
Apprendimento automatico per un modello di classifica
Pubblicato: 2021-05-05Apprendimento automatico in Google
Questo brevetto di Google riguarda la formazione di un modello di apprendimento automatico per classificare i documenti in risposta alle query di ricerca.

I motori di ricerca online come Google classificano i documenti in risposta alle query di ricerca per presentare risultati di ricerca pieni di documenti che rispondono a una query di ricerca.
I motori di ricerca di solito mostrano i risultati della ricerca in un ordine definito da una classifica.
I motori di ricerca classificano i documenti utilizzando vari fattori con varie tecniche di classificazione.
Un motore di ricerca può classificare i documenti in base a un modello di apprendimento automatico di classificazione che riceve le caratteristiche di un documento di input e, possibilmente, la query di ricerca ricevuta e quindi genererà un punteggio di classificazione per il documento di input.
Questo brevetto descrive la formazione di un modello di apprendimento automatico di classificazione.
Utilizzo dell'apprendimento automatico per addestrare un modello di classificazione
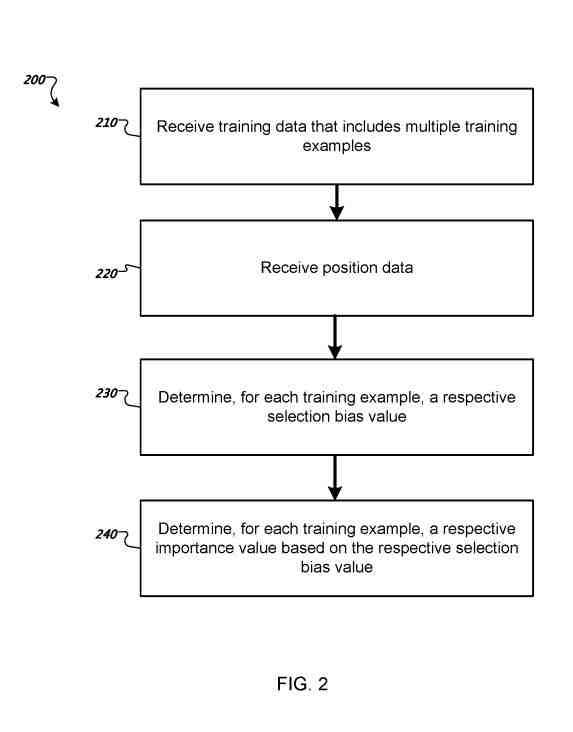
Il brevetto di oggi è stato concesso il 29 aprile 2021. Si concentra sulla ricezione di dati di formazione per un modello di apprendimento automatico di classificazione per classificare i documenti in risposta alle query di ricerca.
I dati di addestramento includono esempi di addestramento. Ogni esempio di formazione include dati che identificano:
- Query di ricerca
- Documenti risultati da un elenco di risultati per la query di ricerca
- Documenti risultato selezionati da un ricercatore dall'elenco dei risultati dei documenti risultato
Il brevetto riguarda la ricezione dei dati di posizione per ciascuno degli esempi di addestramento nei dati di addestramento.
Tali dati di posizione identificano la posizione del documento risultato selezionato nelle SERP per la query di ricerca nell'esempio di addestramento.
Determinare, per ogni esempio di addestramento, i dati sulla posizione e il valore di distorsione della selezione che rappresenta in cui quel risultato avrà un impatto sulla selezione del documento del risultato
Determinando un rispettivo valore di importanza per ogni esempio di addestramento dal valore di distorsione della selezione per l'esempio di addestramento, il valore di importanza che definisce l'importanza dell'esempio di addestramento nell'addestramento del modello di apprendimento automatico di classificazione.
Inoltre, il processo brevettato può includere le seguenti caratteristiche in combinazione:
- Ricezione dei dati dell'esperimento che identificano molte query di ricerca dell'esperimento che riempiono ciascuna una rispettiva posizione in un elenco dei risultati dell'esperimento dei documenti dei risultati dell'esperimento per la query di ricerca dell'esperimento di un documento dei risultati dell'esperimento selezionato da un ricercatore, in cui le posizioni dei documenti dei risultati dell'esperimento negli elenchi dei risultati dell'esperimento sono stati permutati casualmente prima di essere presentati ai ricercatori
- Determinazione per ciascuna posizione, un rispettivo conteggio delle selezioni dei documenti dei risultati dell'esperimento nella posizione da parte dei ricercatori in risposta al numero di query di ricerca dell'esperimento nei dati dell'esperimento; e determinare, per ciascuna della pluralità di posizioni, un rispettivo valore di bias di posizione per la posizione in base al rispettivo conteggio delle selezioni per la posizione
- Assegnare il rispettivo valore di distorsione della posizione corrispondente alla posizione del documento risultato selezionato nell'elenco dei risultati dei documenti di risultato per l'esempio di formazione come valore di distorsione della selezione per l'esempio di formazione
Laddove le query di ricerca dell'esperimento nel numero di query di ricerca dell'esperimento appartengono ciascuna a una rispettiva classe di query di una pluralità di classi di query, il metodo include, per ciascuna della pluralità di classi di query:
- Determinazione, per ciascuno dei numeri di posizioni, di un conteggio delle selezioni dei documenti dei risultati dell'esperimento nella posizione da parte dei ricercatori che rispondono alle query di ricerca dell'esperimento appartenenti alla classe di query nei dati dell'esperimento
- Determinazione, per ciascuna della pluralità di posizioni, un rispettivo valore di distorsione della posizione specifico della classe per la posizione in base al rispettivo conteggio delle selezioni per la posizione
- Ottenere dati che identificano una classe di query a cui appartiene la query di ricerca per l'esempio di addestramento
- Assegnazione del valore di distorsione della posizione specifico della classe per la classe di query a cui appartiene la query di ricerca
- Corrispondente alla posizione del documento risultato selezionato per l'esempio di formazione nell'elenco dei risultati dei documenti di risultato come valore di distorsione della selezione per l'esempio di formazione
- Ottenimento di un rispettivo vettore di caratteristiche per ogni query di ricerca dell'esperimento, generazione di dati di addestramento per addestrare un classificatore che riceve un rispettivo vettore di caratteristiche per una query di ricerca di input ed emette un rispettivo valore di bias di posizione specifico della query per ciascuna di una pluralità di posizioni per la ricerca di input query e addestrare il classificatore sui dati di addestramento
- Ottenere un vettore di funzionalità per la query di ricerca nell'esempio di addestramento
- Elaborazione del vettore di funzionalità utilizzando il classificatore addestrato per generare un rispettivo valore di distorsione della posizione specifico della query per ciascuna delle pluralità di posizioni per la query di ricerca nell'esempio di addestramento
- Assegnazione del valore di distorsione della posizione specifico della query corrispondente alla posizione del documento risultato selezionato per l'esempio di addestramento nell'elenco dei risultati dei documenti di risultato per la query di ricerca come valore di distorsione della selezione per l'esempio di formazione
- Etichettare la query di ricerca dell'esperimento come un esempio positivo per la posizione nell'elenco dei risultati dell'esperimento dei documenti dei risultati per la query di ricerca dell'esperimento del risultato di ricerca dell'esperimento selezionato dal ricercatore ed etichettare la query di ricerca dell'esperimento come un esempio negativo per altre posizioni del pluralità di posizioni
- Addestramento del modello di apprendimento automatico di classificazione sui dati di addestramento utilizzando i rispettivi valori di importanza per la pluralità di esempi di addestramento nei dati di addestramento
- Determinazione, per ogni esempio di addestramento della pluralità di esempi di addestramento nei dati di addestramento, una rispettiva perdita per l'esempio di addestramento
- Regolazione, per ogni esempio di addestramento della pluralità di esempi di addestramento nei dati di addestramento, la perdita per l'esempio di addestramento in base al valore di importanza per l'esempio di addestramento per generare una perdita aggiustata
- Addestramento del modello di apprendimento automatico utilizzando le perdite aggiustate per la pluralità di esempi di addestramento nei dati di addestramento
Il metodo include l'addestramento del modello di apprendimento automatico riducendo al minimo una somma delle perdite rettificate per la pluralità dei dati di addestramento.
Vantaggi di seguire questo modello di classificazione dell'apprendimento automatico
I modelli di dati click-through convenzionali possono stimare la pertinenza per singole coppie query-documento nel contesto della ricerca web.
Questi modelli di dati click-through convenzionali di solito richiedono molti clic per ogni coppia di singole query e documenti di risultato. Ciò rende difficile l'applicazione di modelli di dati click-through laddove i dati sui clic sono molto scarsi a causa di corpora personalizzati e esigenze informative, ad esempio la ricerca personale.
Rispetto ai tradizionali modelli di dati click-through, un sistema che utilizza il bias di selezione per varie posizioni dell'elenco dei risultati durante l'addestramento di un modello di classificazione può sfruttare in modo più efficace i dati sui clic sparsi riducendo o eliminando gli effetti del bias di selezione sui punteggi di classifica generati dal formato modello.
Ciò significa che il modello addestrato può fornire punteggi di classificazione accurati anche quando i dati sui clic sono molto scarsi, il che significa che i risultati della ricerca soddisfano meglio le esigenze informative dei ricercatori.
Questo brevetto è disponibile su:
Formazione di un modello di classifica
Numero di brevetto: US20210125108
Inventori Donald Arthur Metzler, Jr., Xuanhui Wang, Marc Alexander Najork e Michael Bendersky
Candidati Google LLC
Data di assegnazione: 29 aprile 2021
Data di deposito 24 ottobre 2016
Astratto
Metodi, sistemi e apparati, inclusi programmi per computer codificati su un supporto di memorizzazione per computer, per addestrare un modello di apprendimento automatico di classificazione. In un aspetto, un metodo include le azioni di ricezione dei dati di addestramento per un modello di apprendimento automatico di classificazione, i dati di addestramento inclusi gli esempi di addestramento e ogni esempio di addestramento inclusi i dati che identificano: una query di ricerca, risultati in documenti da un elenco di risultati per la query di ricerca e un documento risultato che è stato selezionato da un ricercatore dall'elenco dei risultati, ricevendo i dati di posizione per ogni esempio di addestramento nei dati di addestramento, i dati di posizione che identificano una rispettiva posizione del documento risultato selezionato nell'elenco dei risultati per la query di ricerca nel esempio di formazione; determinare, per ciascun esempio di addestramento nei dati di addestramento, un rispettivo valore di bias di selezione; e determinare un rispettivo valore di importanza per ciascun esempio di addestramento dal valore di distorsione di selezione per l'esempio di addestramento, il valore di importanza.
Un esempio di sistema di ricerca per l'apprendimento automatico
Un ricercatore può interagire con il sistema di ricerca tramite un dispositivo di ricerca.
Il dispositivo di ricerca può essere un computer accoppiato al sistema di ricerca tramite una rete di comunicazione dati, ad esempio una rete locale (LAN) o una rete geografica (WAN), ad esempio Internet o una combinazione di reti.
In alcuni casi, il sistema di ricerca può essere implementato sul dispositivo di ricerca se un ricercatore installa un'applicazione che esegue ricerche sul dispositivo di ricerca.
Il dispositivo di ricerca includerà generalmente una memoria, ad esempio una memoria ad accesso casuale (RAM), per memorizzare istruzioni e dati e un processore per eseguire istruzioni memorizzate. La memoria può includere sia memoria di sola lettura che memoria scrivibile.
In genere, il sistema di ricerca può essere configurato per cercare una raccolta specifica di documenti associati al ricercatore del dispositivo di ricerca.
Il termine "documento" sarà utilizzato in senso lato per includere qualsiasi prodotto di lavoro leggibile e memorizzabile dalla macchina.
I documenti possono includere:
- Un file
- Una combinazione di file
- Uno o più file con collegamenti incorporati ad altri file
- Un messaggio di gruppo di notizie
- Un blog
- Un elenco di attività commerciali
- Una versione elettronica del testo stampato
- Una pubblicità sul web
- Eccetera.
La raccolta di documenti che il sistema di ricerca è configurato per la ricerca può essere inviata tramite posta elettronica in un account di posta elettronica del ricercatore, dati dell'applicazione mobile associati a un account del ricercatore, ad esempio, preferenze delle applicazioni mobili o cronologia di utilizzo delle applicazioni mobili , file associati al ricercatore in un account di archiviazione di documenti cloud, ad esempio, file caricati dal ricercatore o file condivisi con il ricercatore da altri ricercatori, o una diversa raccolta di documenti specifica del ricercatore.
Un ricercatore può inviare query di ricerca al sistema di ricerca utilizzando il dispositivo di ricerca. Quando il ricercatore invia una query di ricerca, la query di ricerca viene trasmessa attraverso la rete al sistema di ricerca.
Quando il sistema di ricerca riceve la query di ricerca, un motore di ricerca all'interno del sistema di ricerca identifica i documenti nella raccolta di documenti che soddisfano la query di ricerca e risponde alla query generando risultati di ricerca che identificano ciascuno un rispettivo documento che soddisfa la ricerca e trasmessi attraverso /la rete al dispositivo del ricercatore per la presentazione al ricercatore, ad esempio, in una forma che può essere presentata al ricercatore.
Il motore di ricerca può includere un motore di indicizzazione e un motore di ranking. Il motore di indicizzazione indicizza i documenti nelle raccolte di documenti e aggiunge i documenti indicizzati a un database di indici. Il motore di classificazione genera i rispettivi punteggi per i documenti nel database dell'indice che soddisfano la query di ricerca e classificano i documenti in base ai rispettivi punteggi.
In genere, i risultati della ricerca vengono visualizzati dal ricercatore; un elenco di risultati è ordinato in base ai punteggi di classifica generati dal motore di classificazione per i documenti identificati dai risultati della ricerca 128. Ad esempio, ad esempio, un risultato di ricerca che identifica un documento con un punteggio più alto può essere presentato in una posizione più alta nel risultato list rispetto a un risultato di ricerca che identifica un documento con un punteggio relativamente basso.
Il motore di classificazione genera punteggi di classificazione per i documenti utilizzando un modello di apprendimento automatico di classificazione.
Il modello di apprendimento automatico di classificazione è un modello di apprendimento automatico addestrato per ricevere funzionalità o altri dati che caratterizzano un documento di input e, facoltativamente, dati che caratterizzano la query di ricerca e per generare un punteggio di classificazione per il documento di input.
Il modello di apprendimento automatico di classificazione può utilizzare una varietà di modelli di apprendimento automatico.
Il modello di apprendimento automatico di classificazione può essere un modello di apprendimento automatico profondo, ad esempio una rete neurale, che include più livelli di operazioni non lineari.
Oppure il modello di apprendimento automatico di classificazione può essere un modello di apprendimento automatico superficiale, ad esempio un modello lineare generalizzato.
A seconda di come è stato addestrato il modello di apprendimento automatico di classificazione, il punteggio di classificazione può prevedere la pertinenza del documento di input per la query di ricerca o può prendere in considerazione sia la pertinenza del documento di input che la qualità indipendente dalla query del documento di input.
In alcune implementazioni, il motore di classificazione modifica i punteggi di classificazione generati dal modello di apprendimento automatico di classificazione in base ad altri fattori e classifica i documenti utilizzando i punteggi di classificazione modificati.
Per addestrare il modello di apprendimento automatico di classificazione in modo che il modello possa essere utilizzato nei documenti di classificazione in risposta alle query di ricerca ricevute, il sistema di ricerca include anche un motore di formazione.
Il motore di addestramento addestra il modello di apprendimento automatico di classificazione sui dati di addestramento che includono più esempi di addestramento.

Ogni esempio di formazione identifica
- (i) una query di ricerca
- (ii) documenti risultati dall'elenco dei risultati per la query di ricerca
- (iii) un documento risultato che è stato selezionato da un ricercatore dall'elenco dei risultati dei documenti risultato per la query di ricerca
Come descritto in questo brevetto, una selezione di un documento di risultato in risposta a una query di ricerca è selezionare un risultato di ricerca che identifica il documento di risultato da un elenco di risultati di risultati di ricerca presentati in risposta all'invio di una query da parte di un ricercatore. Le SERP sono i documenti che vengono identificati dai risultati della ricerca nell'elenco dei risultati.
Per migliorare la qualità dei punteggi di classificazione dal modello di apprendimento automatico di classificazione una volta addestrato, il motore di formazione esegue l'addestramento in un modo che tiene conto dell'elenco dei risultati della ricerca selezionato dal ricercatore.
Il motore di addestramento determina un rispettivo valore di importanza per ogni esempio di addestramento in base alla posizione nell'elenco dei risultati della ricerca che il ricercatore ha selezionato in risposta alla query di ricerca nell'esempio di addestramento.
Addestrando il modello di machine learning in questo modo, il motore di training riduce o elimina l'impatto del bias di posizione sui punteggi di classifica generati dal modello di ranking di machine learning una volta che il modello è stato addestrato.
Determinazione di un rispettivo valore di importanza per ogni esempio di addestramento nei dati di addestramento
Il sistema riceve i dati di posizione, che identificano una rispettiva posizione nell'elenco dei risultati per la query di ricerca che il ricercatore ha selezionato in risposta alla query di ricerca, ovvero il risultato della ricerca che il ricercatore ha selezionato dall'elenco dei risultati generato in risposta alla query di ricerca .
Il sistema determina un rispettivo valore di distorsione della selezione, che rappresenta il grado in cui la posizione del documento risultato selezionato nell'elenco dei risultati per la query di ricerca nell'esempio di formazione ha influito sulla selezione del documento risultato.
Il valore del bias di selezione può essere determinato in molti modi.
Il sistema determina, per ogni esempio di training nei dati di training, un rispettivo valore di importanza.
Il valore di importanza per un determinato esempio di addestramento definisce quanto sia importante l'esempio di addestramento nell'addestramento del modello di apprendimento automatico di classificazione.
Il rispettivo valore di importanza per ciascun esempio di addestramento nei dati di addestramento può essere determinato in base al rispettivo valore di bias di selezione per l'esempio di addestramento.
Ad esempio, il valore di importanza per un particolare esempio di training può essere l'inverso del valore di bias di selezione per l'esempio di training o, più in generale, essere inversamente proporzionale al valore di bias di selezione per l'esempio di training.
Una volta che il sistema ha determinato i rispettivi valori di importanza per i dati di addestramento dei dati di addestramento, il sistema addestra il modello di apprendimento automatico di classificazione sui dati di addestramento utilizzando i valori di importanza.
Determinazione di un rispettivo valore di bias di selezione per ciascun esempio di addestramento nei dati di addestramento
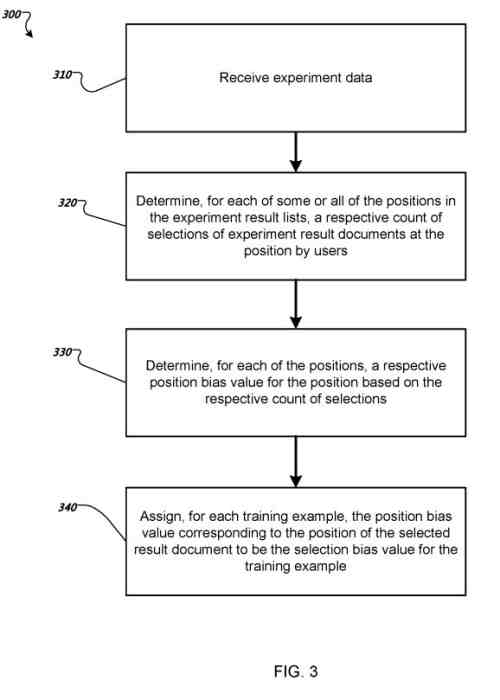
Il sistema riceve i dati dell'esperimento che identificano le query di ricerca dell'esperimento. Per ogni query di ricerca dell'esperimento, una posizione rispettiva in un elenco dei risultati dell'esperimento dei documenti dei risultati dell'esperimento per la query di ricerca dell'esperimento di un esperimento risulta nel documento selezionato da un ricercatore.
Gli elenchi dei risultati delle posizioni dei documenti dei risultati dell'esperimento sono stati permutati casualmente prima che gli elenchi dei risultati dell'esperimento fossero presentati ai ricercatori.
Pertanto, il documento del risultato dell'esperimento selezionato dal ricercatore da un determinato elenco di risultati aveva la stessa probabilità di essere assegnato a una qualsiasi delle posizioni dell'elenco dei risultati dell'esperimento.
Per ciascuna delle posizioni negli elenchi dei risultati dell'esperimento, il sistema determina un rispettivo conteggio delle selezioni dei documenti dei risultati dell'esperimento nella posizione da parte dei ricercatori in risposta alle query di ricerca dell'esperimento nei dati sperimentali.
Ad esempio, il sistema può determinare un rispettivo conteggio delle selezioni per le prime N posizioni negli elenchi dei risultati dell'esperimento, dove N è un numero intero maggiore di 1, ad esempio quattro, cinque o dieci, o per ogni posizione negli elenchi dei risultati dell'esperimento.
Ad esempio, se il sistema riceve i dati dell'esperimento inclusi 10 elenchi di risultati dell'esperimento se i ricercatori hanno selezionato la prima posizione per 7 degli elenchi di risultati dell'esperimento, una seconda posizione per 2 degli elenchi di risultati dell'esperimento. Pertanto, la terza posizione per 1 degli elenchi dei risultati dell'esperimento, il conteggio delle selezioni per la prima posizione può essere 7, il conteggio delle selezioni per la seconda posizione può essere 2 e il conteggio delle selezioni per la terza posizione può essere 1.
Per ciascuna delle posizioni, il sistema determina un rispettivo valore di polarizzazione della posizione per la posizione in base al rispettivo conteggio delle selezioni per la posizione.
Il valore di distorsione della posizione rappresenta il grado in cui il documento del risultato dell'esperimento selezionato nell'elenco dei risultati dell'esperimento per la query di ricerca dell'esperimento nei dati dell'esperimento ha influito sulla selezione del documento del risultato dell'esperimento.
In alcune implementazioni, il rispettivo valore di polarizzazione della posizione di ciascuna posizione può essere proporzionale a un rispettivo conteggio delle selezioni per la posizione. In alcune implementazioni, è possibile calcolare un rispettivo valore di distorsione della posizione per ciascuna posizione dividendo il conteggio delle selezioni nella posizione selezionando le selezioni in qualsiasi posizione delle posizioni negli elenchi dei risultati dell'esperimento.
Per ogni esempio di addestramento nei dati di addestramento, il sistema assegna il valore di distorsione della posizione corrispondente alla posizione del documento risultato selezionato nell'elenco dei risultati dei documenti di risultato per l'esempio di formazione come valore di distorsione della selezione per l'esempio di formazione.
Ad esempio, dove il sistema determina un valore di distorsione della posizione b 1 per una prima posizione utilizzando il conteggio delle selezioni dei documenti dei risultati dell'esperimento nella prima posizione se la prima posizione è la posizione di un documento dei risultati che il ricercatore ha selezionato nell'elenco dei risultati per l'esempio di addestramento nei dati di addestramento, il sistema determina che il valore di distorsione della posizione 1 è il valore di distorsione della selezione per l'esempio di formazione.
Determinazione di un rispettivo valore di bias di selezione per ciascun esempio di addestramento nei dati di addestramento
In questo esempio, ogni query di ricerca dell'esperimento nelle query di ricerca dell'esperimento è stata classificata come appartenente a una rispettiva classe di query di un insieme predeterminato di classi di query. Quindi, il sistema esegue il processo per ogni classe nell'insieme predeterminato di classi di query.

Per una data classe di query, il sistema riceve i dati dell'esperimento che identificano le query di ricerca dell'esperimento che sono state classificate come appartenenti alla data classe di query e, per ciascuna di queste query di ricerca dell'esperimento, una rispettiva posizione nell'elenco dei risultati dell'esperimento dei documenti dei risultati per la ricerca dell'esperimento query di un documento del risultato di un esperimento selezionato da un ricercatore.
Per la data classe di query, il sistema determina, per ciascuna di alcune o tutte le posizioni negli elenchi dei risultati dell'esperimento, un rispettivo conteggio delle selezioni dei documenti dei risultati dell'esperimento nella posizione da parte dei ricercatori in risposta alle query di ricerca dell'esperimento appartenenti alla query classe nei dati dell'esperimento. Così, ad esempio, il sistema può determinare un rispettivo conteggio delle selezioni per le prime N posizioni negli elenchi dei risultati dell'esperimento.
Per la data classe di query, il sistema determina un rispettivo valore di distorsione della posizione specifico della classe per la posizione in base al rispettivo conteggio delle selezioni per la posizione per ciascuna delle posizioni. In alcune implementazioni, il rispettivo valore di polarizzazione della posizione di ciascuna posizione può essere proporzionale a un rispettivo conteggio delle selezioni per la posizione.
Per ogni esempio di addestramento nei dati di addestramento, il sistema ottiene i dati che identificano una classe di query a cui appartiene la query di ricerca per l'esempio di addestramento.
Il sistema assegna, per ogni esempio di addestramento nei dati di addestramento, il valore di distorsione della posizione specifico della classe per la classe di query a cui appartiene la query di ricerca e corrispondente alla posizione del documento risultato selezionato nell'elenco dei risultati dei documenti di risultato per l'addestramento example come valore di bias di selezione per l'esempio di addestramento.
Ad esempio, dove una query di ricerca Q appartiene a una classe di query t e il sistema determina un bit del valore di distorsione della posizione specifico della classe per una prima posizione utilizzando il conteggio delle selezioni dei documenti dei risultati dell'esperimento nella prima posizione, se la prima posizione è posizione di un documento risultato che il ricercatore ha selezionato nell'elenco dei risultati per l'esempio di addestramento nei dati di addestramento, il sistema determina che il valore di distorsione della posizione specifico della classe b 1 t è il valore di distorsione della selezione per l'esempio di formazione.
Un processo di esempio per determinare un rispettivo valore di bias di selezione per ogni esempio di addestramento nei dati di addestramento
Il sistema riceve i dati dell'esperimento che identificano le query di ricerca dell'esperimento. Per ogni query di ricerca dell'esperimento, una posizione rispettiva in un elenco dei risultati dell'esperimento dei documenti dei risultati per la query di ricerca dell'esperimento di un documento dei risultati dell'esperimento selezionato da un ricercatore.

Il sistema ottiene un rispettivo vettore di caratteristiche per ogni query di ricerca dell'esperimento delle query di ricerca dell'esperimento. I vettori delle caratteristiche possono essere specifici della query o del ricercatore. Ad esempio, le caratteristiche della query possono includere il numero di parole nella query, la classe della query o la lingua preferita del ricercatore.
Il sistema genera dati di addestramento per l'addestramento di un classificatore. Il classificatore è addestrato a ricevere un rispettivo vettore di caratteristiche per una query di ricerca di input e ad emettere un rispettivo valore di polarizzazione di posizione specifico della query per ciascuna delle posizioni di query di ricerca di input.
I dati di addestramento possono includere esempi positivi di query di ricerca dell'esperimento ed esempi negativi di query di ricerca dell'esperimento. Ad esempio, il sistema può etichettare una query di ricerca dell'esperimento come un esempio positivo per l'elenco dei risultati dell'esperimento dei documenti dei risultati per la query di ricerca dell'esperimento del risultato della ricerca dell'esperimento selezionato dal ricercatore. Il sistema può etichettare la query di ricerca dell'esperimento come un esempio negativo per le posizioni non selezionate delle posizioni nell'elenco dei risultati dell'esperimento dei documenti dei risultati.
Il sistema addestra il classificatore sui dati di addestramento. L'addestramento del classificatore può essere un processo di apprendimento automatico che apprende i rispettivi pesi da applicare a ciascun vettore di funzionalità di input. In particolare, un classificatore viene addestrato utilizzando un processo di addestramento iterativo convenzionale di apprendimento automatico che determina i pesi addestrati per ciascuna posizione nell'elenco dei risultati. Sulla base dei pesi iniziali assegnati a ciascuna posizione dell'elenco dei risultati, il processo iterativo tenta di trovare i pesi ottimali. Ad esempio, il valore di distorsione della posizione bi Q specifico della query per una determinata posizione i per una determinata query di ricerca Q può essere fornito utilizzando la seguente formula:
β i denota i pesi addestrati per la posizione i e v(Q) denota un vettore di caratteristiche per la query di ricerca Q.
Il classificatore può essere un modello di regressione logistica. Altri classificatori adatti possono essere utilizzati in altre implementazioni, inclusi ingenui Bayes, alberi decisionali, entropia massima, reti neurali o classificatori basati su macchine vettoriali di supporto.
Per ogni esempio di addestramento nei dati di addestramento, il sistema ottiene un vettore di caratteristiche per la query di ricerca nell'esempio di addestramento.
Per ogni esempio di addestramento nei dati di addestramento, il sistema elabora il vettore delle caratteristiche utilizzando il classificatore addestrato per generare un rispettivo valore di distorsione della posizione specifico della query per ciascuna delle posizioni per la query di ricerca nell'esempio di addestramento. Innanzitutto, il classificatore addestrato riceve il vettore delle caratteristiche come input. Quindi, emette un rispettivo valore di distorsione della posizione specifico della query per ogni posizione nell'elenco dei risultati per la query di ricerca nell'esempio di addestramento.
Per ogni esempio di addestramento nei dati di addestramento, il sistema assegna il valore di distorsione della posizione specifico della query corrispondente alla posizione del documento risultato selezionato per l'esempio di formazione nell'elenco dei risultati dei documenti di risultato per la query di ricerca come valore di distorsione della selezione per l'esempio della formazione
Ad esempio, dove il sistema determina un valore di distorsione della posizione specifico della query b 1 Q per una prima posizione utilizzando il classificatore addestrato se la prima posizione è la posizione di un documento risultato che il ricercatore ha selezionato nell'elenco dei risultati per l'esempio di addestramento nel dati di addestramento, il sistema determina che il valore di distorsione della posizione specifico della query b 1 Q è il valore di distorsione della selezione per l'esempio di formazione.
