
Patente de sitios de alta calidad de Google
Publicado: 2016-12-08
Puede reconocer los nombres de uno de los inventores de la patente sobre la que estoy escribiendo una publicación. Tenía una de las actualizaciones de Google más comentadas que lleva su nombre. Se lo conoce como Panda.
Una publicación del blog de Google sobre Panda se refiere a ella como la actualización de "sitios de alta calidad"; esta patente habla de reemplazar los resultados de búsqueda de alto rango de sitios de baja calidad con resultados de búsqueda de alto rango de sitios de alta calidad. Una de las mejores publicaciones de blog sobre Panda Update es esta de Amit Singhal:
Más orientación sobre cómo crear sitios de alta calidad
Es bueno que la publicación del blog detalle mucho sobre qué es un sitio web de alta calidad porque la patente no nos dice cómo distinguir entre un sitio de baja calidad y uno de alta calidad. En esta entrevista de Wired con Matt Cutts y Amit Singhal, se explican aún más conocimientos sobre cómo Google puede identificar sitios de baja y alta calidad:
TED 2011: El 'panda' que odia las granjas: una sesión de preguntas y respuestas con los mejores ingenieros de búsqueda de Google
Esta patente es interesante porque proporciona un vistazo detrás de la Actualización de Panda para darnos una idea de lo que les estaba sucediendo a los buscadores en lugar de a los propietarios del sitio cuando realizaban búsquedas y no terminaban en los sitios de la granja de contenido que se suponía que debía hacer la Actualización de Panda. desviarlos de. Como dice la patente, "se enfoca en mejorar los resultados de búsqueda reemplazando sitios web de baja calidad con sitios que han sido identificados como sitios de alta calidad".
Este era un problema que se había identificado en algunos lugares y observado en lugares destacados, como el New York Times, que notó la actualización de Panda de Google:
Google modifica el algoritmo para eliminar los sitios de baja calidad
Esta patente identifica las páginas que se clasifican bien para determinadas consultas y analiza la calidad de esas páginas. Si una cantidad mínima de esas páginas de clasificación son páginas de baja calidad, el motor de búsqueda puede usar una consulta alternativa para encontrar el segundo conjunto de resultados de búsqueda que incluyen páginas de sitios de alta calidad. Esos resultados de búsqueda de la primera consulta podrían fusionarse con los resultados de la consulta alternativa, eliminando las páginas de los sitios de baja calidad para que los resultados de búsqueda incluyan un mayor porcentaje de páginas de sitios de alta calidad.
El aspecto positivo de este resultado es que los resultados que tienen un umbral alto de resultados de sitios de baja calidad desaparecen y son reemplazados por resultados que incluyen sitios de mayor calidad. Los resultados de búsqueda de Google terminan luciendo mejor.
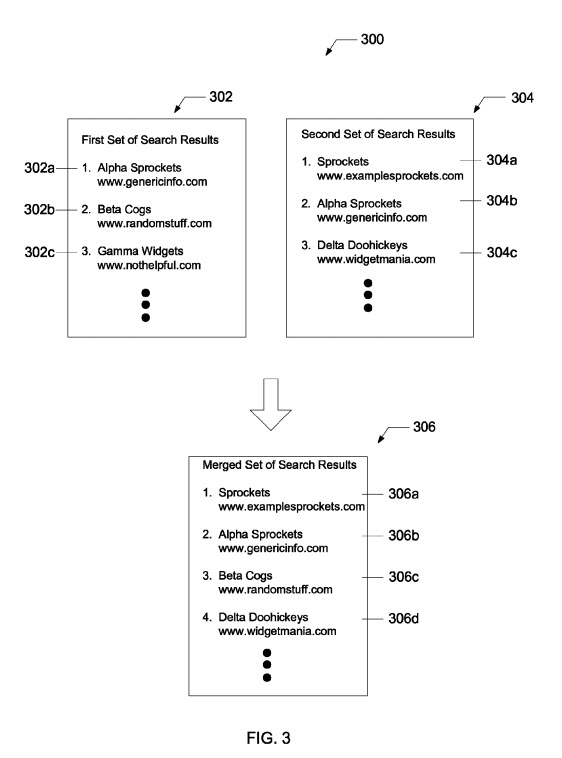
Resultados de búsqueda combinados
La patente no define qué es para nosotros un sitio de alta o baja calidad. La publicación del blog de Amit Singhal hace un mejor trabajo al brindar “orientación” sobre lo que significan esos términos.
La patente no analiza la pérdida de tráfico a los sitios de baja calidad que se eliminan de los resultados de búsqueda. Escuchamos de las personas que se vieron afectadas por Panda la cantidad de tráfico que estaban perdiendo en sus sitios.
La patente es:
Generación de consultas alternativas de forma selectiva
Inventores Navneet Panda, April R. Lehman, Trystan G. Upstill
Cesionario original Google Inc.
Número de publicación US9135307 B1
Tipo de publicación Beca
Número de solicitud US 13 / 728,851
Fecha de publicación 15/09/2015
Fecha de solicitud 27 de diciembre de 2012
Abstracto:
Métodos, sistemas y aparatos, incluidos programas informáticos codificados en soportes de almacenamiento informáticos, para obtener resultados de búsqueda en sitios de alta calidad. Uno de los métodos incluye recibir datos que identifican los primeros recursos que responden a una primera consulta. Si al menos un primer número de umbral N de los primeros recursos mejor clasificados se encuentran en sitios previamente identificados como sitios de baja calidad, se obtienen una segunda consulta y datos que identifican los segundos recursos que responden a la segunda consulta, en donde al menos un segundo umbral El número M de los segundos recursos mejor clasificados se encuentran en sitios previamente identificados como sitios de alta calidad. Los resultados de la búsqueda se proporcionan en respuesta a la primera consulta, en la que los resultados de la búsqueda identifican uno o más de los primeros recursos y también identifican un segundo recurso particular de los segundos recursos.

Es interesante cómo se define un "sitio" dentro de esta patente, y estas son las alternativas proporcionadas:
(1) una colección de recursos que están alojados en un servidor en particular.
(2) Los recursos de un dominio, p. Ej., "Ejemplo.com", donde los recursos del dominio, p. Ej., "Host.example.com/resource1", "www.example.com/folder/resource2" o " example.com/resource3 ”, están en el sitio.
(3) Los recursos en un subdominio, por ejemplo, "en.example.com", donde los recursos en el subdominio, por ejemplo, "en.example.com/resource1" o "en.example.com/folder/resource2", están en el sitio.
(4) Los recursos en un subdirectorio, por ejemplo, "ejemplo.com/subdirectorio", donde los recursos en el subdirectorio, por ejemplo, "ejemplo.com/subdirectorio/resource.html", están en el sitio.
Se mencionan los puntajes de calidad del sitio, pero no cómo se determinan. La patente nos dice que el motor de búsqueda podría usar una lista blanca de sitios de alta calidad y una lista negra de sitios de baja calidad preparada manualmente o por algún otro método fuera de línea.
También se nos dice que la información sobre consultas se puede recopilar durante algún tiempo. Si una cierta cantidad de las páginas de mayor rango para la consulta inicial se encuentran en sitios de baja calidad, se podría usar una segunda consulta basada en esa primera consulta. La patente nos dice que una forma de hacerlo es utilizar una base de datos que "incluya términos de consulta sustitutos y pueda generar una consulta alternativa sustituyendo uno de los términos de consulta en la primera consulta por un término de consulta sustituto". Esto me recordó algunas publicaciones que he escrito sobre patentes de Google que cubren términos de consulta sustitutos como los que escribí en:
- Cómo puede Google sustituir los términos de consulta con la coincidencia
- Cómo los motores de búsqueda pueden sustituir el suyo por otros términos de búsqueda
- Investigación de sustituciones de términos de consulta y RankBrain de Google
Como alternativa, la patente nos dice que el motor de búsqueda podría construir "un gráfico conceptual de consultas y recorrer el gráfico para obtener una o más consultas alternativas". Que, “cada nodo en el gráfico está definido por una consulta y un conjunto de resultados de búsqueda mejor clasificados obtenidos para la consulta. Los vínculos entre los nodos del gráfico pueden indicar que las consultas están relacionadas o que una consulta es una consulta alternativa para otra consulta ".
Eso sería muy diferente de los gráficos de enlaces en los que pensamos cuando se trata de Google, pero es una forma interesante de pensar sobre cómo se pueden encontrar consultas alternativas. La patente se basa en este enfoque gráfico y parece que podría ser un método que utilizaron.
Este sistema de búsqueda puede evaluar más de una consulta alternativa posible antes de seleccionar una con el mayor grado de confianza.
Si el conjunto de resultados incluye una cantidad umbral combinada de sitios de alta calidad, podría intentar acumular más resultados de consultas alternativos de sitios de alta calidad.
Conclusión
Esta puede ser la patente original de Panda Update. Navneet Panda de Google es uno de los inventores de la patente, como se reveló en la entrevista de Wired con Cutts y Singhal. Y esta patente se dirige a sitios de granjas de contenido, que es por lo que la Actualización Panda original era más conocida. La patente en sí no revela las diferencias entre los sitios de baja calidad y los de alta calidad, y en la entrevista por cable nos enteramos de que fue el ingeniero de búsqueda llamado Panda quien planteó algunas de las preguntas iniciales que identificaban las diferencias entre los dos.