後にある目的が指摘され、なぜそれが存在するのかが説明されています。
以下で説明する手法は、システムがクエリを回答を求めるクエリとして分類する方法と、システムが回答を求めるクエリに対する適切な回答である可能性が高いレスポンシブドキュメントの部分を識別する方法の両方に関連しています。
質問に対する「良い答え」が回答ボックスに表示される可能性があることをGoogleから教えてくれるものを見たのはこれが初めてです。
回答を求めるクエリの特定
特許の説明は、回答を求めるクエリの認識の背後にあるプロセスが何であるかを示しています。
それは、特許の側面の要約から始まり、それがどのように機能するかについての側面を示しています。これについては、この投稿でさらに詳しく説明します。
回答を求めるクエリの識別プロセスには、次のものが含まれます。
- 複数の用語を含むクエリを受信する
- クエリを特定の質問タイプの回答を求めるクエリとして分類する
- 特定の質問タイプに関連付けられた1つ以上の回答タイプを取得する
- 各回答タイプが、回答を求めるクエリに対する適切な回答の特性を表す1つ以上のそれぞれの回答要素を指定する場合
- それぞれがドキュメントを識別する、クエリを満たす検索結果の取得
- 検索結果によって識別された各ドキュメントのテキストの1つ以上のパッセージのそれぞれについてそれぞれのスコアを計算する
- テキストの各パッセージのスコアが、1つ以上の回答タイプのいくつがテキストのパッセージに一致するかに基づいている場合
- クエリに応答して、それぞれのスコアに基づいて選択されたテキストの1つ以上のパッセージからの情報を含むプレゼンテーションを提供する
このプロセスに関連するその他のオプション機能:
- テキストの最初のパッセージとクエリを満たす1つ以上の検索結果を提供する
- しきい値を満たすスコアを持つテキストのパッセージを決定する
- プレゼンテーションに含めるためのしきい値を満たすスコアを持つテキストのパッセージを選択する
回答を求めるクエリとは何ですか?
クエリを特定のタイプの「回答を求めるクエリ」として分類すると、次のようになります。
- クエリの用語をいくつかの質問タイプと照合する
- 各質問タイプは、対応するタイプのクエリの特性を集合的に表すいくつかの質問要素を指定します。
- クエリの用語が質問タイプの数の最初の質問タイプと一致することを確認する
クエリの条件は質問の種類とどのように一致しますか?
「n-gram」は「n」の長さの単語のシーケンスを意味するため、2グラムは2単語の長さ、3グラムは3単語の長さになります。 これを「n-gram」と表現することにより、特許のプロセスは、さまざまな長さを探索する柔軟性を提供します。
クエリの用語が特定の質問タイプと一致すると判断することは、次のことを意味します。
- クエリの最初のn-gramがエンティティインスタンスを表すことを確認する
- 最初の質問タイプにエンティティインスタンスを表す質問要素が含まれていることを確認する
クエリの用語が特定の質問タイプと一致すると判断することは、次のことを意味します。
- クエリの最初のn-gramがクラスのインスタンスを表すと判断する
- 質問タイプにクラスを表す質問要素が含まれていることを確認する
テキストの最初のパッセージが1つ以上の回答タイプの最初の回答タイプと一致することを確認する
- テキストの最初のパッセージに、最初の回答タイプの1つ以上の回答要素に一致するn-gramがあると判断する
- 1つまたは複数の回答要素の第1の回答要素は、数値測定を表すことができる。
テキストの最初のパッセージが最初の回答タイプと一致すると判断する場合、テキストの最初のパッセージが数値測定値を表すn-gramを持っていると判断することを含みます。
- 1つ以上の回答要素の最初の回答要素は動詞クラスを表します
- テキストの最初のパッセージが最初の回答タイプと一致することを決定することは、テキストの最初のパッセージが動詞クラスのインスタンスを表すn-gramを持っていることを決定することを含みます。

この特許は次の場所にあります。
回答を求めるクエリの要素と回答の要素を生成する
発明者:Yi Liu、Preyas Popat、Nitin Gupta、Afroz Mohiuddin
譲受人:Google LLC
米国特許:10,592,540
付与:2020年3月17日
提出日:2016年6月28日
概要
回答を求める質問に対する回答を生成するための、コンピュータ記憶媒体上にエンコードされたコンピュータプログラムを含む方法、システム、および装置。
方法の1つには、複数の用語を持つクエリを受信することが含まれます。 クエリは、特定の質問タイプの回答を求めるクエリとして分類され、特定の質問タイプに関連付けられた1つ以上の回答タイプが取得されます。
クエリを満たす検索結果が取得され、検索結果によって識別された各ドキュメントで発生するテキストの1つ以上のパッセージごとにそれぞれのスコアが計算されます。ここで、テキストの各パッセージのスコアは、1つまたはより多くの回答タイプがテキストのパッセージに一致します。
それぞれのスコアに基づいて選択されたテキストの1つまたは複数のパッセージからの情報を含むプレゼンテーションが、クエリに応答して提供されます。
回答を求めるクエリに対する回答の提示
検索結果ページには、Web検索結果と回答ボックスが含まれる場合があります。
回答ボックスについて詳しくは、Googleがクエリの回答ボックスの結果をトリガーする方法を投稿しました。
Web検索結果は、GoogleのWebインデックスからのドキュメントへのリンクを提供できます。
これらは、尋ねられたクエリに関連すると考えられる結果であり、タイトル、スニペット、および表示リンクが含まれています。
これらを検索結果で表示して、特定のリンクが実行したクエリにどの程度関連しているかを検索者に知らせることができます。 そして、検索者が自分の元のページにアクセスできるようにします。
回答ボックスには、クエリへの回答を直接含めることができます。 その答えは、Web検索結果で参照されているドキュメントのテキストから得られる可能性があります。
そのような回答については、「注目のスニペット–インテントクエリの自然言語検索結果」という投稿に書きました。 それらは、検索結果のセットの最初のページにある可能性が高い信頼できるドキュメントからのものである可能性があります。
Googleは、クエリに応答してこれらの回答ボックスの結果をオーガニック検索結果の上に表示し、SERPでそのページをもう一度表示していましたが、最近、Googleの検索エンジンジャーナルで説明されているように、そのような回答を単一の結果として扱うことにしました。注目のスニペットは1ページ目に2回表示されません
この特許は、Googleが「クエリが回答を求めるクエリであるとシステムが判断した場合はいつでも回答ボックスを提供する」可能性があることを示しています。
特定の質問タイプに一致する用語を使用しているかどうかに基づいて、Googleがクエリを回答を求めるクエリと見なす方法はいくつかあります。
これらの質問は、「方法」、「理由」などの質問用語を含めることにより、回答ボックスをトリガーする場合があります。
この特許は、これらの質問用語が常に必要であるとは限らず、クエリが質問として表現されておらず、質問語が含まれていない場合でも、回答ボックスが表示される可能性があることを示しています。
しかし、クエリが「ジャガイモの調理方法」などの場合。 または「フライドポテトの作り方は?」 または「マッシュポテトの作り方は?」 回答ボックスを探している可能性があります。
ただし、回答ボックスをトリガーするために、これらの質問用語と実際の質問が存在する必要はありません。 Googleはクエリを調べて、回答タイプによって回答するのが最適かどうかを判断する場合があります。
むしろ、検索システムは、クエリに一致する質問タイプが、検索結果によって参照されるドキュメントのテキストに一致する回答タイプに関連付けられていることが多いと判断したため、回答ボックスの回答は適切な回答として識別されます。
回答スコアリングエンジン
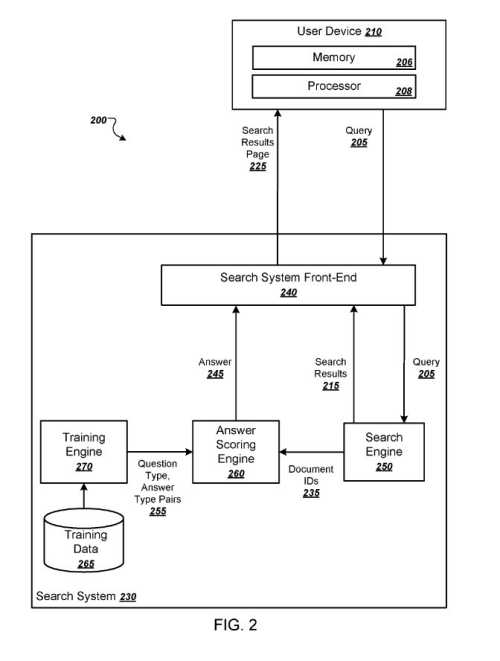
誰かが検索を実行したとき。 それらのクエリの結果、そのクエリに応答してドキュメントが返されます。
回答スコアリングエンジンはドキュメントIDを受け取り、検索結果ページに含めることができる回答を生成する場合があります。
これらのドキュメントIDは、検索結果によって参照されるドキュメントのサブセットを識別します。
回答スコアリングエンジンは、トレーニングエンジンから受け取った質問タイプ/回答タイプのペアを使用して回答を生成する場合があります。 (これらは、回答ボックスに表示される質問と回答である可能性があります。)
回答スコアリングエンジンは、クエリの用語に一致する1つ以上の質問タイプを識別でき、各質問タイプについて、質問要素に関連付けられた1つ以上の回答タイプを識別できます。
各質問タイプは、回答を求めるクエリの特徴である1つ以上の質問要素を指定します。
同様に、対応する各回答タイプは、回答を求めるクエリに対する回答の特徴である1つ以上の回答要素を指定します。
質問タイプおよび回答タイプは、図3に関して以下により詳細に説明される。 3.3。
トレーニングエンジンは、質問タイプと回答タイプのペアを識別します。
トレーニングエンジンは、質問のペアと質問への回答を含むことができるトレーニングデータのコレクションでトレーニング例を処理します。
タイヤの交換方法に関する質問については、次のように質問と回答を選択して質問に回答することができます。

グーグルは、私が最近投稿でより詳細に書いたハウツー質問のような特定のタイプの質問についての情報を提供してきました、どのようにグーグルはハウツー質問への答えを選ぶかもしれません。
私がその投稿で書いた特許は、クエリが回答を求めるクエリであるかどうか、そして回答が良い応答を提供するかどうかを決定することに関するものではなく、そのようなクエリに答える可能性のあるステップに自信を見つけようとすることに焦点を当てていましたそのクエリに。
質問要素と回答要素のペアの生成
この検索システムは、トレーニングデータの質問と回答のペアを処理して、質問の種類と対応する回答の種類を定義します。
どの質問タイプ/回答タイプのペアが回答を求めるクエリに対して適切な回答を生成する可能性が最も高いかを表す統計を計算します。
その決定は、トレーニングエンジンと呼ばれるコンピュータシステムで行われます。
まず、トレーニングデータを特定します。
トレーニングデータは、質問と回答のペアなど、質問と回答を関連付けるデータです。

トレーニングデータには、回答を求めると判断されたクエリや、検索者が一般的に選択した、または他の検索結果よりも頻繁に選択した検索結果のスニペットを含めることができます。
このトレーニングデータでは、システムは、ストップワードなどの質問から特定のタイプの単語やフレーズを除外する場合があります。
したがって、「ラザニアの調理方法」をフィルタリングして、「ラザニアの調理方法」を生成することができます。
形容詞や前置詞句がクエリから削除されるなど、一部の部分が質問から削除される場合があります。
したがって、「食道は人体のどこにあるか」などのクエリをフィルタリングして、「食道はどこにあるか」を生成することができます。
システムは、質問と回答の用語を標準形に変換することもできます。
これは、「料理」という用語の語形変化、たとえば「料理」、「料理」、「料理」などが、標準形の「料理」に変換される可能性があることを意味します。
質問タイプは、トレーニングデータの質問要素から定義できます。
質問タイプは、回答を求めるクエリの特性を表す質問要素のグループです。
質問タイプ(how、cook)は、「how」と「cook」の2つの質問要素を指定します。
質問タイプのすべての質問要素に一致する用語がある場合、クエリはこの質問タイプに一致します。
クエリには質問タイプのすべての質問要素が含まれているため、クエリ「ピザの調理方法」は質問タイプ(how、cook)と一致します。
この特許は、質問タイプは順序付けまたは順序付けなしで実行できることを示しています。 (これは、クエリが特定の順序で実行する特定の手順を示す「ハウツー」クエリであるかどうかを示しているようです。)
この特許では、中かっこを使用して、クエリが順序付けられた構造を使用しているかどうかを識別しています。
したがって、クエリで「料理」という用語の前に「どのように」という用語が含まれている場合に限り、クエリは質問タイプ{how、cook}と一致します。
質問と回答のペアは、質問ごとに、質問のどの用語が質問要素タイプのセットのいずれかに一致するかを調べることによって一致します。
各質問要素タイプは、質問で発生するn-gramの特性を表します。
一般的な質問要素の種類
この特許は、以下を含むいくつかの一般的な質問要素タイプを提供します。
エンティティインスタンス–エンティティインスタンスタイプは、エンティティインスタンスを表すn-gramと一致します。 例として、n-gram「AbrahamLincoln」は質問要素タイプと一致します。これは、このn-gramがエンティティのインスタンスであるためです。 n-gramがこの質問要素タイプと一致する場合、結果の質問タイプには、n-gramのエンティティインスタンスを表す質問要素が含まれます(例:(entity / Abraham_Lincoln))。 同じエンティティのエイリアスに一致する他のn-gramも、この質問要素に一致します。たとえば、「阿部リンカーン」、「リンカーン大統領」、「正直な阿部」などです。
エンティティクラス–エンティティクラスタイプは、エンティティクラスのインスタンスを表すn-gramに一致します。 例として、n-gramの「ラザニア」は、料理を表すエンティティクラスのインスタンスであるため、この質問要素タイプと一致します。 n-gramがこの質問要素タイプと一致する場合、結果の質問タイプには、エンティティクラスを表す質問要素が含まれます(例:(エンティティ/料理))。
品詞クラス–品詞クラスタイプは、品詞クラスのインスタンスを表すn-gramと一致します。 たとえば、n-gramの「run」は品詞クラス「verbs」のインスタンスであるため、この質問要素タイプと一致します。 n-gramがこの質問要素タイプと一致する場合、結果の質問タイプには、一致する品詞クラス(たとえば、品詞/動詞)を表す質問要素が含まれます。
ルートワード–ルートワードタイプは、システムが質問のルートワードであると判断したn-gramに一致します。 一般に、語根は質問の他の用語に依存しない用語です。 たとえば、「ラザニアの作り方」では、「料理」が語源です。 したがって、「ラザニアを調理する方法」というクエリで「cook」が発生すると、「cook」はこの質問要素タイプと一致します。 結果の質問タイプには、一致するn-gramが含まれます(例:(cook))。
N-gram –n-gramタイプは任意のn-gramと一致します。 ただし、この特許は、トレーニングデータからの質問タイプの過度の生成を回避するために、システムがnグラムの質問要素を事前定義されたnグラムのセットに制限できることを示しています。
検索システムは、「どのように」、「どのように」、「いつ」、「いつだったか」、「なぜ」、「どこで」、「何を」などの疑問詞および句を含むように、nグラムの質問要素を事前定義することができる。 「誰」、「誰」。
これらの質問要素タイプが複数表示される場合があります。
したがって、n-gram「GeorgeWashington」は、エンティティインスタンスタイプ(質問要素entities / George_Washington)と、エンティティクラスタイプ(質問要素entities / us_presidents)の両方に一致します。
n-gram「GeorgeWashington」は、システムがn-gramタイプの数を制限する方法によっては、n-gramタイプと一致する場合もあります。
また、「クック」という用語は、ルートワードタイプ、エンティティインスタンスタイプ、およびエンティティクラスタイプと一致します。
質問と回答の種類を広げる例
このシステムは、一致する質問要素タイプを識別した後、さまざまな長さと複数レベルの一般性で質問要素のさまざまな組み合わせを生成することにより、質問タイプを生成できます。
これにより、一般性と特異性のバランスが取れた質問タイプを見つけることができます。
たとえば、「ラザニアの作り方」などです。
最初の用語「how」は、n-gram要素タイプのみに一致します。
ただし、「cook」は、クラス「hobbies」のn-gram要素タイプ、ルートワード要素タイプ、およびエンティティクラス要素タイプと一致します。
したがって、システムは、一致する質問要素のさまざまな組み合わせを選択することにより、次の2要素の質問タイプを生成できます。
(どのように、料理する)
(どのように、エンティティ/趣味)
「ラザニア」という用語は、n-gram要素タイプとエンティティクラス要素タイプ「料理」に一致します。 したがって、システムは、一致する質問要素のさまざまな組み合わせを選択することにより、次の3要素の質問タイプを生成できます。
(どのように、料理、ラザニア)
(どのように、料理し、実体/料理)
(方法、エンティティ/趣味、エンティティ/料理)
(どのように、エンティティ/趣味、ラザニア)
回答要素タイプの選択
この特許は、「回答タイプ」を、回答を求めるクエリに対する適切な回答の特性を集合的に表す回答要素のグループとして定義しています。
この回答を求めるクエリアプローチでは、トレーニングデータ内の回答を処理し、回答ごとに、回答のどの用語が一連の回答要素タイプのいずれかに一致するかを決定することで、回答タイプを生成できます。
検索システムは、回答要素タイプに適合する回答要素を見つけることによって回答タイプを生成することができる。
一般的な回答要素の種類とそれに対応する回答要素には、次のものがあります。
測定–測定タイプは、数値測定を表す用語と一致する場合があります。 これらには次のものが含まれます。
- 日付、たとえば「1997」、「2月。 2、1997」または「2/19/1997」
- 物理的測定値、例:「1.85cm」、「12インチ」
- 所要時間、「10分」、「1時間」
- その他の適切な数値測定
N-gram – n-gramタイプは、回答内の任意のn-gramと一致します。 回答タイプの過度の生成を回避するために、システムはn-gram回答要素を特定のnの値よりも低いn-gramに制限する場合がありますが、これは一般的ではありません。 たとえば、システムは、nグラムの回答要素をしきい値を満たす逆ドキュメント頻度スコアを持つ1グラムと2グラムに制限できます。
動詞–動詞の種類は、システムが動詞であると判断したすべての用語に一致します。
前置詞–前置詞タイプは、システムが前置詞であると判断したすべての用語に一致します。
システムは、任意の品詞の回答要素タイプを定義できると言われています。
ただし、一部の実装では、システムは動詞と前置詞のタイプのみを使用する場合があります。
Entity_instance –エンティティインスタンスタイプは、エンティティインスタンスを表すn-gramと一致します。
回答タイプには、エンティティインスタンスを表す回答要素を含めることができます(例:(entity / Abraham_Lincoln))。
N-gram near entity – n-gram-near-entityタイプは、n-gramanswer要素タイプとentityinstance answer要素タイプの両方を使用し、回答のエンティティインスタンスの近くでn-gramが発生するという制限も課します。 システムは、n-gramが次の場合にエンティティインスタンスの近くにあると見なすことができます。
- エンティティインスタンスの用語のしきい値数内の回答で発生します
- エンティティインスタンスと同じ文で発生します
- エンティティインスタンスと同じパッセージで発生します
たとえば、「オバマはホノルルで生まれた」という回答では、珍しいnグラムの「ホノルル」がエンティティインスタンス「オバマ」の5つの用語内で発生します。 結果の回答タイプには、n-gramとエンティティインスタンスが含まれます。例:(ホノルル近郊のエンティティ/オバマ)
エンティティに近い動詞–エンティティに近い動詞タイプは、動詞の回答要素タイプとエンティティインスタンスの回答要素タイプの両方を使用し、同様に、回答のエンティティインスタンスの近くで動詞が発生するという制限を課します。 たとえば、「オバマはホノルルで生まれた」の場合、結果の回答タイプに回答要素(エンティティ/オバマニアボーン)を含めることができます。
エンティティの近くの前置詞–エンティティの近くの前置詞タイプは、前置詞の回答要素タイプとエンティティインスタンスの回答要素タイプの両方を使用し、同様に、前置詞が回答のエンティティインスタンスの近くで発生するという制限を課します。 たとえば、「オバマはホノルルで生まれた」の場合、結果の回答タイプに回答要素(エンティティ/オバマの近く)を含めることができます。
動詞クラス–動詞クラスタイプは、動詞クラスのインスタンスを表すn-gramに一致します。 たとえば、システムは次のすべての動詞をクラス動詞/ブレンドのインスタンスとして識別できます:追加、ブレンド、結合、混合、接続、クリーム、融合、結合、リンク、マージ、混合、混合、ネットワーク、プール。 結果の回答タイプには、動詞クラスを表す質問要素が含まれます(例:(動詞/ブレンド))。
スキップグラム–スキップグラムタイプは、バイグラムと、バイグラムの用語の間に発生するいくつかの用語を指定します。 たとえば、スキップ値が1の場合、スキップグラム「where * the」は、「where is the」、「where was the」、「where does the」、および「wherehas」のすべてのn-gramに一致します。 。」 結果の回答タイプには、バイグラムとスキップ値を表す回答要素が含まれます。たとえば、(*は)、単一のアスタリスクはスキップ値1を表します。
システムは、質問タイプと回答タイプのペアのカウントを計算します。
質問と回答のペアのスコアリング
この特許は、システムが各質問タイプ/回答タイプのペアのスコアを計算することを示しています。
このスコアは、「トレーニングデータに反映される特定の質問タイプ/回答タイプのペアの予測品質」に基づいています。
スコアが高い質問タイプ/回答タイプのペアは、質問タイプによって表される回答を求めるクエリに対する適切な回答の特性を集合的に表す1つ以上の回答要素を持つ回答タイプを持っている可能性があります。
システムは通常、すべてのカウントが計算されるまで待機してから、特定の質問タイプと回答タイプのペアのスコアを計算します。
一部の実装では、システムは各ペアのポイントごとの相互情報(PMI)スコアを計算します。 PMIスコアがゼロの場合は、質問と回答が独立しており、関係がないことを示します。 一方、高いスコアは、対応する質問タイプに一致する質問に対する回答に一致する回答タイプを見つける可能性が高いことを表します。
システムは、最高のスコアを持つ質問タイプ/回答タイプのペアを選択します。 それらはランク付けされ、しきい値を満たすスコアを持つペアを選択できます。
選択されたペアの回答タイプは、対応する質問タイプによって表される回答を求めるクエリに対する適切な回答を表す可能性があります。
次に、この回答を求めるクエリシステムは、選択した質問タイプと回答タイプのペアを質問タイプごとにインデックス付けして、オンラインスコアリング中に特定の質問タイプに関連付けられたすべての回答タイプを効率的に取得できるようにします。
質問タイプのインデックスをスコアで並べ替えて、試行する回答タイプの数をリアルタイムで決定する場合があります。
このシステムは、質問タイプに関連付けられた各回答タイプをスコアで並べ替えることができるため、スコアが最も高い回答タイプをクエリ時に最初に処理できます。
回答を求めるクエリの回答を生成するプロセス
この特許は、私が過去に書いた質問への回答に関する別の特許を思い出させました。 その特許は私が投稿で書いたものでした、Googleは注目のスニペットの回答パッセージを書くためにスキーマを使用していますか?
その投稿は、Googleが質問に対するよく書かれたテキストの回答から選択する方法を示しており、それらの回答に追加の事実を提供するために構造化されたデータも関連付けられていますが、回答の要素を調べることによってこの特許が行う分析は提供していません-クエリとそれらの回答の要素を探します。
この特許の説明は、回答を求めるクエリのために特別に回答が生成される方法についての詳細を提供することで終わります。
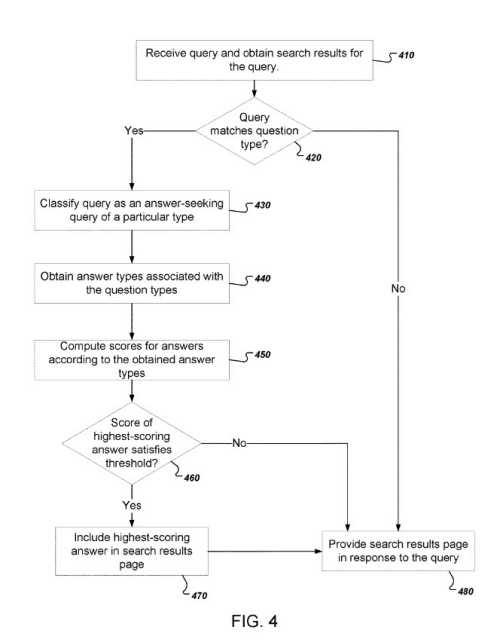
クエリを受信することから始まり、その検索結果を取得します
次に、クエリに一致する質問タイプを決定します。
クエリが生成された質問タイプのいずれにも一致しない場合、システムはそのクエリが回答を求めるクエリではないと判断できます。
その場合、回答ボックスなしで応答し、回答なしで検索結果ページを表示します。
回答を求めるクエリのタイプは、一致する質問タイプの要素によって定義されます。 次に、検索システムは、回答を求めるクエリに対する適切な回答である可能性が高いテキストのパッセージを決定する場合があります。
これを行うために、一致する各質問タイプを1つ以上の回答タイプに関連付ける質問タイプインデックスにアクセスできます。
検索システムは、検索から得られた回答タイプに従って回答のスコアを計算することができる。
検索システムは、最高得点の回答のスコアが閾値を満たすかどうかを決定することができる。 スコアがしきい値を満たさない場合、システムはその回答がクエリに対する適切な回答ではないと判断し、検索結果ページにその回答を表示することを拒否できます。
スコアがしきい値を満たしている場合、検索システムは、検索結果ページに最高スコアの回答を含め、クエリに応答して検索結果ページを提供する場合があります。
回答を求めるクエリの最終的なポイント
この特許は、この特許に記載されているプロセスがどのように機能するかについてのいくつかの追加の側面を提供し、必ずしもカバーされていない他のステップも含む可能性があると述べています。
私は少なくとも1つの他の特許(ハウツークエリに関するもの)を指摘しました。これは、この特許にも詳述されていない、回答の選択方法のより多くの側面を説明しています。
したがって、自然言語の回答について上記でリンクしたものや、回答のパッセージを使用したクエリへの応答など、特に回答を探すことに焦点を当てたクエリへの応答の追加の側面をカバーする他の特許を調べることは理にかなっています。
また、Googleがクエリに応答してナレッジグラフを生成する方法について書き、エンティティとそれらのエンティティの分類および属性との関連スコアを考慮して、「ナレッジグラフを使用した質問への回答」の投稿で質問に回答します。
これらの投稿が対象としているさまざまな特許のアプローチがどのように組み合わされるかについての明確なガイダンスはありませんが、Googleが回答を求めるクエリに応答するときに、それらが存在し、すべてがどのように組み合わされるかを判断する際に考慮する必要があることに注意してください。役に立った。