
谷歌向我们展示了在索引人员时上下文为王
已发表: 2017-12-12
语境为王
有时,您会看到有人写关于 SEO 的文章说“内容为王”。 但是,当我看到这一点时,我常常想回应:“语境为王。”
在正确的时间满足某人搜索意图的正确词可以满足他们的信息甚至情境需求。 当您编写页面时,您应该包含有助于展示您在创建页面时可能关注的关键字上下文的词。
更多关于 Context 的专利
最近,我注意到来自谷歌的专利专注于上下文。 第一个是关于上下文向量的专利。 我在帖子中写了这些上下文向量:Google Patents Context Vectors to Improvement Search。
在帖子中,Domorrow Deliver Topical Search Results at Google?,我写了一篇关于谷歌专利的文章,该专利告诉我们搜索引擎可能会在每个搜索结果之前开始显示面包屑,这可能会显示可能具有多个含义的查询词的含义.
注意到谷歌如何在索引页面和在搜索结果中显示页面时更加关注上下文,谷歌最近的一项专利中的“上下文”一词引起了我的注意。 尤其是当我看到我今天正在写的“使用上下文术语进行名称消歧”时。
考虑一个常见的名字,例如 John Smith。 有一位来自英国的著名的约翰史密斯,他以发现北美第一个永久英国定居点詹姆斯敦的殖民地而闻名。 还有一位著名的植物学家约翰·史密斯。 该专利告诉我们,它可能会识别一些可能与每个 John Smith 相关联的上下文词汇术语。 因此,如果有人搜索 John Smith 和 Kew Gardens,他们很可能正在寻找植物学家。 另一个寻找 John Smith 和 Virginia 的人很可能正在寻找探险家。
该专利通过类似的例子确定了它旨在解决的问题:
一个非常流行的搜索场景是搜索个人姓名。 由于大多数人名都不是唯一的,因此对一个人名的初始搜索可能会产生多个搜索结果,每个搜索结果都引用了描述不同人的资源。 例如,搜索“约翰·史密斯”的名字可能会产生搜索结果,这些搜索结果引用了关于探险家信息的资源、关于植物学家和邱园馆长的资源、关于职业摔跤手的资源,以及关于其他人的其他资源被命名为“约翰史密斯”。 由于搜索查询通常是对所需信息的不完整表达,因此用户通常会修改搜索查询以关注搜索结果。 此类修订包括向名称添加其他搜索词。 例如,假设用户正在搜索与探索者 John Smith 与首席 Powhatan 的交互有关的信息。 用户可以修改查询以阅读“John Smith Chief Powhatan”。 搜索查询将导致搜索引擎提供参考文档的搜索结果,这些文档更可能满足用户的信息需求。
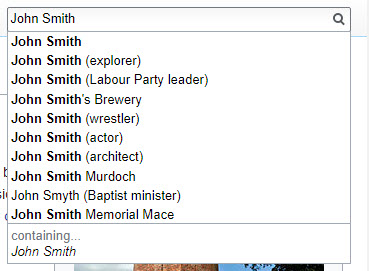
当维基百科有一个关于多个同名人的条目时,它包含“消歧”信息。 除了此人的姓名外,它还可能包含其他术语以标识所指的人。 就约翰史密斯而言,我正在写的可能是:
约翰·史密斯(植物学家)
约翰·史密斯(探险家)
这些代表性术语可以从搜索建议中获取:
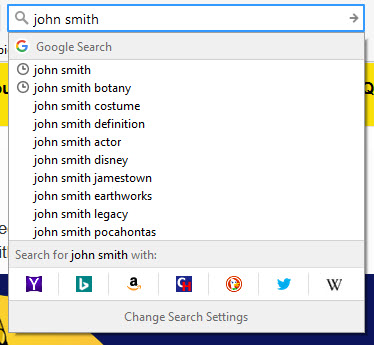
查询词和代表词可能看起来像维基百科中的消歧词:
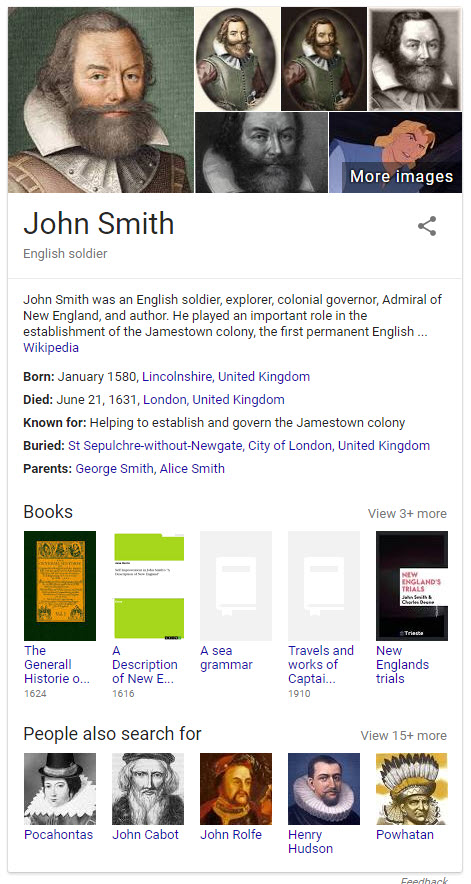
专利中没有提到的是,我们可能会看到识别这些不同约翰史密斯的知识面板:

约翰·史密斯(探险家):
约翰·史密斯(植物学家):
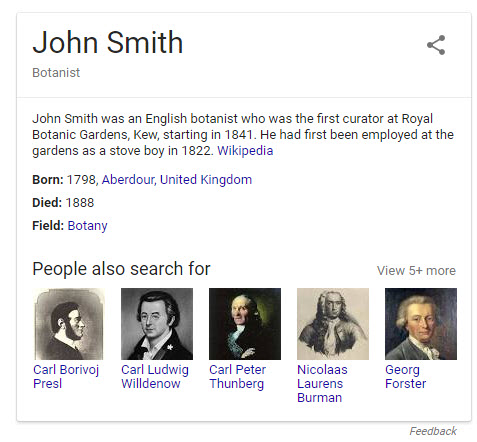
Google 如何跟踪不同的 John Smiths?
1. 为人名创建上下文术语列表:
...每个上下文术语列表是来自人名资源的上下文术语列表,并且每个人名上下文术语列表对应的资源是不同的资源; 将上下文术语列表聚类成多个集群,每个上下文术语列表集群包括相对于其他集群与该集群最相似的上下文术语列表; 对于每个集群,为集群选择一个代表词; 接收人名作为搜索查询; 并且从搜索查询和集群的代表词生成多个查询建议,每个查询建议是人名和一个代表词的组合。
2. 这种上下文方法的优点,根据专利:
向用户提供个人姓名的查询建议,每个建议都代表与姓名关联的上下文。 每个上下文都用于消除名称的歧义,因此用户可以快速将搜索集中在适当的上下文上,而无需手动确定各种上下文。 否则将具有主导解释的人名(例如,名人或历史人物的名字)在上下文之间消除歧义,并且主导解释仅限于上下文的适当子集。 因此,系统可以为主导解释和与主导解释不相关联的多个其他上下文提供查询建议。
3. 指代同一个人的资源(即,在上下文中消除歧义的名称)可以单独聚集。
其他可能具有多个含义的术语(例如 Jaguar)可能将结果单独聚类。 例如,Jaguar Car、Jaguar cat 和 Jacksonville Jaguar NFL 橄榄球运动员。
上下文专利
可以在以下位置找到有关上下文和名称的专利:
使用上下文术语进行名称消歧
发明人:Nitin Gupta 和 Abhinandan S. Das
受让人:谷歌公司
美国专利:9,830,379
授予日期:2017 年 11 月 28 日
提交时间:2010 年 11 月 29 日
抽象的
用于消除文档语料库中名称歧义的方法、系统和装置,包括编码在计算机存储介质上的计算机程序。 在一个方面,一种方法包括为人名生成上下文术语列表,每个上下文术语列表是来自该人名的资源的上下文术语列表; 将上下文术语列表聚类成多个集群,每个上下文术语列表集群包括相对于其他集群与该集群最相似的上下文术语列表; 对于每个集群,为集群选择一个代表词; 接收人名作为搜索查询; 并且从搜索查询和集群的代表词生成多个查询建议,每个查询建议是人名和一个代表词的组合。
外卖
就像有关上下文向量的专利所描述的那样,知识库可能有助于查找有关潜在独特人员的信息。 例如,迈克尔杰克逊是著名的流行歌手。 还有一位迈克尔杰克逊,他是国土安全部的行政长官。 我们可以从迈克尔杰克逊(消歧义)页面了解到这一点,就像什么时候可以为马术、木匠和体操运动员查找不同类型的马匹一样。 可以采用有助于定义每个含义和人的上下文的术语。
这个消歧专利告诉我们用于查找页面的查询可以向我们显示与人名相关的不同上下文。 如果您正在为特定的人优化页面,那么包含有助于定义您所写对象的上下文术语是有意义的。
如果可以使用有助于定义一个人的上下文的术语,在您创建的页面上包含这些术语可以帮助通过注意上下文来索引合适的人。