
SEOのための最も重要なHTMLタグの8
公開: 2021-03-02SEOプロセスでHTMLタグを利用していますか?
HTMLタグは、すべてのWebページのバックエンドを持つコード要素ですが、検索エンジンにSERP表示の重要な情報を提供する特定のHTMLコードタイプもあります。 基本的に、これらの要素は、検索に関連するコンテンツの部分を強調表示し、検索クローラーの要素を説明します。
そうは言っても、これらの追加のコードツールをすべて使用する必要はありません。 検索エンジンはよりスマートになり、最近ではHTMLタグの使用が以前よりもはるかに少なくなっています。 しかし、いくつかのタグはまだ保持されています-そしていくつかはSEOの価値を獲得しています。
この投稿では、2020年でも意味のある主要なSEOHTMLタグのいくつかについて説明します。
1.タイトルタグ
タイトルタグは、SERPに表示されるクリック可能な見出しを設定するために使用されます。
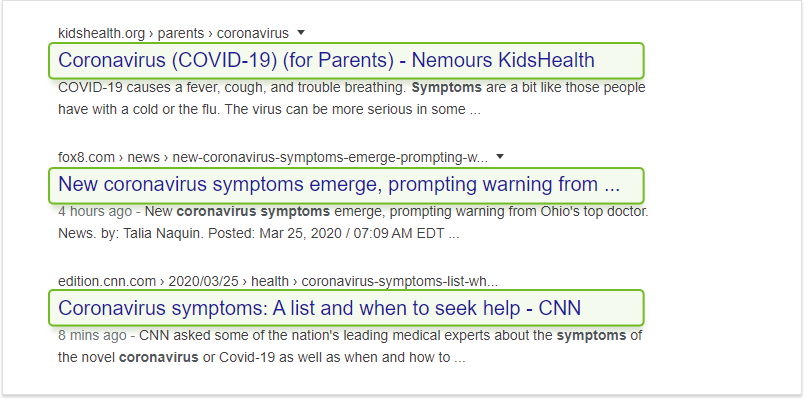
一般的に言って、ページのSERP見出しを作成するのはグーグル次第であり、ページ内から任意のセクション見出しを使用することも、まったく新しい見出しを作成することもできます。
しかし、Googleが見出しのアイデアを最初にチェックするのはタイトルタグであり、タイトルタグが存在する場合、Googleはそれを関連するリストのメインの見出しにする可能性が非常に高いです。 そのため、タイトルタグを最適化すると、SERPでのページの表示方法をある程度制御できます。
ベストプラクティス
一方では、タイトルに検索結果に表示するのに役立つキーワードを含める必要があります。 一方、タイトルはユーザーが実際にクリックスルーできるほど魅力的である必要があるため、検索の最適化とユーザーエクスペリエンスのバランスが必要です。
- 長さに注意してください-Googleはタイトルの最初の50〜60文字のみを表示し、残りを切り取ります。 カットオフポイントの前に重要な情報を収める限り、60文字を超えるタイトルを付けても問題ありません。
- 妥当な数のキーワードを含める-キーワードの乱用はペナルティを受ける可能性がありますが、1つまたは2つのキーワードで問題ありません。 タイトルが一貫した文を形成していることを確認してください。
- 良いコピーを書く-売れ行きが悪く、一般的ではありません。 コンテンツの価値を強調する説明的なタイトルを作成し、適切な期待を設定して、ユーザーがページにアクセスしたときに失望しないようにします。
- ブランド名を追加する-クリック率を高める可能性のある有名なブランドがある場合は、それをタイトルにも自由に追加してください。
HTMLコード
以下は、コロナウイルス統計に関するBBCの記事から取得したコードです。 メタディスクリプションタグのすぐ上に適切に設定されたタイトルタグが表示されます。これについて次に説明します。

2.メタ記述タグ
メタディスクリプションタグは、検索結果スニペット内にディスクリプションを設定するために使用されます。
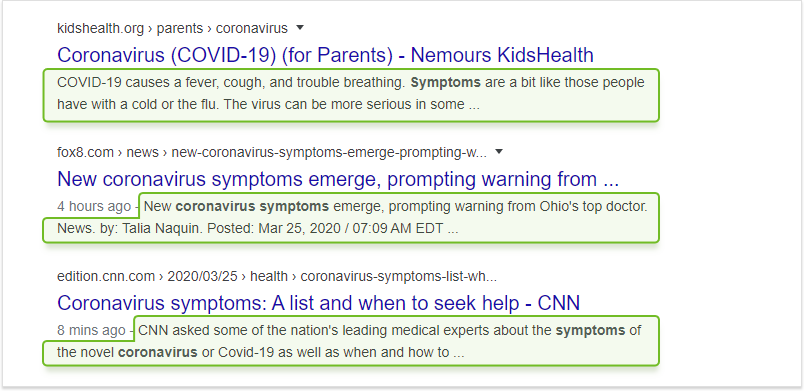
Googleは、これらのスニペットを作成するために常にメタディスクリプションタグを使用するとは限りませんが、メタタグが存在する場合は、メタディスクリプションがSERPに反映される可能性が高くなります。
ただし、Googleがメタディスクリプションタグを無視し、代わりにページから少しコピーを引用する場合があることに注意してください。 これは通常、引用符がメタディスクリプションよりも特定のクエリによく一致する場合に発生します。
基本的に、Googleはクリックスルーの可能性を高めるための最良のオプションを選択します。
ベストプラクティス
メタディスクリプションのルールはそれほど厳密ではありません。結局のところ、適切なメタデータを作成できなかった場合、完全に作成できなかったとしても、Googleが自動的に作成します。
- 長さに注意してください-見出しと同じように、Googleはメタディスクリプションの最初の150〜160文字を保持し、残りをカットします。 検索者の関心を最大化するために、重要な側面が早い段階で含まれていることを確認してください。
- 良いコピーを書く-メタディスクリプションはランキングには使用されませんが、検索目的に合わせて最適化することは依然として重要です。 それぞれのクエリに基づいて、説明の関連性が高いほど、ユーザーがページにアクセスする可能性が高くなります。
- メタディスクリプションをスキップすることを検討してください-特にロングテールのキーワードや、さまざまなキーワードを対象とするページの適切なコピーを作成するのは難しい場合があります。 そのような場合は、メタディスクリプションを除外することを検討してください。Googleはページをスクレイピングし、いずれかの方法でスニペットにいくつかの関連する引用符を入力します。
HTMLコード
以下は、コロナウイルス統計に関する同じBBCの記事から取得したコードの一部です。タイトルタグの後には、記事の内容の簡単な要約を提供するメタ説明タグがあることがわかります。

3.見出し(H1-H6)タグ
見出しタグは、リーダーと検索エンジンの両方のページを構成するために使用されます。

もうほとんど誰もが記事を読んでいないことは周知の事実です。代わりに、通常は、好きなセクションが見つかるまで記事をスキャンし、その1つのセクションを読んでから、バウンスします。 また、記事がセクションに分割されていない場合、記事が多すぎるため、多くの人がすぐにバウンスします。 したがって、ユーザーの観点からは、見出しは便利な読み物です。
ただし、検索エンジンの観点からは、見出しタグがコンテンツのコアを形成し、検索クローラーボットがページの内容を理解するのに役立ちます。
ベストプラクティス
見出しのルールは、一般的なコピーライティングの慣行に基づいています。コピーを一口サイズに分割し、一貫したフォーマットを維持します。
- 複数のH1を使用しないでください-H1の見出しは、検索エンジンによってページのタイトルとして扱われるため、他の見出しとは異なります。 タイトルタグと混同しないでください-タイトルタグは検索結果に表示され、H1タグはWebサイトに表示されます。
- 浅い構造を維持する-H3より下に行く必要はめったにありません。 タイトルにはH1、セクション見出しにはH2、サブセクションにはH3を使用します。 それ以上のものは混乱する傾向があります。
- クエリのような見出しを作成する-各見出しを検索でランク付けする追加の機会として扱います。 この目的のために、各見出しはクエリまたはクエリへの回答のように聞こえる必要があります-キーワードが含まれています。
- すべての見出しと一貫性を保つ-すべての見出しは、すべてのテキストを削除して見出しのみを保持する場合、リストのように読めるように記述する必要があります。
HTMLコード
以下は、コロナウイルス統計に関する同じBBCの記事から取得したコードの抜粋です。適切に設定されたH2見出しがあり、その後に2つの段落が続いていることがわかります。

4.画像の代替テキスト
altテキストの主な目標はWebアクセシビリティですが、alt属性のSEOの目標は画像のインデックス作成です。
画像の代替テキストの主な目的は、たとえば視覚障害のある訪問者が画像を表示できない場合に、ユーザーが画像を理解できるようにすることです。 この場合、たとえば問題が発生して画像が読み込まれない場合は、画像を表示する代わりに、代替テキストを使用して画像の内容を説明できます。
SEOの観点からは、代替テキストはGoogle検索で画像をインデックスに登録する方法の大きな部分を占めています。 したがって、製品の画像、作品、ストック画像、アートなど、自分の行動に視覚的な要素がある場合は、画像の代替テキストの使用を検討する必要があります。
ベストプラクティス
代替テキストタグを追加するための前提条件は、それなしですべての画像を見つけることです。

WebSite Auditorなどのツールを使用して、Webサイトをクロールし、代替テキストが欠落している画像のリストをコンパイルできます。
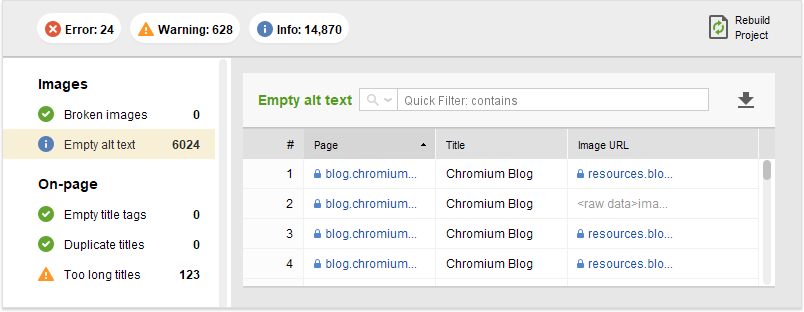
リストを作成したら、次のガイドラインを適用します。
- 簡潔に、しかし説明的に-良い代替テキストは、視覚障害者が何が描かれているのかを理解するのに役立つ1、2行のテキストに関するものです。
- 簡潔にしすぎないでください-1つの単語、またはいくつかの単語でさえ、おそらくそれをカットするつもりはありません-画像を他の画像と区別する方法はありません。 オブジェクトの種類、色、素材、形状、仕上げ、照明など、表示される可能性のあるすべてのプロパティについて考えてください。
- キーワードの乱用をしないでください-キーワードの乱用がまだ機能する場所は残っていません。代替テキストも例外ではありません。
HTMLコード
疾患細胞の画像からの代替テキストスニペットの例を次に示します。

5.スキーママークアップ
スキーママークアップは、通常のSERPスニペットをリッチスニペット機能で拡張するために使用されます。
Schema.orgは、Google、Bing、Yahoo!、Yandexが共同で開発したタグのコレクションをホストしており、タグはウェブマスターがさまざまな種類のページに関する追加情報を検索エンジンに提供するために使用されます。 次に、検索エンジンはこの情報を使用して、さまざまな豊富な機能でSERPスニペットを拡張します。
スキーママークアップを使用することでランキングの可能性が向上するかどうかは定かではありませんが、結果のスニペットが通常のスニペットよりもはるかに魅力的に見えるため、検索での地位が向上することは間違いありません。
ベストプラクティス
唯一のベストプラクティスは、schema.orgにアクセスして、ページの種類に適用できるタグがあるかどうかを確認することです。 数千とは言わないまでも数百のタグがあるので、適用されるオプションがある可能性が高く、Webサイトのリストを改善するのに役立つ可能性があります。
HTMLコード
これは、レシピの栄養成分を指定するコードのサンプルスニペットです。 マークアップに使用できるアイテムの完全なリストについては、schema.orgにアクセスしてください。

6.HTML5セマンティックタグ
HTML5要素は、さまざまなページコンポーネントをより適切に説明するために使用されます。
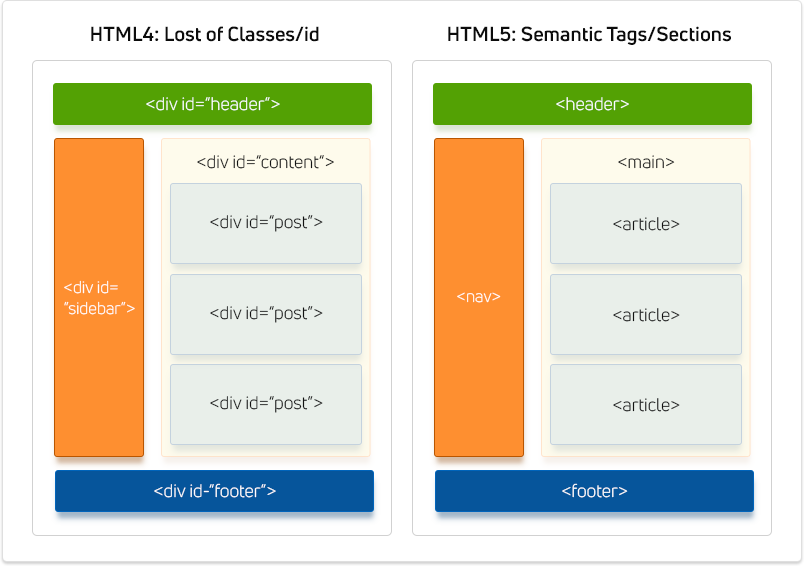
HTML5要素を導入する前は、主にdivタグを使用してHTMLコードを個別のコンポーネントに分割し、次にクラスとIDを使用してそれらのコンポーネントをさらに指定していました。 各ウェブマスターは独自のカスタム方法でコンポーネントを指定したため、結果的に少し混乱し、検索エンジンが各ページの内容を理解するのが困難になりました。
セマンティックHTML5要素の導入により、直感的なタグのセットが得られ、それぞれが個別のページコンポーネントを記述します。 そのため、コンテンツに多数の紛らわしいdivのタグを付ける代わりに、わかりやすく標準化された方法でコンポーネントを説明する方法があります。
ご想像のとおり、検索エンジンはセマンティックHTML5に非常に熱心です。
HTMLコード
最も便利なセマンティックHTML5要素のいくつかを次に示します。これらを使用して、検索エンジンとの通信を改善します。
- 記事-投稿を残りのコードから分離し、移植可能にします
- セクション-ブログ内の投稿のグループまたは投稿内の見出しのグループを分離します
- 余談-メインコンテンツの一部ではない補足コンテンツを分離します
- ヘッダー-ドキュメント、記事、セクションの上部を分離し、ナビゲーションを含めることができます
- フッター-ドキュメント、記事、セクションの下部を分離し、メタ情報を含みます
- nav-ナビゲーションメニュー、ナビゲーション要素のグループを分離します
7.メタロボットタグ
ロボットのメタタグは、ウェブサイトと検索エンジンの間の交戦規定に関するものです。
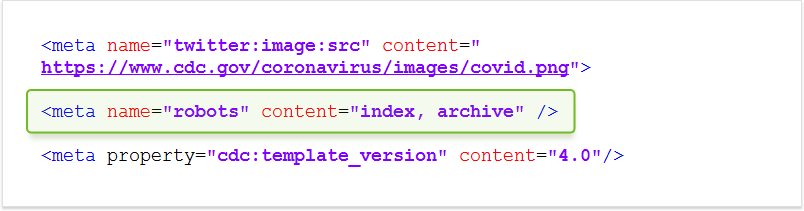
ここで、Webサイトの所有者は、ページをクロールしてインデックスを作成するための一連のルールの概要を説明します。 これらのルールの一部は必須ですが、他のルールは提案に似ています。すべてのクローラーがロボットのメタタグを尊重するわけではありませんが、主流の検索エンジンはしばしば尊重します。 また、メタロボットタグがない場合、クローラーは好きなように動作します。
ベストプラクティス
メタロボットタグは、ページコードのヘッドセクションに配置する必要があり、アドレス指定するクローラーと適用する命令を指定する必要があります。
- 名前でロボットに対処する-指示がすべてのクローラーを対象としている場合はロボットを使用しますが、個々のクローラーに対処するには特定の名前を使用します。 たとえば、Googleの標準的なWebクローラーはGooglebotと呼ばれます。 個々のロボットへの対処は通常、悪意のあるクローラーをページから禁止すると同時に、善意のクローラーが続行できるようにするために行われます。
- 指示を目標に一致させる-通常、ロボットのメタタグを使用して、検索エンジンがドキュメント、内部検索結果、重複ページ、ステージング領域など、検索に表示したくないものをインデックスに登録しないようにします。
HTMLコード
以下は、ロボットのメタタグで最も一般的に使用されるパラメータの一部です。 カンマで区切って、単一のメタロボットタグでそれらをいくつでも使用できます。
- noindex —ページにインデックスを付けないでください
- nofollow —ページ上のリンクをたどらないでください
- フォロー—ページにインデックスを付けない場合でも、ページ上のリンクをたどる必要があります
- noimageindex —ページ上の画像にインデックスを付けないでください
- noarchive —検索結果にキャッシュされたバージョンのページが表示されないようにする
- available_after —ページは特定の日付を超えてインデックス付けされるべきではありません。
8.正規タグ
Canonicalタグは、コンテンツが重複するリスクを回避します。
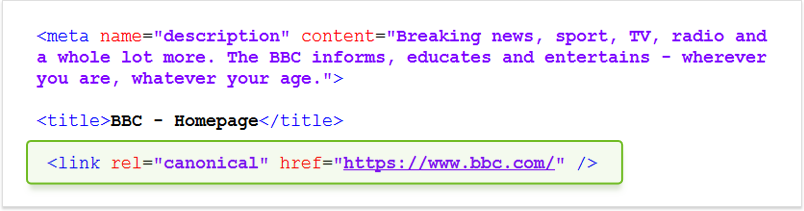
その要点は、特定のページは、あなた自身の過失ではなく、複数のアドレスを持つことができるということです。 http / httpsやさまざまなトラッキングタグなどのさまざまなアーティファクトが原因である場合もあれば、製品カタログで利用可能なさまざまな並べ替えやカスタマイズオプションが原因である場合もあります。
正直なところ、これらのアドレスすべてがクロールの予算とページの権限に負担をかけている可能性があり、パフォーマンスの追跡に支障をきたす可能性があることを除けば、大きな問題ではありません。 別の方法は、正規タグを使用して、これらのページアドレスのどれがメインアドレスであるかを検索エンジンに通知することです。
ベストプラクティス
潜在的なSEOの複雑化を回避するには、次のページに正規タグを適用します。
- さまざまなURLから利用できるページ
- 内容が非常に似ているページ
- 独自のURLパラメータを作成する動的ページ
最終的な考え
これらは、2020年にまだ心配している私のトップHTMLタグですが、それらのいくつかはしっかりと出て行くと信じています。 前述のように、検索エンジンがますますスマートになるにつれて、ほとんどのものがアルゴリズムで推測できるようになったため、HTMLタグの最適化の必要性はますます少なくなっています。 また、最新のCMSシステムのほとんどは、少なくともある程度の容量で、これらの要素を自動的に追加します。
それでも、私のコンテンツを解釈するのは完全にGoogleに任せるわけではありません。可能な限り、途中で会うのが最善です。