
SEO для Headless CMS: на что обратить внимание
Опубликовано: 2020-11-30Оглавление
По сути, SEO для безголовой CMS по-прежнему следует тем же правилам, что и традиционная CMS. Таким образом, сканируемость, скорость и качество контента остаются целями, когда вы хотите вникнуть в это. Но хотя у нас схожие цели, средства для достижения этих целей в безголовой CMS разные.
Чем отличается SEO в безголовой CMS
В безголовой CMS большую часть работы по поисковой оптимизации приходится выполнять вручную, поскольку обычно нет плагинов или надстроек, облегчающих весь процесс, а это означает, что вам придется больше работать и большему количеству вещей нужно учиться в процессе, а не полагаться на сторонние инструменты. Более того, поскольку большинство безголовых CMS и интерфейсных фреймворков в настоящее время основаны на JavaScript, SEO для таких сред может быть сложным из-за того, что сканеры не могут легко отображать JavaScript.
Несмотря на то, что Googlebot может отображать JavaScript, мы не хотим на это полагаться.
Мартин Сплитт о реализации динамического рендеринга
Рекомендуемая литература: Headless CMS против традиционной CMS
На что обратить внимание в безголовой CMS
Альтернативные тексты
Замещающие тексты помогают сделать содержимое вашего изображения доступным для чтения ботами Google. Подобно пользовательским метаданным, альтернативный текст для изображений не является стандартной функцией в большинстве безголовых CMS, и это означает, что он должен быть реализован вашим поставщиком CMS.
Для безголовой CMS, в которой нет встроенной функции замещающего текста, мы можем вручную добавить замещающий текст для каждого изображения без особых усилий, так как вам нужно всего лишь добавить к изображениям атрибут <alt> .
<img src="image.png" alt="наш альтернативный текст">
Метаданные
Теги метаданных — это специальные теги, которые понимает Google Поиск. Эти теги описывают содержание вашего сайта и помогают контролировать отображение ваших страниц в поиске Google. И в отличие от традиционной CMS, безголовая CMS обычно не имеет возможности редактировать теги метаданных на лету, а это означает, что заголовок вашей страницы, описания и другие метатеги должны быть вручную добавлены в ваши модели контента.
Например, для безголового веб -сайта с интерфейсом на основе React, но без поддержки пользовательских метаданных, мы используем react-helmet для удобного добавления метаданных в наш <head> .
Для безголовой CMS, которая поддерживает пользовательские метаданные, обычно вам нужно добавить поля, содержащие настраиваемые теги метаданных, в вашу модель контента или создать пользовательскую модель SEO, в которой содержатся все необходимые метатеги. Созданная SEO-модель должна быть настроена так, чтобы иметь отношения ко всем страницам, которые в ней нуждаются.
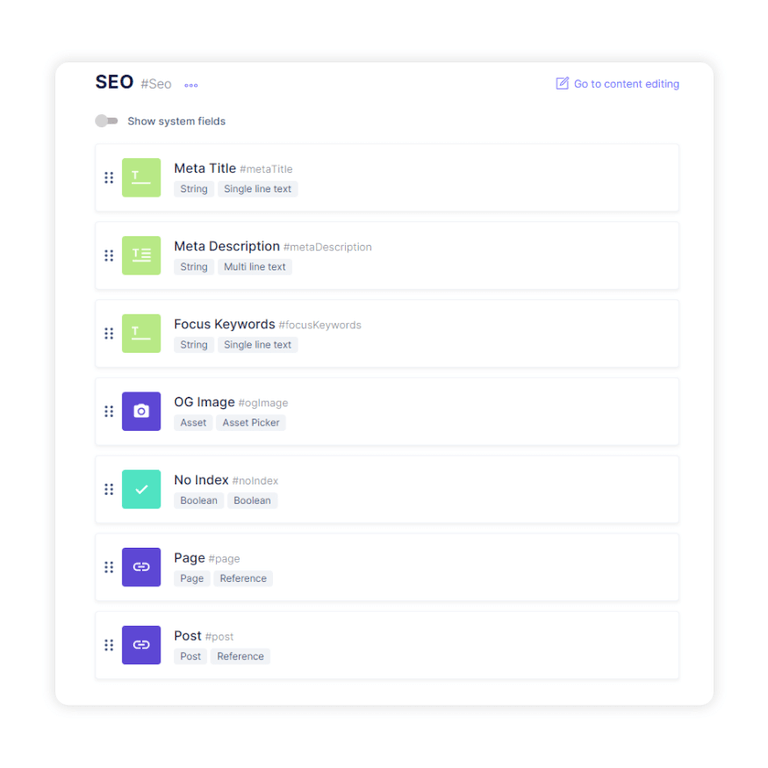
Фрагменты структурированных данных
Структурированные фрагменты данных помогают Google Поиску лучше понять вашу страницу и весь ее контент. Предоставляя действительные фрагменты структурированных данных, ваш сайт подходит для расширенных результатов.
Чтобы создать фрагмент структурированных данных, мы используем массив JSON-LD, который хранится в <head> вашего сайта. И в отличие от традиционной CMS, где весь процесс автоматизирован с помощью плагина (например, Yoast SEO), в безголовой CMS вам придется:
- Выберите правильные типы структурированных данных для своих страниц
- Добавьте пользовательский код JavaScript, который помогает генерировать либо все необходимые структурированные данные, либо добавлять дополнительную информацию к структурированным данным, отображаемым на стороне сервера.
выборка('https://api.example.com/recipes/123')
.тогда(ответ => ответ.текст())
.then (структурированный текст данных => {
const script = document.createElement('script');
script.setAttribute('тип', 'приложение/ld+json');
script.textContent = структурированный текст данных;
document.head.appendChild (скрипт);
});- Протестируйте свою реализацию с помощью Rich Results Test
Проблемы с отслеживанием просмотров страниц
Если вы когда-либо пытались внедрить Google Analytics на безголовый веб-сайт, вы, вероятно, заметили, что отслеживается только первый просмотр страницы вашего веб-сайта. Во многом это связано с тем, что внешний интерфейс безголовой CMS по своей природе является одностраничным приложением, а это означает, что страница загружается только один раз, и за сеанс запускается только одно событие pageView. Чтобы обойти эту проблему, мы реализуем History API, чтобы включить виртуальные просмотры страниц, которые затем можно отслеживать с помощью триггера изменения истории в Диспетчере тегов Google.
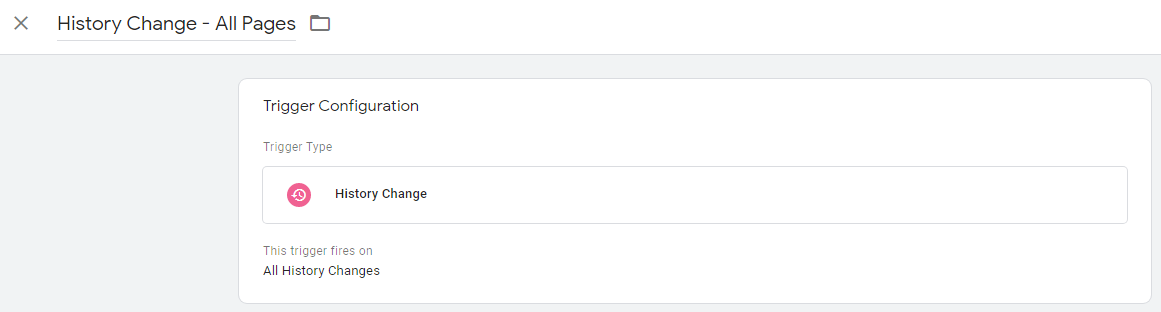
Триггер изменения истории отслеживает изменения во фрагменте URL или в объекте состояния истории. Когда между этими двумя происходит изменение, у нас есть следующие переменные:

- Старый фрагмент URL-адреса истории: каким был фрагмент URL-адреса.
- История нового фрагмента URL-адреса: какой сейчас фрагмент URL-адреса.
- Старое состояние истории: объект старого состояния истории, управляемый вызовами сайта к pushState.
- Новое состояние истории: новый объект состояния истории, управляемый вызовами сайта к pushState.
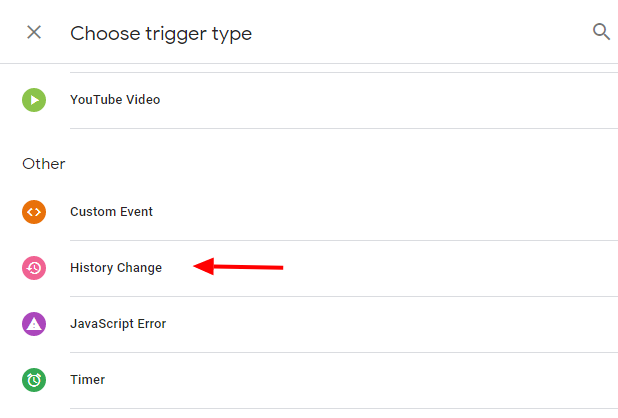
Чтобы создать триггер изменения истории, просто перейдите в Диспетчер тегов Google и:
- Выберите «Триггеры » > « Создать ».
- Выберите «Конфигурация триггера » > «Изменение истории».
После этого нам нужно создать новый тег конфигурации Google Analytics , чтобы активировать только что созданный триггер изменения истории, например:
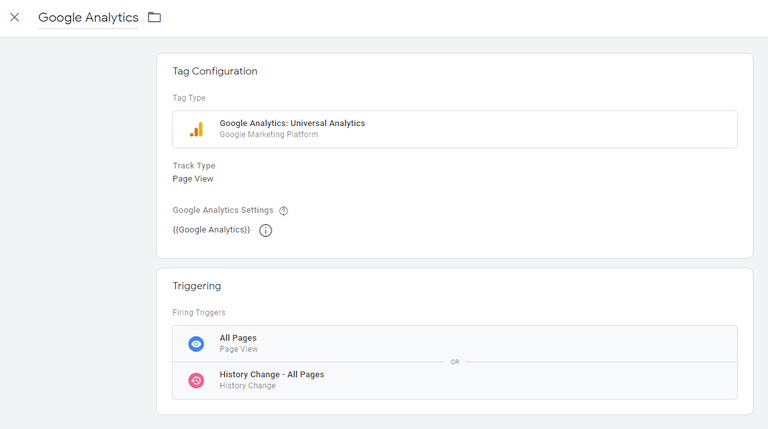
Вот и все. Теперь вы сможете отслеживать просмотры страниц на своем безголовом веб-сайте.
вопросы SEO-аудита
Поскольку ваш безголовый веб-сайт в основном состоит из клиентского JavaScript, его SEO-аудит может стать проблемой, поскольку сканеры, используемые в большинстве бесплатных инструментов SEO-аудита, не имеют возможности отображать JavaScript.
Ожидается, что эту проблему можно решить, заплатив больше, поскольку вы можете перейти на следующий премиальный план, чтобы включить поддержку этой функции. Вы также должны отметить, что рендеринг JavaScript не включен по умолчанию в большинстве инструментов SEO-аудита, а это означает, что вам придется вручную включить его для сканирования вашего веб-сайта без головы.
Разделение кода
Поскольку типичная безголовая CMS в значительной степени основана на JavaScript, объем кода JavaScript, используемого на вашем веб-сайте, особенно когда вы используете большое количество сторонних библиотек, может стать чрезмерным.

И, как мы все знаем, скорость страницы влияет на SEO, поэтому мы не можем оставить наш код JavaScript таким, поэтому разделение кода сделано, чтобы обойти эту проблему. С помощью разделения кода вы можете разделить свой JS-код на более мелкие пакеты, которые затем можно будет динамически загружать во время выполнения. В настоящее время эта функция поддерживается такими сборщиками, как Webpack и Browserify, через factor-bundle.
импортировать React, { Suspense, lazy } из 'React';
импортировать {BrowserRouter as Router, Route, Switch} из 'react-router-dom';
const Home = lazy(() => import('./routes/Home'));
const About = lazy(() => import('./routes/About'));
константное приложение = () => (
<Маршрутизатор>
<Задержка приостановки={<div>Загрузка...</div>}>
<Переключатель>
<Точный путь = "/" component={Home}/>
<Route path="/about" component={О программе}/>
</переключатель>
</приостановка>
</маршрутизатор>
);Динамический рендеринг
Поскольку большинство безголовых веб-сайтов по своей природе являются JavaScript, они сталкиваются с той же серьезной проблемой SEO, что и рендеринг JavaScript.
[…] JavaScript трудно обрабатывать, и не все сканеры поисковых систем могут обработать его успешно или сразу.
Внедрение динамического рендеринга, Google
Краулеры не могут эффективно отображать JavaScript, поэтому сами Google пока предлагают динамическую визуализацию в качестве обходного решения . Динамический рендеринг, представленный на конференции Google I/O '18, является идеальным решением для веб-сайтов на основе JavaScript, которым нужен простой способ решить проблемы SEO, сохраняя при этом все преимущества рендеринга на стороне клиента. Благодаря этому новому методу рендеринга ваш веб-сервер отправляет пользователям обычный контент, отображаемый на стороне клиента, в то время как сканеры поисковых систем получают полностью обработанный сервером статический HTML-контент.

Все это означает, что при динамическом рендеринге вы получаете лучшее из обоих миров — легкость сканирования при рендеринге на стороне сервера и быстрое последующее рендеринг при рендеринге на стороне клиента.
Для реализации динамического рендеринга нам придется полагаться на динамические рендереры, такие как Rendertron или Puppeteer, чтобы сократить весь процесс. Эти рендеры преобразуют содержимое вашего сайта в статический HTML, понятный поисковым роботам.
После завершения установки и настройки вашего динамического рендерера выполните дополнительные шаги в официальном документе Google, чтобы настроить поведение пользовательских агентов.
Вывод
SEO для безголовой CMS — не самый простой способ, и от ваших разработчиков потребуется немного работы, чтобы все сделать правильно. Но как только вы освоитесь, безголовая CMS может быть столь же эффективной, как и традиционная CMS, когда дело доходит до SEO. И более того, вы получаете гораздо больше свободы и гибкости для создания контента так, как вы хотите.