
ランキングモデルの機械学習
公開: 2021-05-05Googleでの機械学習
このGoogle特許は、検索クエリに応答してドキュメントをランク付けするための機械学習モデルのトレーニングに関するものです。

Googleなどのオンライン検索エンジンは、検索クエリに応答してドキュメントをランク付けし、検索クエリに応答するドキュメントで満たされた検索結果を表示します。
検索エンジンは通常、ランキングで定義された順序で検索結果を表示します。
検索エンジンは、さまざまなランク付け手法を使用してさまざまな要素を使用してドキュメントをランク付けします。
検索エンジンは、入力ドキュメントの特徴を受け取り、場合によっては受け取った検索クエリを受け取り、入力ドキュメントのランキングスコアを生成するランキング機械学習モデルに基づいてドキュメントをランク付けすることができます。
この特許は、ランキング機械学習モデルのトレーニングについて説明しています。
機械学習を使用してランキングモデルをトレーニングする
本日からの特許は2021年4月29日に付与されました。これは、検索クエリに応答してドキュメントをランク付けするためのランク付け機械学習モデルのトレーニングデータの受信に重点を置いています。
トレーニングデータには、トレーニング例が含まれています。 各トレーニング例には、以下を識別するデータが含まれています。
- 検索クエリ
- 検索クエリの結果リストからの結果ドキュメント
- 結果ドキュメントの結果リストから検索者が選択した結果ドキュメント
この特許は、トレーニングデータ内の各トレーニング例の位置データを受け取ることに関するものです。
その位置データは、トレーニング例の検索クエリのSERPで選択された結果ドキュメントの位置を識別します。
トレーニング例ごとに、位置データと、その結果が結果ドキュメントの選択に影響を与えることを表す選択バイアス値を決定します。
トレーニング例の選択バイアス値から各トレーニング例のそれぞれの重要度値を決定します。重要度値は、ランキング機械学習モデルのトレーニングにおいてトレーニング例がどれほど重要であるかを定義します。
また、特許取得済みのプロセスには、次の機能を組み合わせて含めることができます。
- 検索者が選択した実験結果ドキュメントの実験検索クエリの実験結果ドキュメントの実験結果リストのそれぞれの位置をそれぞれ埋める多くの実験検索クエリを識別する実験データを受信します。ここで、実験結果ドキュメント内の実験結果ドキュメントの位置はリストされます。検索者に提示される前にランダムに並べ替えられました
- 各位置について、実験データ内の実験検索クエリの数に応じた、検索者によるその位置での実験結果文書の選択のそれぞれの数を決定する。 そして、複数の位置のそれぞれについて、位置の選択のそれぞれのカウントに基づいて、位置のそれぞれの位置バイアス値を決定する。
- トレーニング例の結果ドキュメントの結果リストで選択された結果ドキュメントの位置に対応するそれぞれの位置バイアス値を、トレーニング例の選択バイアス値として割り当てます。
実験検索クエリの数における実験検索クエリは、それぞれ、複数のクエリクラスのそれぞれのクエリクラスに属するが、この方法は、複数のクエリクラスのそれぞれについて、以下を含む。
- 位置の数ごとに、実験データのクエリクラスに属する実験検索クエリに応答する検索者によるその位置での実験結果ドキュメントの選択の数を決定します。
- 複数の位置のそれぞれについて、位置の選択のそれぞれの数に基づいて、位置のそれぞれのクラス固有の位置バイアス値を決定する。
- トレーニング例の検索クエリが属するクエリクラスを識別するデータの取得
- 検索クエリが属するクエリクラスにクラス固有の位置バイアス値を割り当てる
- 結果ドキュメントの結果リスト内のトレーニング例の選択された結果ドキュメントの位置に対応して、トレーニング例の選択バイアス値になります。
- 各実験検索クエリのそれぞれの特徴ベクトルを取得し、入力検索クエリのそれぞれの特徴ベクトルを受け取り、入力検索の複数の位置のそれぞれについてそれぞれのクエリ固有の位置バイアス値を出力する分類器をトレーニングするためのトレーニングデータを生成します。クエリを実行し、トレーニングデータで分類器をトレーニングします
- トレーニング例での検索クエリの特徴ベクトルの取得
- トレーニングされた分類器を使用して特徴ベクトルを処理し、トレーニング例の検索クエリの複数の位置のそれぞれについて、それぞれのクエリ固有の位置バイアス値を生成します。
- 検索クエリの結果ドキュメントの結果リストで、トレーニング例の選択された結果ドキュメントの位置に対応するクエリ固有の位置バイアス値を、トレーニング例の選択バイアス値として割り当てます。
- 検索者が選択した実験検索結果の実験検索クエリの結果ドキュメントの実験結果リスト内の位置の肯定的な例として実験検索クエリにラベルを付け、他の位置の否定的な例として実験検索クエリにラベルを付ける複数のポジション
- トレーニングデータ内の複数のトレーニング例のそれぞれの重要度値を使用して、トレーニングデータでランキング機械学習モデルをトレーニングします。
- トレーニングデータ内の複数のトレーニング例の各トレーニング例について、トレーニング例のそれぞれの損失を決定する
- トレーニングデータ内の複数のトレーニング例の各トレーニング例について、トレーニング例の重要度値に基づいてトレーニング例の損失を調整し、調整された損失を生成します。
- トレーニングデータ内の複数のトレーニング例の調整済み損失を使用して機械学習モデルをトレーニングする
この方法には、トレーニングデータの複数の調整済み損失の合計を最小化することによって機械学習モデルをトレーニングすることが含まれます。
この機械学習ランキングモデルに従うことの利点
従来のクリックスルーデータモデルでは、Web検索のコンテキストで個々のクエリとドキュメントのペアの関連性を推定できます。
これらの従来のクリックスルーデータモデルは、通常、個々のクエリと結果ドキュメントのペアごとに多くのクリックを必要とします。 これにより、パーソナライズされたコーパスや個人検索などの情報ニーズのためにクリックデータが非常にまばらな場合に、クリックスルーデータモデルを適用することが困難になります。
従来のクリックスルーデータモデルと比較して、ランキングモデルをトレーニングするときにさまざまな結果リストの位置に選択バイアスを使用するシステムは、トレーニングによって生成されるランキングスコアに対する選択バイアスの影響を低減または排除しながら、スパースクリックデータをより効果的に活用できますモデル。
これは、クリックデータが非常に少ない場合でも、トレーニングされたモデルが正確なランキングスコアを提供できることを意味します。つまり、検索結果は検索者の情報ニーズをよりよく満たすことができます。
この特許は次の場所にあります。
ランキングモデルのトレーニング
特許番号:US20210125108
発明家DonaldArthur Metzler、Jr.、Xuanhui Wang、Marc Alexander Najork、Michael Bendersky
応募者GoogleLLC
付与日:2021年4月29日
提出日2016年10月24日
概要
ランキング機械学習モデルをトレーニングするための、コンピューター記憶媒体にエンコードされたコンピュータープログラムを含む方法、システム、および装置。 一態様では、方法は、ランキングマシン学習モデルのトレーニングデータ、トレーニング例を含むトレーニングデータ、および検索クエリ、検索クエリの結果リストからの結果を識別するデータを含む各トレーニング例を受信するアクションを含む。 、および結果リストから検索者によって選択された結果ドキュメントは、トレーニングデータ内の各トレーニング例の位置データを受け取り、位置データは、検索クエリの結果リスト内の選択された結果ドキュメントのそれぞれの位置を識別する。トレーニング例; トレーニングデータのトレーニング例ごとに、それぞれの選択バイアス値を決定します。 そして、トレーニング例の選択バイアス値である重要度値から、各トレーニング例のそれぞれの重要度値を決定する。
機械学習検索システムの例
サーチャーは、サーチャーデバイスを介して検索システムと対話できます。
検索装置は、データ通信ネットワーク、例えば、ローカルエリアネットワーク(LAN)またはワイドエリアネットワーク(WAN)、例えば、インターネット、またはネットワークの組み合わせを介して検索システムに結合されたコンピュータであり得る。
場合によっては、サーチャーがサーチャーデバイス上で検索を実行するアプリケーションをインストールすれば、サーチャーデバイス上に検索システムを実装することができる。
サーチャーデバイスは、一般に、命令およびデータを格納するためのメモリ、例えば、ランダムアクセスメモリ(RAM)と、格納された命令を実行するためのプロセッサとを含む。 メモリには、読み取り専用メモリと書き込み可能メモリの両方を含めることができます。
一般に、検索システムは、サーチャーデバイスのサーチャーに関連付けられているドキュメントの特定のコレクションを検索するように構成できます。
「ドキュメント」という用語は、機械で読み取り可能で機械に保存可能な作業成果物を含むために広く使用されます。
ドキュメントには次のものが含まれる場合があります。
- Eメール
- ファイル
- ファイルの組み合わせ
- 他のファイルへのリンクが埋め込まれた1つ以上のファイル
- ニュースグループの投稿
- ブログ
- ビジネスリスト
- 印刷されたテキストの電子版
- Web広告
- 等。
検索システムが検索するように構成された文書のコレクションは、検索者の電子メールアカウント、検索者のアカウントに関連付けられたモバイルアプリケーションデータ、例えば、モバイルアプリケーションの好みまたはモバイルアプリケーションの使用履歴に電子メールで送られ得る。 、クラウドドキュメントストレージアカウント内のサーチャーに関連付けられたファイル。たとえば、サーチャーによってアップロードされたファイル、他のサーチャーによってサーチャーと共有されたファイル、または別のサーチャー固有のドキュメントのコレクション。
検索者は、検索デバイスを使用して検索システムに検索クエリを送信できます。 検索者が検索クエリを送信すると、検索クエリはネットワークを介して検索システムに送信されます。
検索システムが検索クエリを受信すると、検索システム内の検索エンジンは、検索クエリを満たすドキュメントのコレクション内のドキュメントを識別し、それぞれが検索を満たし、送信されるそれぞれのドキュメントを識別する検索結果を生成することによってクエリに応答します。 /サーチャーに提示するための、すなわち、サーチャーに提示することができる形式でのサーチャーデバイスへのネットワーク。
検索エンジンは、索引付けエンジンおよびランキングエンジンを含み得る。 インデックスエンジンは、ドキュメントのコレクション内のドキュメントにインデックスを付け、インデックス付きのドキュメントをインデックスデータベースに追加します。 ランク付けエンジンは、検索クエリを満たすインデックスデータベース内のドキュメントのそれぞれのスコアを生成し、それぞれのスコアに基づいてドキュメントをランク付けします。
通常、検索結果は検索者に表示されます。 結果リストは、検索結果128によって識別されたドキュメントのランキングエンジンによって生成されたランキングスコアに従って順序付けられます。したがって、たとえば、スコアの高いドキュメントを識別する検索結果は、結果のより高い位置に表示されます。スコアが比較的低いドキュメントを識別する検索結果よりもリストします。
ランキングエンジンは、ランキング機械学習モデルを使用してドキュメントのランキングスコアを生成します。
ランキング機械学習モデルは、入力ドキュメントを特徴付ける特徴やその他のデータ、およびオプションで検索クエリを特徴付けるデータを受け取り、入力ドキュメントのランキングスコアを生成するようにトレーニングされた機械学習モデルです。
ランキング機械学習モデルでは、さまざまな機械学習モデルを使用できます。
ランキング機械学習モデルは、非線形操作の複数のレイヤーを含む、ニューラルネットワークなどの深層機械学習モデルにすることができます。
または、ランキング機械学習モデルは、一般化線形モデルなどの浅い機械学習モデルにすることができます。
ランキング機械学習モデルがどのようにトレーニングされたかに応じて、ランキングスコアは、検索クエリに対する入力ドキュメントの関連性を予測するか、入力ドキュメントの関連性と入力ドキュメントのクエリに依存しない品質の両方を考慮に入れる場合があります。

一部の実装では、ランキングエンジンは、他の要因に基づいてランキング機械学習モデルによって生成されたランキングスコアを変更し、変更されたランキングスコアを使用してドキュメントをランク付けします。
ランキング機械学習モデルをトレーニングして、受信した検索クエリに応答してモデルをランキングドキュメントで使用できるようにするために、検索システムにはトレーニングエンジンも含まれています。
トレーニングエンジンは、複数のトレーニング例を含むトレーニングデータでランキング機械学習モデルをトレーニングします。
各トレーニング例は、
- (i)検索クエリ
- (ii)検索クエリの結果リストからの結果ドキュメント
- (iii)検索クエリの結果ドキュメントの結果リストから検索者が選択した結果ドキュメント
この特許に記載されているように、検索クエリに応答する結果文書の選択は、検索者によるクエリの提出に応答して提示される検索結果の結果リストから結果文書を識別する検索結果を選択することである。 SERPは、結果リストの検索結果によって識別されるドキュメントです。
トレーニングされたランキング機械学習モデルからのランキングスコアの品質を向上させるために、トレーニングエンジンは、検索者が選択した検索結果の結果リストを考慮した方法でトレーニングします。
トレーニングエンジンは、トレーニング例の検索クエリに応答して検索者が選択した検索結果の結果リスト内の位置に基づいて、各トレーニング例のそれぞれの重要度の値を決定します。
このように機械学習モデルをトレーニングすることにより、トレーニングエンジンは、モデルがトレーニングされた後、ランキング機械学習モデルによって生成されるランキングスコアに対する位置バイアスの影響を軽減または排除します。
トレーニングデータの各トレーニング例のそれぞれの重要度の値を決定する
システムは、検索クエリに応答して検索者が選択した検索クエリの結果リスト内のそれぞれの位置、すなわち、検索クエリに応答して生成された結果リストから検索者が選択した検索結果を識別する位置データを受信する。 。
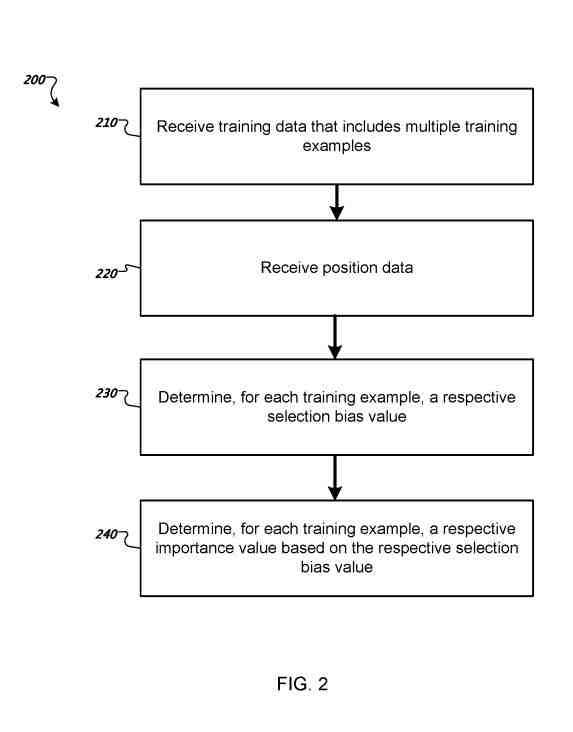
システムは、それぞれの選択バイアス値を決定します。これは、トレーニング例の検索クエリの結果リストで選択された結果ドキュメントの位置が結果ドキュメントの選択に影響を与えた程度を表します。
選択バイアス値は、さまざまな方法で決定できます。
システムは、トレーニングデータのトレーニング例ごとに、それぞれの重要度の値を決定します。
特定のトレーニング例の重要度の値は、ランキング機械学習モデルのトレーニングにおいてトレーニング例がどれほど重要であるかを定義します。
トレーニングデータ内の各トレーニング例のそれぞれの重要度の値は、トレーニング例のそれぞれの選択バイアス値に基づいて決定できます。
たとえば、特定のトレーニング例の重要度の値は、トレーニング例の選択バイアス値の逆数にすることも、より一般的には、トレーニング例の選択バイアス値に反比例することもできます。
システムがトレーニングデータのトレーニングデータのそれぞれの重要度値を決定すると、システムは重要度値を使用してトレーニングデータでランキング機械学習モデルをトレーニングします。
トレーニングデータの各トレーニング例のそれぞれの選択バイアス値を決定する
システムは、実験検索クエリを識別する実験データを受け取ります。 各実験検索クエリについて、実験結果ドキュメントの実験結果リスト内のそれぞれの位置は、検索者が選択したドキュメントになります。
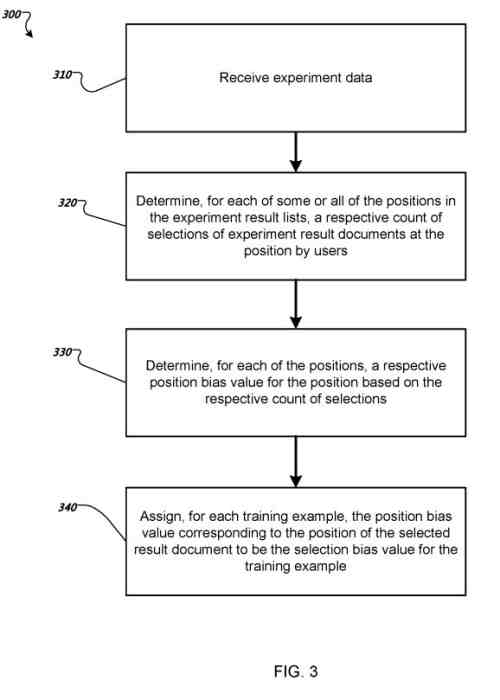
実験結果リストが検索者に提示される前に、実験結果ドキュメントの位置結果リストがランダムに並べ替えられました。
したがって、特定の結果リストから選択した検索者が、どの実験結果リストの位置にも同じように割り当てられる可能性が高いという実験結果ドキュメント。
実験結果リスト内の位置ごとに、システムは、実験データ内の実験検索クエリに応答して、検索者によるその位置での実験結果ドキュメントの選択のそれぞれのカウントを決定します。
たとえば、システムは、実験結果リストの上位N位置の選択のそれぞれの数を決定できます。ここで、Nは1より大きい整数、たとえば4、5、または10、または実験結果リストの各位置です。
たとえば、検索者が7つの実験結果リストの最初の位置を選択した場合にシステムが10の実験結果リストを含む実験データを受信する場合、2つの実験結果リストの2番目の位置を選択します。 したがって、実験結果リストの1つの3番目の位置、最初の位置の選択数は7、2番目の位置の選択数は2、3番目の位置の選択数は1になります。
位置ごとに、システムは、位置の選択のそれぞれのカウントに基づいて、位置のそれぞれの位置バイアス値を決定します。
位置バイアス値は、実験データの実験検索クエリの実験結果リストで選択された実験結果ドキュメントが、実験結果ドキュメントの選択に影響を与えた度合いを表します。
いくつかの実装形態では、各位置のそれぞれの位置バイアス値は、その位置のそれぞれの選択の数に比例することができる。 いくつかの実装形態では、各位置のそれぞれの位置バイアス値は、実験結果リスト内の位置の任意の位置で選択を選択することによって、その位置での選択の数を割ることによって計算することができる。
トレーニングデータの各トレーニング例について、システムは、トレーニング例の結果ドキュメントの結果リストで選択された結果ドキュメントの位置に対応する位置バイアス値を、トレーニング例の選択バイアス値として割り当てます。
たとえば、最初の位置が検索者が結果リストで選択した結果ドキュメントの位置である場合、システムが最初の位置での実験結果ドキュメントの選択数を使用して、最初の位置の位置バイアス値b1を決定する場合トレーニングデータのトレーニング例では、システムは位置バイアス値1がトレーニング例の選択バイアス値であると判断します。
トレーニングデータの各トレーニング例のそれぞれの選択バイアス値を決定する
この例では、実験検索クエリの各実験検索クエリは、所定のクエリクラスのセットのそれぞれのクエリクラスに属するものとして分類されています。 次に、システムは、クエリクラスの所定のセット内の各クラスのプロセスを実行します。

特定のクエリクラスについて、システムは、特定のクエリクラスに属するものとして分類された実験検索クエリを識別する実験データを受け取り、これらの実験検索クエリのそれぞれについて、実験検索の結果ドキュメントの実験結果リスト内のそれぞれの位置を受け取ります。検索者が選択した実験結果ドキュメントのクエリ。
与えられたクエリクラスについて、システムは、実験結果リスト内の一部またはすべての位置について、クエリに属する実験検索クエリに応答して、検索者がその位置で行った実験結果ドキュメントの選択のそれぞれの数を決定します。実験データのクラス。 したがって、例えば、システムは、実験結果リストの上位N位置の選択のそれぞれの数を決定することができる。
与えられたクエリクラスについて、システムは、各位置の位置のそれぞれの選択数に基づいて、その位置のそれぞれのクラス固有の位置バイアス値を決定します。 いくつかの実装形態では、各位置のそれぞれの位置バイアス値は、その位置のそれぞれの選択の数に比例することができる。
トレーニングデータ内のトレーニング例ごとに、システムはトレーニング例の検索クエリが属するクエリクラスを識別するデータを取得します。
システムは、トレーニングデータのトレーニング例ごとに、検索クエリが属するクエリクラスのクラス固有の位置バイアス値を割り当て、トレーニングの結果ドキュメントの結果リストで選択した結果ドキュメントの位置に対応します。例は、トレーニング例の選択バイアス値になります。
たとえば、検索クエリQがクエリクラスtに属し、システムが最初の位置での実験結果ドキュメントの選択数を使用して、最初の位置のクラス固有の位置バイアス値ビットを決定する場合、最初の位置は検索者がトレーニングデータのトレーニング例の結果リストで選択した結果ドキュメントの位置に基づいて、システムはクラス固有の位置バイアス値b 1tがトレーニング例の選択バイアス値であると判断します。
トレーニングデータの各トレーニング例のそれぞれの選択バイアス値を決定するためのプロセス例
システムは、実験検索クエリを識別する実験データを受け取ります。 実験検索クエリごとに、検索者が選択した実験結果ドキュメントの実験検索クエリの結果ドキュメントの実験結果リスト内のそれぞれの位置。

システムは、実験検索クエリの各実験検索クエリに対してそれぞれの特徴ベクトルを取得します。 特徴ベクトルは、クエリ固有またはサーチャー固有にすることができます。 たとえば、クエリ機能には、クエリ内の単語数、クエリのクラス、または検索者の優先言語が含まれる場合があります。
システムは、分類器をトレーニングするためのトレーニングデータを生成します。 分類器は、入力検索クエリのそれぞれの特徴ベクトルを受け取り、入力検索クエリの位置ごとにそれぞれのクエリ固有の位置バイアス値を出力するようにトレーニングされています。
トレーニングデータには、実験検索クエリの肯定的な例と実験検索クエリの否定的な例を含めることができます。 たとえば、システムは、検索者が選択した実験検索結果の実験検索クエリの結果ドキュメントの実験結果リストの肯定的な例として、実験検索クエリにラベルを付けることができます。 システムは、結果ドキュメントの実験結果リスト内の位置の選択されていない位置の否定的な例として、実験検索クエリにラベルを付けることができます。
システムは、トレーニングデータに基づいて分類器をトレーニングします。 分類器のトレーニングは、各入力特徴ベクトルに適用するそれぞれの重みを学習する機械学習プロセスにすることができます。 特に、分類器は、各結果リストの位置に対してトレーニングされた重みを決定する従来の反復機械学習トレーニングプロセスを使用してトレーニングされます。 各結果リストの位置に割り当てられた初期の重みに基づいて、反復プロセスは最適な重みを見つけようとします。 たとえば、特定の検索クエリQの特定の位置iに対するクエリ固有の位置バイアス値bi Qは、次の式を使用して指定できます。
βiは位置iのトレーニングされた重みを示し、v(Q)は検索クエリQの特徴ベクトルを示します。
分類器はロジスティック回帰モデルである可能性があります。 単純ベイズ、決定木、最大エントロピー、ニューラルネットワーク、サポートベクターマシンベースの分類器など、他の適切な分類器を他の実装で使用できます。
トレーニングデータのトレーニング例ごとに、システムはトレーニング例の検索クエリの特徴ベクトルを取得します。
トレーニングデータのトレーニング例ごとに、システムはトレーニングされた分類器を使用して特徴ベクトルを処理し、トレーニング例の検索クエリの各位置に対してそれぞれのクエリ固有の位置バイアス値を生成します。 まず、訓練された分類器が特徴ベクトルを入力として受け取ります。 次に、トレーニング例の検索クエリの結果リストの各位置について、それぞれのクエリ固有の位置バイアス値を出力します。
トレーニングデータのトレーニング例ごとに、検索クエリの結果ドキュメントの結果リストで、トレーニング例の選択された結果ドキュメントの位置に対応するクエリ固有の位置バイアス値が、の選択バイアス値に割り当てられます。トレーニングの例。
たとえば、システムが、トレーニングされた分類器を使用して、最初の位置のクエリ固有の位置バイアス値b 1 Qを決定する場合、最初の位置が、検索者がトレーニング例の結果リストで選択した結果ドキュメントの位置である場合、トレーニングデータの場合、システムは、クエリ固有の位置バイアス値b 1Qがトレーニング例の選択バイアス値であると判断します。
