
Googleの高品質サイト特許
公開: 2016-12-08
私が投稿している特許の発明者の一人の名前をご存知かもしれません。 彼は彼にちなんで名付けられた最も話題のGoogleアップデートの1つを持っていました。 パンダとして知られています。
パンダに関するGoogleブログの投稿では、パンダを「高品質のサイト」の更新と呼んでいます。 この特許は、低品質のサイトからの高ランクの検索結果を高品質のサイトからの高ランクの検索結果に置き換えることについて説明しています。 Panda Updateに関する最高のブログ投稿の1つは、AmitSinghalからの次の投稿です。
高品質のサイトを構築するための詳細なガイダンス
特許は低品質のサイトと高品質のサイトを区別する方法を教えていないので、ブログ投稿が高品質のWebサイトとは何かについて多くのことを詳しく説明しているのは良いことです。 グーグルが低品質と高品質のサイトをどのように特定するかについてのさらに多くの洞察は、マット・カッツとアミット・シンハルとのこの有線インタビューで説明されています。
TED 2011:農場を憎む「パンダ」:Googleのトップ検索エンジニアとのQ&A
この特許は、Panda Updateの背後にある一瞥を提供し、サイト所有者ではなく検索者が検索を実行し、PandaUpdateが想定していたコンテンツファームサイトに到達しなかったときに何が起こったのかを示しているため、興味深いものです。それらをそらす。 特許が言うように、それは「低品質のウェブサイトを高品質のサイトとして識別されたサイトに置き換えることによって検索結果を改善することに焦点を合わせています」。
これは、いくつかの場所で特定され、Googleのパンダアップデートに気付いたニューヨークタイムズなどの著名な場所で指摘されていた問題でした。
グーグルは低品質のサイトを押し下げるためにアルゴリズムを微調整します
この特許は、特定のクエリに適したページを特定し、それらのページの品質を調べます。 これらのランキングページのしきい値が低品質のページである場合、検索エンジンは代替クエリを使用して、高品質のサイトからのページを含む検索結果の2番目のセットを検索する場合があります。 次に、最初のクエリの検索結果が代替クエリの結果とマージされ、低品質のサイトのページが削除されて、検索結果に高品質のサイトのページがより多く含まれるようになります。
この結果の良い面は、低品質のサイトからの結果のしきい値が高い結果が消え、高品質のサイトを含む結果に置き換えられることです。 Googleの検索結果は見栄えが良くなります。
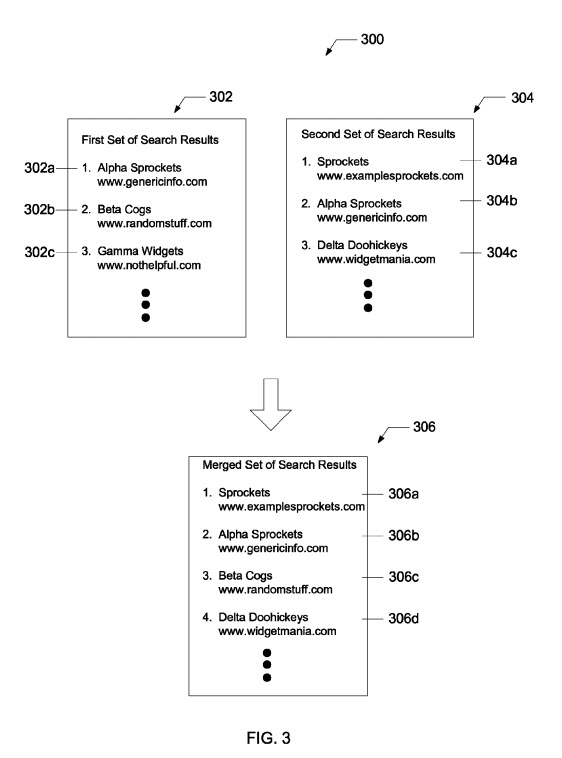
マージされた検索結果
この特許は、私たちにとって高品質または低品質のサイトが何であるかを定義していません。 Amit Singhalのブログ投稿は、これらの用語の意味についての「ガイダンス」を提供する上でより良い仕事をしています。
この特許は、検索結果から削除された低品質のサイトへのトラフィックの損失については説明していません。 パンダの影響を受けた人々から、自分のサイトにどれだけのトラフィックが失われているのか聞いた。
特許は次のとおりです。
代替クエリを選択的に生成する
発明家NavneetPanda、April R. Lehman、Trystan G. Upstill
元の譲受人GoogleInc。
公開番号US9135307B1
出版物の種類助成金
出願番号US13 / 728,851
発行日2015年9月15日
出願日2012年12月27日
概要:
高品質のサイトから検索結果を取得するための、コンピューター記憶媒体にエンコードされたコンピュータープログラムを含む方法、システム、および装置。 方法の1つには、最初のクエリに応答する最初のリソースを識別するデータを受信することが含まれます。 上位の第1のリソースの少なくとも第1の閾値数Nが、以前に低品質サイトとして識別されたサイトに位置する場合、第2のクエリおよび第2のクエリに応答する第2のリソースを識別するデータが得られ、ここで、少なくとも第2の閾値上位の2番目のリソースの数Mは、以前に高品質のサイトとして識別されたサイトにあります。 検索結果は、第1のクエリに応答して提供され、検索結果は、第1のリソースのうちの1つまたは複数を識別し、また、第2のリソースの特定の第2のリソースを識別する。

この特許内で「サイト」がどのように定義されているかは興味深いものであり、これらは提供される代替案です。
(1)特定のサーバーでホストされているリソースのコレクション。
(2)ドメイン内のリソース(例:「example.com」)。ドメイン内のリソース(例:「host.example.com/resource1」」「www.example.com/folder/resource2」または「 example.com/resource3」がサイトにあります。
(3)サブドメイン内のリソース(例:「en.example.com」)。サブドメイン内のリソース(例:「en.example.com/resource1」または「en.example.com/folder/resource2」)。サイトにあります。
(4)サブディレクトリ内のリソース(例:「example.com/subdirectory」)。サブディレクトリ内のリソース(例:「example.com/subdirectory/resource.html」)はサイト内にあります。
サイトの品質スコアについては言及されていますが、それらがどのように決定されるかについては言及されていません。 この特許は、検索エンジンが手動またはオフラインで他の方法で作成された高品質のサイトのホワイトリストと低品質のサイトのブラックリストを使用する可能性があることを示しています。
また、クエリに関する情報は、しばらくすると収集される可能性があるとも言われています。 最初のクエリの上位ページの特定の量が低品質のサイトにある場合、その最初のクエリに基づく2番目のクエリが使用される可能性があります。 この特許は、これを行う1つの方法は、「代替クエリ用語を含み、最初のクエリのクエリ用語の1つを代替クエリ用語に置き換えることで代替クエリを生成できる」データベースを使用することであると述べています。 これは、私が次のように書いたような代替クエリ用語をカバーするGoogle特許について書いたいくつかの投稿を思い出させました。
- Googleが共起でクエリ用語を置き換える方法
- 検索エンジンがあなたの代わりに他の検索用語を使用する方法
- GoogleのRankBrainとクエリ用語の置換の調査
別の方法として、この特許は、検索エンジンが「クエリの概念グラフを作成し、グラフをトラバースして1つ以上の代替クエリを取得する」可能性があることを示しています。 つまり、「グラフの各ノードは、クエリと、クエリに対して取得された上位の検索結果のセットによって定義されます。 グラフ内のノード間のリンクは、クエリが関連していること、または1つのクエリが別のクエリの代替クエリであることを示している可能性があります。」
これは、Googleに関して考えるリンクグラフとは大きく異なりますが、代替クエリがどのように見つかるかについての興味深い考え方です。 この特許はこのグラフアプローチに基づいており、彼らが使用した方法のように思われます。
この検索システムは、信頼度が最も高いクエリを選択する前に、複数の可能な代替クエリを評価する場合があります。
マージされたしきい値量の高品質サイトを含む一連の結果の場合、高品質サイトからより多くの代替クエリ結果を取得しようとする可能性があります。
結論
これは、PandaUpdateの元の特許である可能性があります。 GoogleのNavneetPandaは、CuttsとSinghalのWiredインタビューで明らかにされたように、この特許の発明者の1人です。 そして、この特許はコンテンツファームサイトを対象としています。これは、元のPandaUpdateで最もよく知られているものです。 特許自体は低品質のサイトと高品質のサイトの違いを開示しておらず、Wired Interviewで、2つの違いを特定する最初の質問のいくつかを思いついたのはPandaという名前の検索エンジニアであることがわかりました。