
Aprendizaje automático para un modelo de clasificación
Publicado: 2021-05-05Aprendizaje automático en Google
Esta patente de Google trata de entrenar un modelo de aprendizaje automático para clasificar documentos en respuesta a consultas de búsqueda.

Los motores de búsqueda en línea, como Google, clasifican los documentos en respuesta a consultas de búsqueda para presentar resultados de búsqueda llenos de documentos que responden a una consulta de búsqueda.
Los motores de búsqueda suelen mostrar los resultados de la búsqueda en un orden definido por una clasificación.
Los motores de búsqueda clasifican los documentos utilizando varios factores con diversas técnicas de clasificación.
Un motor de búsqueda puede clasificar documentos basándose en un modelo de aprendizaje automático de clasificación que recibe características de un documento de entrada y, posiblemente, la consulta de búsqueda recibida y luego generará una puntuación de clasificación para el documento de entrada.
Esta patente describe el entrenamiento de un modelo de aprendizaje automático de clasificación.
Usar Machine Learning para entrenar un modelo de clasificación
La patente de hoy fue otorgada el 29 de abril de 2021. Se enfoca en recibir datos de entrenamiento para un modelo de aprendizaje automático de clasificación para clasificar documentos en respuesta a consultas de búsqueda.
Los datos de entrenamiento incluyen ejemplos de entrenamiento. Cada ejemplo de entrenamiento incluye datos que identifican:
- Consulta de busqueda
- Documentos de resultado de una lista de resultados para la consulta de búsqueda
- Documentos de resultado seleccionados por un buscador de la lista de resultados de documentos de resultados
La patente trata de recibir datos de posición para cada uno de los ejemplos de entrenamiento en los datos de entrenamiento.
Los datos de posición identifican la posición del documento de resultado seleccionado en las SERP para la consulta de búsqueda en el ejemplo de entrenamiento.
Determinar, para cada ejemplo de entrenamiento, los datos de posición y el valor de sesgo de selección que representa en qué resultado afectará la selección del documento de resultado.
Determinando un valor de importancia respectivo para cada ejemplo de entrenamiento a partir del valor de sesgo de selección para el ejemplo de entrenamiento, el valor de importancia define cuán importante es el ejemplo de entrenamiento en el entrenamiento del modelo de aprendizaje automático de clasificación.
Además, el proceso patentado puede incluir las siguientes características en combinación:
- Recibir datos de experimentos que identifican muchas consultas de búsqueda de experimentos, cada una de las cuales ocupa una posición respectiva en una lista de resultados de experimentos de documentos de resultados de experimentos para la consulta de búsqueda de experimentos de un documento de resultados de experimentos seleccionado por un buscador, donde las posiciones de los documentos de resultados de experimentos en las listas de resultados de experimentos fueron permutados aleatoriamente antes de ser presentados a los buscadores
- Determinar para cada posición, un recuento respectivo de selecciones de documentos de resultados de experimentos en la posición por parte de los buscadores en respuesta al número de consultas de búsqueda de experimentos en los datos del experimento; y determinar, para cada una de la pluralidad de posiciones, un valor de sesgo de posición respectivo para la posición en base al recuento respectivo de selecciones para la posición
- Asignar el valor de sesgo de posición respectivo correspondiente a la posición del documento de resultado seleccionado en la lista de resultados de documentos de resultado para el ejemplo de entrenamiento para que sea el valor de sesgo de selección para el ejemplo de entrenamiento
Donde las consultas de búsqueda de experimentos en el número de consultas de búsqueda de experimentos pertenecen cada una a una clase de consulta respectiva de una pluralidad de clases de consulta, el método incluye, para cada una de la pluralidad de clases de consulta:
- Determinar, para cada uno de los números de posiciones, un recuento de selecciones de documentos de resultados de experimentos en la posición por parte de los buscadores que responden a las consultas de búsqueda de experimentos que pertenecen a la clase de consulta en los datos del experimento.
- Determinar, para cada una de la pluralidad de posiciones, un valor de sesgo de posición específico de clase respectivo para la posición en función del recuento respectivo de selecciones para la posición
- Obtener datos que identifican una clase de consulta a la que pertenece la consulta de búsqueda para el ejemplo de entrenamiento
- Asignar el valor de sesgo de posición específico de la clase para la clase de consulta a la que pertenece la consulta de búsqueda
- Corresponde a la posición del documento de resultado seleccionado para el ejemplo de formación en la lista de resultados de los documentos de resultado para ser el valor de sesgo de selección para el ejemplo de formación
- Obtener un vector de características respectivo para cada consulta de búsqueda de experimento, generar datos de entrenamiento para entrenar un clasificador que recibe un vector de características respectivo para una consulta de búsqueda de entrada y genera un valor de sesgo de posición específico de la consulta respectiva para cada una de una pluralidad de posiciones para la búsqueda de entrada consulta y entrenamiento del clasificador en los datos de entrenamiento
- Obtener un vector de características para la consulta de búsqueda en el ejemplo de entrenamiento
- Procesar el vector de características usando el clasificador entrenado para generar un valor de sesgo de posición específico de consulta respectivo para cada una de la pluralidad de posiciones para la consulta de búsqueda en el ejemplo de entrenamiento
- Asignar el valor de sesgo de posición específico de la consulta correspondiente a la posición del documento de resultado seleccionado para el ejemplo de entrenamiento en la lista de resultados de documentos de resultado para la consulta de búsqueda para que sea el valor de sesgo de selección para el ejemplo de entrenamiento
- Etiquetar la consulta de búsqueda del experimento como un ejemplo positivo para la posición en la lista de resultados del experimento de los documentos de resultados para la consulta de búsqueda del experimento del resultado de la búsqueda del experimento que el buscador seleccionó y etiquetar la consulta de búsqueda del experimento como un ejemplo negativo para otras posiciones del pluralidad de posiciones
- Entrenamiento del modelo de aprendizaje automático de clasificación en los datos de entrenamiento utilizando los valores de importancia respectivos para la pluralidad de ejemplos de entrenamiento en los datos de entrenamiento
- Determinar, para cada ejemplo de entrenamiento de la pluralidad de ejemplos de entrenamiento en los datos de entrenamiento, una pérdida respectiva para el ejemplo de entrenamiento.
- Ajustar, para cada ejemplo de entrenamiento de la pluralidad de ejemplos de entrenamiento en los datos de entrenamiento, la pérdida del ejemplo de entrenamiento basado en el valor de importancia del ejemplo de entrenamiento para generar una pérdida ajustada.
- Entrenamiento del modelo de aprendizaje automático utilizando las pérdidas ajustadas para la pluralidad de ejemplos de entrenamiento en los datos de entrenamiento.
El método incluye entrenar el modelo de aprendizaje automático minimizando una suma de las pérdidas ajustadas para la pluralidad de datos de entrenamiento.
Ventajas de seguir este modelo de clasificación de aprendizaje automático
Los modelos de datos de click-through convencionales pueden estimar la relevancia para pares de consulta-documento individuales en el contexto de la búsqueda web.
Esos modelos de datos de clics convencionales generalmente requieren muchos clics para cada par de consultas individuales y documentos de resultados. Esto hace que los modelos de datos de clics sean difíciles de aplicar cuando los datos de clics son muy escasos debido a los corpus personalizados y las necesidades de información, por ejemplo, búsqueda personal.
En comparación con los modelos de datos de clics convencionales, un sistema que utiliza el sesgo de selección para varias posiciones de la lista de resultados cuando se entrena un modelo de clasificación puede aprovechar de manera más efectiva los datos de clics dispersos mientras reduce o elimina los efectos del sesgo de selección en las puntuaciones de clasificación generadas por los capacitados. modelo.
Esto significa que el modelo entrenado puede proporcionar puntuaciones de clasificación precisas incluso cuando los datos de los clics son muy escasos, lo que significa que los resultados de búsqueda satisfacen mejor las necesidades de información de los buscadores.
Esta patente se puede encontrar en:
Entrenamiento de un modelo de clasificación
Número de patente: US20210125108
Inventores Donald Arthur Metzler, Jr., Xuanhui Wang, Marc Alexander Najork y Michael Bendersky
Solicitantes Google LLC
Fecha de concesión: 29 de abril de 2021
Fecha de presentación 24 de octubre de 2016
Abstracto
Métodos, sistemas y aparatos, incluidos programas informáticos codificados en un medio de almacenamiento informático, para entrenar un modelo de aprendizaje automático de clasificación. En un aspecto, un método incluye las acciones de recibir datos de entrenamiento para un modelo de aprendizaje automático de clasificación, los datos de entrenamiento incluyen ejemplos de entrenamiento, y cada ejemplo de entrenamiento incluye datos que identifican: una consulta de búsqueda, resultado en documentos de una lista de resultados para la consulta de búsqueda , y un documento de resultado que fue seleccionado por un buscador de la lista de resultados, recibiendo datos de posición para cada ejemplo de entrenamiento en los datos de entrenamiento, identificando los datos de posición una posición respectiva del documento de resultado seleccionado en la lista de resultados para la consulta de búsqueda en el ejemplo de formación; determinar, para cada ejemplo de entrenamiento en los datos de entrenamiento, un valor de sesgo de selección respectivo; y determinar un valor de importancia respectivo para cada ejemplo de entrenamiento a partir del valor de sesgo de selección para el ejemplo de entrenamiento, el valor de importancia.
Un ejemplo de sistema de búsqueda de aprendizaje automático
Un buscador puede interactuar con el sistema de búsqueda a través de un dispositivo de búsqueda.
El dispositivo de búsqueda puede ser un ordenador acoplado al sistema de búsqueda a través de una red de comunicación de datos, por ejemplo, una red de área local (LAN) o una red de área amplia (WAN), por ejemplo, Internet, o una combinación de redes.
En algunos casos, el sistema de búsqueda se puede implementar en el dispositivo de búsqueda si un buscador instala una aplicación que realiza búsquedas en el dispositivo de búsqueda.
El dispositivo de búsqueda incluirá generalmente una memoria, por ejemplo, una memoria de acceso aleatorio (RAM), para almacenar instrucciones y datos y un procesador para ejecutar instrucciones almacenadas. La memoria puede incluir tanto memoria de solo lectura como de escritura.
Generalmente, el sistema de búsqueda se puede configurar para buscar una colección específica de documentos que están asociados con el buscador del dispositivo buscador.
El término "documento" se utilizará ampliamente para incluir cualquier producto de trabajo legible y almacenable por máquina.
Los documentos pueden incluir:
- Correo electrónico
- Un archivo
- Una combinación de archivos
- Uno o más archivos con enlaces incrustados a otros archivos
- Publicación de un grupo de noticias
- Un blog
- Una lista de empresas
- Una versión electrónica de texto impreso.
- Un anuncio web
- Etc.
La colección de documentos que el sistema de búsqueda está configurado para buscar puede enviarse por correo electrónico en una cuenta de correo electrónico del buscador, datos de aplicaciones móviles asociados con una cuenta del buscador, por ejemplo, preferencias de aplicaciones móviles o historial de uso de aplicaciones móviles. , archivos asociados con el buscador en una cuenta de almacenamiento de documentos en la nube, por ejemplo, archivos cargados por el buscador o archivos compartidos con el buscador por otros buscadores, o una colección de documentos diferente específica del buscador.
Un buscador puede enviar consultas de búsqueda al sistema de búsqueda utilizando el dispositivo de búsqueda. Cuando el buscador envía una consulta de búsqueda, la consulta de búsqueda se transmite a través de la red al sistema de búsqueda.
Cuando el sistema de búsqueda recibe la consulta de búsqueda, un motor de búsqueda dentro del sistema de búsqueda identifica documentos en la colección de documentos que satisfacen la consulta de búsqueda y responde a la consulta generando resultados de búsqueda que identifican cada uno un documento respectivo que satisface la búsqueda y se transmite a través de / la red al dispositivo de búsqueda para su presentación al buscador, es decir, en una forma que se puede presentar al buscador.
El motor de búsqueda puede incluir un motor de indexación y un motor de clasificación. El motor de indexación indexa documentos en las colecciones de documentos y agrega los documentos indexados a una base de datos de índices. El motor de clasificación genera puntuaciones respectivas para los documentos en la base de datos del índice que satisfacen la consulta de búsqueda y clasifican los documentos en función de sus puntuaciones respectivas.
Generalmente, los resultados de la búsqueda se muestran al buscador; una lista de resultados se ordena de acuerdo con las puntuaciones de clasificación generadas por el motor de clasificación para los documentos identificados por los resultados de búsqueda 128. Por tanto, por lo tanto, un resultado de búsqueda que identifica un documento con una puntuación más alta se puede presentar en una posición más alta en el resultado lista que un resultado de búsqueda que identifica un documento con una puntuación relativamente más baja.
El motor de clasificación genera puntuaciones de clasificación para documentos utilizando un modelo de aprendizaje automático de clasificación.
El modelo de aprendizaje automático de clasificación es un modelo de aprendizaje automático entrenado para recibir características u otros datos que caracterizan un documento de entrada y, opcionalmente, datos que caracterizan la consulta de búsqueda y para generar una puntuación de clasificación para el documento de entrada.
El modelo de aprendizaje automático de clasificación puede usar una variedad de modelos de aprendizaje automático.
El modelo de aprendizaje automático de clasificación puede ser un modelo de aprendizaje automático profundo, por ejemplo, una red neuronal, que incluye múltiples capas de operaciones no lineales.
O el modelo de aprendizaje automático de clasificación puede ser un modelo de aprendizaje automático superficial, por ejemplo, un modelo lineal generalizado.
Dependiendo de cómo se haya entrenado el modelo de aprendizaje automático de clasificación, la puntuación de clasificación puede predecir la relevancia del documento de entrada para la consulta de búsqueda o puede tener en cuenta tanto la relevancia del documento de entrada como la calidad independiente de la consulta del documento de entrada.
En algunas implementaciones, el motor de clasificación modifica las puntuaciones de clasificación generadas por el modelo de aprendizaje automático de clasificación en función de otros factores y clasifica los documentos utilizando las puntuaciones de clasificación modificadas.
Para entrenar el modelo de aprendizaje automático de clasificación de modo que el modelo pueda usarse en la clasificación de documentos en respuesta a las consultas de búsqueda recibidas, el sistema de búsqueda también incluye un motor de entrenamiento.

El motor de entrenamiento entrena el modelo de aprendizaje automático de clasificación en datos de entrenamiento que incluyen varios ejemplos de entrenamiento.
Cada ejemplo de entrenamiento identifica
- (i) una consulta de búsqueda
- (ii) documentos de resultado de la lista de resultados para la consulta de búsqueda
- (iii) un documento de resultado que fue seleccionado por un buscador de la lista de resultados de documentos de resultado para la consulta de búsqueda
Como se describe en esta patente, una selección de un documento de resultado en respuesta a una consulta de búsqueda es seleccionar un resultado de búsqueda que identifica el documento de resultado de una lista de resultados de resultados de búsqueda presentados en respuesta al envío de una consulta por parte de un buscador. Los SERP son los documentos que se identifican por los resultados de la búsqueda en la lista de resultados.
Para mejorar la calidad de las puntuaciones de clasificación del modelo de aprendizaje automático de clasificación una vez entrenado, el motor de entrenamiento se entrena de una manera que tiene en cuenta la lista de resultados del resultado de búsqueda que seleccionó el buscador.
El motor de entrenamiento determina un valor de importancia respectivo para cada ejemplo de entrenamiento basado en la posición en la lista de resultados del resultado de búsqueda que el buscador seleccionó en respuesta a la consulta de búsqueda en el ejemplo de entrenamiento.
Al entrenar el modelo de aprendizaje automático de esta manera, el motor de entrenamiento reduce o elimina el impacto del sesgo de posición en las puntuaciones de clasificación generadas por el modelo de aprendizaje automático de clasificación una vez que el modelo ha sido entrenado.
Determinar un valor de importancia respectivo para cada ejemplo de entrenamiento en los datos de entrenamiento
El sistema recibe datos de posición, que identifican una posición respectiva en la lista de resultados para la consulta de búsqueda que el buscador seleccionó en respuesta a la consulta de búsqueda, es decir, el resultado de búsqueda que el buscador seleccionó de la lista de resultados generada en respuesta a la consulta de búsqueda. .
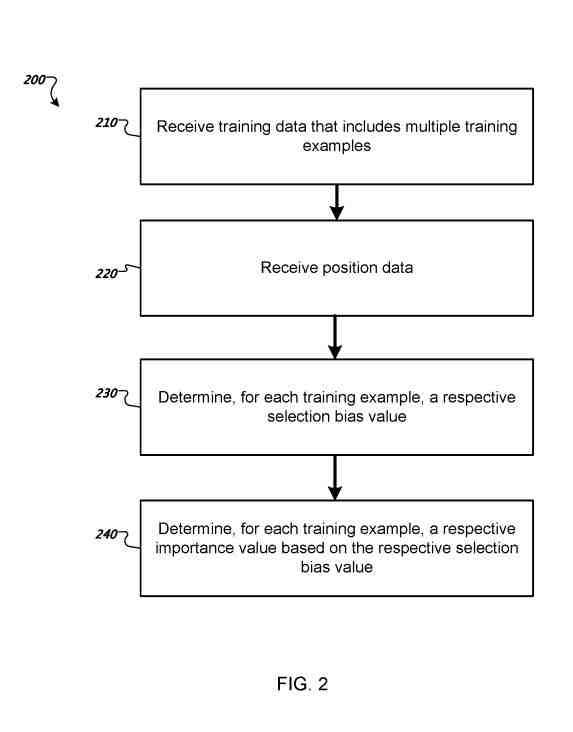
El sistema determina un valor de sesgo de selección respectivo, que representa un grado en el que la posición del documento de resultado seleccionado en la lista de resultados para la consulta de búsqueda en el ejemplo de formación afectó la selección del documento de resultado.
El valor del sesgo de selección se puede determinar de muchas formas.
El sistema determina, para cada ejemplo de entrenamiento en los datos de entrenamiento, un valor de importancia respectivo.
El valor de importancia para un ejemplo de entrenamiento dado define qué tan importante es el ejemplo de entrenamiento en el entrenamiento del modelo de aprendizaje automático de clasificación.
El valor de importancia respectivo para cada ejemplo de entrenamiento en los datos de entrenamiento se puede determinar basándose en el valor de sesgo de selección respectivo para el ejemplo de entrenamiento.
Por ejemplo, el valor de importancia para un ejemplo de entrenamiento particular puede ser el inverso del valor de sesgo de selección para el ejemplo de entrenamiento o, más generalmente, ser inversamente proporcional al valor de sesgo de selección para el ejemplo de entrenamiento.
Una vez que el sistema determina los valores de importancia respectivos para los datos de entrenamiento de los datos de entrenamiento, el sistema entrena el modelo de aprendizaje automático de clasificación en los datos de entrenamiento usando los valores de importancia.
Determinar un valor de sesgo de selección respectivo para cada ejemplo de entrenamiento en los datos de entrenamiento
El sistema recibe datos de experimentos que identifican las consultas de búsqueda de experimentos. Para cada consulta de búsqueda de experimentos, una posición respectiva en una lista de resultados de experimentos de documentos de resultados de experimentos para la consulta de búsqueda de experimentos de un experimento da como resultado un documento que un buscador seleccionó.
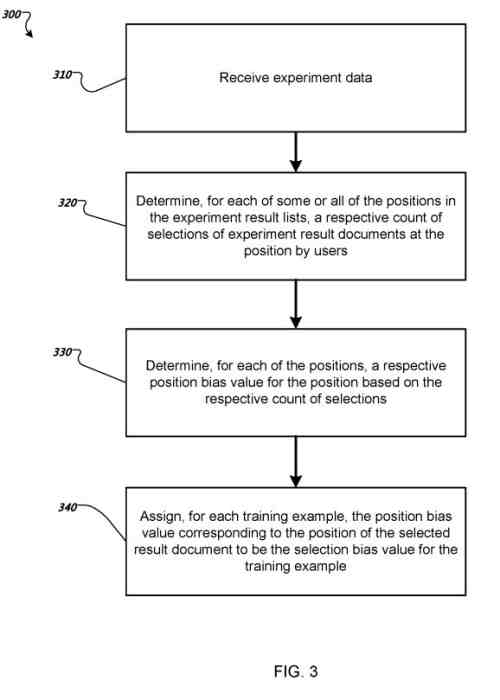
Las listas de resultados de las posiciones de los documentos de resultados del experimento se permutaron aleatoriamente antes de que las listas de resultados del experimento se presentaran a los buscadores.
Por lo tanto, el documento del resultado del experimento que el buscador seleccionó de una lista de resultados dada tenía la misma probabilidad de ser asignado a cualquiera de las posiciones de la lista de resultados del experimento.
Para cada una de las posiciones en las listas de resultados de experimentos, el sistema determina un recuento respectivo de selecciones de documentos de resultados de experimentos en la posición por parte de los buscadores en respuesta a las consultas de búsqueda de experimentos en los datos experimentales.
Por ejemplo, el sistema puede determinar un recuento respectivo de selecciones para las primeras N posiciones en las listas de resultados del experimento, donde N es un número entero mayor que 1, por ejemplo, cuatro, cinco o diez, o para cada posición en las listas de resultados del experimento.
Por ejemplo, cuando el sistema recibe datos de experimentos, incluidas 10 listas de resultados de experimentos, si los buscadores seleccionaron la primera posición para 7 de las listas de resultados de experimentos, una segunda posición para 2 de las listas de resultados de experimentos. Por lo tanto, la tercera posición para 1 de las listas de resultados del experimento, el recuento de selecciones para la primera posición puede ser 7, el recuento de selecciones para la segunda posición puede ser 2 y el recuento de selecciones para la tercera posición puede ser 1.
Para cada una de las posiciones, el sistema determina un valor de polarización de posición respectivo para la posición basándose en el recuento respectivo de selecciones para la posición.
El valor de sesgo de posición representa un grado en el que el documento de resultado del experimento seleccionado en la lista de resultados del experimento para la consulta de búsqueda del experimento en los datos del experimento afectó la selección del documento de resultado del experimento.
En algunas implementaciones, el valor de sesgo de posición respectivo de cada posición puede ser proporcional a un recuento respectivo de selecciones para la posición. En algunas implementaciones, se puede calcular un valor de sesgo de posición respectivo para cada posición dividiendo el recuento de selecciones en la posición seleccionando selecciones en cualquier posición de las posiciones en las listas de resultados del experimento.
Para cada ejemplo de entrenamiento en los datos de entrenamiento, el sistema asigna el valor de sesgo de posición correspondiente a la posición del documento de resultado seleccionado en la lista de resultados de documentos de resultado para el ejemplo de entrenamiento para que sea el valor de sesgo de selección para el ejemplo de entrenamiento.
Por ejemplo, cuando el sistema determina un valor de sesgo de posición b 1 para una primera posición utilizando el recuento de selecciones de documentos de resultados de experimentos en la primera posición, si la primera posición es la posición de un documento de resultados que el buscador seleccionó en la lista de resultados. el ejemplo de entrenamiento en los datos de entrenamiento, el sistema determina que el valor de sesgo de posición 1 es el valor de sesgo de selección para el ejemplo de entrenamiento.
Determinar un valor de sesgo de selección respectivo para cada ejemplo de entrenamiento en los datos de entrenamiento
En este ejemplo, cada consulta de búsqueda de experimentos en las consultas de búsqueda de experimentos se ha clasificado como perteneciente a una clase de consulta respectiva de un conjunto predeterminado de clases de consulta. Luego, el sistema realiza el proceso para cada clase en el conjunto predeterminado de clases de consulta.

Para una clase de consulta determinada, el sistema recibe datos de experimentos que identifican las consultas de búsqueda de experimentos que se clasificaron como pertenecientes a la clase de consulta dada y, para cada una de estas consultas de búsqueda de experimentos, una posición respectiva en una lista de resultados de experimentos de documentos de resultados para la búsqueda de experimentos. consulta de un documento de resultado de experimento que seleccionó un buscador.
Para la clase de consulta dada, el sistema determina, para cada una de algunas o todas las posiciones en las listas de resultados de experimentos, un recuento respectivo de selecciones de documentos de resultados de experimentos en la posición por parte de los buscadores en respuesta a las consultas de búsqueda de experimentos que pertenecen a la consulta. clase en los datos del experimento. Así, por ejemplo, el sistema puede determinar un recuento respectivo de selecciones para las primeras N posiciones en las listas de resultados del experimento.
Para la clase de consulta dada, el sistema determina un valor de sesgo de posición específico de clase respectivo para la posición basándose en el recuento respectivo de selecciones para la posición para cada una de las posiciones. En algunas implementaciones, el valor de sesgo de posición respectivo de cada posición puede ser proporcional a un recuento respectivo de selecciones para la posición.
Para cada ejemplo de entrenamiento en los datos de entrenamiento, el sistema obtiene datos que identifican una clase de consulta a la que pertenece la consulta de búsqueda para el ejemplo de entrenamiento.
El sistema asigna, para cada ejemplo de entrenamiento en los datos de entrenamiento, el valor de sesgo de posición específico de la clase para la clase de consulta a la que pertenece la consulta de búsqueda y correspondiente a la posición del documento de resultado seleccionado en la lista de resultados de documentos de resultado para el entrenamiento. ejemplo para ser el valor de sesgo de selección para el ejemplo de entrenamiento.
Por ejemplo, cuando una consulta de búsqueda Q pertenece a una clase de consulta ty el sistema determina un bit de valor de sesgo de posición específico de clase para una primera posición utilizando el recuento de selecciones de documentos de resultados de experimentos en la primera posición, si la primera posición es la posición de un documento de resultado que el buscador seleccionó en la lista de resultados para el ejemplo de entrenamiento en los datos de entrenamiento, el sistema determina que el valor de sesgo de posición específico de clase b 1 t es el valor de sesgo de selección para el ejemplo de entrenamiento.
Un proceso de ejemplo para determinar un valor de sesgo de selección respectivo para cada ejemplo de entrenamiento en datos de entrenamiento
El sistema recibe datos de experimentos que identifican las consultas de búsqueda de experimentos. Para cada consulta de búsqueda de experimentos, una posición respectiva en una lista de resultados de experimentos de documentos de resultados para la consulta de búsqueda de experimentos de un documento de resultados de experimentos que seleccionó un buscador.

El sistema obtiene un vector de características respectivo para cada consulta de búsqueda de experimentos de las consultas de búsqueda de experimentos. Los vectores de características pueden ser específicos de la consulta o del buscador. Por ejemplo, las características de la consulta pueden incluir el número de palabras en la consulta, la clase de la consulta o el idioma preferido del buscador.
El sistema genera datos de entrenamiento para entrenar a un clasificador. El clasificador está entrenado para recibir un vector de características respectivo para una consulta de búsqueda de entrada y generar un valor de sesgo de posición específico de consulta respectivo para cada una de las posiciones de consulta de búsqueda de entrada.
Los datos de entrenamiento pueden incluir ejemplos positivos de consultas de búsqueda de experimentos y ejemplos negativos de consultas de búsqueda de experimentos. Por ejemplo, el sistema puede etiquetar una consulta de búsqueda de experimentos como un ejemplo positivo para la lista de resultados de experimentos de documentos de resultados para la consulta de búsqueda de experimentos del resultado de búsqueda de experimentos que seleccionó el buscador. El sistema puede etiquetar la consulta de búsqueda del experimento como un ejemplo negativo para las posiciones no seleccionadas de las posiciones en la lista de resultados del experimento de los documentos de resultados.
El sistema entrena al clasificador con los datos de entrenamiento. El entrenamiento del clasificador puede ser un proceso de aprendizaje automático que aprende los pesos respectivos para aplicar a cada vector de característica de entrada. En particular, un clasificador se entrena mediante un proceso de entrenamiento de aprendizaje automático iterativo convencional que determina los pesos entrenados para cada posición de la lista de resultados. Con base en los pesos iniciales asignados a cada posición de la lista de resultados, el proceso iterativo intenta encontrar los pesos óptimos. Por ejemplo, el valor de sesgo de posición específico de la consulta bi Q para una posición dada i para una consulta de búsqueda determinada Q se puede dar mediante la siguiente fórmula:
β i denota los pesos entrenados para la posición i, y v (Q) denota un vector de características para la consulta de búsqueda Q.
El clasificador puede ser un modelo de regresión logística. Se pueden usar otros clasificadores adecuados en otras implementaciones, incluidos Bayes ingenuos, árboles de decisión, entropía máxima, redes neuronales o clasificadores de vectores de soporte basados en máquinas.
Para cada ejemplo de entrenamiento en los datos de entrenamiento, el sistema obtiene un vector de características para la consulta de búsqueda en el ejemplo de entrenamiento.
Para cada ejemplo de entrenamiento en los datos de entrenamiento, el sistema procesa el vector de características usando el clasificador entrenado para generar un valor de sesgo de posición específico de consulta respectivo para cada una de las posiciones para la consulta de búsqueda en el ejemplo de entrenamiento. Primero, el clasificador entrenado recibe el vector de características como entrada. Luego, genera un valor de sesgo de posición específico de la consulta respectivo para cada posición en la lista de resultados para la consulta de búsqueda en el ejemplo de entrenamiento.
Para cada ejemplo de entrenamiento en los datos de entrenamiento, el sistema asigna el valor de sesgo de posición específico de la consulta correspondiente a la posición del documento de resultado seleccionado para el ejemplo de entrenamiento en la lista de resultados de documentos de resultado para que la consulta de búsqueda sea el valor de sesgo de selección para el ejemplo de entrenamiento.
Por ejemplo, cuando el sistema determina un valor de sesgo de posición específico de la consulta b 1 Q para una primera posición usando el clasificador entrenado si la primera posición es la posición de un documento de resultado que el buscador seleccionó en la lista de resultados para el ejemplo de entrenamiento en el datos de entrenamiento, el sistema determina que el valor de sesgo de posición específico de la consulta b 1 Q es el valor de sesgo de selección para el ejemplo de entrenamiento.
