
Apprentissage automatique pour un modèle de classement
Publié: 2021-05-05Apprentissage automatique chez Google
Ce brevet de Google concerne la formation d'un modèle d'apprentissage automatique pour classer les documents en réponse aux requêtes de recherche.

Les moteurs de recherche en ligne tels que Google classent les documents en réponse aux requêtes de recherche pour présenter des résultats de recherche remplis de documents répondant à une requête de recherche.
Les moteurs de recherche affichent généralement les résultats de la recherche dans un ordre défini par un classement.
Les moteurs de recherche classent les documents en utilisant divers facteurs avec diverses techniques de classement.
Un moteur de recherche peut classer des documents sur la base d'un modèle d'apprentissage automatique de classement qui reçoit les caractéristiques d'un document d'entrée et, éventuellement, la requête de recherche reçue et générera ensuite un score de classement pour le document d'entrée.
Ce brevet décrit la formation d'un modèle d'apprentissage automatique de classement.
Utiliser le Machine Learning pour entraîner un modèle de classement
Le brevet d'aujourd'hui a été accordé le 29 avril 2021. Il se concentre sur la réception de données d'entraînement pour un modèle d'apprentissage automatique de classement afin de classer les documents en réponse aux requêtes de recherche.
Les données d'entraînement incluent des exemples d'entraînement. Chaque exemple de formation comprend des données identifiant :
- Requête de recherche
- Documents de résultats à partir d'une liste de résultats pour la requête de recherche
- Documents de résultats sélectionnés par un chercheur dans la liste de résultats de documents de résultats
Le brevet concerne la réception de données de position pour chacun des exemples d'apprentissage dans les données d'apprentissage.
Ces données de position identifient la position du document de résultat sélectionné dans les SERP pour la requête de recherche dans l'exemple d'apprentissage.
Déterminer, pour chaque exemple d'apprentissage, les données de position et la valeur de biais de sélection représentant dans laquelle ce résultat aura un impact sur la sélection du document de résultat
Détermination d'une valeur d'importance respective pour chaque exemple d'apprentissage à partir de la valeur de biais de sélection pour l'exemple d'apprentissage, la valeur d'importance définissant l'importance de l'exemple d'apprentissage dans l'apprentissage du modèle d'apprentissage automatique de classement.
En outre, le processus breveté peut inclure les caractéristiques suivantes en combinaison :
- Recevoir des données d'expérience identifiant de nombreuses requêtes de recherche d'expérience qui remplissent chacune une position respective dans une liste de résultats d'expérience de documents de résultats d'expérience pour la requête de recherche d'expérience d'un document de résultat d'expérience sélectionné par un chercheur, où les positions des documents de résultats d'expérience dans les listes de résultats d'expérience ont été permutés au hasard avant d'être présentés aux chercheurs
- déterminer pour chaque position, un nombre respectif de sélections de documents de résultats d'expérience à la position par des chercheurs en réponse au nombre de requêtes de recherche d'expérience dans les données d'expérience ; et déterminer, pour chacune de la pluralité de positions, une valeur de biais de position respective pour la position sur la base du nombre respectif de sélections pour la position
- Attribution de la valeur de biais de position respective correspondant à la position du document de résultat sélectionné dans la liste de résultats de documents de résultats pour l'exemple d'apprentissage comme étant la valeur de biais de sélection pour l'exemple d'apprentissage
Dans lequel les requêtes de recherche d'expérience dans le nombre de requêtes de recherche d'expérience appartiennent chacune à une classe de requête respective d'une pluralité de classes de requête, le procédé comprend, pour chacune de la pluralité de classes de requête :
- Détermination, pour chacun des nombres de positions, d'un nombre de sélections de documents de résultats d'expérience à la position par les chercheurs répondant aux requêtes de recherche d'expérience appartenant à la classe de requête dans les données d'expérience
- Détermination, pour chacune de la pluralité de positions, d'une valeur de biais de position spécifique à une classe respective pour la position sur la base du nombre respectif de sélections pour la position
- Obtention de données identifiant une classe de requête à laquelle appartient la requête de recherche pour l'exemple d'apprentissage
- Affectation de la valeur de biais de position spécifique à la classe pour la classe de requête à laquelle appartient la requête de recherche
- Correspondant à la position du document de résultat sélectionné pour l'exemple d'apprentissage dans la liste de résultats des documents de résultat pour être la valeur de biais de sélection pour l'exemple d'apprentissage
- Obtention d'un vecteur de caractéristiques respectif pour chaque requête de recherche d'expérience, génération de données d'apprentissage pour former un classificateur qui reçoit un vecteur de caractéristiques respectif pour une requête de recherche d'entrée et produit une valeur de biais de position spécifique à la requête respective pour chacune d'une pluralité de positions pour la recherche d'entrée requête et formation du classificateur sur les données de formation
- Obtention d'un vecteur de caractéristiques pour la requête de recherche dans l'exemple d'apprentissage
- Traitement du vecteur de caractéristiques à l'aide du classificateur formé pour générer une valeur de biais de position spécifique à la requête respective pour chacune de la pluralité de positions pour la requête de recherche dans l'exemple de formation
- Attribution de la valeur de biais de position spécifique à la requête correspondant à la position du document de résultat sélectionné pour l'exemple d'apprentissage dans la liste de résultats des documents de résultat pour la requête de recherche comme étant la valeur de biais de sélection pour l'exemple d'apprentissage
- Étiqueter la requête de recherche d'expérience comme un exemple positif pour la position dans la liste des résultats d'expérience des documents de résultats pour la requête de recherche d'expérience du résultat de recherche d'expérience que le chercheur a sélectionné, et étiqueter la requête de recherche d'expérience comme un exemple négatif pour d'autres positions du pluralité de postes
- Apprentissage du modèle d'apprentissage automatique de classement sur les données d'apprentissage à l'aide des valeurs d'importance respectives pour la pluralité d'exemples d'apprentissage dans les données d'apprentissage
- Détermination, pour chaque exemple d'apprentissage de la pluralité d'exemples d'apprentissage dans les données d'apprentissage, d'une perte respective pour l'exemple d'apprentissage
- Ajuster, pour chaque exemple d'apprentissage de la pluralité d'exemples d'apprentissage dans les données d'apprentissage, la perte pour l'exemple d'apprentissage sur la base de la valeur d'importance pour l'exemple d'apprentissage afin de générer une perte ajustée
- Apprentissage du modèle d'apprentissage automatique à l'aide des pertes ajustées pour la pluralité d'exemples d'apprentissage dans les données d'apprentissage
Le procédé comprend l'apprentissage du modèle d'apprentissage automatique en minimisant une somme des pertes ajustées pour la pluralité des données d'apprentissage.
Avantages de suivre ce modèle de classement d'apprentissage automatique
Les modèles de données cliquables conventionnels peuvent estimer la pertinence des paires requête-document individuelles dans le contexte de la recherche sur le Web.
Ces modèles de données cliquables conventionnels nécessitent généralement de nombreux clics pour chaque paire de documents de requête et de résultat individuels. Cela rend les modèles de données de clic difficiles à appliquer lorsque les données de clic sont très rares en raison de corpus personnalisés et de besoins en informations, par exemple, la recherche personnelle.
Par rapport aux modèles de données cliquables conventionnels, un système qui utilise un biais de sélection pour diverses positions de liste de résultats lors de la formation d'un modèle de classement peut exploiter plus efficacement les données de clic éparses tout en réduisant ou en éliminant les effets du biais de sélection sur les scores de classement générés par les maquette.
Cela signifie que le modèle entraîné peut fournir des scores de classement précis même lorsque les données de clic sont très rares, ce qui signifie que les résultats de la recherche répondent mieux aux besoins d'information des chercheurs.
Ce brevet est disponible sur :
Former un modèle de classement
Numéro de brevet : US20210125108
Inventeurs Donald Arthur Metzler, Jr., Xuanhui Wang, Marc Alexander Najork et Michael Bendersky
Candidats Google LLC
Date d'octroi : 29 avril 2021
Date de dépôt 24 octobre 2016
Résumé
L'invention concerne des procédés, des systèmes et un appareil, comprenant des programmes informatiques codés sur un support de stockage informatique, pour former un modèle d'apprentissage automatique de classement. Dans un aspect, un procédé comprend les actions de réception de données d'entraînement pour un modèle d'apprentissage automatique de classement, les données d'entraînement comprenant des exemples d'entraînement, et chaque exemple d'entraînement comprenant des données identifiant : une requête de recherche, aboutissent à des documents à partir d'une liste de résultats pour la requête de recherche , et un document de résultat qui a été sélectionné par un chercheur dans la liste de résultats, recevant des données de position pour chaque exemple d'apprentissage dans les données d'apprentissage, les données de position identifiant une position respective du document de résultat sélectionné dans la liste de résultats pour la requête de recherche dans le exemple de formation ; déterminer, pour chaque exemple d'apprentissage dans les données d'apprentissage, une valeur de biais de sélection respective ; et déterminer une valeur d'importance respective pour chaque exemple d'apprentissage à partir de la valeur de biais de sélection pour l'exemple d'apprentissage, la valeur d'importance.
Un exemple de système de recherche d'apprentissage automatique
Un chercheur peut interagir avec le système de recherche via un dispositif de recherche.
Le dispositif de recherche peut être un ordinateur couplé au système de recherche via un réseau de communication de données, par exemple un réseau local (LAN) ou un réseau étendu (WAN), par exemple Internet, ou une combinaison de réseaux.
Dans certains cas, le système de recherche peut être mis en œuvre sur le dispositif de recherche si un chercheur installe une application qui effectue des recherches sur le dispositif de recherche.
Le dispositif de recherche comprendra généralement une mémoire, par exemple une mémoire vive (RAM), pour stocker des instructions et des données et un processeur pour exécuter des instructions stockées. La mémoire peut inclure à la fois une mémoire en lecture seule et une mémoire inscriptible.
Généralement, le système de recherche peut être configuré pour rechercher une collection spécifique de documents qui sont associés au chercheur du dispositif de recherche.
Le terme « document » sera utilisé au sens large pour inclure tout produit de travail lisible par machine et stockable par machine.
Les documents peuvent inclure :
- Un fichier
- Une combinaison de fichiers
- Un ou plusieurs fichiers avec des liens intégrés vers d'autres fichiers
- Une publication sur un groupe de discussion
- Un blog
- Une liste d'entreprises
- Une version électronique du texte imprimé
- Une publicité en ligne
- Etc.
La collection de documents que le système de recherche est configuré pour rechercher peut être envoyée par courrier électronique dans un compte de messagerie du chercheur, des données d'application mobile associées à un compte du chercheur, par exemple, les préférences des applications mobiles ou l'historique d'utilisation des applications mobiles , les fichiers associés au chercheur dans un compte de stockage de documents en nuage, par exemple, les fichiers téléchargés par le chercheur ou les fichiers partagés avec le chercheur par d'autres chercheurs, ou une autre collection de documents spécifique au chercheur.
Un chercheur peut soumettre des requêtes de recherche au système de recherche en utilisant le dispositif de recherche. Lorsque le chercheur soumet une requête de recherche, la requête de recherche est transmise via le réseau au système de recherche.
Lorsque le système de recherche reçoit la requête de recherche, un moteur de recherche dans le système de recherche identifie les documents dans la collection de documents qui satisfont à la requête de recherche et répond à la requête en générant des résultats de recherche qui identifient chacun un document respectif qui satisfait la recherche et transmis via /le réseau au dispositif de recherche pour présentation au chercheur, c'est-à-dire sous une forme qui peut être présentée au chercheur.
Le moteur de recherche peut comprendre un moteur d'indexation et un moteur de classement. Le moteur d'indexation indexe les documents dans les collections de documents et ajoute les documents indexés à une base de données d'index. Le moteur de classement génère des scores respectifs pour les documents dans la base de données d'index qui satisfont à la requête de recherche et classe les documents sur la base de leurs scores respectifs.
Généralement, les résultats de la recherche sont affichés pour le chercheur ; une liste de résultats est ordonnée en fonction des scores de classement générés par le moteur de classement pour les documents identifiés par les résultats de recherche 128. Par exemple, par exemple, un résultat de recherche identifiant un document avec un score plus élevé peut être présenté à une position plus élevée dans le résultat liste qu'un résultat de recherche identifiant un document avec un score relativement inférieur.
Le moteur de classement génère des scores de classement pour les documents à l'aide d'un modèle d'apprentissage automatique de classement.
Le modèle d'apprentissage automatique de classement est un modèle d'apprentissage automatique formé pour recevoir des caractéristiques ou d'autres données caractérisant un document d'entrée et, facultativement, des données caractérisant la requête de recherche et pour générer un score de classement pour le document d'entrée.
Le modèle d'apprentissage automatique de classement peut utiliser une variété de modèles d'apprentissage automatique.
Le modèle d'apprentissage automatique de classement peut être un modèle d'apprentissage automatique en profondeur, par exemple un réseau de neurones, qui comprend plusieurs couches d'opérations non linéaires.
Ou le modèle d'apprentissage automatique de classement peut être un modèle d'apprentissage automatique superficiel, par exemple un modèle linéaire généralisé.
Selon la façon dont le modèle d'apprentissage automatique de classement a été formé, le score de classement peut prédire la pertinence du document d'entrée par rapport à la requête de recherche ou peut prendre en compte à la fois la pertinence du document d'entrée et la qualité indépendante de la requête du document d'entrée.
Dans certaines mises en œuvre, le moteur de classement modifie les scores de classement générés par le modèle d'apprentissage automatique de classement sur la base d'autres facteurs et classe les documents à l'aide des scores de classement modifiés.
Pour former le modèle d'apprentissage automatique de classement afin que le modèle puisse être utilisé dans le classement de documents en réponse aux requêtes de recherche reçues, le système de recherche comprend également un moteur de formation.

Le moteur d'entraînement entraîne le modèle d'apprentissage automatique de classement sur des données d'entraînement qui incluent plusieurs exemples d'entraînement.
Chaque exemple de formation identifie
- (i) une requête de recherche
- (ii) les documents de résultat de la liste de résultats pour la requête de recherche
- (iii) un document de résultat qui a été sélectionné par un chercheur dans la liste de résultats de documents de résultat pour la requête de recherche
Comme décrit dans ce brevet, une sélection d'un document de résultat en réponse à une requête de recherche sélectionne un résultat de recherche identifiant le document de résultat à partir d'une liste de résultats de recherche présentée en réponse à la soumission d'une requête par un chercheur. Les SERP sont les documents identifiés par les résultats de la recherche dans la liste des résultats.
Pour améliorer la qualité des scores de classement à partir du modèle d'apprentissage automatique de classement une fois formé, le moteur de formation s'entraîne d'une manière qui tient compte de la liste de résultats du résultat de la recherche que le chercheur a sélectionné.
Le moteur d'apprentissage détermine une valeur d'importance respective pour chaque exemple d'apprentissage sur la base de la position dans la liste de résultats du résultat de recherche que le chercheur a sélectionné en réponse à la requête de recherche dans l'exemple d'apprentissage.
En entraînant le modèle d'apprentissage automatique de cette manière, le moteur d'entraînement réduit ou élimine l'impact du biais de position sur les scores de classement générés par le modèle d'apprentissage automatique de classement une fois que le modèle a été formé.
Détermination d'une valeur d'importance respective pour chaque exemple d'apprentissage dans les données d'apprentissage
Le système reçoit des données de position, qui identifient une position respective dans la liste de résultats pour la requête de recherche que le chercheur a sélectionnée en réponse à la requête de recherche, c'est-à-dire le résultat de recherche que le chercheur a sélectionné à partir de la liste de résultats générée en réponse à la requête de recherche .
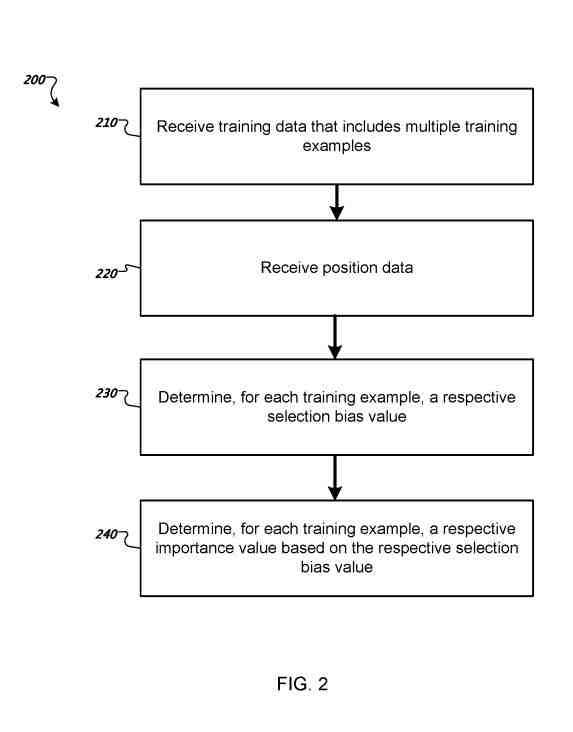
Le système détermine une valeur de biais de sélection respective, qui représente un degré auquel la position du document de résultat sélectionné dans la liste de résultats pour la requête de recherche dans l'exemple d'apprentissage a eu un impact sur la sélection du document de résultat.
La valeur du biais de sélection peut être déterminée de plusieurs manières.
Le système détermine, pour chaque exemple d'apprentissage dans les données d'apprentissage, une valeur d'importance respective.
La valeur d'importance pour un exemple d'entraînement donné définit l'importance de l'exemple d'entraînement dans l'entraînement du modèle d'apprentissage automatique de classement.
La valeur d'importance respective pour chaque exemple d'apprentissage dans les données d'apprentissage peut être déterminée sur la base de la valeur de biais de sélection respective pour l'exemple d'apprentissage.
Par exemple, la valeur d'importance pour un exemple d'apprentissage particulier peut être l'inverse de la valeur de biais de sélection pour l'exemple d'apprentissage ou, plus généralement, être inversement proportionnelle à la valeur de biais de sélection pour l'exemple d'apprentissage.
Une fois que le système a déterminé les valeurs d'importance respectives pour les données d'entraînement des données d'entraînement, le système entraîne le modèle d'apprentissage automatique de classement sur les données d'entraînement à l'aide des valeurs d'importance.
Détermination d'une valeur de biais de sélection respective pour chaque exemple d'apprentissage dans les données d'apprentissage
Le système reçoit des données d'expérience identifiant des requêtes de recherche d'expérience. Pour chaque requête de recherche d'expérience, une position respective dans une liste de résultats d'expérience de documents de résultats d'expérience pour la requête de recherche d'expérience d'une expérience résulte dans un document qu'un chercheur a sélectionné.
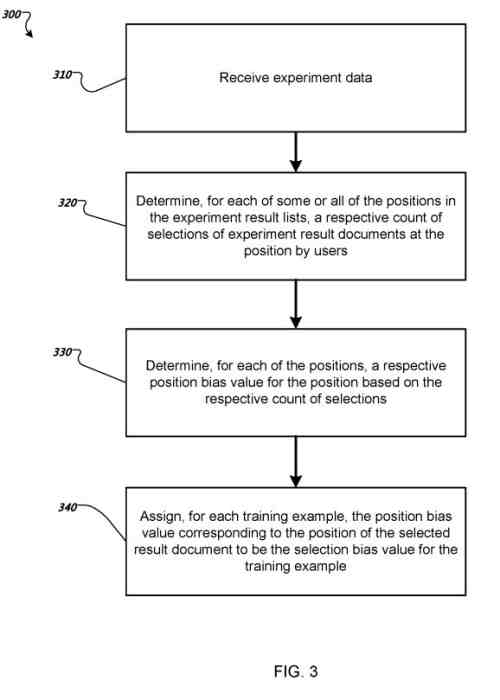
Les listes de résultats des positions des documents de résultats de l'expérience ont été permutées au hasard avant que les listes de résultats de l'expérience ne soient présentées aux chercheurs.
Ainsi, le document de résultat d'expérience que le chercheur a sélectionné à partir d'une liste de résultats donnée était également susceptible d'être affecté à l'une des positions de la liste de résultats d'expérience.
Pour chacune des positions dans les listes de résultats d'expérience, le système détermine un nombre respectif de sélections de documents de résultats d'expérience à la position par les chercheurs en réponse aux requêtes de recherche d'expérience dans les données expérimentales.
Par exemple, le système peut déterminer un nombre respectif de sélections pour les N premières positions dans les listes de résultats d'expérience, où N est un nombre entier supérieur à 1, par exemple quatre, cinq ou dix, ou pour chaque position dans les listes de résultats d'expérience.
Par exemple, lorsque le système reçoit des données d'expérience comprenant 10 listes de résultats d'expérience si les chercheurs ont sélectionné la première position pour 7 des listes de résultats d'expérience, une deuxième position pour 2 des listes de résultats d'expérience. Ainsi, la troisième position pour 1 des listes de résultats d'expérience, le nombre de sélections pour la première position peut être 7, le nombre de sélections pour la deuxième position peut être 2, et le nombre de sélections pour la troisième position peut être 1.
Pour chacune des positions, le système détermine une valeur de biais de position respective pour la position sur la base du nombre respectif de sélections pour la position.
La valeur de biais de position représente le degré auquel le document de résultat d'expérience sélectionné dans la liste de résultats d'expérience pour la requête de recherche d'expérience dans les données d'expérience a eu un impact sur la sélection du document de résultat d'expérience.
Dans certaines mises en œuvre, la valeur de biais de position respective de chaque position peut être proportionnelle à un nombre respectif de sélections pour la position. Dans certaines mises en œuvre, une valeur de biais de position respective pour chaque position peut être calculée en divisant le nombre de sélections à la position en sélectionnant des sélections à n'importe quelle position des positions dans les listes de résultats d'expérience.
Pour chaque exemple d'entraînement dans les données d'entraînement, le système attribue la valeur de biais de position correspondant à la position du document de résultat sélectionné dans la liste de résultats des documents de résultats pour l'exemple d'entraînement comme valeur de biais de sélection pour l'exemple d'entraînement.
Par exemple, lorsque le système détermine une valeur de biais de position b 1 pour une première position en utilisant le nombre de sélections de documents de résultats d'expérience à la première position si la première position est la position d'un document de résultats que le chercheur a sélectionné dans la liste de résultats pour l'exemple d'apprentissage dans les données d'apprentissage, le système détermine que la valeur de biais de position 1 est la valeur de biais de sélection pour l'exemple d'apprentissage.
Détermination d'une valeur de biais de sélection respective pour chaque exemple d'apprentissage dans les données d'apprentissage
Dans cet exemple, chaque requête de recherche d'expérience dans les requêtes de recherche d'expérience a été classée comme appartenant à une classe de requête respective d'un ensemble prédéterminé de classes de requête. Ensuite, le système exécute le processus pour chaque classe dans l'ensemble prédéterminé de classes de requête.

Pour une classe de requête donnée, le système reçoit des données d'expérience identifiant les requêtes de recherche d'expérience qui ont été classées comme appartenant à la classe de requête donnée et, pour chacune de ces requêtes de recherche d'expérience, une position respective dans une liste de résultats d'expérience de documents de résultats pour la recherche d'expérience requête d'un document de résultat d'expérience qu'un chercheur a sélectionné.
Pour la classe de requête donnée, le système détermine, pour chacune de certaines ou toutes les positions dans les listes de résultats d'expérience, un nombre respectif de sélections de documents de résultats d'expérience à la position par les chercheurs en réponse aux requêtes de recherche d'expérience appartenant à la requête classe dans les données de l'expérience. Ainsi, par exemple, le système peut déterminer un nombre respectif de sélections pour les N premières positions dans les listes de résultats d'expérience.
Pour la classe de requête donnée, le système détermine une valeur de biais de position spécifique à la classe respective pour la position sur la base du nombre respectif de sélections pour la position pour chacune des positions. Dans certaines mises en œuvre, la valeur de biais de position respective de chaque position peut être proportionnelle à un nombre respectif de sélections pour la position.
Pour chaque exemple d'apprentissage dans les données d'apprentissage, le système obtient des données identifiant une classe d'interrogation à laquelle appartient l'interrogation de recherche de l'exemple d'apprentissage.
Le système attribue, pour chaque exemple de formation dans les données de formation, la valeur de biais de position spécifique à la classe pour la classe de requête à laquelle appartient la requête de recherche et correspondant à la position du document de résultat sélectionné dans la liste de résultats des documents de résultat pour la formation example comme valeur de biais de sélection pour l'exemple d'apprentissage.
Par exemple, lorsqu'une requête de recherche Q appartient à une classe de requête t et que le système détermine un bit de valeur de biais de position spécifique à la classe pour une première position en utilisant le nombre de sélections de documents de résultats d'expérience à la première position, si la première position est la position d'un document de résultat que le chercheur a sélectionné dans la liste de résultats pour l'exemple d'apprentissage dans les données d'apprentissage, le système détermine que la valeur de biais de position spécifique à la classe b 1 t est la valeur de biais de sélection pour l'exemple d'apprentissage.
Exemple de processus pour déterminer une valeur de biais de sélection respective pour chaque exemple d'apprentissage dans les données d'apprentissage
Le système reçoit des données d'expérience identifiant des requêtes de recherche d'expérience. Pour chaque requête de recherche d'expérience, une position respective dans une liste de résultats d'expérience de documents de résultats pour la requête de recherche d'expérience d'un document de résultat d'expérience qu'un chercheur a sélectionné.

Le système obtient un vecteur de caractéristique respectif pour chaque requête de recherche d'expérience des requêtes de recherche d'expérience. Les vecteurs de caractéristiques peuvent être spécifiques à une requête ou à un chercheur. Par exemple, les caractéristiques de la requête peuvent inclure le nombre de mots dans la requête, la classe de la requête ou la langue préférée du chercheur.
Le système génère des données d'apprentissage pour l'apprentissage d'un classificateur. Le classificateur est formé pour recevoir un vecteur de caractéristique respectif pour une requête de recherche d'entrée et sortir une valeur de biais de position spécifique à la requête respective pour chacune des positions de requête de recherche d'entrée.
Les données d'apprentissage peuvent inclure des exemples positifs de requêtes de recherche d'expérience et des exemples négatifs de requêtes de recherche d'expérience. Par exemple, le système peut étiqueter une requête de recherche d'expérience comme un exemple positif pour la liste de résultats d'expérience de documents de résultats pour la requête de recherche d'expérience du résultat de recherche d'expérience que le chercheur a sélectionné. Le système peut étiqueter la requête de recherche d'expérience comme un exemple négatif pour les positions non sélectionnées des positions dans la liste des résultats de l'expérience des documents de résultats.
Le système entraîne le classificateur sur les données d'entraînement. L'apprentissage du classificateur peut être un processus d'apprentissage automatique qui apprend les poids respectifs à appliquer à chaque vecteur de caractéristiques en entrée. En particulier, un classificateur est entraîné à l'aide d'un processus d'entraînement d'apprentissage automatique itératif classique qui détermine des poids entraînés pour chaque position de liste de résultats. Sur la base des poids initiaux attribués à chaque position de la liste de résultats, le processus itératif tente de trouver les poids optimaux. Par exemple, la valeur de biais de position spécifique à la requête bi Q pour une position donnée i pour une requête de recherche donnée Q peut être donnée à l'aide de la formule suivante :
β i désigne les poids formés pour la position i, et v(Q) désigne un vecteur de caractéristiques pour la requête de recherche Q.
Le classificateur peut être un modèle de régression logistique. D'autres classificateurs appropriés peuvent être utilisés dans d'autres implémentations, y compris Bayes naïf, les arbres de décision, l'entropie maximale, les réseaux de neurones ou les classificateurs basés sur des machines à vecteurs de support.
Pour chaque exemple d'apprentissage dans les données d'apprentissage, le système obtient un vecteur de caractéristiques pour la requête de recherche dans l'exemple d'apprentissage.
Pour chaque exemple d'apprentissage dans les données d'apprentissage, le système traite le vecteur de caractéristiques à l'aide du classificateur formé pour générer une valeur de biais de position spécifique à la requête respective pour chacune des positions pour la requête de recherche dans l'exemple d'apprentissage. Tout d'abord, le classificateur entraîné reçoit le vecteur de caractéristiques en entrée. Ensuite, il sort une valeur de biais de position spécifique à la requête respective pour chaque position dans la liste de résultats pour la requête de recherche dans l'exemple d'apprentissage.
Pour chaque exemple d'apprentissage dans les données d'apprentissage, le système attribue la valeur de biais de position spécifique à la requête correspondant à la position du document de résultat sélectionné pour l'exemple d'apprentissage dans la liste de résultats des documents de résultat pour la requête de recherche comme valeur de biais de sélection pour l'exemple de la formation.
Par exemple, lorsque le système détermine une valeur de biais de position b 1 Q spécifique à une requête pour une première position à l'aide du classificateur entraîné si la première position est la position d'un document de résultat que le chercheur a sélectionné dans la liste de résultats pour l'exemple d'entraînement dans le données d'apprentissage, le système détermine que la valeur de biais de position spécifique à la requête b 1 Q est la valeur de biais de sélection pour l'exemple d'apprentissage.
