
Patent für hochwertige Websites von Google
Veröffentlicht: 2016-12-08
Sie erkennen vielleicht die Namen eines der Erfinder des Patents, über das ich einen Beitrag schreibe. Er hatte eines der am meisten diskutierten Google Updates nach ihm benannt. Es ist als Panda bekannt.
Ein Google-Blog-Post über Panda bezeichnet es als das Update für „hochwertige Websites“. In diesem Patent geht es darum, hochrangige Suchergebnisse von minderwertigen Websites durch hochrangige Suchergebnisse von hochwertigen Websites zu ersetzen. Einer der besten Blog-Beiträge zum Panda-Update ist dieser von Amit Singhal:
Weitere Anleitungen zum Erstellen hochwertiger Websites
Es ist gut, dass der Blog-Beitrag viel darüber erklärt, was eine qualitativ hochwertige Website ist, denn das Patent sagt uns nicht, wie man zwischen einer minderwertigen und einer qualitativ hochwertigen Website unterscheidet. In diesem Wired-Interview mit Matt Cutts und Amit Singhal werden noch mehr Erkenntnisse darüber erklärt, wie Google Websites von geringer und hoher Qualität erkennen kann:
TED 2011: Der 'Panda', der Farmen hasst: Eine Frage-und-Antwort-Runde mit den besten Suchmaschinen-Ingenieuren von Google
Dieses Patent ist interessant, weil es einen Einblick hinter das Panda-Update bietet, um uns eine Vorstellung davon zu geben, was mit Suchenden anstelle von Website-Besitzern passierte, wenn sie Suchen durchführten und nicht auf den Inhaltsfarm-Sites landeten, die das Panda-Update eigentlich hätte machen sollen lenken sie ab. Wie das Patent sagt, konzentriert es sich auf die Verbesserung der Suchergebnisse, indem minderwertige Websites durch Websites ersetzt werden, die als qualitativ hochwertige Websites identifiziert wurden.
Dies war ein Problem, das an einigen wenigen Stellen identifiziert und an prominenten Stellen vermerkt war, wie beispielsweise der New York Times, die Googles Panda Update bemerkte:
Google optimiert den Algorithmus, um Websites mit geringer Qualität herunterzudrücken
Dieses Patent identifiziert Seiten, die für bestimmte Abfragen gut ranken, und untersucht die Qualität dieser Seiten. Wenn es sich bei einem Schwellenwert dieser Ranking-Seiten um Seiten von geringer Qualität handelt, verwendet die Suchmaschine möglicherweise eine alternative Abfrage, um den zweiten Satz von Suchergebnissen zu finden, die Seiten von Websites mit hoher Qualität enthalten. Diese Suchergebnisse der ersten Abfrage können dann mit den Ergebnissen der alternativen Abfrage zusammengeführt werden, wobei die Seiten von Websites mit geringer Qualität entfernt werden, sodass die Suchergebnisse einen größeren Prozentsatz von Seiten von Websites mit hoher Qualität enthalten.
Der positive Aspekt dieses Ergebnisses ist, dass Ergebnisse, die eine hohe Schwelle für Ergebnisse von Websites geringer Qualität aufweisen, verschwinden und durch Ergebnisse mit Websites höherer Qualität ersetzt werden. Die Suchergebnisse von Google sehen am Ende besser aus.
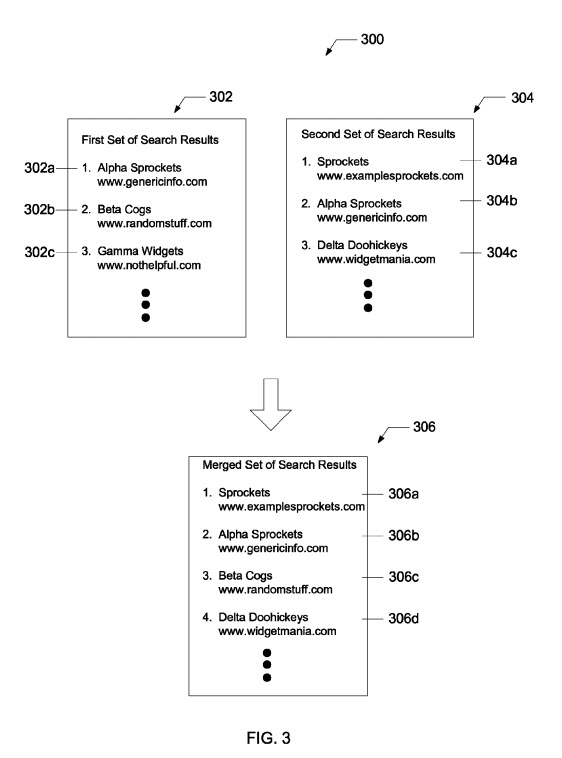
Zusammengeführte Suchergebnisse
Das Patent definiert nicht, was eine qualitativ hochwertige oder eine minderwertige Website für uns ist. Der Blog-Beitrag von Amit Singhal bietet eine bessere „Anleitung“ zur Bedeutung dieser Begriffe.
Das Patent behandelt nicht den Verlust von Datenverkehr zu Websites mit geringer Qualität, die aus den Suchergebnissen entfernt werden. Wir haben von Menschen gehört, die von Panda betroffen waren, wie viel Traffic sie auf ihre Websites verloren.
Das Patent lautet:
Selektive Generierung alternativer Abfragen
Erfinder Navneet Panda, April R. Lehman, Trystan G. Upstill
Ursprünglicher Bevollmächtigter Google Inc.
Veröffentlichungsnummer US9135307 B1
Publikationsart Stipendium
Antragsnummer US 13/728,851
Erscheinungsdatum 15.09.2015
Einreichungsdatum 27. Dezember 2012
Abstrakt:
Verfahren, Systeme und Geräte, einschließlich auf Computerspeichermedien codierter Computerprogramme, zum Erhalten von Suchergebnissen von hochwertigen Websites. Eines der Verfahren umfasst das Empfangen von Daten, die erste Ressourcen identifizieren, die auf eine erste Abfrage reagieren. Wenn sich mindestens eine erste Schwellenanzahl N der ersten Ressourcen mit dem höchsten Rang auf Sites befindet, die zuvor als Sites geringer Qualität identifiziert wurden, werden eine zweite Abfrage und Daten erhalten, die zweite Ressourcen identifizieren, die auf die zweite Abfrage reagieren, wobei mindestens eine zweite Schwelle Anzahl M der zweitbesten Ressourcen befinden sich auf Standorten, die zuvor als qualitativ hochwertige Standorte identifiziert wurden. Suchergebnisse werden als Reaktion auf die erste Abfrage bereitgestellt, wobei die Suchergebnisse eine oder mehrere der ersten Ressourcen identifizieren und auch eine bestimmte zweite Ressource der zweiten Ressourcen identifizieren.

Es ist interessant, wie eine „Site“ in diesem Patent definiert wird, und dies sind die angebotenen Alternativen:
(1) eine Sammlung von Ressourcen, die auf einem bestimmten Server gehostet werden.
(2) Die Ressourcen in einer Domäne, z. B. „example.com“, wobei die Ressourcen in der Domäne, z. B. „host.example.com/resource1“, „www.example.com/folder/resource2“ oder „ example.com/resource3“, befinden sich auf der Site.
(3) Die Ressourcen in einer Subdomain, z. B. „en.example.com“, wobei die Ressourcen in der Subdomain, z. B. „en.example.com/resource1“ oder „en.example.com/folder/resource2“, sind auf der Seite.
(4) Die Ressourcen in einem Unterverzeichnis, zB „example.com/subdirectory“, wobei sich die Ressourcen in dem Unterverzeichnis, zB „example.com/subdirectory/resource.html“, in der Site befinden.
Es gibt eine Erwähnung von Site-Qualitätswerten, aber nicht, wie sie bestimmt werden. Das Patent sagt uns, dass die Suchmaschine möglicherweise eine weiße Liste von Websites mit hoher Qualität und eine schwarze Liste von Websites mit geringer Qualität verwendet, die manuell oder auf andere Weise offline erstellt wurden.
Uns wird auch mitgeteilt, dass im Laufe der Zeit möglicherweise Informationen zu Anfragen gesammelt werden. Wenn sich ein bestimmter Anteil der Seiten mit dem höchsten Rang für die erste Abfrage auf Websites mit geringer Qualität befindet, kann eine zweite Abfrage basierend auf dieser ersten Abfrage verwendet werden. Das Patent sagt uns, dass eine Möglichkeit dazu besteht, eine Datenbank zu verwenden, die „Ersatzabfragebegriffe enthält und eine alternative Abfrage generieren kann, indem ein Ersatzabfragebegriff für einen der Abfragebegriffe in der ersten Abfrage ersetzt wird“. Dies erinnerte mich an einige Beiträge, die ich über Google-Patente geschrieben habe, die Ersatzabfragebegriffe behandeln, wie ich in folgenden Artikeln geschrieben habe:
- Wie Google Abfragebegriffe durch gemeinsames Auftreten ersetzen kann
- Wie Suchmaschinen Ihre Suchbegriffe durch andere ersetzen können
- Untersuchen von Google RankBrain und Ersetzungen von Abfragebegriffen
Als Alternative sagt uns das Patent, dass die Suchmaschine „einen konzeptionellen Graphen von Abfragen erstellen und den Graphen durchqueren könnte, um eine oder mehrere alternative Abfragen zu erhalten“. „Jeder Knoten im Diagramm wird durch eine Abfrage und eine Reihe von Suchergebnissen mit dem höchsten Rang definiert, die für die Abfrage erhalten wurden. Verknüpfungen zwischen Knoten im Diagramm können darauf hinweisen, dass die Abfragen zusammenhängen oder dass eine Abfrage eine alternative Abfrage für eine andere Abfrage ist.“
Das würde sich stark von den Link-Graphen unterscheiden, über die wir bei Google nachdenken, aber eine interessante Denkweise darüber, wie alternative Suchanfragen gefunden werden könnten. Das Patent baut auf diesem Graphen-Ansatz auf, und es hört sich so an, als ob es eine Methode sein könnte, die sie verwendet haben.
Dieses Suchsystem kann mehr als eine mögliche alternative Abfrage auswerten, bevor eine mit dem höchsten Vertrauensmaß ausgewählt wird.
Wenn die Ergebnismenge eine zusammengeführte Schwellenwertmenge hochwertiger Sites enthält, wird möglicherweise versucht, mehr alternative Abfrageergebnisse von qualitativ hochwertigen Sites zu erhalten.
Fazit
Dies könnte das Originalpatent des Panda-Updates sein. Navneet Panda von Google ist einer der Erfinder des Patents, wie im Wired-Interview mit Cutts and Singhal bekannt wurde. Und dieses Patent zielt auf Content-Farm-Sites ab, wofür das ursprüngliche Panda Update am bekanntesten war. Das Patent selbst offenbart keine Unterschiede zwischen minderwertigen und qualitativ hochwertigen Websites, und wir haben im Wired-Interview erfahren, dass es der Suchingenieur namens Panda war, der einige der ersten Fragen stellte, um die Unterschiede zwischen den beiden zu identifizieren.