
Patente de sites de alta qualidade do Google
Publicados: 2016-12-08
Você pode reconhecer os nomes de um dos inventores da patente sobre a qual estou escrevendo um artigo. Ele teve um dos mais comentados Google Updates com o seu nome. É conhecido como Panda.
Uma postagem no blog do Google sobre o Panda se refere a ele como a atualização de “sites de alta qualidade”; esta patente fala sobre a substituição de resultados de pesquisa de alta classificação de sites de baixa qualidade por resultados de pesquisa de alta classificação de sites de alta qualidade. Uma das melhores postagens de blog sobre a Atualização do Panda é esta de Amit Singhal:
Mais orientações sobre a construção de sites de alta qualidade
É bom que a postagem do blog descreva muito sobre o que é um site de alta qualidade, porque a patente não nos diz como distinguir entre um site de baixa qualidade e um de alta qualidade. Ainda mais insights sobre como o Google pode identificar sites de baixa e alta qualidade são explicados nesta entrevista da Wired com Matt Cutts e Amit Singhal:
TED 2011: O 'Panda' que odeia fazendas: Perguntas e respostas com os principais engenheiros de pesquisa do Google
Esta patente é interessante porque fornece um vislumbre por trás do Panda Update para nos dar uma ideia do que estava acontecendo com os pesquisadores, e não com os proprietários do site, quando eles realizaram pesquisas e não acabaram nos sites de farm de conteúdo que o Panda Update deveria desviá-los de. Como diz a patente, ela “se concentra em melhorar os resultados da pesquisa, substituindo sites de baixa qualidade por sites que foram identificados como sites de alta qualidade”.
Esse foi um problema que foi identificado em alguns lugares e observado em lugares de destaque, como o New York Times, que notou a atualização do Google Panda:
Algoritmo de ajustes do Google para reduzir sites de baixa qualidade
Esta patente identifica páginas que têm boa classificação para determinadas consultas e analisa a qualidade dessas páginas. Se uma quantidade limite dessas páginas de classificação forem páginas de baixa qualidade, o mecanismo de pesquisa pode usar uma consulta alternativa para encontrar o segundo conjunto de resultados de pesquisa que inclui páginas de sites de alta qualidade. Os resultados da pesquisa da primeira consulta podem então ser mesclados com os resultados da consulta alternativa, com as páginas dos sites de baixa qualidade removidas para que os resultados da pesquisa incluam uma porcentagem maior de páginas de sites de alta qualidade.
O aspecto positivo desse resultado é que os resultados que têm um limite alto de resultados de sites de baixa qualidade desaparecem e são substituídos por resultados que incluem sites de qualidade superior. Os resultados de pesquisa do Google acabam ficando melhores.
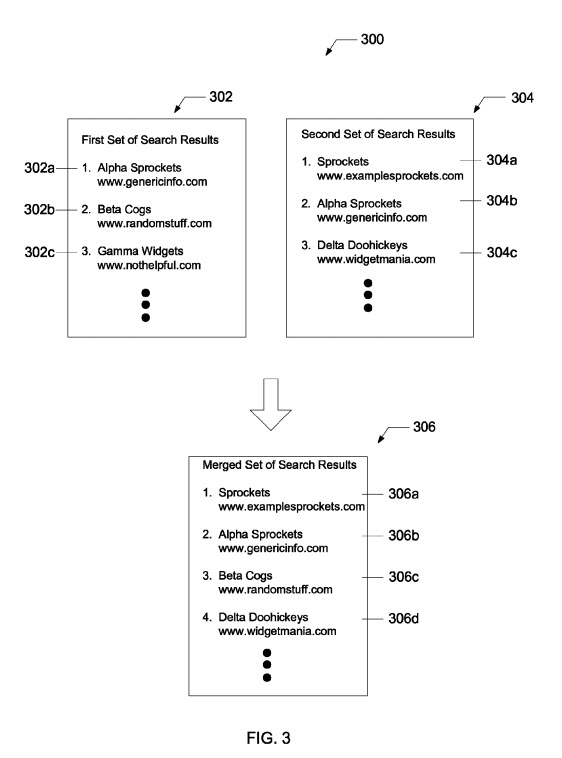
Resultados de pesquisa mesclados
A patente não define o que é um site de alta ou baixa qualidade para nós. A postagem no blog de Amit Singhal faz um trabalho melhor ao fornecer “orientação” sobre o que esses termos significam.
A patente não discute a perda de tráfego para sites de baixa qualidade que são removidos dos resultados de pesquisa. Ouvimos de pessoas que foram impactadas pelo Panda quanto tráfego elas estavam perdendo em seus sites.
A patente é:
Geração seletiva de consultas alternativas
Inventores Navneet Panda, April R. Lehman, Trystan G. Upstill
Cessionário original Google Inc.
Publicação número US9135307 B1
Publicação tipo Concessão
Número do pedido US 13 / 728.851
Data de publicação 15 de setembro de 2015
Data de arquivamento 27 de dezembro de 2012
Resumo:
Métodos, sistemas e aparelhos, incluindo programas de computador codificados em mídia de armazenamento de computador, para obter resultados de pesquisa em sites de alta qualidade. Um dos métodos inclui o recebimento de dados que identificam os primeiros recursos que respondem a uma primeira consulta. Se pelo menos um primeiro número limite N dos primeiros recursos classificados estiver localizado em sites previamente identificados como sites de baixa qualidade, uma segunda consulta e dados identificando os segundos recursos que são responsivos à segunda consulta são obtidos, em que pelo menos um segundo limite o número M dos segundos recursos mais bem classificados está localizado em sites previamente identificados como sites de alta qualidade. Os resultados da pesquisa são fornecidos em resposta à primeira consulta, em que os resultados da pesquisa identificam um ou mais dos primeiros recursos e também identificam um segundo recurso particular dos segundos recursos.

É interessante como um "site" é definido dentro desta patente, e estas são as alternativas fornecidas:
(1) uma coleção de recursos hospedados em um servidor específico.
(2) Os recursos em um domínio, por exemplo, “example.com,” onde os recursos no domínio, por exemplo, “host.example.com/resource1,” “www.example.com/folder/resource2,” ou “ example.com/resource3, ”estão no site.
(3) Os recursos em um subdomínio, por exemplo, “en.example.com,” onde os recursos no subdomínio, por exemplo, “en.example.com/resource1” ou “en.example.com/folder/resource2,” estão no site.
(4) Os recursos em um subdiretório, por exemplo, “exemplo.com/subdiretório,” onde os recursos no subdiretório, por exemplo, “exemplo.com/subdiretório/resource.html,” estão no site.
Há uma menção aos índices de qualidade do site, mas não como são determinados. A patente nos diz que o mecanismo de busca pode usar uma lista branca de sites de alta qualidade e uma lista negra de sites de baixa qualidade preparados manualmente ou por algum outro método offline.
Também somos informados de que informações sobre consultas podem ser coletadas com o tempo. Se uma certa quantidade das páginas de melhor classificação para a consulta inicial estiverem em sites de baixa qualidade, uma segunda consulta com base nessa primeira consulta pode ser usada. A patente nos diz que uma maneira de fazer isso é usar um banco de dados que “inclui termos de consulta substitutos e pode gerar uma consulta alternativa substituindo um termo de consulta substituto por um dos termos de consulta na primeira consulta”. Isso me lembrou de alguns posts que escrevi sobre patentes do Google cobrindo termos de consulta substitutos, como escrevi em:
- Como o Google pode substituir os termos de consulta por coocorrência
- Como os motores de busca podem substituir outros termos de pesquisa pelos seus
- Investigando o Google RankBrain e substituições de termos de consulta
Como alternativa, a patente nos diz que o mecanismo de pesquisa pode construir “um gráfico conceitual de consultas e percorrer o gráfico para obter uma ou mais consultas alternativas”. Que, “cada nó no gráfico é definido por uma consulta e um conjunto de resultados de pesquisa com classificação superior obtidos para a consulta. Os links entre os nós no gráfico podem indicar que as consultas estão relacionadas ou que uma consulta é uma consulta alternativa para outra consulta. ”
Isso seria muito diferente dos gráficos de links que pensamos quando se trata do Google, mas uma maneira interessante de pensar sobre como as consultas alternativas podem ser encontradas. A patente se baseia nessa abordagem de gráfico e parece que pode ser um método usado por eles.
Este sistema de pesquisa pode avaliar mais de uma consulta alternativa possível antes de selecionar uma com a maior medida de confiança.
Se o conjunto de resultados inclui uma quantidade limite mesclada de sites de alta qualidade, ele pode tentar acumular mais resultados de consulta alternativos de sites de alta qualidade.
Conclusão
Esta pode ser a patente original da atualização do Panda. Navneet Panda, do Google, é um dos inventores da patente, como foi divulgado na entrevista da Wired com Cutts e Singhal. E esta patente tem como alvo sites de farm de conteúdo, que é o motivo pelo qual o Panda Update original era mais conhecido. A patente em si não revela diferenças entre sites de baixa qualidade e de alta qualidade, e aprendemos na entrevista com fio que foi o engenheiro de pesquisa chamado Panda que surgiu com algumas das perguntas iniciais para identificar as diferenças entre os dois.