
对于提出问题的查询,什么是好的答案?
已发表: 2020-03-24寻求答案的查询要素和答案要素
谷歌最近获得了一项专利,专注于寻求答案的查询并为此类查询提供良好的答案。
了解寻求答案的查询的要素可以帮助人们了解他们可能需要发布哪些内容才能为这些查询提供答案。
因此,看看这项专利说明了谷歌在查询的良好答案方面可能正在寻找的内容,可能会很有趣。
本专利重点在于:
搜索系统如何学习寻求答案的查询的特征元素以及寻求答案的查询的答案。
该专利的描述首先告诉我们更多有关查询的良好答案的信息:
通常,搜索系统接收搜索查询并获得满足搜索查询的搜索结果。 搜索结果识别与搜索查询相关或响应于搜索查询的资源,例如互联网可访问资源。 搜索系统可以响应于接收到的搜索查询来识别许多不同类型的搜索结果,例如,识别网页、图像、视频、书籍或新闻文章的搜索结果,呈现驾驶方向的搜索结果,以及许多其他搜索结果的类型。
这可能包括 Google 了解有关这些查询中实体的信息并在答案中使用该信息:
搜索系统可以利用各种子系统来获取与查询相关的资源。 例如,搜索系统可以维护知识库,该知识库存储关于各种实体的信息并在搜索查询引用实体的别名时提供关于实体的信息。 系统可以为每个实体分配一个或多个文本字符串别名。 例如,自由女神像可以与别名“自由女神像”和“自由女神像”相关联。 别名在实体之间不必是唯一的。 例如,“jaguar”既可以是动物的别名,也可以是汽车制造商的别名。
它还可以让谷歌理解查询中不同的词性,并在答案中使用这些信息:
另一个示例搜索子系统是词性标注器。 词性标注器分析查询中的术语并将每个术语分类为特定的词性,例如名词、动词或直接宾语。 另一个示例搜索子系统是词根标识符。 给定特定查询,根木材标识符可以将查询中的术语分类为根词,该词不依赖于查询中的任何其他词。 例如,在查询“how to cook lasagna”中,词根标识符可以确定“cook”是查询的词根。
最重要的是,该专利专门针对查询的简明答案,重点是显示搜索者问题的答案:
本规范描述了与将查询分类为寻求答案和为寻求答案的查询生成答案相关的技术。 寻求答案的查询是由寻求简洁答案的用户发出的查询。 例如,“乔治华盛顿何时出生”将被系统归类为寻求答案的查询,因为系统可以确定发布它的用户很可能寻求简洁的答案,例如,“Feb. 22 日,1732 年。”
来自专利图纸的示例答案寻求查询:

将查询分类为寻求答案并为寻求答案的查询生成答案
寻求答案的查询是寻找简洁答案的搜索者所寻求的查询。
一个例子是,“乔治华盛顿是什么时候出生的?” 这可以归类为寻求答案的查询,因为可以确定搜索者很可能想要一个答案,例如:“Feb. 22 日,1732 年。”
该专利告诉我们,并非所有查询都是寻求答案的,而且这些查询可能只返回搜索结果,而不是带有答案的回答框。
对于某些查询,最佳答案似乎是为搜索者提供与查询相关的多个文档的排序列表。 有人搜索“纽约的餐馆”,他们可能想要一份关于纽约市不同餐饮场所的文件清单。
我们被指出了这项专利背后的目的,并被告知为什么它存在:
下面描述的技术涉及系统如何将查询分类为寻求答案的查询以及系统如何识别可能是寻求答案的查询的良好答案的响应文档的部分。
这是我第一次从 Google 看到任何告诉我们答案框中的问题的“好答案”的内容。
识别答案寻求查询
专利描述告诉我们识别寻求答案的查询背后的过程可能是什么。
它首先总结了专利的各个方面,并阐述了其工作原理的各个方面,我将在本文中进一步详细介绍。
寻求答案的查询识别过程包括:
- 接收具有多个术语的查询
- 将查询分类为特定问题类型的寻求答案查询
- 获取与特定问题类型相关的一种或多种答案类型
- 其中每个答案类型指定一个或多个相应的答案元素,代表对寻求答案的查询的正确答案的特征
- 获取满足查询的搜索结果,其中每一个标识一个文档
- 为搜索结果识别的每个文档中的一个或多个文本段落中的每一个计算相应的分数
- 每段文本的分数基于一个或多个答案类型中有多少与文本段匹配
- 响应查询,提供包含来自一个或多个基于相应分数选择的文本段落的信息的演示文稿
此过程中涉及的其他一些可选功能:
- 提供第一段文本和一个或多个满足查询的搜索结果
- 确定具有满足阈值的分数的文本段落
- 选择分数满足包含在演示文稿中的阈值的文本段落
什么是寻求答案的查询?
将查询分类为特定类型的“寻求答案的查询”可能意味着:
- 将查询词与多种问题类型相匹配
- 其中每个问题类型指定了许多问题元素,这些元素共同代表了相应类型查询的特征
- 确定查询词匹配问题类型数量的第一个问题类型
查询条件如何匹配问题类型?
“n-gram”表示长度为“n”的单词序列,因此 2-gram 将是两个单词长,而 3-gram 将是 3 个单词长。 通过将其表述为“n-gram”,专利中的过程提供了探索不同长度的灵活性。
确定查询词匹配特定问题类型意味着:
- 确定查询中的第一个 n-gram 代表实体实例
- 确定第一个问题类型包括表示实体实例的问题元素
确定查询词匹配特定问题类型意味着:
- 决定查询中的第一个 n-gram 代表一个类的实例
- 确定问题类型包括代表类的问题元素
确定文本的第一段与一个或多个答案类型中的第一个答案类型匹配
- 确定文本的第一段具有与第一个答案类型的一个或多个答案元素匹配的 n-gram
- 一个或多个答案元素中的第一个答案元素可以表示数值测量
其中确定第一段文本匹配第一答案类型包括确定第一段文本具有表示数值度量的n-gram。
- 一个或多个答案元素中的第一个答案元素代表一个动词类
- 确定第一段文本与第一答案类型匹配包括确定第一段文本具有表示动词类实例的 n-gram

该专利可在以下网址找到:
生成寻求答案的查询元素和答案元素
发明人: Yi Liu、Preyas Popat、Nitin Gupta 和 Afroz Mohiuddin
受让人:谷歌有限责任公司
美国专利:10,592,540
授予时间:2020 年 3 月 17 日
提交时间:2016 年 6 月 28 日
抽象的
方法、系统和装置,包括编码在计算机存储介质上的计算机程序,用于生成对寻求答案的查询的答案。
方法之一包括接收具有多个术语的查询。 将该查询归类为特定问题类型的寻答案查询,获得与该特定问题类型相关联的一个或多个答案类型。
获得满足查询的搜索结果,并为搜索结果标识的每个文档中出现的一个或多个文本段落中的每一个计算相应的分数,其中每个文本段落的分数基于一个或多个文本段落中的多少个。更多的答案类型匹配文本的段落。
响应于查询提供包括来自基于相应分数选择的一个或多个文本段落的信息的呈现。
呈现寻求答案的查询的答案
搜索结果页面可能包括网络搜索结果以及答案框。
我在帖子中写了更多关于答案框的内容,Google 如何触发查询的答案框结果。
网络搜索结果可以提供指向 Google 网络索引中的文档的链接。
它们是被认为可能与所询问的查询相关的结果,包括标题、片段和显示链接。
这些可以在搜索结果中查看,让搜索者了解特定链接与他们执行的查询的相关性。 它们将使搜索者能够访问他们来自的页面。
答案框可以直接包含对查询的答案。 该答案很可能是从网络搜索结果中引用的文档文本中获得的。
我在 Featured Snippets – Natural Language Search Results for Intent Queries 一文中写到了这样的答案。 这些可能来自权威文档,可能来自一组搜索结果的第一页。
谷歌一直在有机结果上方显示这些答案框结果以响应查询,并在 SERP 中第二次显示该页面,但他们最近决定将此类答案视为单个结果,如谷歌搜索引擎杂志所述:网页与精选片段不会在第 1 页上出现两次
该专利告诉我们,谷歌可能“在系统判定查询是寻求答案的查询时提供答案框”。
根据是否使用与特定问题类型匹配的术语,Google 可以通过几种不同的方式将查询视为寻求答案的查询。
这些问题可以通过包含诸如“如何”、“为什么”等问题术语来触发答案框。
该专利告诉我们,这些问题术语并不是一直都需要的,即使查询没有被表述为问题并且不包含问题词,也可以显示答案框。
但是,当查询是诸如“如何煮土豆?”之类的内容时。 或“如何制作炸薯条?” 或“如何制作土豆泥?” 它很可能在寻找答案框。
但是不需要出现这些问题术语和实际问题来触发答案框。 谷歌可能会查看查询并决定是否最好通过以下答案类型来回答:
相反,答案框中的答案被识别为好的答案,因为搜索系统已确定与查询匹配的问题类型通常与与搜索结果引用的文档的文本匹配的答案类型相关联。
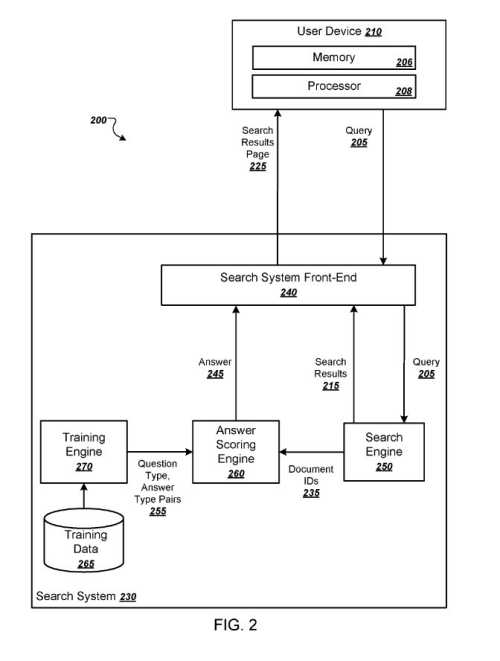
答案评分引擎
当有人进行搜索时。 他们的查询导致响应该查询返回文档。
答案评分引擎接收文档 ID,并可以生成可以包含在搜索结果页面中的答案。
这些文档 ID 将标识搜索结果引用的文档子集。
答案评分引擎可以通过使用从训练引擎接收的问题类型/答案类型对来生成答案。 (这些可能是答案框中显示的问题和答案。)
答案评分引擎可以为查询识别与查询的术语匹配的一个或多个问题类型,并且对于每个问题类型,识别与问题元素相关联的一个或多个答案类型。
每个问题类型指定一个或多个作为寻求答案查询特征的问题元素。
类似地,每个对应的答案类型指定一个或多个作为寻求答案查询的答案特征的答案元素。
下面将关于图1更详细地描述问题类型和回答类型。 3.
训练引擎识别成对的问题类型和答案类型。
训练引擎处理训练数据集合中的训练示例,其中可以包括成对的问题和问题的答案。
可以选择一个问题和一个答案来响应查询,例如关于如何更换轮胎的查询的以下内容:

Google 一直在提供有关特定类型问题的信息,例如我最近在帖子“Google 如何选择 How-to 查询的答案”中更详细地写的 how-to 问题。
我在那篇文章中写的专利专注于试图找到对可能回答此类查询的步骤的信心,而不是这个更多地关于确定查询是否是寻求答案的查询以及答案是否提供良好响应的专利到那个查询。
生成问题元素/答案元素对
该搜索系统将处理训练数据中的问题/答案对,以定义问题类型和相应的答案类型。
它将计算代表哪些问题类型/答案类型对最有可能为寻求答案的查询生成好的答案的统计数据。
该确定发生在称为训练引擎的计算机系统上。
它从识别训练数据开始。
训练数据是将问题与答案相关联的数据,例如问答对。
训练数据可以包括被确定为寻求答案的查询和搜索者选择的搜索结果片段,一般而言或比其他搜索结果更频繁地选择。

在这个训练数据中,系统可能会从问题中过滤出某些类型的单词和短语,例如停用词。
因此,可以过滤“如何烹饪烤宽面条”以生成“如何烹饪烤宽面条”。
某些部分可能会从问题中删除,例如从查询中删除的形容词和介词短语。
因此,可以过滤诸如“食道在人体中的位置”之类的查询以生成“食道位于哪里”。
该系统还可以将问题和答案中的术语转换为规范形式。
这意味着术语“cook”的屈折形式,例如“cooking”、“cooked”、“cooks”等,可能会转化为规范形式“cook”。
可以从训练数据中的问题元素定义问题类型。
问题类型是一组问题元素,它们一起表示寻求答案的查询的特征。
问题类型(how、cook)指定了两个问题元素,“how”和“cook”。
当查询具有匹配问题类型中的所有问题元素的术语时,该查询匹配该问题类型。
查询“如何烹饪披萨”与问题类型(如何,烹饪)相匹配,因为该查询包含该问题类型的所有问题元素。
该专利告诉我们问题类型可以是有序的或无序的。 (这似乎表明查询是否是“如何”查询,显示了按特定顺序遵循的特定步骤。)
该专利使用大括号来标识查询是否使用有序结构。
因此,当且仅当术语“how”出现在术语“cook”之前,查询才会匹配问题类型 {how,cook}。
问题和答案对通过查看每个问题的问题的哪些术语匹配任何一组问题元素类型来匹配。
每个问题元素类型表示出现在问题中的 n-gram 的特征。
常见问题元素类型
该专利提供了一些常见的问题元素类型,其中包括:
实体实例——实体实例类型匹配代表实体实例的 n-gram。 例如,n-gram“Abraham Lincoln”匹配一个问题元素类型,因为这个 n-gram 是一个实体的实例。 当 n-gram 匹配此问题元素类型时,结果问题类型包括表示 n-gram 的实体实例的问题元素,例如 (entity/Abraham_Lincoln)。 匹配同一实体的任何别名的其他 n-gram 也将匹配这个问题元素,例如,“Abe Lincoln”、“President Lincoln”和“Honest Abe”。
实体类——实体类类型匹配表示实体类实例的 n-gram。 例如,n-gram“lasagna”匹配这个问题元素类型,因为它是代表食物菜肴的实体类的实例。 当一个 n-gram 匹配这个问题元素类型时,结果问题类型包括一个代表实体类的问题元素,例如,(entity/dishes)
词性类——词性类类型匹配表示词性类实例的 n-gram。 例如,n-gram“run”匹配这个问题元素类型,因为它是词性类“verbs”的一个实例。 当一个 n-gram 匹配这个问题元素类型时,产生的问题类型包括一个代表匹配词性类的问题元素,例如,(part-of-speech/verb)。
根词- 根词类型匹配系统确定为问题的根词的 n-gram。 一般来说,词根是一个不依赖于问题中其他术语的术语。 例如,在“如何烹饪千层面”中,“cook”是词根。 因此,当查询“how to cook lasagna”中出现“cook”时,“cook”将匹配这个问题元素类型。 生成的问题类型包括匹配的 n-gram,例如 (cook)。
N-gram – n-gram 类型匹配任何 n-gram。 然而,该专利告诉我们,为了避免从训练数据中过度生成问题类型,系统可以将 n-gram 问题元素限制为一组预定义的 n-gram。
搜索系统可以预定义 n-gram 问题元素以包括问题词和短语,例如“如何”、“如何”、“何时”、“什么时候”、“为什么”、“哪里”、“什么” “谁”和“谁”。
可能会出现不止一种这些问题元素类型。
因此,n-gram“George Washington”既匹配实体实例类型,产生问题元素entities/George_Washington,也匹配实体类类型,产生问题元素entities/us_presidents。
n-gram“George Washington”也可能匹配 n-gram 类型,这取决于系统如何限制 n-gram 类型的数量。
此外,术语“cook”与词根类型、实体实例类型和实体类类型相匹配。
扩展问题和答案类型的示例
该系统识别出匹配的问题元素类型后,可以通过生成不同长度和多级通用性的问题元素的不同组合来生成问题类型。
这可以允许发现在一般性和特异性之间提供良好平衡的问题类型。
例如,“如何烹饪千层面”。
第一个术语“如何”仅匹配 n-gram 元素类型。
但是,“cook”与“hobbies”类的 n-gram 元素类型、词根元素类型和实体类元素类型相匹配。
因此,系统可以通过选择匹配问题元素的不同组合来生成以下双元素问题类型:
(怎么做,做饭)
(如何,实体/爱好)
术语“lasagna”匹配 n-gram 元素类型和实体类元素类型“dishes”。 因此,系统可以通过选择匹配问题元素的不同组合来生成以下三元素问题类型:
(怎么做,做饭,烤宽面条)
(如何,烹饪,实体/菜肴)
(如何,实体/爱好,实体/菜肴)
(如何,实体/爱好,千层面)
选择答案元素类型
该专利将“答案类型”定义为一组答案元素,它们共同表示对寻求答案的查询的正确答案的特征。
这种寻求答案的查询方法可以通过处理训练数据中的那些答案并为每个答案决定答案的哪些术语匹配任何一组答案元素类型来生成答案类型。
搜索系统可以通过找到适合答案元素类型的答案元素来生成答案类型。
一些常见的答案元素类型及其对应的答案元素包括:
测量- 测量类型可以匹配表示数值测量的术语。 这些可以包括:
- 日期,例如“1997”、“Feb. 2, 1997”或“2/19/1997”
- 物理测量值,例如“1.85 厘米”、“12 英寸”
- 持续时间,“10 分钟”,“1 小时”
- 任何其他适当的数字测量
N-gram – n-gram 类型匹配答案中的任何 n-gram。 为避免生成过多的答案类型,系统可能会将 n-gram 答案元素限制为低于某个 n 值的 n-gram,这并不常见。 例如,系统可以将 n-gram 答案元素限制为具有满足阈值的逆文档频率分数的 1-gram 和 2-gram。
动词- 动词类型与系统确定为动词的任何术语相匹配。
介词- 介词类型匹配系统确定为介词的任何术语。
我们被告知系统可以为任何词性定义答案元素类型。
但是,在某些实现中,系统可能仅使用动词和介词类型。
Entity_instance – 实体实例类型匹配代表实体实例的 n-gram。
回答类型可以包括表示实体实例的回答元素,例如,(entity/Abraham_Lincoln)。
N-gram 实体附近——n-gram-near-entity 类型同时使用 n-gram 答案元素类型和实体实例答案元素类型,并且还限制了 n-gram 出现在答案中的实体实例附近。 当 n-gram 出现时,系统可以认为 n-gram 靠近实体实例:
- 出现在实体实例的阈值数量内的答案中
- 出现在与实体实例相同的句子中
- 出现在与实体实例相同的段落中
例如,在回答“Obama wasbirth in Honolulu”中,不常见的n-gram“Honolulu”出现在实体实例“Obama. 生成的答案类型包括 n-gram 和实体实例,例如,(檀香山附近的实体/奥巴马)
动词近实体——动词-近实体类型同时使用动词答案元素类型和实体实例答案元素类型,并类似地强加了动词出现在答案中实体实例附近的限制。 例如,对于“奥巴马出生在檀香山”,结果答案类型可以包括答案元素(实体/奥巴马近出生)。
介词近实体——介词-近实体类型同时使用介词答案元素类型和实体实例答案元素类型,同样限制介词出现在答案中的实体实例附近。 例如,对于“Obama wasbirth in Honolulu”,生成的答案类型可以包含答案元素(entity/Obama near in)
动词类- 动词类类型匹配表示动词类实例的 n-gram。 例如,系统可以将以下所有动词识别为类动词/混合的实例:添加、混合、组合、混合、连接、奶油、融合、连接、链接、合并、混合、混合、网络、池。 得到的答案类型包括表示动词类的问题元素,例如,(动词/混合)。
Skip gram ——skip-gram 类型指定了一个二元词,以及一些出现在二元词之间的词。 例如,如果跳过值为 1,则跳过语法“where * the”匹配以下所有 n-gram:“where is the”、“where was the”、“where did the”和“where has这。” 生成的答案类型包括一个代表二元组和跳过值的答案元素,例如,(where * the),其中单个星号代表跳过值 1。
系统计算问题类型/答案类型对的计数。
为问答对评分
该专利告诉我们,系统将为每个问题类型/答案类型对计算一个分数。
该分数基于“训练数据所反映的特定问题类型/答案类型对的预测质量”。
具有良好分数的问题类型/答案类型对很可能具有一个答案类型,该答案类型具有一个或多个答案元素,这些元素共同表示对由该问题类型表示的寻求答案的查询的正确答案的特征。
在计算特定问题类型/答案类型对的分数之前,系统通常会等到所有计数都计算完毕。
在一些实施方式中,系统计算每对的逐点互信息(PMI)分数。 PMI 分数为零表示问题和答案是独立的,没有关系。 另一方面,高分表示找到匹配相应问题类型的问题的答案的答案类型的可能性更高。
系统选择得分最高的问题类型/答案类型对。 可以对那些进行排序并且可以选择具有满足阈值的分数的对。
所选对的答案类型很可能代表相应问题类型所代表的寻求答案的查询的正确答案。
这个寻求答案的查询系统然后可以通过问题类型索引选择的问题类型/答案类型对,使得系统可以在在线评分期间有效地获得与特定问题类型相关联的所有答案类型。
它可以按分数对问题类型索引进行排序,以实时决定要尝试多少个答案类型。
该系统可以按分数对与问题类型相关联的每个答案类型进行排序,从而可以在查询时首先处理具有最高分数的答案类型。
为寻求答案的查询生成答案的过程
这项专利让我想起了我过去写过的另一项涉及回答问题的专利。 该专利是我在帖子中写的一项,Google 是否使用架构为精选片段编写答案段落?
那篇文章告诉我们,谷歌可能如何在对问题的精心编写的文本答案之间进行选择,这些问题也有与之相关的结构化数据,以便为这些答案提供额外的事实,但没有提供该专利通过查看答案元素所做的分析——寻求查询和这些答案的元素。
本专利中的描述以提供有关如何专门为寻求答案的查询生成答案的更多详细信息结束。
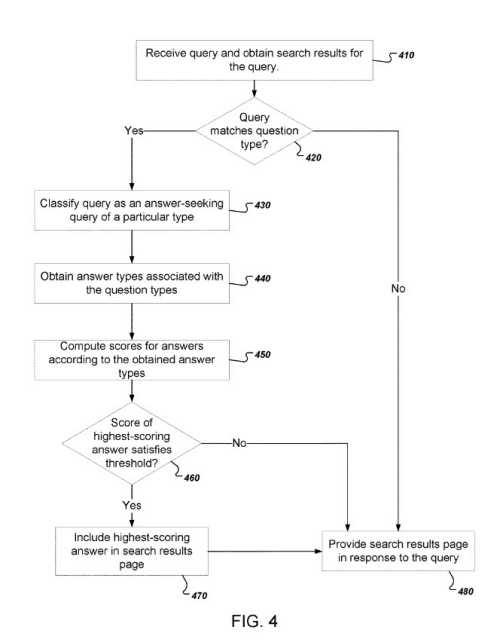
它首先接收查询并获得搜索结果
然后确定与查询匹配的问题类型。
如果查询不匹配任何生成的问题类型,则系统可以确定该查询不是寻求答案的查询。
如果是这样,它会在没有答案框的情况下响应,显示没有答案的搜索结果页面。
寻求答案的查询的类型由匹配问题类型的元素定义。 搜索系统然后可以决定可能是对寻求答案的查询的良好答案的文本段落。
为此,它可以访问将每个匹配的问题类型与一个或多个答案类型相关联的问题类型索引。
搜索系统可以根据从搜索中获得的答案类型来计算答案的分数。
搜索系统可以确定得分最高的答案的得分是否满足阈值。 如果分数不满足阈值,系统可以判定该答案不是查询的好答案,并且可以拒绝在搜索结果页面上显示该答案。
如果分数确实满足阈值,则搜索系统可以在搜索结果页面中包括得分最高的答案并响应于查询提供搜索结果页面。
寻求答案的最终结论
该专利确实提供了该专利中描述的过程如何工作的一些附加方面,并声明它可能还涉及不一定涵盖的其他步骤。
我已经指出了至少一项其他专利(关于如何查询的专利),它描述了如何选择答案的更多方面,而本专利中也没有详细说明。
因此,查看其他专利是有意义的,这些专利涵盖了响应查询的其他方面,这些方面专门侧重于寻求答案,例如我在上面链接到的有关自然语言答案和使用答案段落响应查询的专利。
在使用知识图回答问题一文中,我还写了关于谷歌如何生成知识图来响应查询,并考虑实体与这些实体的分类和属性之间的关联分数来回答问题。
对于这些帖子所涉及的不同专利中的方法如何组合在一起,我们没有明确的指导,但请注意它们存在并且在确定所有内容如何组合时,当 Google 可能会响应寻求答案的查询时可能会考虑这些方法有帮助。