
SEO สำหรับ Headless CMS: สิ่งที่ต้องให้ความสนใจ
เผยแพร่แล้ว: 2020-11-30สารบัญ
โดยพื้นฐานแล้ว SEO สำหรับ CMS ที่ไม่มีส่วนหัวยังคงใช้กฎเดียวกันกับ CMS ดั้งเดิม ดังนั้นความสามารถในการรวบรวมข้อมูล ความเร็ว และคุณภาพของเนื้อหายังคงเป็นเป้าหมายเมื่อคุณต้องการเข้าถึง แต่ถึงแม้เราจะมีเป้าหมายที่คล้ายคลึงกันที่จะบรรลุเป้าหมาย แต่วิธีการที่จะบรรลุเป้าหมายเหล่านี้ก็แตกต่างกันใน CMS แบบไม่มีหัว
SEO แตกต่างอย่างไรใน CMS ที่ไม่มีส่วนหัว
ใน CMS ที่ไม่มีส่วนหัว งาน SEO ส่วนใหญ่จะต้องดำเนินการด้วยตนเอง เนื่องจากโดยทั่วไปแล้วจะไม่มีปลั๊กอินหรือส่วนเสริมที่ช่วยให้กระบวนการทั้งหมดง่ายขึ้น และนี่หมายถึงการทำงานให้คุณมากขึ้น และมีสิ่งที่ต้องเรียนรู้ในกระบวนการมากกว่า อาศัยเครื่องมือของบุคคลที่สาม นอกจากนี้ เนื่องจาก CMS ที่ไม่มีส่วนหัวและเฟรมเวิร์กส่วนหน้าส่วนใหญ่ในขณะนี้เป็นแบบ JavaScript ดังนั้น SEO สำหรับสภาพแวดล้อมดังกล่าวจึงอาจซับซ้อนได้เนื่องจากลักษณะของโปรแกรมรวบรวมข้อมูลไม่สามารถแสดง JavaScript ได้อย่างง่ายดาย
แม้ว่า Googlebot สามารถแสดง JavaScript ได้ แต่เราไม่ต้องการพึ่งพาสิ่งนั้น
Martin Splitt ในการใช้การเรนเดอร์แบบไดนามิก
การอ่านที่แนะนำ: Headless CMS เทียบกับ CMS ดั้งเดิม
สิ่งที่ต้องระวังใน CMS ที่ไม่มีหัว
ข้อความแสดงแทน
ข้อความแสดงแทนช่วยให้บอทของ Google อ่านเนื้อหารูปภาพของคุณได้ เช่นเดียวกับข้อมูลเมตาที่กำหนดเอง ข้อความแสดงแทนสำหรับรูปภาพไม่ใช่คุณลักษณะสำเร็จรูปใน CMS ที่ไม่มี ส่วน หัวส่วนใหญ่ และนี่หมายความว่าผู้ให้บริการ CMS ของคุณต้องติดตั้งใช้งาน
สำหรับ CMS ที่ไม่มีส่วนหัวซึ่งไม่มีฟีเจอร์ข้อความแสดงแทนในตัว เราสามารถเพิ่มข้อความแสดงแทนต่อภาพได้ด้วยตนเองโดยไม่ต้องใช้ความพยายามมากนัก เนื่องจากคุณเพียงแค่ต้องเพิ่มแอตทริบิวต์ <alt> ให้กับรูปภาพของคุณ
<img src="image.png" alt="ข้อความแสดงแทนของเรา">
ข้อมูลเมตา
แท็กข้อมูลเมตาเป็นแท็กพิเศษที่ Google Search เข้าใจ แท็กเหล่านี้อธิบายเนื้อหาของไซต์ของคุณและช่วยควบคุมลักษณะที่หน้าเว็บของคุณจะปรากฏใน Google Search และตรงกันข้ามกับ CMS แบบดั้งเดิม CMS ที่ไม่มีส่วนหัวมักจะ ไม่มี ความสามารถในการแก้ไขแท็กข้อมูลเมตาได้ทันที ซึ่งหมายความว่าต้องเพิ่มชื่อหน้า คำอธิบาย และเมตาแท็กอื่นๆ ของหน้าเว็บลงในโมเดลเนื้อหาด้วยตนเอง
ตัวอย่างเช่น สำหรับเว็บไซต์ที่ไม่มีส่วนหัวที่มีส่วนหน้าที่ใช้ React แต่ไม่มีการสนับสนุนสำหรับข้อมูลเมตาที่กำหนดเอง เราใช้ react-helmet เพื่อเพิ่มข้อมูลเมตาลงใน <head> ของเราได้อย่างสะดวก
สำหรับ CMS ที่ไม่มีส่วนหัวซึ่งสนับสนุนข้อมูลเมตาที่กำหนดเอง โดยทั่วไปแล้ว คุณจะต้องเพิ่มฟิลด์ที่มีแท็กข้อมูลเมตาที่กำหนดเองลงในโมเดลเนื้อหาของคุณ หรือเพื่อสร้างโมเดล SEO ที่กำหนดเองซึ่งมีเมตาแท็กที่จำเป็นทั้งหมด โมเดล SEO ที่สร้างขึ้นควรได้รับการกำหนดค่าให้มีความสัมพันธ์กับเพจทั้งหมดที่ต้องการ
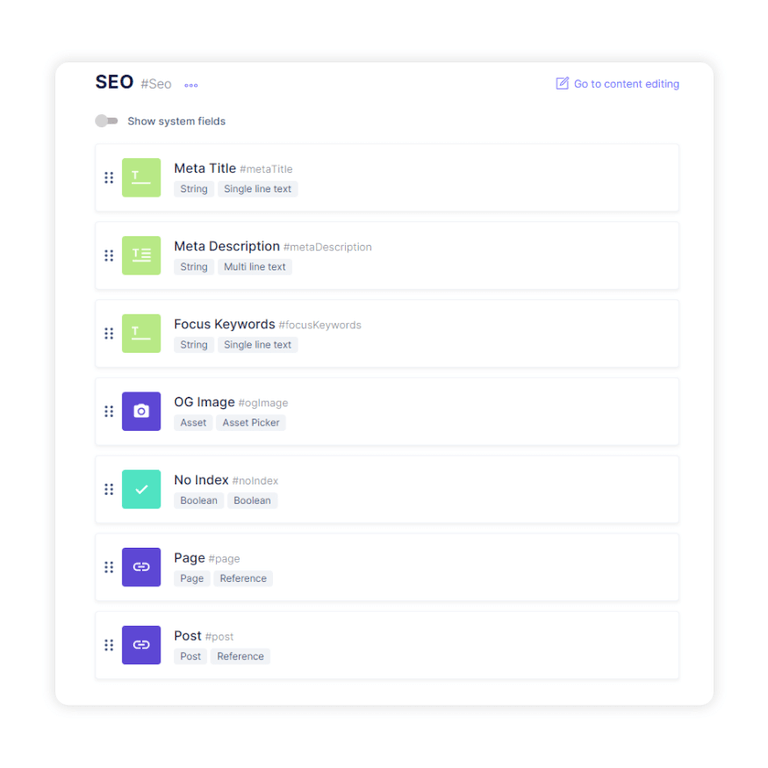
ตัวอย่างข้อมูลที่มีโครงสร้าง
ตัวอย่างข้อมูลที่มีโครงสร้างช่วยให้ Google Search เข้าใจหน้าเว็บของคุณและเนื้อหาทั้งหมดภายในหน้าได้ดียิ่งขึ้น การให้ข้อมูลโค้ดที่มีโครงสร้างที่ถูกต้องจะทำให้เว็บไซต์ของคุณมีสิทธิ์แสดงผลการค้นหาที่เป็นสื่อสมบูรณ์
ในการสร้างข้อมูลโค้ดที่มีโครงสร้าง เราใช้อาร์เรย์ JSON-LD ซึ่งจัดเก็บไว้ใน <head> ของไซต์ของคุณ และไม่เหมือนกับ CMS แบบเดิมที่กระบวนการทั้งหมดเป็น แบบอัตโนมัติด้วยปลั๊กอิน (เช่น Yoast SEO) ใน CMS แบบไม่มีส่วนหัว คุณจะต้อง:
- เลือกประเภทข้อมูลที่มีโครงสร้างที่ถูกต้องสำหรับเพจของคุณ
- เพิ่มโค้ด JavaScript ที่กำหนดเองซึ่งช่วยสร้างข้อมูลที่มีโครงสร้างที่จำเป็นทั้งหมดหรือเพิ่มข้อมูลเพิ่มเติมไปยังข้อมูลที่มีโครงสร้างที่แสดงฝั่งเซิร์ฟเวอร์
ดึงข้อมูล ('https://api.example.com/recipes/123')
.then(การตอบสนอง => response.text())
.then (structuredDataText => {
สคริปต์ const = document.createElement('script');
script.setAttribute('type', 'application/ld+json');
script.textContent = structuredDataText;
document.head.appendChild(สคริปต์);
});- ทดสอบการใช้งานของคุณโดยใช้การทดสอบผลการค้นหาที่เป็นสื่อสมบูรณ์
ปัญหาการติดตามการดูหน้าเว็บ
หากคุณเคยพยายามใช้ Google Analytics บนเว็บไซต์ที่ไม่มีหัวเรื่อง คุณอาจสังเกตเห็นว่ามีเพียงการดูหน้าเว็บครั้งแรกของเว็บไซต์ของคุณเท่านั้นที่จะถูกติดตาม สาเหตุส่วนใหญ่มาจากข้อเท็จจริงที่ว่าส่วนหน้าของ CMS แบบไม่มีส่วนหัวนั้นเป็นแอปพลิเคชันแบบหน้าเดียว ซึ่งหมายความว่าหน้าเว็บจะโหลดเพียงครั้งเดียว และมีการทริกเกอร์เหตุการณ์ pageView เพียงรายการเดียวเท่านั้นต่อเซสชัน เพื่อหลีกเลี่ยงปัญหานี้ เราใช้ API ประวัติเพื่อเปิดใช้งานการดูหน้าเว็บเสมือน ซึ่งสามารถติดตามได้โดยใช้ทริกเกอร์การเปลี่ยนแปลงประวัติใน Google Tag Manager
ทริกเกอร์การเปลี่ยนประวัติสำหรับการเปลี่ยนแปลงในส่วนของ URL หรือในออบเจ็กต์สถานะประวัติ เมื่อมีการเปลี่ยนแปลงระหว่างสองสิ่งนี้ เรามีตัวแปรดังต่อไปนี้:

- ประวัติส่วน URL เก่า: ส่วน ใดของ URL ที่เคยเป็น
- ประวัติส่วน URL ใหม่: ตอนนี้ส่วนย่อยของ URL คืออะไร
- สถานะ เก่าของประวัติ: ออบเจ็กต์สถานะประวัติเก่า ควบคุมโดยการเรียกของไซต์ไปที่ pushState
- สถานะ ใหม่ของประวัติ: ออบเจ็กต์สถานะประวัติใหม่ ควบคุมโดยการเรียกของไซต์ไปที่ pushState
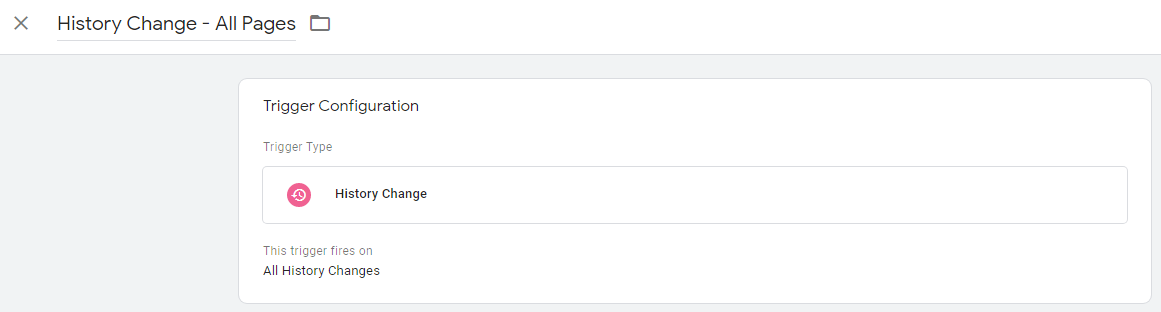
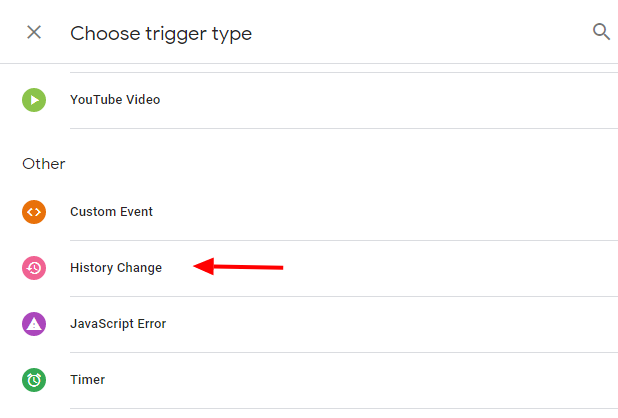
หากต้องการสร้างทริกเกอร์การเปลี่ยนแปลงประวัติ เพียงไปที่ Google Tag Manager และ:
- เลือก ทริกเกอร์ > ใหม่
- เลือกการ กำหนดค่าทริกเกอร์ > การเปลี่ยนแปลงประวัติ
หลังจากนี้ เราจะต้องสร้างแท็กการ กำหนดค่า Google Analytics ใหม่เพื่อเริ่มทำงานในทริกเกอร์การเปลี่ยนแปลงประวัติที่เราเพิ่งสร้างขึ้น เช่น:
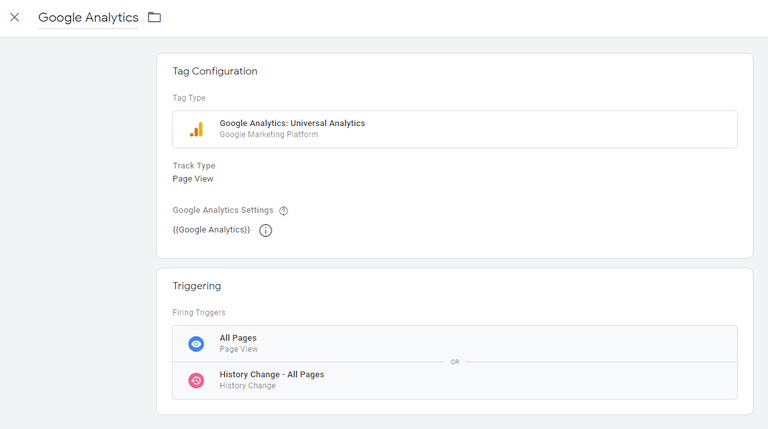
และนั่นแหล่ะ ตอนนี้คุณควรจะสามารถติดตามการเปิดดูหน้าเว็บในเว็บไซต์ที่ไม่มีหัวเรื่องได้แล้ว
ปัญหาการตรวจสอบ SEO
เนื่องจากเว็บไซต์ที่ไม่มีส่วนหัวของคุณส่วนใหญ่ทำจาก JavaScript ฝั่งไคลเอ็นต์ การตรวจสอบ SEO จึงอาจเป็นปัญหาได้เนื่องจากโปรแกรมรวบรวมข้อมูลที่ใช้ในเครื่องมือตรวจสอบ SEO ฟรีส่วนใหญ่ไม่มีความสามารถในการแสดง JavaScript
ปัญหานี้ คาดว่าจะแก้ไขได้ด้วยการจ่ายเงินมากขึ้น เนื่องจากคุณสามารถอัปเกรดเป็นแผนพรีเมียมถัดไปเพื่อเปิดใช้งานการสนับสนุนคุณลักษณะนี้ คุณควรทราบด้วยว่าการแสดงผล JavaScript ไม่ได้เปิดใช้งานโดยค่าเริ่มต้น ในเครื่องมือตรวจสอบ SEO ส่วนใหญ่ ซึ่งหมายความว่าคุณจะต้องเปิดใช้งานด้วยตนเองเพื่อรวบรวมข้อมูลเว็บไซต์ที่ไม่มีส่วนหัว
การแยกรหัส
เนื่องจาก CMS ที่ไม่มีส่วนหัวทั่วไปนั้นใช้ JavaScript เป็นหลัก จำนวนโค้ด JavaScript ที่ใช้ในเว็บไซต์ของคุณ โดยเฉพาะอย่างยิ่งเมื่อคุณใช้ไลบรารีของบุคคลที่สามจำนวนมาก สามารถไปถึงจุดที่ล้นหลามได้

และอย่างที่เราทราบกันดีว่าความเร็วของหน้าส่งผลต่อ SEO ดังนั้นเราจึงไม่สามารถให้โค้ด JavaScript ของเราคงสภาพเช่นนี้ได้ ซึ่งเป็นเหตุให้มีการแยกโค้ดเพื่อหลีกเลี่ยงปัญหานี้ ด้วยการแยกโค้ด คุณสามารถแบ่งโค้ด JS ของคุณออกเป็นบันเดิลที่มีขนาดเล็กลง ซึ่งสามารถโหลดไดนามิกที่รันไทม์ได้ ปัจจุบันฟีเจอร์นี้รองรับโดยบันเดิล เช่น Webpack และ Browserify ผ่าน factor-bundle
นำเข้า React, { Suspense, lazy } จาก 'react';
นำเข้า { BrowserRouter เป็นเราเตอร์, เส้นทาง, สวิตช์ } จาก 'react-router-dom';
const Home = lazy(() => import('./routes/Home'));
const About = lazy(() => import('./routes/About'));
แอป const = () => (
<เราเตอร์>
<Suspense fallback={<div>กำลังโหลด...</div>}>
<สวิตช์>
<เส้นทางที่แน่นอนเส้นทาง="/" component={Home}/>
<เส้นทางเส้นทาง="/เกี่ยวกับ" component={About}/>
</Switch>
</ใจจดใจจ่อ>
</Router>
);การแสดงผลแบบไดนามิก
เนื่องจากเว็บไซต์ที่ไม่มีส่วนหัวส่วนใหญ่มีลักษณะเป็น JavaScript พวกเขาจึงต้องเผชิญกับความท้าทายด้าน SEO ที่สำคัญเช่นเดียวกันกับการแสดงผล JavaScript
[…] เป็นการยากที่จะประมวลผล JavaScript และโปรแกรมรวบรวมข้อมูลของเครื่องมือค้นหาบางโปรแกรมไม่สามารถประมวลผลได้สำเร็จหรือในทันที
การใช้ Dynamic Rendering, Google
โปรแกรมรวบรวมข้อมูลไม่สามารถแสดงผล JavaScript ได้อย่างมีประสิทธิภาพ เหตุใด Google จึงแนะนำ Dynamic Rendering เป็น วิธีแก้ปัญหาชั่วคราวในระหว่าง นี้ การแสดงผลแบบไดนามิกที่เปิดตัวใน Google I/O '18 เป็นโซลูชันในอุดมคติสำหรับเว็บไซต์ที่ใช้ JavaScript ที่ต้องการวิธีง่ายๆ ในการแก้ปัญหาความท้าทายด้าน SEO ในขณะที่ยังคงรักษาผลประโยชน์ทั้งหมดที่มาพร้อมกับการแสดงผลฝั่งไคลเอ็นต์ ด้วยวิธีการแสดงผลใหม่นี้ เว็บเซิร์ฟเวอร์ของคุณจะส่งเนื้อหาปกติที่แสดงผลฝั่งไคลเอ็นต์ไปยังผู้ใช้ ในขณะที่โปรแกรมรวบรวมข้อมูลของเครื่องมือค้นหาจะได้รับเนื้อหา HTML แบบคงที่ที่แสดงโดยเซิร์ฟเวอร์ทั้งหมด

ทั้งหมดนี้หมายความว่าคุณจะได้รับสิ่งที่ดีที่สุดจากทั้งสองโลกด้วยการแสดงผลแบบไดนามิก—ความง่ายในการรวบรวมข้อมูลของการแสดงผลฝั่งเซิร์ฟเวอร์และการแสดงผลฝั่งไคลเอ็นต์ที่ตามมาอย่างรวดเร็ว
ในการใช้การเรนเดอร์แบบไดนามิก เราจะต้องพึ่งพาตัวเรนเดอร์ไดนามิก เช่น Rendertron หรือ Puppeteer เพื่อทำให้กระบวนการทั้งหมดสั้นลง การแสดงผลเหล่านี้จะแปลงเนื้อหาของไซต์ของคุณเป็น HTML แบบคงที่ที่โปรแกรมรวบรวมข้อมูลสามารถเข้าใจได้
หลังจากติดตั้งและกำหนดค่าตัวแสดงไดนามิกของคุณเสร็จแล้ว ให้ทำตามขั้นตอนเพิ่มเติมในเอกสารอย่างเป็นทางการของ Google เพื่อกำหนดค่าการทำงานของตัวแทนผู้ใช้
บทสรุป
SEO สำหรับ CMS ที่ไม่มีส่วนหัวไม่ใช่วิธีที่ตรงไปตรงมาที่สุด และ จะ ต้องอาศัยการทำงานเล็กน้อยจากนักพัฒนาซอฟต์แวร์ของคุณจึงจะทำทุกอย่างให้ถูกต้อง แต่เมื่อคุณคุ้นเคยกับมันแล้ว CMS แบบไม่มีหัวจะมีประสิทธิภาพพอๆ กับ CMS แบบเดิมๆ เมื่อพูดถึง SEO และยิ่งไปกว่านั้น คุณจะได้รับอิสระและความยืดหยุ่นมากขึ้นในการสร้างเนื้อหาในแบบที่คุณต้องการ