
Headless CMS 的 SEO:需要注意的事項
已發表: 2020-11-30目錄
從根本上說,無頭 CMS 的 SEO 仍然遵循與傳統 CMS 相同的規則。 因此,當您想要進入它時,可抓取性、速度和內容質量仍然是目標。 但是,儘管我們有類似的目標要實現,但在無頭 CMS 中實現這些目標的方法是不同的。
無頭 CMS 中的 SEO 有何不同
在無頭 CMS 中,大部分 SEO 工作必須手動完成,因為通常沒有插件或附加組件來簡化整個過程——這意味著您需要做更多的工作,並且在此過程中需要學習更多的東西,而不是依賴第三方工具。 此外,由於目前大多數無頭 CMS 和前端框架都是基於 JavaScript 的,因此由於爬蟲無法輕鬆呈現 JavaScript 的性質,此類環境的 SEO 可能會變得複雜。
即使 Googlebot 可以渲染 JavaScript,我們也不想依賴它。
Martin Splitt,關於實現動態渲染
推薦閱讀:無頭 CMS 與傳統 CMS
在無頭 CMS 中需要注意的事項
替代文本
替代文本有助於讓您的圖像內容被 Google 機器人讀取。 與自定義元數據類似,圖像的替代文本在大多數無頭 CMS 中不是開箱即用的功能,這意味著它必須由您的 CMS 提供商實施。
對於沒有內置替代文本功能的無頭 CMS,我們可以手動為每個圖像添加替代文本,因為您只需要為圖像添加<alt>屬性。
<img src="image.png" alt="我們的替代文字">
元數據
元數據標籤是 Google 搜索能夠理解的特殊標籤。 這些標籤描述了您網站的內容並幫助控制您的網頁在 Google 搜索中的顯示方式。 與傳統的 CMS 不同,無頭 CMS 通常不具備動態編輯元數據標籤的能力,這意味著您的頁面標題、描述和其他元標籤必須手動添加到您的內容模型中。
例如,對於具有基於React 的前端但不支持自定義元數據的無頭網站,我們使用 react-helmet 方便地將元數據添加到我們的<head>中。
對於支持自定義元數據的無頭 CMS,通常您需要將包含自定義元數據標籤的字段添加到您的內容模型中,或者創建一個自定義 SEO 模型,其中包含所有必要的元標籤。 創建的 SEO 模型應配置為與所有需要它的頁面有關係。
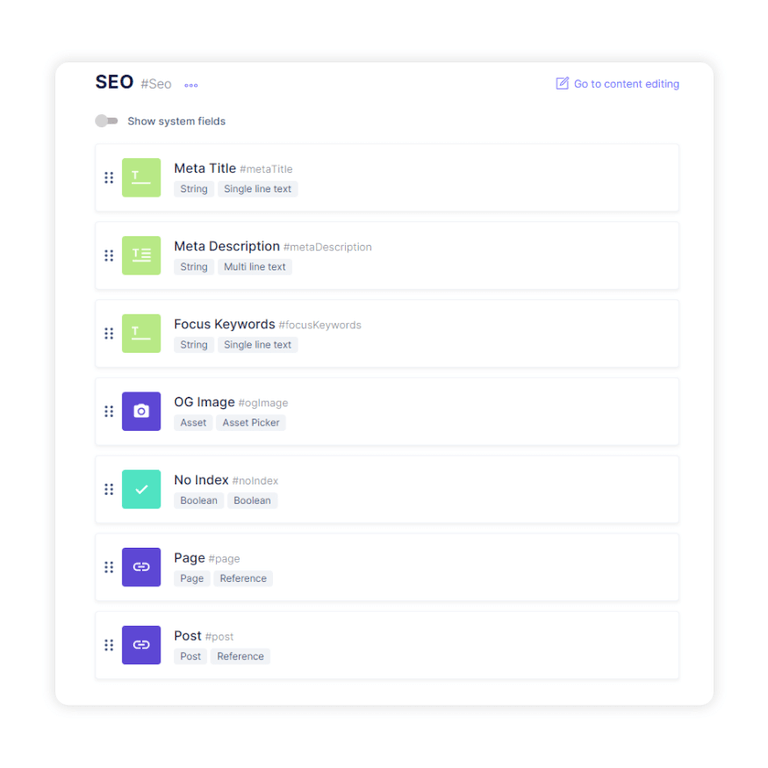
結構化數據片段
結構化數據片段可幫助 Google 搜索更好地了解您的網頁及其中的所有內容。 通過提供有效的結構化數據片段,您的網站可以獲得豐富的搜索結果。
為了創建結構化數據片段,我們使用存儲在您網站的<head>中的 JSON-LD 數組。 與使用插件(例如,Yoast SEO)自動化整個過程的傳統 CMS 不同,在無頭 CMS 中,您必須:
- 為您的頁面選擇正確的結構化數據類型
- 添加自定義 JavaScript 代碼,幫助生成所有需要的結構化數據或向服務器端呈現的結構化數據添加更多信息
fetch('https://api.example.com/recipes/123')
.then(response => response.text())
.then(結構化數據文本 => {
const script = document.createElement('script');
script.setAttribute('type', 'application/ld+json');
script.textContent = 結構化數據文本;
document.head.appendChild(腳本);
});- 使用 Rich Results Test 測試您的實現
瀏覽量跟踪問題
如果您曾嘗試在無頭網站上實施 Google Analytics,您可能會注意到僅跟踪您網站的第一次綜合瀏覽量。 這主要是因為無頭 CMS 的前端本質上是一個單頁應用程序,這意味著頁面只加載一次,並且每個會話只觸發一個 pageView 事件。 為了規避這個問題,我們實現了 History API 來啟用虛擬瀏覽量,然後可以使用 Google Tag Manager 中的 History Change 觸發器來跟踪這些瀏覽量。

歷史更改觸發器跟踪 URL 片段或歷史狀態對像中的更改。 當這兩者之間發生變化時,我們有以下變量:
- 歷史舊 URL 片段: URL 片段曾經是什麼。
- 歷史新 URL 片段:現在的 URL 片段是什麼。
- 歷史舊狀態:舊曆史狀態對象,由站點對 pushState 的調用控制。
- 歷史新狀態:新的歷史狀態對象,由站點對 pushState 的調用控制。
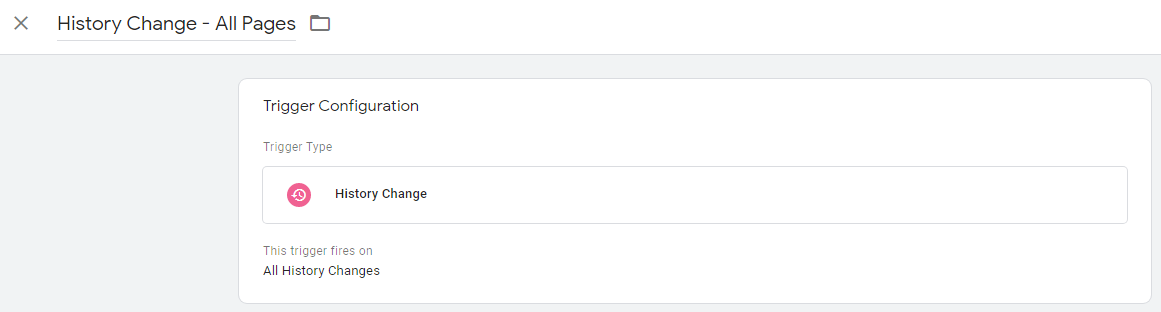
要創建歷史更改觸發器,只需轉到 Google 跟踪代碼管理器並:
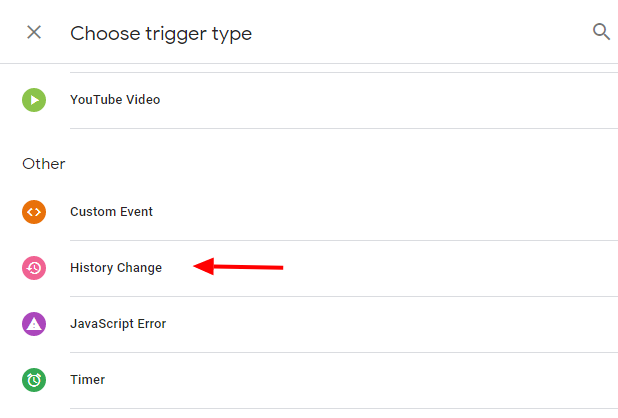
- 選擇觸發器>新建
- 選擇觸發器配置>歷史更改
在此之後,我們需要創建一個新的Google Analytics 配置代碼來觸發我們剛剛創建的歷史更改觸發器,如下所示:
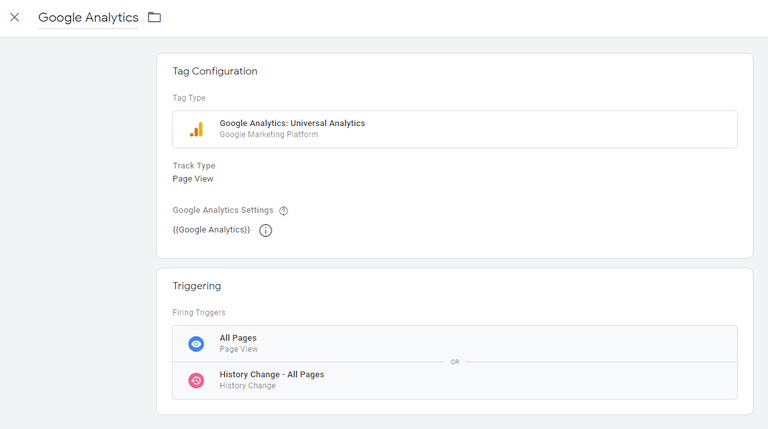
就是這樣。 您現在應該能夠跟踪無頭網站中的綜合瀏覽量。
SEO審核問題
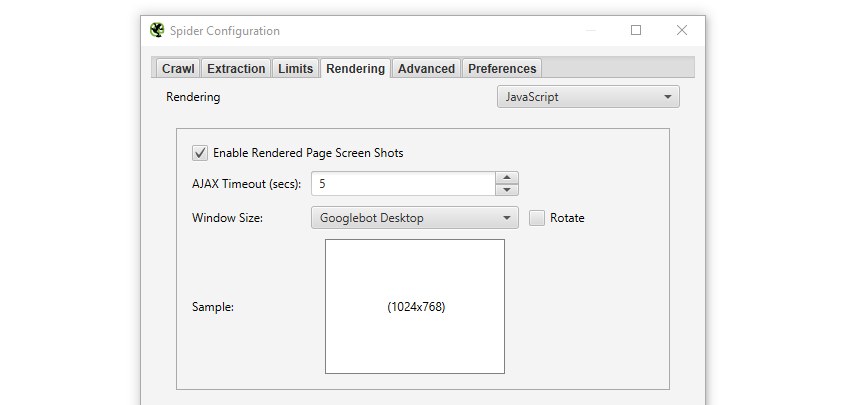
由於您的無頭網站主要由客戶端 JavaScript 組成,因此 SEO 審計可能會成為一個問題,因為大多數免費 SEO 審計工具中使用的爬蟲不具備呈現 JavaScript 的能力。
預計可以通過支付更多費用來解決此問題,因為您可以升級到下一個高級計劃以啟用對此功能的支持。 您還應該注意,大多數 SEO 審計工具默認不啟用JavaScript 渲染,這意味著您必須手動啟用它才能抓取無頭網站。
代碼拆分
由於典型的無頭 CMS 大量基於 JavaScript,因此您網站中使用的 JavaScript 代碼量(尤其是當您使用大量第三方庫時)可能會達到壓倒性的地步。

眾所周知,頁面速度會影響 SEO,所以我們不能讓我們的 JavaScript 代碼保持這種狀態,這就是為什麼要進行代碼拆分來規避這個問題的原因。 通過代碼拆分,您可以將 JS 代碼拆分為更小的包,然後可以在運行時動態加載這些包。 目前,Webpack 和 Browserify 等打包工具通過 factor-bundle 支持此功能。
從“反應”中導入反應,{懸念,懶惰};
從 'react-router-dom' 導入 { BrowserRouter as Router, Route, Switch };
const Home = lazy(() => import('./routes/Home'));
const About = lazy(() => import('./routes/About'));
常量應用 = () => (
<路由器>
<Suspense fallback={<div>加載中...</div>}>
<開關>
<Route exact path="/" component={Home}/>
<Route path="/about" 組件={About}/>
</開關>
</懸念>
</路由器>
);動態渲染
由於大多數無頭網站本質上都是 JavaScript,因此它們面臨著與 JavaScript 渲染相同的主要 SEO 挑戰。
[...],處理 JavaScript 很困難,而且並非所有搜索引擎爬蟲都能成功或立即處理它。
實現動態渲染,谷歌
爬蟲無法有效地渲染 JavaScript,因此 Google 自己同時建議將動態渲染作為一種解決方案。 在 Google I/O '18 中引入的動態渲染是基於 JavaScript 的網站的理想解決方案,這些網站需要一種簡單的方法來解決 SEO 挑戰,同時仍保留客戶端渲染帶來的所有好處。 使用這種新的呈現方法,您的 Web 服務器向用戶發送正常的、客戶端呈現的內容,而搜索引擎爬蟲則獲得完全由服務器呈現的靜態 HTML 內容。

所有這一切意味著您可以通過動態渲染獲得兩全其美的優勢——服務器端渲染的可爬取性和客戶端渲染的快速後續渲染。
要實現動態渲染,我們將不得不依賴 Rendertron 或 Puppeteer 等動態渲染器來縮短整個過程。 這些渲染會將您網站的內容轉換為爬蟲可以理解的靜態 HTML。
完成安裝和配置動態渲染器後,按照谷歌官方文檔中的附加步驟配置用戶代理的行為。
結論
無頭 CMS 的 SEO 並不是最直接的方法,它需要您的開發人員進行一些工作才能使一切正確。 但是一旦你掌握了它的竅門,在 SEO 方面,無頭 CMS 可以與傳統 CMS 一樣有效。 更重要的是,您可以獲得更多的自由和靈活性,以您想要的方式創建內容。