
Googleは、人々のインデックスを作成するときにコンテキストが重要であることを示しています
公開: 2017-12-12
コンテキストは王様
時々、SEOについて書いている誰かが「コンテンツは王様だ」と言うのを見るでしょう。 しかし、それを見ると、「文脈が王様だ」と答えたくなることがよくあります。
誰かが検索する意図を満たす適切なタイミングで適切な言葉を使用することで、情報や状況に応じたニーズを満たすことができます。 あなたがページを書くとき、あなたがその作成の間にあなたが焦点を合わせているかもしれないキーワードの文脈を誇示するのを助けることができる言葉を含めるべきです。
コンテキストに関するその他の特許
最近、私は文脈に焦点を当てたグーグルからの特許に気づいています。 最初の1つは、コンテキストベクトルに関する特許でした。 私はこれらのコンテキストベクトルについて投稿しました:検索を改善するためのGoogle特許コンテキストベクトル。
投稿「明日はGoogleでトピック検索結果を提供しますか?」で、検索エンジンがすべての検索結果の前にパンくずリストを表示し始め、複数の意味を持つ可能性のあるクエリ用語の意味を示す可能性があることを示したGoogle特許について書きました。
Googleがページのインデックス作成や検索結果へのページの表示でコンテキストにどのように注意を払っているのかに気づいたので、Googleのごく最近の特許の「コンテキスト」という単語が私の注意を引きました。 特に、今日書いている「文脈用語を使った名前の曖昧性解消」を見たとき。
JohnSmithなどの一般名を考えてみましょう。 北米で最初の恒久的な英国人入植地であるジェームズタウンの植民地を発見したことで知られるイギリス出身の有名なジョン・スミスがいます。 植物学者としてよく知られている別のジョン・スミスがいます。 この特許は、各ジョン・スミスに関連する可能性のあるいくつかの文脈語彙用語を特定する可能性があることを示しています。 したがって、誰かがJohnSmithとKewGardensを検索する場合、彼らは植物学者を探している可能性があります。 ジョン・スミスとバージニアを探している別の人は、おそらく探検家を探しています。
この特許は、同様の例で解決しようとしている問題を特定しています。
非常に人気のある検索シナリオは、個人名の検索です。 ほとんどの人名は一意ではないため、人の名前を最初に検索すると、それぞれが異なる人を説明するリソースを参照する複数の検索結果が得られる可能性があります。 たとえば、「ジョンスミス」という名前で検索すると、探検家に関する情報、キューガーデンの植物学者と学芸員に関するリソース、プロレスラーに関するリソース、その他の人々に関するリソースを参照する検索結果が得られる場合があります。 「ジョン・スミス」という名前です。 検索クエリは必要な情報の不完全な表現であることが多いため、ユーザーは検索結果に焦点を合わせるために検索クエリを修正することがよくあります。 名前に検索語を追加するなどの改訂。 たとえば、ユーザーが探索者のジョン・スミスとチーフ・ポウハタンとのやり取りに関連する情報を検索しているとします。 ユーザーはクエリを修正して、「ジョンスミスチーフポウハタン」を読むことができます。 検索クエリにより、検索エンジンは、ユーザーの情報ニーズを満たす可能性が高いドキュメントを参照する検索結果を提供します。
ウィキペディアに同じ名前の複数の人物に関するエントリがある場合、「曖昧性解消」情報が含まれています。 人の名前に加えて、どの人が参照されているかを識別するための他の用語が含まれている場合があります。 ジョン・スミスの場合、私は次のように書いています。
ジョン・スミス(植物学者)
ジョン・スミス(探検家)
これらの代表的な用語は、検索候補から取得できます。
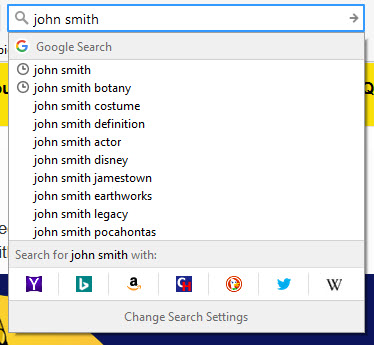
クエリ用語と代表的な用語は、ウィキペディアにある曖昧性解消用語のように見える場合があります。
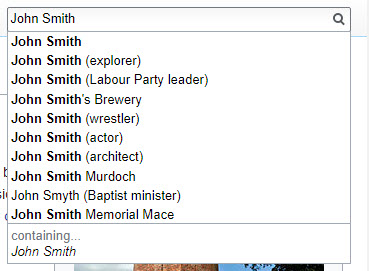
特許で言及されていないのは、これらの異なるジョン・スミスのそれぞれを識別する知識パネルが表示される可能性があるということです。
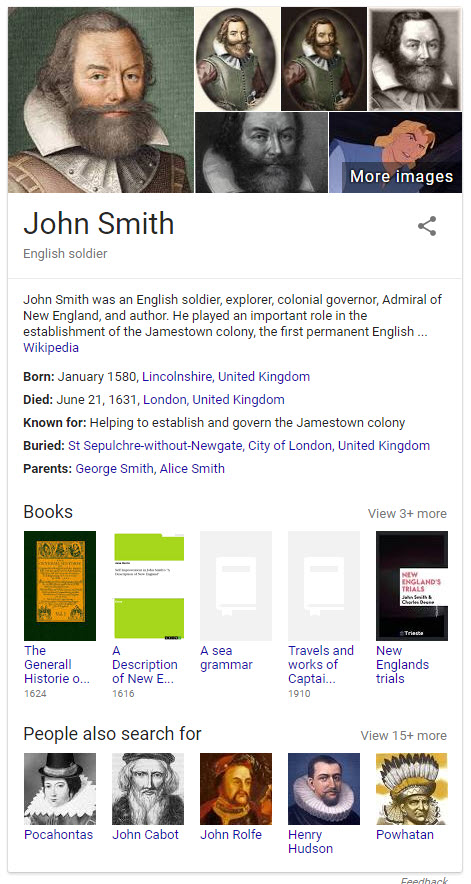
ジョン・スミス(探検家):

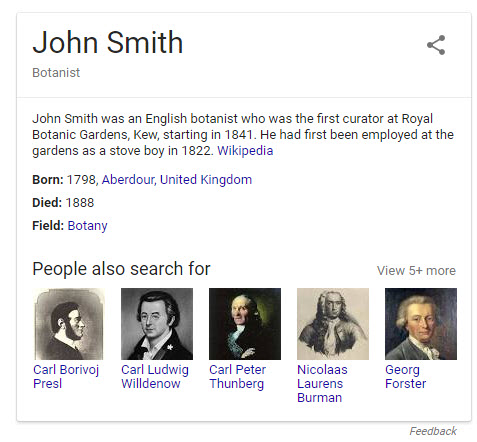
ジョン・スミス(植物学者):
Googleはさまざまなジョンスミスをどのように追跡していますか?
1.コンテキスト用語リストは、人の名前に対して作成されます。
…各コンテキスト用語リストは、個人名のリソースからのコンテキスト用語のリストであり、個人名のコンテキスト用語リストが対応する各リソースは、異なるリソースです。 文脈用語リストを複数のクラスターにクラスター化し、文脈用語リストのクラスターのそれぞれは、他のクラスターと比較してクラスターに最も類似している文脈用語リストを含む。 クラスターごとに、クラスターの代表的な用語を選択します。 検索クエリとして個人名を受け取る。 そして、検索クエリとクラスタの代表的な用語から複数のクエリ提案を生成します。各クエリは、人物名と1つの代表的な用語の組み合わせであることを提案します。
2.特許によると、このコンテキストアプローチの利点は次のとおりです。
ユーザーには個人名のクエリ提案が提供され、各提案は名前に関連付けられたコンテキストを表します。 各コンテキストは名前の曖昧さを解消するために使用されるため、ユーザーはさまざまなコンテキストを手動で決定しなくても、適切なコンテキストにすばやく検索を集中できます。 そうでなければ支配的な解釈を持つ人の名前(例えば、有名人や歴史上の人物の名前)は文脈間で明確にされ、支配的な解釈は文脈の適切なサブセットに制限されます。 したがって、システムは、ドミナント解釈およびドミナント解釈に関連付けられていない他の複数のコンテキストに対するクエリ提案を提供できます。
3.同じ人物を参照するリソース(つまり、コンテキスト間で明確にされた名前)は、個別にクラスター化される場合があります。
ジャガーのように、複数の意味を持つ可能性のある他の用語では、結果が個別にクラスター化される場合があります。 たとえば、ジャガーカー、ジャガー猫、ジャクソンビルジャガーNFLのフットボール選手。
コンテキスト特許
コンテキストと名前に関する特許は、次の場所にあります。
文脈用語を使用した名前の曖昧性解消
発明者:NitinGuptaおよびAbhinandanS。Das
譲受人:Google Inc.
米国特許:9,830,379
付与:2017年11月28日
提出日:2010年11月29日
概要
文書コーパス内の名前を明確にするための、コンピュータ記憶媒体にエンコードされたコンピュータプログラムを含む方法、システム、および装置。 一態様では、方法は、人名のコンテキスト用語リストを生成することを含み、各コンテキスト用語リストは、人名のリソースからのコンテキスト用語のリストである。 文脈用語リストを複数のクラスターにクラスター化し、文脈用語リストのクラスターのそれぞれは、他のクラスターと比較してクラスターに最も類似している文脈用語リストを含む。 クラスターごとに、クラスターの代表的な用語を選択します。 検索クエリとして個人名を受け取る。 そして、検索クエリとクラスタの代表的な用語から複数のクエリ提案を生成します。各クエリは、人物名と1つの代表的な用語の組み合わせであることを提案します。
テイクアウト
コンテキストベクトルに関する特許が説明しているように、知識ベースは潜在的にユニークな人々に関する情報を見つけるのに役立つ可能性があります。 たとえば、マイケルジャクソンは有名な人気歌手でした。 国土安全保障省の管理者であったマイケルジャクソンもいました。 これは、マイケルジャクソン(曖昧さ回避)ページから学ぶことができます。馬術、大工、体操選手のさまざまな種類の馬をいつ調べることができるかと同じです。 それらの意味と人のそれぞれの文脈を定義するのに役立つ用語をとることは可能です。
この曖昧性解消特許は、ページを見つけるために使用されるクエリが、人々の名前に関連するさまざまなコンテキストを示すことができることを示しています。 特定の人のためにページを最適化する場合は、誰について書いているのかを定義するのに役立つコンテキスト用語を含めるのが理にかなっています。
人のコンテキストを定義するのに役立つ用語を使用できる場合は、それらについて作成するページにそれらの用語を含めると、コンテキストに注意を払うことで適切な人のインデックスを作成するのに役立ちます。